AI Native Daily Paper Digest – 20241210

1. Evaluating and Aligning CodeLLMs on Human Preference
🔑 Keywords: Code LLMs, Human Preference Alignment, CodeArena, SynCode-Instruct, Open Source vs Proprietary LLMs
💡 Category: Natural Language Processing
🌟 Research Objective:
– To bridge the gap between model-generated responses and human preferences in code large language models (codeLLMs).
🛠️ Research Methods:
– Introduced CodeArena, a human-curated benchmark containing 397 high-quality samples across 40 categories and 44 programming languages.
– Developed a diverse synthetic instruction corpus, SynCode-Instruct, with nearly 20 billion tokens for large-scale synthetic instruction fine-tuning.
💬 Research Conclusions:
– Highlighted the performance disparities between execution-based benchmarks and CodeArena.
– Identified a notable performance gap between open state-of-the-art (SOTA) code LLMs and proprietary models, emphasizing the importance of aligning with human preferences.
👉 Paper link: https://huggingface.co/papers/2412.05210

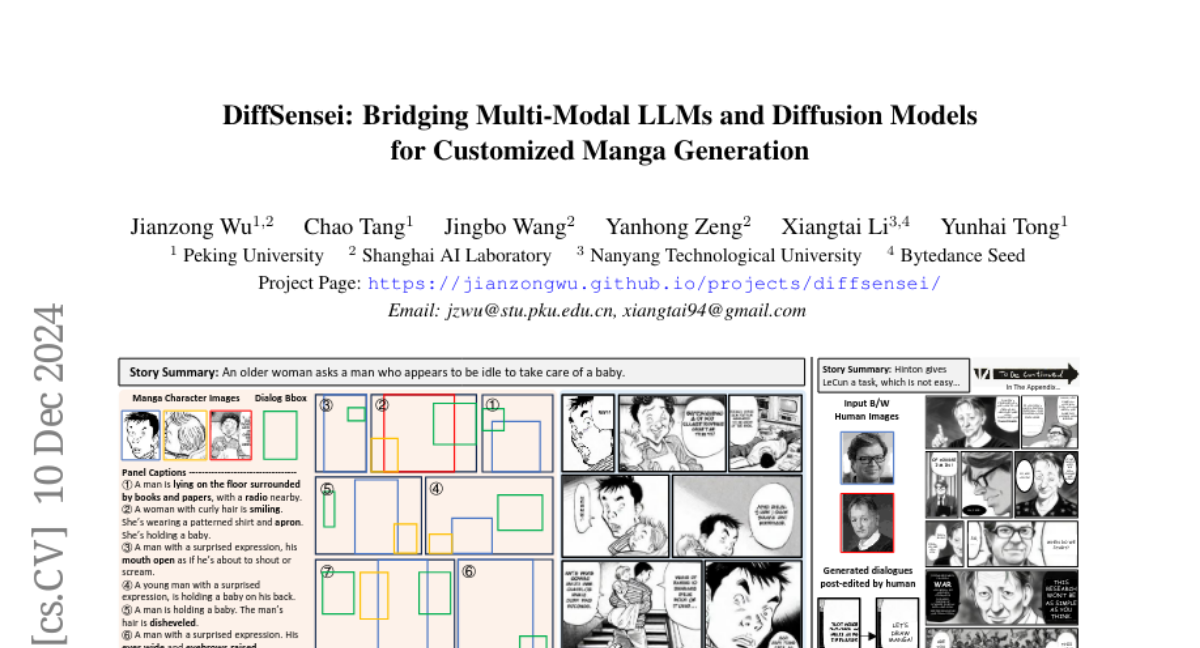
2. DiffSensei: Bridging Multi-Modal LLMs and Diffusion Models for Customized Manga Generation
🔑 Keywords: Story visualization, text-to-image generation, DiffSensei, Multimodal large language model, MangaZero
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to address the limitations of current text-to-image generation models, specifically their lack of effective control over character appearances and interactions in multi-character scenes.
🛠️ Research Methods:
– Introduces DiffSensei, a framework integrating a diffusion-based image generator with a multimodal large language model for dynamic multi-character control.
– Employs masked cross-attention to incorporate character features seamlessly, achieving precise layout control.
– Uses a dataset, MangaZero, with 43,264 manga pages and 427,147 annotated panels, supporting visualization of varied character interactions.
💬 Research Conclusions:
– DiffSensei significantly outperforms existing models, advancing manga generation by enabling text-adaptable character customization.
👉 Paper link: https://huggingface.co/papers/2412.07589
3. STIV: Scalable Text and Image Conditioned Video Generation
🔑 Keywords: video generation, Diffusion Transformer (DiT), text-to-video (T2V), image-text conditional, STIV
💡 Category: Generative Models
🌟 Research Objective:
– The study systematically explores the development of robust and scalable video generation models through the interaction of model architectures, training methods, and data strategies, resulting in the creation of STIV.
🛠️ Research Methods:
– STIV integrates image and text conditioning within a Diffusion Transformer using techniques like frame replacement and joint image-text conditional classifier-free guidance, enabling tasks like T2V and TI2V.
💬 Research Conclusions:
– STIV demonstrates strong performance in tasks such as T2V and TI2V, achieving state-of-the-art results on VBench metrics and outperforming existing open and closed-source models.
👉 Paper link: https://huggingface.co/papers/2412.07730

4. UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics
🔑 Keywords: UniReal, image generation, editing tasks, video generation
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces UniReal, a framework for unifying image generation and editing tasks by leveraging principles from video generation models.
🛠️ Research Methods:
– UniReal treats image-level tasks as discontinuous video generation, using large-scale videos for scalable supervision and learning world dynamics.
💬 Research Conclusions:
– UniReal demonstrates advanced capabilities in handling complex visual elements like shadows, reflections, and object interactions, and shows potential for new applications.
👉 Paper link: https://huggingface.co/papers/2412.07774

5. Hidden in the Noise: Two-Stage Robust Watermarking for Images
🔑 Keywords: Deepfakes, Image Watermarking, Diffusion Model, Fourier Patterns
💡 Category: Generative Models
🌟 Research Objective:
– To develop a distortion-free image watermarking method that enhances robustness against forgery and removal attacks.
🛠️ Research Methods:
– Utilized a diffusion model to introduce a distortion-free watermarking technique based on initial noise, and proposed a two-stage framework involving noise augmentation with Fourier patterns for efficient detection.
💬 Research Conclusions:
– The proposed watermarking approach demonstrated state-of-the-art robustness to various attacks, improving the security of AI-generated content detection.
👉 Paper link: https://huggingface.co/papers/2412.04653

6. FiVA: Fine-grained Visual Attribute Dataset for Text-to-Image Diffusion Models
🔑 Keywords: text-to-image generation, visual attributes, image customization, FiVA dataset, FiVA-Adapter
💡 Category: Generative Models
🌟 Research Objective:
– To devise a more nuanced methodology for decomposing and adapting specific visual attributes such as lighting, texture, and dynamics in text-to-image generation.
🛠️ Research Methods:
– Development of a fine-grained visual attributes dataset (FiVA) and creation of a FiVA-Adapter framework for decoupling and adapting visual attributes from source images.
💬 Research Conclusions:
– The proposed framework allows users to selectively apply desired attributes, enhancing the customization and personalization of generated images.
👉 Paper link: https://huggingface.co/papers/2412.07674
7. OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations
🔑 Keywords: document content extraction, OmniDocBench, computer vision, large language models, retrieval-augmented generation
💡 Category: Computer Vision
🌟 Research Objective:
– Address the limitations in diversity and evaluation of current document parsing methods by introducing OmniDocBench.
🛠️ Research Methods:
– Develop a multi-source benchmark with a curated dataset of nine document types, 19 layout categories, and 14 attribute labels for comprehensive evaluation.
💬 Research Conclusions:
– OmniDocBench provides a robust evaluation framework, highlighting limitations of existing methods and fostering future advancements in document parsing technologies.
👉 Paper link: https://huggingface.co/papers/2412.07626

8. Perception Tokens Enhance Visual Reasoning in Multimodal Language Models
🔑 Keywords: Multimodal language models, depth estimation, object detection, perception tokens, AURORA
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address the limitations of Multimodal language models (MLMs) in visual perception tasks and improve their reasoning capabilities through the introduction of Perception Tokens and the AURORA training method.
🛠️ Research Methods:
– Introduction of Perception Tokens to assist MLMs in reasoning tasks by transforming image representations into tokenized formats.
– Implementation of the AURORA training method, which leverages VQVAE and adopts a multi-task training framework.
💬 Research Conclusions:
– AURORA shows significant improvements in counting benchmarks and relative depth estimations, outperforming traditional finetuning approaches, enhancing MLMs’ ability in visual reasoning beyond language-based tasks.
👉 Paper link: https://huggingface.co/papers/2412.03548

9. Video Motion Transfer with Diffusion Transformers
🔑 Keywords: DiTFlow, Diffusion Transformers, Attention Motion Flow, zero-shot motion transfer
💡 Category: Generative Models
🌟 Research Objective:
– Introduce DiTFlow for transferring motion from a reference video to a synthesized one using Diffusion Transformers.
🛠️ Research Methods:
– Process reference video with pre-trained DiT to analyze cross-frame attention maps and extract patch-wise motion signals (AMF).
– Guide latent denoising process without training using AMF loss and optimize transformer positional embeddings.
💬 Research Conclusions:
– DiTFlow outperforms recent methods across multiple metrics and human evaluations, enhancing zero-shot motion transfer capabilities.
👉 Paper link: https://huggingface.co/papers/2412.07776

10. ILLUME: Illuminating Your LLMs to See, Draw, and Self-Enhance
🔑 Keywords: ILLUME, multimodal understanding, image-text alignment, vision tokenizer, self-enhancing multimodal alignment
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper presents ILLUME, an advanced multimodal large language model, aiming to integrate seamless multimodal understanding and generation.
🛠️ Research Methods:
– The authors design a vision tokenizer that includes semantic information and implement a progressive multi-stage training approach, reducing necessary dataset size for pretraining.
– Introduces a novel self-enhancing multimodal alignment scheme for better synergy between understanding and generation capabilities.
💬 Research Conclusions:
– ILLUME competes effectively with current leading unified multimodal language models and specialized models in multimodal understanding, generation, and editing benchmarks, despite using a smaller dataset.
👉 Paper link: https://huggingface.co/papers/2412.06673

11. Granite Guardian
🔑 Keywords: Granite Guardian, risk detection, large language model, RAG-specific issues, responsible AI development
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– To introduce the Granite Guardian models for providing risk detection in prompts and responses, facilitating safe and responsible use with large language models.
🛠️ Research Methods:
– Training on a unique dataset combining human annotations from diverse sources and synthetic data to address risks like jailbreaks and retrieval-augmented generation-specific issues.
💬 Research Conclusions:
– Granite Guardian models are highly generalizable and competitive, achieving AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks, and are released as open-source to promote responsible AI development.
👉 Paper link: https://huggingface.co/papers/2412.07724

12. EMOv2: Pushing 5M Vision Model Frontier
🔑 Keywords: Lightweight models, Efficiency, Dense predictions, EMOv2
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to develop parameter-efficient and lightweight models, particularly focusing on dense predictions with a model size of approximately 5M.
🛠️ Research Methods:
– Introduction of a Meta Mobile Block (MMBlock) for lightweight model design, extending concepts from IRB and Transformer for CNN and attention-based models.
– Creation of Improved Inverted Residual Mobile Block (i2RMB) and a hierarchical Efficient Model (EMOv2) without complex structures.
– Experiments on various tasks such as vision recognition, dense prediction, and image generation using these novel approaches.
💬 Research Conclusions:
– The EMOv2 models outperform state-of-the-art CNN and attention-based models, notably achieving higher Top-1 accuracy on various benchmarks.
– EMOv2-5M equipped RetinaNet achieves superior object detection performance, showing a considerable improvement over previous models, confirming the efficiency and robustness of lightweight models at the 5M magnitude.
👉 Paper link: https://huggingface.co/papers/2412.06674

13. ObjCtrl-2.5D: Training-free Object Control with Camera Poses
🔑 Keywords: Object Control, 3D Trajectory, Image-to-Video Generation, ObjCtrl-2.5D, Camera Motion Control
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to achieve more precise and versatile object control in image-to-video (I2V) generation by using 3D trajectories to capture spatial movements.
🛠️ Research Methods:
– ObjCtrl-2.5D, a training-free approach, models object movement as camera movement and uses a 3D trajectory with depth information for controlling object motion without additional training.
💬 Research Conclusions:
– ObjCtrl-2.5D significantly enhances object control accuracy and provides diverse control capabilities, surpassing traditional methods and enabling complex effects such as object rotation.
👉 Paper link: https://huggingface.co/papers/2412.07721
14. Fully Open Source Moxin-7B Technical Report
🔑 Keywords: Large Language Models, Open-source LLMs, Model Openness Framework, Moxin 7B
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Moxin 7B, a fully open-source Large Language Model adhering to Model Openness Framework principles.
🛠️ Research Methods:
– Comprehensive release of pre-training code, configurations, datasets, and checkpoints to achieve the highest MOF classification level.
💬 Research Conclusions:
– Moxin 7B demonstrates superior performance in zero-shot evaluations and competitive performance in few-shot evaluations compared to popular 7B models.
👉 Paper link: https://huggingface.co/papers/2412.06845

15. Frame Representation Hypothesis: Multi-Token LLM Interpretability and Concept-Guided Text Generation
🔑 Keywords: Interpretability, Large Language Models, Frame Representation Hypothesis, Linear Representation Hypothesis, Concept-Guided Decoding
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance interpretability and control of Large Language Models by extending the Linear Representation Hypothesis to multi-token words.
🛠️ Research Methods:
– Proposing the Frame Representation Hypothesis and introducing Top-k Concept-Guided Decoding to interpret and manipulate LLM text generation by modeling multi-token word relationships.
💬 Research Conclusions:
– Demonstrated on the Llama 3.1, Gemma 2, and Phi 3 models, revealing both biases and the potential to address harmful content, ultimately promoting safer and more transparent LLMs.
👉 Paper link: https://huggingface.co/papers/2412.07334

16. A New Federated Learning Framework Against Gradient Inversion Attacks
🔑 Keywords: Federated Learning, Gradient Inversion Attacks, Privacy-preserving Methods, Hypernetwork, Secure Multi-party Computing
💡 Category: Machine Learning
🌟 Research Objective:
– To develop a novel privacy-preserving FL framework that mitigates privacy exposure by breaking the direct connection between shared parameters and local private data.
🛠️ Research Methods:
– Design and implementation of the Hypernetwork Federated Learning (HyperFL) framework, which uses hypernetworks to generate local model parameters and only uploads hypernetwork parameters for aggregation.
💬 Research Conclusions:
– HyperFL demonstrates effective privacy-preserving capabilities against Gradient Inversion Attacks and achieves comparable performance based on theoretical analyses and extensive experimental results.
👉 Paper link: https://huggingface.co/papers/2412.07187

17. Chimera: Improving Generalist Model with Domain-Specific Experts
🔑 Keywords: Large Multi-modal Models, domain-specific tasks, Chimera, Generalist-Specialist Collaboration Masking
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to enhance the capabilities of Large Multi-modal Models (LMMs) for domain-specific tasks by integrating domain-specific knowledge from expert models.
🛠️ Research Methods:
– A progressive training strategy was designed to incorporate features from domain-specific expert models into the generalist LMMs.
– The Generalist-Specialist Collaboration Masking (GSCM) mechanism was introduced to address imbalanced optimization.
💬 Research Conclusions:
– The resulting model demonstrates versatility and achieves state-of-the-art performance in domains like charts, tables, math, and documents, particularly excelling in multi-modal reasoning and visual content extraction tasks.
👉 Paper link: https://huggingface.co/papers/2412.05983

18. Maximizing Alignment with Minimal Feedback: Efficiently Learning Rewards for Visuomotor Robot Policy Alignment
🔑 Keywords: Visuomotor robot policies, Human feedback, Reinforcement learning, Preference-based learning, Robot embodiments
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper aims to align pre-trained visuomotor robot policies with end-user preferences, addressing challenges in specifying these preferences.
🛠️ Research Methods:
– The study introduces Representation-Aligned Preference-based Learning (RAPL), an observation-only approach to learn visual rewards with reduced human feedback, focusing on aligning vision encoders with user visual representation through feature matching.
💬 Research Conclusions:
– RAPL effectively reduces the need for human feedback by 5x in aligning robot policies while maintaining alignment with human preferences and is validated across simulations and hardware experiments.
👉 Paper link: https://huggingface.co/papers/2412.04835

19. 3DTrajMaster: Mastering 3D Trajectory for Multi-Entity Motion in Video Generation
🔑 Keywords: 3D motions, multi-entity, controllable video generation, 6DoF pose, self-attention
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to effectively manipulate multi-entity 3D motions in video generation using 3D control signals, overcoming the limitations of 2D control signals.
🛠️ Research Methods:
– Introduction of **3DTrajMaster**, which regulates dynamics in 3D space utilizing 6 degrees of freedom (6DoF) pose sequences.
– Utilization of a 3D-motion grounded object injector with a gated self-attention mechanism to fuse entities with their 3D trajectories.
– Incorporation of a domain adaptor and annealed sampling strategy to improve video quality and generalization.
💬 Research Conclusions:
– Construction of a new **360-Motion Dataset** to address the lack of suitable training data.
– Extensive experiments demonstrate that **3DTrajMaster** achieves state-of-the-art performance in accuracy and generalization for controlling multi-entity 3D motions.
👉 Paper link: https://huggingface.co/papers/2412.07759
