AI Native Daily Paper Digest – 20241220
1. Qwen2.5 Technical Report
🔑 Keywords: Qwen2.5, Large Language Models, Reinforcement Learning, Human Preference Alignment
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce Qwen2.5, a series of comprehensive large language models designed for various needs and demonstrating significant improvements in pre-training and post-training processes.
🛠️ Research Methods:
– Utilization of 18 trillion tokens in pre-training datasets to enhance common sense, expert knowledge, and reasoning capabilities.
– Implementation of intricate supervised finetuning with over 1 million samples and multistage reinforcement learning to enhance human preference alignment.
💬 Research Conclusions:
– Qwen2.5 LLM series demonstrate top-tier performance across diverse benchmarks, offering models like Qwen2.5-72B-Instruct, which competes with state-of-the-art models while being cost-effective.
– Introduction of proprietary models such as Qwen2.5-Turbo and Qwen2.5-Plus, which provide superior performance-to-cost ratios.
👉 Paper link: https://huggingface.co/papers/2412.15115

2. Progressive Multimodal Reasoning via Active Retrieval
🔑 Keywords: AR-MCTS, Active Retrieval, Monte Carlo Tree Search, multimodal reasoning, MLLMs
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance the reasoning capabilities of multimodal large language models (MLLMs) using a new framework, AR-MCTS, which integrates Active Retrieval and Monte Carlo Tree Search for improved multimodal reasoning.
🛠️ Research Methods:
– Development of a unified retrieval module for retrieving key insights from a hybrid-modal corpus.
– Use of Monte Carlo Tree Search algorithm combined with an active retrieval mechanism to generate step-wise annotations for multimodal reasoning.
– Introduction of a process reward model for automatic verification of reasoning tasks.
💬 Research Conclusions:
– The AR-MCTS framework effectively enhances the performance of various multimodal models by optimizing sampling diversity and accuracy in reasoning tasks.
– Experimental results show significant improvement across three complex multimodal reasoning benchmarks, confirming the reliability of the AR-MCTS approach.
👉 Paper link: https://huggingface.co/papers/2412.14835

3. MegaPairs: Massive Data Synthesis For Universal Multimodal Retrieval
🔑 Keywords: MegaPairs, Vision Language Models, Multimodal Retrieval, Data Synthesis
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce MegaPairs, a novel data synthesis method leveraging Vision Language Models and open-domain images to improve multimodal retrieval.
🛠️ Research Methods:
– Utilize MegaPairs to generate a massive synthetic dataset enhancing multimodal retriever performance compared to existing datasets with significantly more data.
💬 Research Conclusions:
– New models trained on MegaPairs demonstrate state-of-the-art zero-shot performance on popular benchmarks and notable performance improvements with fine-tuning.
👉 Paper link: https://huggingface.co/papers/2412.14475

4. LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks
🔑 Keywords: LongBench v2, LLMs, multitasks, reasoning, inference-time compute
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce LongBench v2, a benchmark for evaluating the ability of LLMs to solve long-context problems involving deep understanding and reasoning across various tasks.
🛠️ Research Methods:
– Collection of data from diverse professionals and employing both automated and manual review to maintain benchmark quality.
– Challenges include multiple-choice questions requiring reasoning across contexts up to 2M words.
💬 Research Conclusions:
– Human experts achieved 53.7% accuracy in solving these tasks within a time limit, while the best model achieved 57.7%, demonstrating the importance of reasoning and scalable compute to handle long-context challenges.
👉 Paper link: https://huggingface.co/papers/2412.15204

5. How to Synthesize Text Data without Model Collapse?
🔑 Keywords: Model collapse, Synthetic data, GPT-{n} models, Token editing, Distributional shift
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the impact of synthetic data on language model training and identify ways to synthesize data without causing model collapse.
🛠️ Research Methods:
– Pre-training language models with varying proportions of synthetic data and conducting statistical analysis to detect distributional shift and over-concentration of n-gram features; proposing token editing on human-produced data to create semi-synthetic data.
💬 Research Conclusions:
– Demonstrated that token-level editing can prevent model collapse by improving data quality, as evidenced by experiments showing enhanced model performance.
👉 Paper link: https://huggingface.co/papers/2412.14689

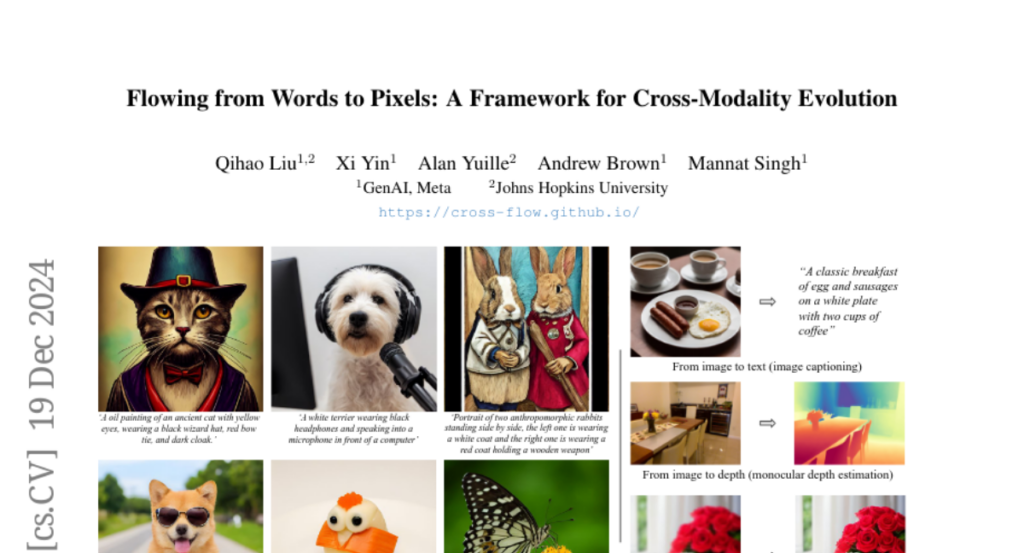
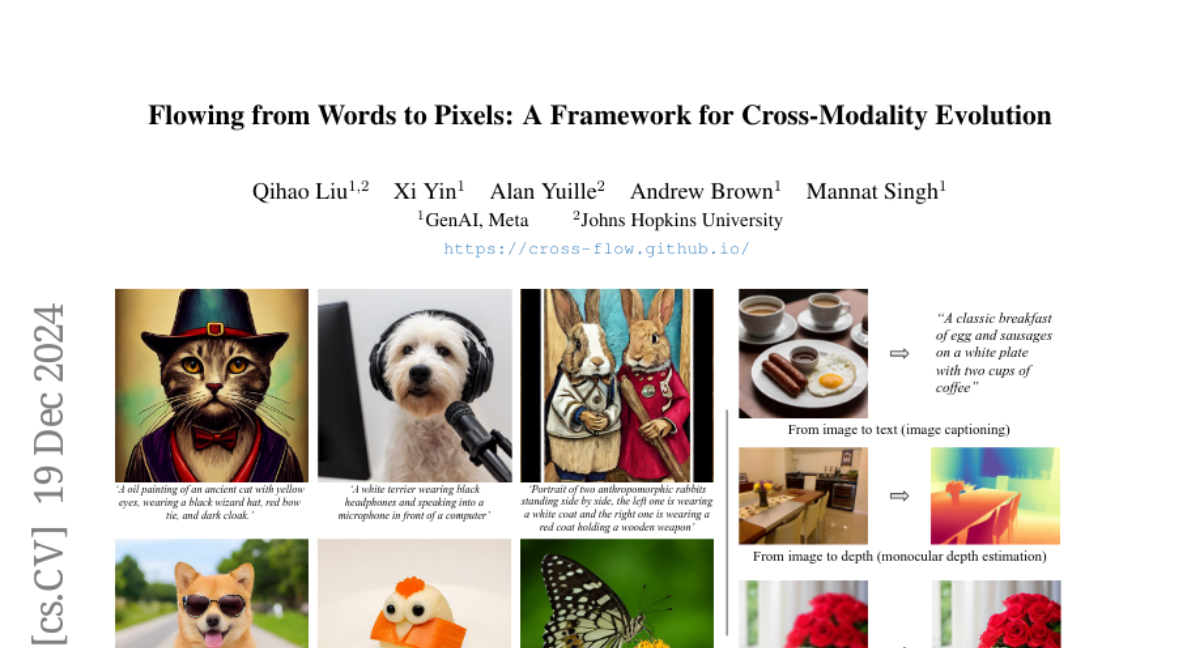
6. Flowing from Words to Pixels: A Framework for Cross-Modality Evolution
🔑 Keywords: Diffusion models, CrossFlow, flow matching, cross-modal tasks, Variational Encoders
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to explore the potential of training flow matching models to directly map one modality’s distribution to another, eliminating the need for noise distribution and conditioning mechanisms.
🛠️ Research Methods:
– The authors propose CrossFlow, a simple framework for cross-modal flow matching, incorporating Variational Encoders and a novel method for Classifier-free guidance.
💬 Research Conclusions:
– CrossFlow slightly outperforms standard flow matching in text-to-image tasks without cross attention, scales better with training steps and size, and facilitates meaningful latent arithmetic for semantic edits. It also matches or surpasses state-of-the-art results in tasks like image captioning, depth estimation, and image super-resolution.
👉 Paper link: https://huggingface.co/papers/2412.15213
7. Affordance-Aware Object Insertion via Mask-Aware Dual Diffusion
🔑 Keywords: Affordance, Image Composition, Mask-Aware Dual Diffusion, Generalization, SAM-FB dataset
💡 Category: Computer Vision
🌟 Research Objective:
– To expand the concept of Affordance from human-centered tasks to a general object-scene composition framework and define an affordance-aware object insertion task.
🛠️ Research Methods:
– Construction of the SAM-FB dataset with over 3 million examples spanning more than 3,000 object categories.
– Introduction of the Mask-Aware Dual Diffusion (MADD) model which employs a dual-stream architecture for denoising RGB images and insertion masks.
💬 Research Conclusions:
– The proposed method outperforms state-of-the-art methods and shows strong generalization capabilities on in-the-wild images.
👉 Paper link: https://huggingface.co/papers/2412.14462
8. LeviTor: 3D Trajectory Oriented Image-to-Video Synthesis
🔑 Keywords: 3D trajectory control, image-to-video synthesis, depth dimension, video diffusion model, LeviTor
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to enhance object trajectory control in image-to-video synthesis by integrating a depth dimension, facilitating more precise 3D movement control.
🛠️ Research Methods:
– The method involves abstracting object masks into cluster points with depth and instance information, which serve as control signals in a video diffusion model.
💬 Research Conclusions:
– The proposed LeviTor approach effectively manipulates object movements, producing photo-realistic videos from static images in a 3D context.
👉 Paper link: https://huggingface.co/papers/2412.15214

9. DI-PCG: Diffusion-based Efficient Inverse Procedural Content Generation for High-quality 3D Asset Creation
🔑 Keywords: Procedural Content Generation, Inverse PCG, Diffusion Transformer, 3D generation
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to improve the process of Procedural Content Generation (PCG) by developing an efficient method to automatically find the best parameters from general image conditions.
🛠️ Research Methods:
– The research introduces DI-PCG, a lightweight diffusion transformer model that treats PCG parameters as the denoising target and uses observed images to control parameter generation.
💬 Research Conclusions:
– DI-PCG demonstrates superior performance in accurately recovering parameters and generalizing to diverse images, validated through both quantitative and qualitative experiments.
👉 Paper link: https://huggingface.co/papers/2412.15200

10. AceMath: Advancing Frontier Math Reasoning with Post-Training and Reward Modeling
🔑 Keywords: AceMath, reward models, math reasoning, supervised fine-tuning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce AceMath, a suite of math models and reward models that solve complex math problems and evaluate solutions effectively.
🛠️ Research Methods:
– Implement a supervised fine-tuning process to develop instruction-tuned math models and create a robust benchmark, AceMath-RewardBench, for evaluating reward models.
💬 Research Conclusions:
– AceMath models outperform existing state-of-the-art models, achieving the highest average rm@8 score across math reasoning benchmarks.
👉 Paper link: https://huggingface.co/papers/2412.15084

11. TOMG-Bench: Evaluating LLMs on Text-based Open Molecule Generation
🔑 Keywords: Open Molecule Generation, Text-guided Discovery, Benchmark, LLMs, AI Native
💡 Category: Generative Models
🌟 Research Objective:
– The paper proposes TOMG-Bench, the first benchmark to evaluate the open-domain molecule generation capability of Large Language Models (LLMs).
🛠️ Research Methods:
– The benchmark includes three major tasks (molecule editing, optimization, and customized generation), with an automated evaluation system to assess quality and accuracy.
💬 Research Conclusions:
– The study highlights the limitations and potential improvements in text-guided molecule discovery, noting that Llama3.1-8B significantly outperforms other models, including GPT-3.5-turbo, by 46.5% on TOMG-Bench.
👉 Paper link: https://huggingface.co/papers/2412.14642

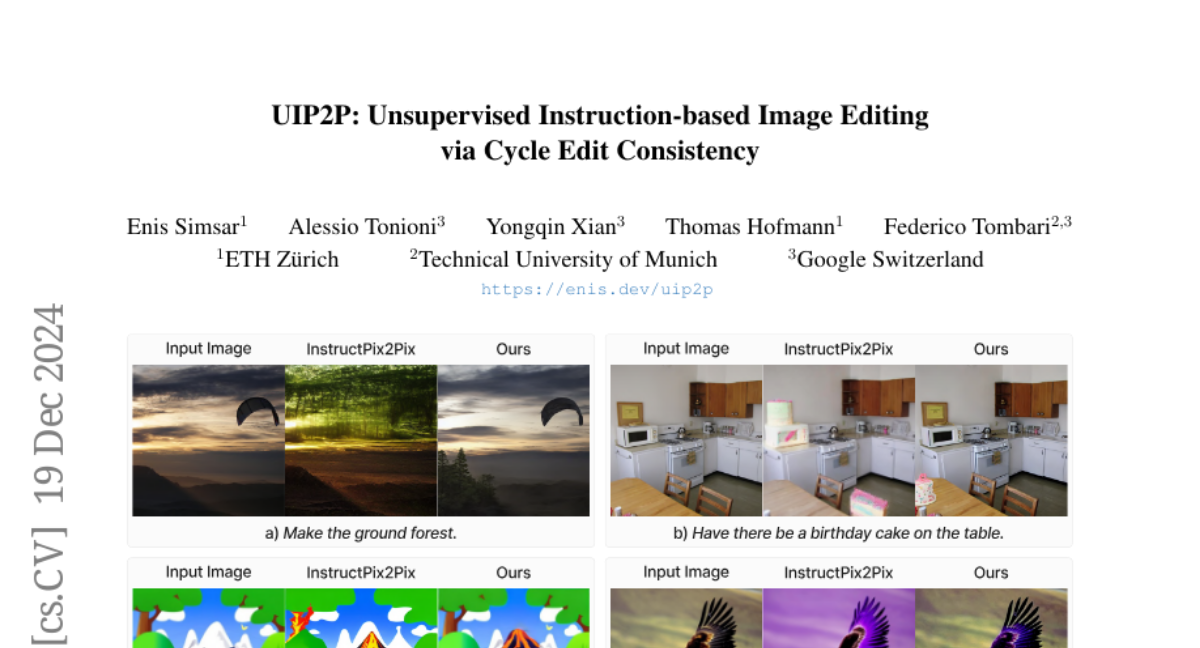
12. UIP2P: Unsupervised Instruction-based Image Editing via Cycle Edit Consistency
🔑 Keywords: Unsupervised Model, Instruction-based Image Editing, Cycle Edit Consistency, High Fidelity, Bias Reduction
💡 Category: Computer Vision
🌟 Research Objective:
– To develop an unsupervised model for instruction-based image editing that eliminates the need for ground-truth edited images during training.
🛠️ Research Methods:
– Introduction of Cycle Edit Consistency (CEC) mechanism which applies forward and backward edits enforcing consistency in image and attention spaces.
💬 Research Conclusions:
– The proposed method improves performance across a range of edits with high precision and fidelity, reducing biases associated with supervised methods and eliminating reliance on pre-existing triplet datasets.
👉 Paper link: https://huggingface.co/papers/2412.15216
13. Descriptive Caption Enhancement with Visual Specialists for Multimodal Perception
🔑 Keywords: Large Multimodality Models, Image Captioning, Visual Specialists, Visual Understanding, Descriptive Caption
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to improve image captioning by utilizing off-the-shelf visual specialists trained from annotated images, which are not initially intended for image captioning.
🛠️ Research Methods:
– The proposed approach, named DCE, incorporates object low-level and fine-grained attributes as well as object relations into descriptive captions.
💬 Research Conclusions:
– Incorporating visual specialists helps enhance performance in visual understanding tasks and reasoning by providing more accurate visual interpretations. The researchers plan to release the source code and pipeline for public use.
👉 Paper link: https://huggingface.co/papers/2412.14233

14. PixelMan: Consistent Object Editing with Diffusion Models via Pixel Manipulation and Generation
🔑 Keywords: Diffusion Models (DMs), consistent object editing, Pixel Manipulation, training-free methods
💡 Category: Computer Vision
🌟 Research Objective:
– To explore consistent object editing using Diffusion Models that maintain texture and attributes.
🛠️ Research Methods:
– Proposing an inversion-free, training-free method called PixelMan that uses Pixel Manipulation for direct duplication and inpainting to achieve consistency.
💬 Research Conclusions:
– PixelMan outperforms state-of-the-art methods in as few as 16 inference steps, requiring fewer steps than current methods.
👉 Paper link: https://huggingface.co/papers/2412.14283

15. Move-in-2D: 2D-Conditioned Human Motion Generation
🔑 Keywords: human motion sequence, scene image, diffusion model, video synthesis
💡 Category: Generative Models
🌟 Research Objective:
– To develop Move-in-2D, a method for generating diverse human motion sequences conditioned on a scene image.
🛠️ Research Methods:
– Utilizes a diffusion model integrating a scene image and text prompt to produce tailored human motion sequences.
– Collected a large-scale video dataset with annotated single-human activities for model training.
💬 Research Conclusions:
– The proposed method effectively predicts human motion aligned with scene images and enhances motion quality in video synthesis tasks.
👉 Paper link: https://huggingface.co/papers/2412.13185

16. DateLogicQA: Benchmarking Temporal Biases in Large Language Models
🔑 Keywords: DateLogicQA, temporal reasoning, Representation-Level Bias, Logical-Level Bias
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce DateLogicQA benchmark to evaluate various date formats, temporal contexts, and reasoning types.
🛠️ Research Methods:
– Propose Semantic Integrity Metric to assess tokenization quality and analyze two types of biases.
💬 Research Conclusions:
– Comprehensive evaluation of LLMs reveals their capabilities and limitations in handling temporal data accurately, highlighting challenges in temporal reasoning.
👉 Paper link: https://huggingface.co/papers/2412.13377

17. AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
🔑 Keywords: AV-Link, Video-to-Audio, Audio-to-Video, Diffusion Models, Cross-modal Conditioning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study proposes AV-Link, a unified framework for generating synchronized video-to-audio and audio-to-video content using frozen video and audio diffusion models.
🛠️ Research Methods:
– A Fusion Block is introduced to enable bidirectional information exchange between video and audio models through temporally-aligned self-attention, leveraging features from complementary modalities.
💬 Research Conclusions:
– AV-Link is demonstrated to achieve high-quality, synchronized audiovisual content, highlighting its potential in immersive media generation.
👉 Paper link: https://huggingface.co/papers/2412.15191
