AI Native Daily Paper Digest – 20241225

1. 3DGraphLLM: Combining Semantic Graphs and Large Language Models for 3D Scene Understanding
🔑 Keywords: 3D scene graph, Large Language Models, semantic relationships, user-robot interaction
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose a method, 3DGraphLLM, for constructing a learnable representation of a 3D scene graph to enhance the performance of Large Language Models in 3D vision-language tasks.
🛠️ Research Methods:
– Utilization of 3DGraphLLM to create learnable representations focused on both object semantics and coordinates, followed by testing on datasets such as ScanRefer, RIORefer, and Multi3DRefer.
💬 Research Conclusions:
– The proposed method outperforms baseline approaches that neglect semantic relationships, improving the quality of LLM responses in user-robot interaction contexts.
👉 Paper link: https://huggingface.co/papers/2412.18450

2. DepthLab: From Partial to Complete
🔑 Keywords: Depth Inpainting, Image Diffusion Priors, 3D Scene Generation, LiDAR Depth Completion
💡 Category: Computer Vision
🌟 Research Objective:
– To address the challenge of missing values in depth data and provide solutions for depth-deficient regions using the DepthLab model.
🛠️ Research Methods:
– Utilization of a foundation depth inpainting model powered by image diffusion priors, ensuring resilience and scale consistency in filling missing values.
💬 Research Conclusions:
– DepthLab outperforms existing solutions in numerical performance and visual quality, excelling in tasks such as 3D scene inpainting and LiDAR depth completion.
👉 Paper link: https://huggingface.co/papers/2412.18153
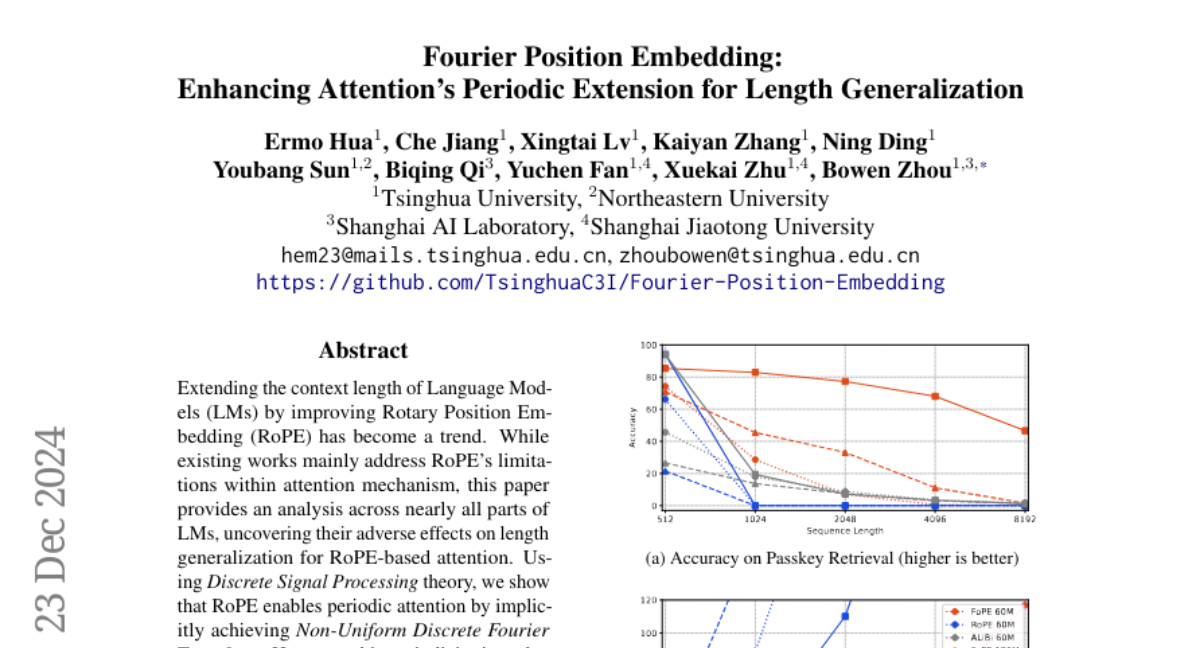
3. Fourier Position Embedding: Enhancing Attention’s Periodic Extension for Length Generalization
🔑 Keywords: RoPE, Fourier Position Embedding, Discrete Signal Processing, attention mechanism, length generalization
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to improve the length generalization of Rotary Position Embedding (RoPE) in Language Models by addressing its limitations and proposing enhancements.
🛠️ Research Methods:
– Utilizes Discrete Signal Processing theory to analyze RoPE across Language Models, introducing Fourier Position Embedding (FoPE) to address spectrum damage and enhance frequency domain properties.
💬 Research Conclusions:
– FoPE is shown to maintain more stable perplexity and consistent accuracy across different context windows compared to RoPE and ALiBi, enhancing model robustness.
👉 Paper link: https://huggingface.co/papers/2412.17739
4. DiTCtrl: Exploring Attention Control in Multi-Modal Diffusion Transformer for Tuning-Free Multi-Prompt Longer Video Generation
🔑 Keywords: Multi-Modal Diffusion Transformer, multi-prompt video generation, DiTCtrl, smooth transitions, MPVBench
💡 Category: Generative Models
🌟 Research Objective:
– To propose a training-free multi-prompt video generation method called DiTCtrl under the MM-DiT architecture to address the challenges in generating coherent scenes with multiple sequential prompts.
🛠️ Research Methods:
– Analysis of MM-DiT’s attention mechanism to enable mask-guided precise semantic control across different prompts for smooth multi-prompt video generation transitions without additional training.
– Development of a new benchmark, MPVBench, specifically designed to evaluate multi-prompt video generation performance.
💬 Research Conclusions:
– DiTCtrl achieves state-of-the-art performance in generating videos with smooth transitions and consistent object motion from multiple prompts, without needing additional training, as demonstrated by extensive experiments.
👉 Paper link: https://huggingface.co/papers/2412.18597

5. ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing
🔑 Keywords: Sparsely activated MoE, ReMoE, TopK routers, Differentiable, Scalability
💡 Category: Machine Learning
🌟 Research Objective:
– To develop a fully differentiable MoE architecture, ReMoE, that improves upon the traditional TopK routers by enhancing scalability and performance.
🛠️ Research Methods:
– Implemented ReMoE using ReLU as the router, replacing conventional TopK+Softmax routing.
– Introduced methods to regulate router sparsity and balance the load among experts.
💬 Research Conclusions:
– ReMoE outperforms traditional MoE models in performance and scalability across various model sizes and expert counts.
– Offers superior dynamic allocation capacity and domain specialization.
– Implementation is available on Megatron-LM GitHub repository.
👉 Paper link: https://huggingface.co/papers/2412.14711

6. In Case You Missed It: ARC ‘Challenge’ Is Not That Challenging
🔑 Keywords: ARC Challenge, LLMs, evaluation, OpenBookQA, reasoning deficits
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the perceived difficulty in ARC Challenge versus ARC Easy for modern language models due to evaluation setups.
🛠️ Research Methods:
– Analysis of evaluation practices and comparison of answer choices in benchmarks such as ARC and SIQA.
💬 Research Conclusions:
– Highlight that current evaluation practices can falsely suggest reasoning deficits; fairer evaluation methods can reduce performance gaps and achieve superhuman results.
👉 Paper link: https://huggingface.co/papers/2412.17758

7. SKETCH: Structured Knowledge Enhanced Text Comprehension for Holistic Retrieval
🔑 Keywords: Retrieval-Augmented Generation, SKETCH, semantic text retrieval, knowledge graphs
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to enhance the Retrieval-Augmented Generation (RAG) systems to process vast datasets more efficiently and maintain comprehensive context understanding.
🛠️ Research Methods:
– Introduces SKETCH, a novel methodology that integrates semantic text retrieval with knowledge graphs to merge structured and unstructured data for improved retrieval performance.
💬 Research Conclusions:
– SKETCH shows significant improvement over traditional methods in retrieval performance, answer relevancy, faithfulness, context precision, and context recall, especially noted on the Italian Cuisine dataset with high metrics scores.
👉 Paper link: https://huggingface.co/papers/2412.15443

8. PartGen: Part-level 3D Generation and Reconstruction with Multi-View Diffusion Models
🔑 Keywords: PartGen, 3D assets, multi-view diffusion model, 3D reconstruction
💡 Category: Generative Models
🌟 Research Objective:
– Introduce PartGen, a novel approach to generate 3D objects made of meaningful parts from text, image, or unstructured 3D objects.
🛠️ Research Methods:
– Utilize a multi-view diffusion model for plausible and view-consistent part segmentation and a second model for 3D reconstruction by completing occlusions.
💬 Research Conclusions:
– PartGen significantly outperforms baselines in segmentation and part-extraction and supports applications like 3D part editing.
👉 Paper link: https://huggingface.co/papers/2412.18608

9. MotiF: Making Text Count in Image Animation with Motion Focal Loss
🔑 Keywords: Text-Image-to-Video (TI2V), MotiF, motion heatmap, TI2V Bench
💡 Category: Generative Models
🌟 Research Objective:
– To improve video generation from images guided by text descriptions with a focus on enhancing text alignment and motion through the introduction of the MotiF approach.
🛠️ Research Methods:
– Utilization of optical flow to create a motion heatmap, adjusting loss based on motion intensity, complemented by proposing a diverse evaluation dataset, TI2V Bench.
💬 Research Conclusions:
– MotiF notably enhances performance over nine existing models, achieving a 72% preference in human evaluations, highlighting its effectiveness in generating well-aligned and dynamic videos.
👉 Paper link: https://huggingface.co/papers/2412.16153

10. Bridging the Data Provenance Gap Across Text, Speech and Video
🔑 Keywords: AI Native, Datasets, Multimodal, Data Sourcing, Responsible AI
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To conduct a comprehensive longitudinal audit of popular datasets across text, speech, and video modalities.
🛠️ Research Methods:
– Manual analysis of nearly 4000 public datasets globally sourced from 1990 to 2024.
💬 Research Conclusions:
– Web-crawled and social media platforms dominate dataset sources.
– Majority of datasets have non-commercial restrictions although few are restrictively licensed.
– Despite more languages and geographies in datasets, there is little improvement in their diverse representation since 2013.
👉 Paper link: https://huggingface.co/papers/2412.17847

11. Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning
🔑 Keywords: Large Language Models, Ensemble Methods, Monte Carlo Tree Search, Complex Reasoning, Markov Decision Process
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce LE-MCTS, a new framework for process-level ensembling of language models to improve performance on complex reasoning tasks.
🛠️ Research Methods:
– Formulate reasoning as a Markov decision process using an ensemble of language models, leveraging a Monte Carlo Tree Search guided by a process-based reward model.
💬 Research Conclusions:
– LE-MCTS outperforms existing ensemble and single model methods, with improvements of 3.6% and 4.3% on the MATH and MQA datasets, showcasing its effectiveness in complex reasoning.
👉 Paper link: https://huggingface.co/papers/2412.15797
