AI Native Daily Paper Digest – 20241216

1. Apollo: An Exploration of Video Understanding in Large Multimodal Models
🔑 Keywords: Large Multimodal Models, video understanding, Apollo, Scaling Consistency, video-LMMs
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to uncover the effective drivers of video understanding in Large Multimodal Models (LMMs) and addresses the challenges of high computational costs and limited open research in the development of video-LMMs.
🛠️ Research Methods:
– The research examines primary contributors to computational requirements, identifies Scaling Consistency in design and training decisions, and explores video-specific aspects like video sampling and architecture. Key insights are utilized to improve the model design.
💬 Research Conclusions:
– The introduction of Apollo, a state-of-the-art family of LMMs, demonstrates superior performance across different model sizes. Apollo-3B and Apollo-7B models outperform comparable models on benchmarks such as LongVideoBench and MLVU.
👉 Paper link: https://huggingface.co/papers/2412.10360

2. GenEx: Generating an Explorable World
🔑 Keywords: GenEx, generative imagination, 3D environment, embodied AI, AI Native
💡 Category: Generative Models
🌟 Research Objective:
– The main aim of the paper is to introduce GenEx, a system developed to enable complex exploration and navigation in 3D physical environments by leveraging generative imagination.
🛠️ Research Methods:
– GenEx creates 3D-consistent imaginative environments from a single RGB image, using scalable 3D world data from Unreal Engine. It integrates continuous 360-degree capture to offer AI agents a broad environment for interaction.
💬 Research Conclusions:
– GenEx demonstrates high-quality world generation with robust loop consistency and 3D mapping capabilities. It provides a platform that enhances the capabilities of GPT-assisted agents, allowing them to perform complex tasks and refine decision-making in both virtual and real-world settings.
👉 Paper link: https://huggingface.co/papers/2412.09624
3. SynerGen-VL: Towards Synergistic Image Understanding and Generation with Vision Experts and Token Folding
🔑 Keywords: Large Language Models, Multimodal Large Language Models, encoder-free, image understanding, SynerGen-VL
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary objective of the research is to develop a simplified yet effective Multimodal Large Language Model (MLLM) capable of both image understanding and generation, addressing challenges in existing MLLMs.
🛠️ Research Methods:
– The study introduces SynerGen-VL, an encoder-free model, utilizing a token folding mechanism and a vision-expert-based progressive alignment pretraining strategy to support high-resolution image understanding and mitigate training complexity.
💬 Research Conclusions:
– SynerGen-VL demonstrates its capability by achieving or surpassing existing encoder-free unified MLLMs in performance with comparable or smaller parameter sizes, bringing it closer to task-specific state-of-the-art models and highlighting its potential in developing future unified MLLMs.
👉 Paper link: https://huggingface.co/papers/2412.09604

4. BiMediX2: Bio-Medical EXpert LMM for Diverse Medical Modalities
🔑 Keywords: BiMediX2, bilingual, multi-modal model, medical applications, multilingual
💡 Category: AI in Healthcare
🌟 Research Objective:
– The paper introduces BiMediX2, a bilingual (Arabic-English) large multimodal model aimed at integrating text and visual modalities for advanced medical image understanding and applications.
🛠️ Research Methods:
– BiMediX2 is built on the Llama3.1 architecture and trained on an extensive bilingual healthcare dataset consisting of 1.6M samples, integrating both image and text modalities to support multi-turn conversations involving medical images.
💬 Research Conclusions:
– BiMediX2 achieves state-of-the-art performance across several medical benchmarks, showing significant improvements over existing models, including a 9% improvement in factual accuracy evaluations over GPT-4.
👉 Paper link: https://huggingface.co/papers/2412.07769

5. Large Action Models: From Inception to Implementation
🔑 Keywords: Large Action Models, AI Native, artificial general intelligence, agent systems
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to transition from Large Language Models (LLMs) to Large Action Models (LAMs) for intelligent agents capable of real-world actions.
🛠️ Research Methods:
– It provides a comprehensive framework for developing LAMs, including data collection, model training, environment integration, grounding, and evaluation, exemplified with a Windows OS-based agent.
💬 Research Conclusions:
– The study identifies limitations of current LAMs and suggests future research and industrial deployment directions, highlighting challenges and opportunities in real-world applications.
👉 Paper link: https://huggingface.co/papers/2412.10047

6. InstanceCap: Improving Text-to-Video Generation via Instance-aware Structured Caption
🔑 Keywords: Text-to-video generation, instance-aware, structured caption, fidelity, hallucinations
💡 Category: Generative Models
🌟 Research Objective:
– To develop a novel instance-aware structured caption framework, InstanceCap, aiming for instance-level and fine-grained video captions to enhance generation fidelity and reduce hallucinations.
🛠️ Research Methods:
– Design of an auxiliary models cluster that converts videos into detailed instances, refining dense prompts into precise descriptions, supported by a curated 22K InstanceVid dataset.
💬 Research Conclusions:
– The InstanceCap framework significantly outperforms previous models, ensuring high fidelity between captions and videos while effectively reducing hallucinations.
👉 Paper link: https://huggingface.co/papers/2412.09283

7. FreeScale: Unleashing the Resolution of Diffusion Models via Tuning-Free Scale Fusion
🔑 Keywords: Visual diffusion models, high-resolution generation, tuning-free strategies, FreeScale
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to address the limitations of current visual diffusion models in generating high-fidelity images at higher resolutions by proposing a new approach.
🛠️ Research Methods:
– The introduction of FreeScale, a tuning-free inference paradigm, which processes information from different receptive scales and fuses it through extraction of desired frequency components.
💬 Research Conclusions:
– FreeScale significantly enhances the capability of generating higher-resolution images and videos, achieving 8k-resolution image generation, surpassing previous methods.
👉 Paper link: https://huggingface.co/papers/2412.09626

8. ObjectMate: A Recurrence Prior for Object Insertion and Subject-Driven Generation
🔑 Keywords: Object Insertion, Subject-Driven Generation, Photorealistic Composition, Identity Preservation, Tuning-Free
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a tuning-free method for object insertion and subject-driven generation that achieves seamless photorealistic composition and preserves object identity.
🛠️ Research Methods:
– Leverage large unlabeled datasets to retrieve diverse views of the same object to enable massive supervision.
– Utilize a text-to-image diffusion architecture for mapping object and scene descriptions to composited images without requiring test-time tuning.
💬 Research Conclusions:
– The proposed method, ObjectMate, demonstrates superior identity preservation and more photorealistic composition compared to state-of-the-art references, without the need for tuning.
👉 Paper link: https://huggingface.co/papers/2412.08645
9. FireFlow: Fast Inversion of Rectified Flow for Image Semantic Editing
🔑 Keywords: Rectified Flows, FireFlow, Inversion, Editing, Zero-shot
💡 Category: Generative Models
🌟 Research Objective:
– Introduce FireFlow to enhance the inversion and editing capabilities of ReFlow-based models while maintaining fast sampling.
🛠️ Research Methods:
– Utilize a carefully designed numerical solver for accurate inversion with a second-order precision and first-order efficiency, achieving a 3x runtime speedup.
💬 Research Conclusions:
– FireFlow enables smaller reconstruction errors and superior editing results in a training-free mode, significantly improving over existing ReFlow inversion techniques.
👉 Paper link: https://huggingface.co/papers/2412.07517

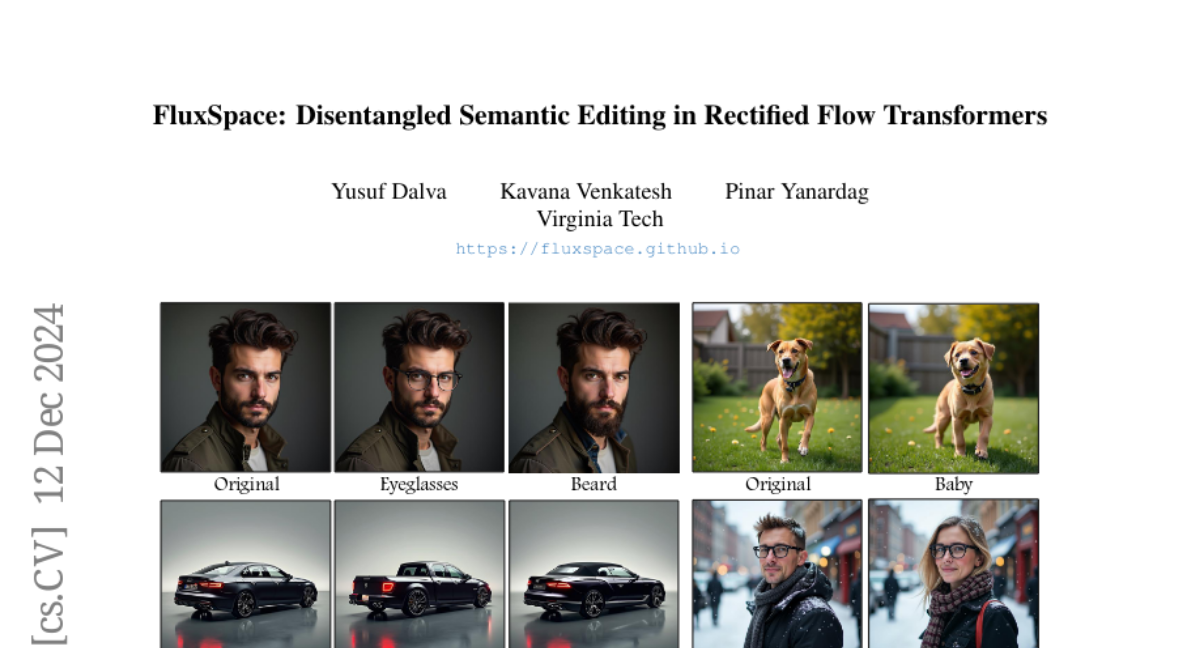
10. FluxSpace: Disentangled Semantic Editing in Rectified Flow Transformers
🔑 Keywords: Rectified flow models, Image generation, Disentangled editing, Semantically interpretable, FluxSpace
💡 Category: Generative Models
🌟 Research Objective:
– To introduce FluxSpace, a domain-agnostic image editing method leveraging rectified flow models for semantically interpretable modifications.
🛠️ Research Methods:
– Utilize representation space within rectified flow transformers and propose a set of semantically interpretable representations for broad image editing tasks.
💬 Research Conclusions:
– FluxSpace provides a scalable and effective approach to image editing, enabling precise, attribute-specific modification without affecting unrelated image aspects.
👉 Paper link: https://huggingface.co/papers/2412.09611
11. SCBench: A KV Cache-Centric Analysis of Long-Context Methods
🔑 Keywords: Long-context LLMs, KV cache, SCBench, Sparse attention, Dynamic sparsity
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to introduce SCBench, a comprehensive benchmark for evaluating long-context methods from a KV cache-centric perspective, addressing challenges in computational and memory efficiency.
🛠️ Research Methods:
– SCBench evaluates long-context LLMs with test examples across 12 tasks, employing shared context modes in four categories: string retrieval, semantic retrieval, global information, and multi-task, involving KV cache generation, compression, retrieval, and loading.
💬 Research Conclusions:
– Findings reveal that sub-O(n) memory methods struggle in multi-turn scenarios, while sparse encoding with O(n) memory and sub-O(n^2) pre-filling computation are robust. Dynamic sparsity provides more expressive KV caches, and layer-level sparsity in hybrid architectures reduces memory usage with strong performance. Attention distribution shift issues are identified in long-generation scenarios.
👉 Paper link: https://huggingface.co/papers/2412.10319

12. Multimodal Music Generation with Explicit Bridges and Retrieval Augmentation
🔑 Keywords: Multimodal Music Generation, Visuals Music Bridge, Cross-modal Alignment, Controllability
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance multimodal music generation by addressing challenges in data scarcity, cross-modal alignment, and controllability.
🛠️ Research Methods:
– Introduces the Visuals Music Bridge (VMB), which employs a Multimodal Music Description Model and a Dual-track Music Retrieval module to improve alignment and user control.
– Develops an Explicitly Conditioned Music Generation framework using text and music bridges.
💬 Research Conclusions:
– The proposed VMB significantly improves music quality, alignment, and customization in comparison to previous methods, setting a new standard for interpretable and expressive multimodal music generation.
👉 Paper link: https://huggingface.co/papers/2412.09428

13. LinGen: Towards High-Resolution Minute-Length Text-to-Video Generation with Linear Computational Complexity
🔑 Keywords: Text-to-video generation, LinGen framework, Computational cost, Self-attention, Video quality
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to create a Linear-complexity text-to-video Generation (LinGen) framework that allows for high-resolution minute-length video generation on a single GPU without compromising quality.
🛠️ Research Methods:
– LinGen replaces the computationally intensive self-attention block with a linear-complexity MATE block, composed of the MA-branch for short-to-long-range correlations and the TE-branch for temporal correlations. This method significantly reduces the quadratic computational cost to linear.
💬 Research Conclusions:
– LinGen significantly outperforms existing Diffusion Transformers (DiTs) in video quality while reducing FLOPs and latency by up to 15 and 11.5 times, respectively. It achieves better or comparable quality to state-of-the-art models and facilitates longer video generation, showcased on their project website.
👉 Paper link: https://huggingface.co/papers/2412.09856
14. SmolTulu: Higher Learning Rate to Batch Size Ratios Can Lead to Better Reasoning in SLMs
🔑 Keywords: SmolTulu-1.7b-Instruct, AI Native, instruction-tuned language model, optimization dynamics
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study presents SmolTulu-1.7b-Instruct, an instruction-tuned language model designed to enhance performance of sub-2B parameter models in instruction following and reasoning tasks.
🛠️ Research Methods:
– The researchers used a comprehensive empirical analysis with a 135M parameter model to explore the relationship between learning rate and batch size, and their impact on task-specific model performance.
💬 Research Conclusions:
– The study concludes that higher learning rate to batch size ratios benefit reasoning tasks, while lower ratios optimize pattern recognition tasks. The resulting model, SmolTulu, achieved state-of-the-art performance on various benchmarks, providing valuable insights for efficient language model alignment.
👉 Paper link: https://huggingface.co/papers/2412.08347

15. TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
🔑 Keywords: VLA models, visual trace prompting, robot manipulation, spatial-temporal dynamics
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To enhance the spatial-temporal awareness of vision-language-action models in robotic learning for improved action prediction.
🛠️ Research Methods:
– Introduced a technique called visual trace prompting to encode state-action trajectories visually and developed a new TraceVLA model by finetuning OpenVLA on a custom dataset of 150K robot manipulation trajectories.
💬 Research Conclusions:
– TraceVLA achieved state-of-the-art performance, outperforming previous models by significant margins in various setups, demonstrating robust generalization across diverse settings. A compact VLA model shows enhanced inference efficiency while maintaining competitive performance compared to larger models.
👉 Paper link: https://huggingface.co/papers/2412.10345

16. GReaTer: Gradients over Reasoning Makes Smaller Language Models Strong Prompt Optimizers
🔑 Keywords: Prompt Optimization, Large Language Models, Gradient Information, Self-Optimization, Transferability
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to enhance the performance of large language models by optimizing prompts using a novel technique that incorporates gradient information.
🛠️ Research Methods:
– Introduced a method called GReaTer that uses task loss gradients for self-optimizing prompts, enabling effective optimization for lightweight language models without relying on large LLMs.
💬 Research Conclusions:
– GReaTer outperforms existing prompt optimization methods, even those relying on large LLMs, and shows improved transferability and task performance, sometimes even surpassing larger models.
👉 Paper link: https://huggingface.co/papers/2412.09722

17. Efficient Generative Modeling with Residual Vector Quantization-Based Tokens
🔑 Keywords: Residual Vector Quantization, Generative Models, High-Fidelity, Image Generation, Text-to-Speech
💡 Category: Generative Models
🌟 Research Objective:
– To explore using Residual Vector Quantization for high-fidelity generation in vector-quantized generative models, focusing on maintaining higher data fidelity without compromising sampling speed.
🛠️ Research Methods:
– Introduced ResGen, an RVQ-based discrete diffusion model, with a focus on direct prediction of vector embedding of collective tokens and a token masking and multi-token prediction method framed within a probabilistic framework.
💬 Research Conclusions:
– ResGen outperforms autoregressive counterparts in conditional image generation on ImageNet and zero-shot text-to-speech synthesis, offering superior performance while maintaining sampling speed and enhanced generation fidelity when scaling RVQ depth.
👉 Paper link: https://huggingface.co/papers/2412.10208

18. Prompt2Perturb (P2P): Text-Guided Diffusion-Based Adversarial Attacks on Breast Ultrasound Images
🔑 Keywords: adversarial attacks, Prompt2Perturb, breast cancer diagnosis, medical imaging, state-of-the-art
💡 Category: AI in Healthcare
🌟 Research Objective:
– To improve the reliability and security of deep neural networks in breast cancer diagnosis by developing a novel language-guided attack method called Prompt2Perturb (P2P).
🛠️ Research Methods:
– Utilization of learnable prompts within the text encoder to generate imperceptible perturbations, guiding models towards targeted outcomes without retraining diffusion models.
– Optimization of early reverse diffusion steps to boost efficiency and maintain image quality in adversarial attacks.
💬 Research Conclusions:
– Prompt2Perturb (P2P) outperforms existing attack techniques on three breast ultrasound datasets, offering images that are more natural and effective.
– The method preserves ultrasound image quality while incorporating subtle noise, making it a viable tool for adversarial attacks in medical imaging.
👉 Paper link: https://huggingface.co/papers/2412.09910
