AI Native Daily Paper Digest – 20250122

1. Agent-R: Training Language Model Agents to Reflect via Iterative Self-Training
🔑 Keywords: Large Language Models, Intelligent Agent, Self-Training Framework, Error Correction, Reflection
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To develop an iterative self-training framework for Large Language Models that enhances error recovery and reflection abilities.
🛠️ Research Methods:
– Introduced Agent-R, which uses MCTS to construct training data, facilitating self-critique and error correction. The approach involves a model-guided critique construction mechanism to splice correct trajectories from erroneous ones.
💬 Research Conclusions:
– The proposed Agent-R framework demonstrates improved error correction capabilities, ensures timely intervention, and surpasses baseline methods in performance across three interactive environments.
👉 Paper link: https://huggingface.co/papers/2501.11425

2. MMVU: Measuring Expert-Level Multi-Discipline Video Understanding
🔑 Keywords: MMVU, expert-level reasoning, domain-specific knowledge, video understanding, System-2-capable models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce MMVU, a benchmark for evaluating expert-level multi-discipline video understanding models.
🛠️ Research Methods:
– Evaluate 32 multimodal foundation models using MMVU, with strict data quality controls and expert annotations across 27 subjects.
💬 Research Conclusions:
– System-2-capable models, o1 and Gemini 2.0, lead in performance but still do not match human expertise, highlighting areas for future improvement in specialized domain video analysis.
👉 Paper link: https://huggingface.co/papers/2501.12380

3. Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models
🔑 Keywords: Load-balancing Loss, Mixture-of-Experts, Global-batch, Domain Specialization
💡 Category: Natural Language Processing
🌟 Research Objective:
– This paper aims to improve the implementation of Load-balancing Loss (LBL) in training Mixture-of-Experts (MoEs) models by using a global-batch approach to enhance model performance and expert specialization.
🛠️ Research Methods:
– The authors propose calculating LBL using a global-batch across micro-batches and synchronizing frequency calculations of expert selections to encourage load balancing at the corpus level.
💬 Research Conclusions:
– The global-batch LBL strategy leads to significant performance improvements in pre-training perplexity and downstream tasks, as well as enhances the domain specialization of MoE experts.
👉 Paper link: https://huggingface.co/papers/2501.11873

4. TokenVerse: Versatile Multi-concept Personalization in Token Modulation Space
🔑 Keywords: TokenVerse, multi-concept personalization, DiT-based model
💡 Category: Generative Models
🌟 Research Objective:
– To develop TokenVerse, a framework enabling seamless multi-concept personalization in text-to-image generation.
🛠️ Research Methods:
– Utilized a DiT-based text-to-image diffusion model, leveraging both attention and modulation for localized control over complex concepts.
– Designed an optimization framework that identifies distinct directions in the modulation space for words extracted from image-text pairs.
💬 Research Conclusions:
– Demonstrated the effectiveness of TokenVerse in handling multiple and complex concepts for image generation, showing advantages over previous methods.
👉 Paper link: https://huggingface.co/papers/2501.12224
5. UI-TARS: Pioneering Automated GUI Interaction with Native Agents
🔑 Keywords: UI-TARS, Native GUI Agent, System-2 Reasoning, Iterative Training
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to introduce UI-TARS, a native GUI agent model that outperforms existing agent frameworks by perceiving screenshots and executing human-like interactions without the need for heavily wrapped models.
🛠️ Research Methods:
– UI-TARS utilizes enhanced perception, unified action modeling, system-2 reasoning, and iterative training with reflective online traces for improved performance and adaptability.
💬 Research Conclusions:
– UI-TARS demonstrates superior performance in 10+ GUI agent benchmarks, achieves state-of-the-art results in varying tasks, and learns from mistakes with minimal human intervention.
👉 Paper link: https://huggingface.co/papers/2501.12326

6. InternLM-XComposer2.5-Reward: A Simple Yet Effective Multi-Modal Reward Model
🔑 Keywords: Large Vision Language Models, Multi-Modal Reward Model, Reinforcement Learning, InternLM-XComposer2.5-Reward, Open-Sourcing
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve the alignment of Large Vision Language Models with human preferences using a multi-modal reward model.
🛠️ Research Methods:
– Developed InternLM-XComposer2.5-Reward using a high-quality multi-modal preference corpus; tested its robustness and versatility across diverse domains.
💬 Research Conclusions:
– IXC-2.5-Reward produced strong results on multi-modal reward benchmarks and demonstrated key applications, such as enhancing RL training and filtering noisy training data.
👉 Paper link: https://huggingface.co/papers/2501.12368

7. Mobile-Agent-E: Self-Evolving Mobile Assistant for Complex Tasks
🔑 Keywords: Mobile-Agent-E, large multimodal model, hierarchical multi-agent framework, self-evolution, Tips and Shortcuts
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To introduce Mobile-Agent-E, a hierarchical multi-agent framework designed to address limitations in current LMM-based mobile agents by enabling self-evolution and improving task execution on mobile devices.
🛠️ Research Methods:
– The proposed framework separates high-level planning and low-level action execution, involving components like a Manager for planning and subagents for perception, action execution, error verification, and information aggregation. It also includes a self-evolution module with Tips and Shortcuts.
💬 Research Conclusions:
– Mobile-Agent-E achieves significant performance improvements, with a 22% improvement over previous methods, and introduces a new benchmark, Mobile-Eval-E, for complex mobile tasks.
👉 Paper link: https://huggingface.co/papers/2501.11733

8. Reasoning Language Models: A Blueprint
🔑 Keywords: Reasoning language models, Large Reasoning Models, Reinforcement Learning, modular framework, prototyping
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to redefine and extend the problem-solving capabilities of Reasoning language models (RLMs) through a comprehensive modular framework.
🛠️ Research Methods:
– The paper organizes RLM components into a blueprint that incorporates diverse reasoning structures, strategies, and various reinforcement learning concepts, along with detailed formulations and algorithmic specifications.
💬 Research Conclusions:
– The proposed blueprint demonstrates versatility by unifying RLM structures and democratizes advanced reasoning capabilities, aiming to reduce the disparity between “rich AI” and “poor AI” by facilitating innovation and accessible RLM development.
👉 Paper link: https://huggingface.co/papers/2501.11223

9. Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
🔑 Keywords: Hunyuan3D 2.0, 3D synthesis, texture synthesis, diffusion transformer, AI Systems
💡 Category: Generative Models
🌟 Research Objective:
– To develop Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets.
🛠️ Research Methods:
– Utilized a scalable flow-based diffusion transformer for shape generation and leveraged strong geometric and diffusion priors for texture synthesis.
💬 Research Conclusions:
– Hunyuan3D 2.0 surpasses previous state-of-the-art models in geometry details, condition alignment, and texture quality, and it fills a gap in the open-source 3D community.
👉 Paper link: https://huggingface.co/papers/2501.12202

10. Learn-by-interact: A Data-Centric Framework for Self-Adaptive Agents in Realistic Environments
🔑 Keywords: Autonomous agents, Large Language Models (LLMs), Learn-by-interact, Synthetic data, In-context learning (ICL)
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To enhance LLM-powered autonomous agents’ capabilities by developing a data-centric framework, Learn-by-interact, without human annotations.
🛠️ Research Methods:
– Implement Learn-by-interact to synthesize trajectories of agent-environment interactions and construct instructions through backward construction.
– Conduct experiments on various environments to assess the framework’s effectiveness in enhancing downstream tasks.
💬 Research Conclusions:
– The application of Learn-by-interact leads to significant improvements in ICL and training scenarios. Backward construction plays a critical role, contributing to efficiency and effectiveness in synthetic data generation and retrieval processes.
👉 Paper link: https://huggingface.co/papers/2501.10893

11. Video Depth Anything: Consistent Depth Estimation for Super-Long Videos
🔑 Keywords: Depth Estimation, Temporal Consistency, Video Depth, Zero-Shot, Real-Time Performance
💡 Category: Computer Vision
🌟 Research Objective:
– The goal is to achieve high-quality, consistent depth estimation in super-long videos without sacrificing efficiency.
🛠️ Research Methods:
– Developed a model based on Depth Anything V2 with a spatial-temporal head and novel temporal consistency loss.
– Introduced a key-frame-based strategy for long video inference.
💬 Research Conclusions:
– The model demonstrates state-of-the-art performance in zero-shot video depth estimation on multiple benchmarks.
– Offers scalability with models of different sizes, supporting real-time performance at 30 FPS.
👉 Paper link: https://huggingface.co/papers/2501.12375

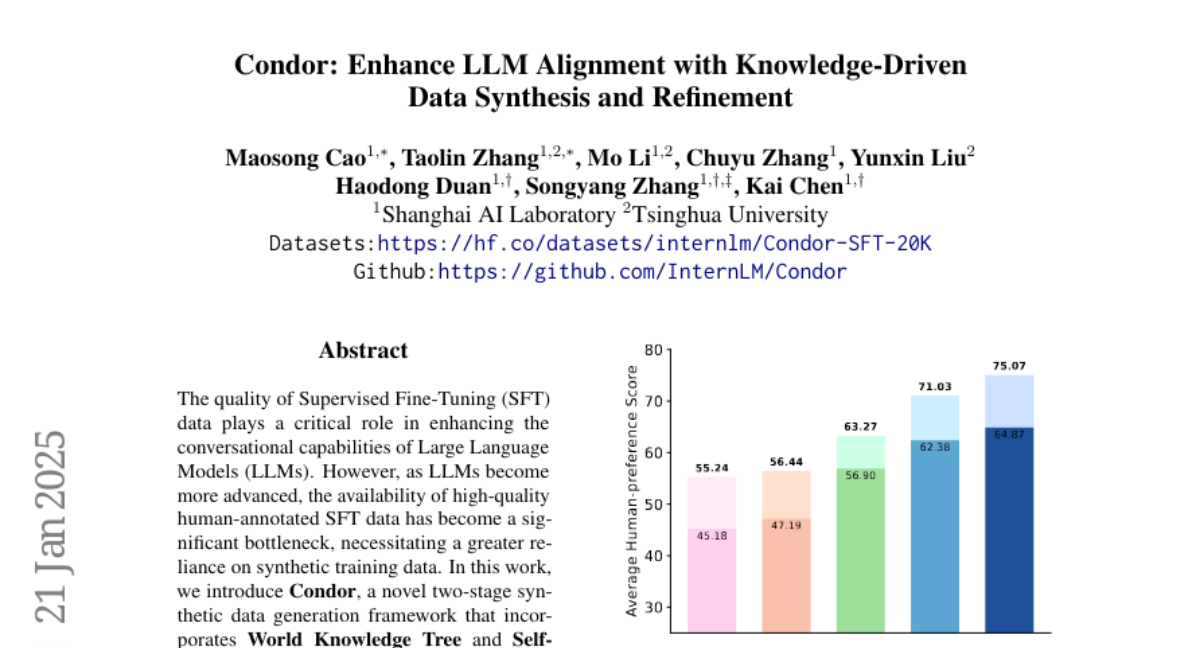
12. Condor: Enhance LLM Alignment with Knowledge-Driven Data Synthesis and Refinement
🔑 Keywords: Supervised Fine-Tuning, Large Language Models, Synthetic Data Generation, World Knowledge Tree, Self-Reflection Refinement
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce Condor, a two-stage synthetic data generation framework to enhance SFT data for LLMs.
🛠️ Research Methods:
– Incorporation of World Knowledge Tree and Self-Reflection Refinement stages to produce high-quality data at scale.
💬 Research Conclusions:
– Condor-generated samples enable superior performance and iterative self-improvement of LLMs, with promising potential for performance enhancements explored in synthetic data scaling.
👉 Paper link: https://huggingface.co/papers/2501.12273
13. Go-with-the-Flow: Motion-Controllable Video Diffusion Models Using Real-Time Warped Noise
🔑 Keywords: Generative modeling, Video diffusion models, Motion control, Noise warping, Temporal Gaussianity
💡 Category: Generative Models
🌟 Research Objective:
– Enhance video diffusion models for motion control through structured latent noise sampling.
🛠️ Research Methods:
– Implement a novel noise warping algorithm utilizing optical flow fields to achieve real-time motion control.
💬 Research Conclusions:
– The proposed approach offers effective motion control while maintaining high per-frame pixel quality in video diffusion models, as demonstrated by extensive experiments and user studies.
👉 Paper link: https://huggingface.co/papers/2501.08331

14. GPS as a Control Signal for Image Generation
🔑 Keywords: GPS tags, image generation, diffusion model, 3D models, GPS conditioning
💡 Category: Generative Models
🌟 Research Objective:
– To explore the use of GPS tags in photo metadata as a control signal for generating images.
🛠️ Research Methods:
– Training GPS-to-image models to generate images based on GPS and text inputs.
– Utilization of a diffusion model for image generation conditioned on geographical data and text.
💬 Research Conclusions:
– The model accurately generates images that reflect the unique characteristics of different city locations.
– GPS conditioning enhances the estimation of 3D structures from 2D models, showing improved accuracy in location-based image generation.
👉 Paper link: https://huggingface.co/papers/2501.12390

15. EMO2: End-Effector Guided Audio-Driven Avatar Video Generation
🔑 Keywords: Audio-driven, Gesture Generation, Diffusion Model, Talking Head
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a novel method for generating expressive talking heads with synchronized gestures and facial expressions driven by audio input.
🛠️ Research Methods:
– Redefining gesture generation as a two-stage process: first, hand poses are generated from audio input; second, a diffusion model synthesizes video frames incorporating these poses.
💬 Research Conclusions:
– The proposed method achieves superior performance over state-of-the-art techniques like CyberHost and Vlogger in terms of visual quality and synchronization accuracy.
👉 Paper link: https://huggingface.co/papers/2501.10687

16. MSTS: A Multimodal Safety Test Suite for Vision-Language Models
🔑 Keywords: Vision-language models, multimodal inputs, AI safety, chat assistants
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– To evaluate the safety of Vision-language models (VLMs) and identify novel risks associated with their multimodal inputs.
🛠️ Research Methods:
– Introduction of MSTS, a Multimodal Safety Test Suite for VLMs, comprising 400 test prompts across 40 hazard categories.
💬 Research Conclusions:
– Identified safety issues in several open VLMs, with some models being inadvertently safe due to misinterpretation of prompts.
– Translated MSTS into ten languages, revealing an increased rate of unsafe responses with non-English prompts.
– Models show safer outcomes when tested with text-only inputs.
👉 Paper link: https://huggingface.co/papers/2501.10057

17. The Geometry of Tokens in Internal Representations of Large Language Models
🔑 Keywords: Token Embeddings, Transformer Models, Empirical Measure, Cross-Entropy Loss
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore the relationship between the geometry of token embeddings and their role in next token prediction within transformer models.
🛠️ Research Methods:
– Metrics such as intrinsic dimension, neighborhood overlap, and cosine similarity are used to analyze empirical measures across layers. A dataset with shuffled tokens is used for comparison to validate the approach.
💬 Research Conclusions:
– The findings show a correlation between the geometric properties of token embeddings and the cross-entropy loss in next token predictions, indicating that prompts with higher loss values have tokens in higher-dimensional spaces.
👉 Paper link: https://huggingface.co/papers/2501.10573

18. Panoramic Interests: Stylistic-Content Aware Personalized Headline Generation
🔑 Keywords: Personalized Headline Generation, Stylistic-Content Preferences, Large Language Model, Contrastive Learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance personalized news headline generation by considering both the content and stylistic preferences of users.
🛠️ Research Methods:
– The authors propose the SCAPE framework, which leverages large language model collaboration and a contrastive learning-based hierarchical fusion network to extract and integrate users’ long- and short-term interests.
💬 Research Conclusions:
– Extensive experiments on the PENS dataset show that SCAPE significantly outperforms existing baseline methods in generating personalized headlines that reflect users’ comprehensive preferences.
👉 Paper link: https://huggingface.co/papers/2501.11900

19. Taming Teacher Forcing for Masked Autoregressive Video Generation
🔑 Keywords: MAGI, Video Generation, Complete Teacher Forcing, Autoregressive Generation
💡 Category: Generative Models
🌟 Research Objective:
– Introduce MAGI, a hybrid video generation framework with improved intra-frame and next-frame prediction.
🛠️ Research Methods:
– Combine masked modeling with causal modeling using the Complete Teacher Forcing (CTF) technique.
💬 Research Conclusions:
– MAGI significantly enhances video prediction with a +23% improvement in FVD scores over traditional methods and can generate coherent video sequences of over 100 frames from short training sequences.
👉 Paper link: https://huggingface.co/papers/2501.12389

20. Fixing Imbalanced Attention to Mitigate In-Context Hallucination of Large Vision-Language Model
🔑 Keywords: LVLMs, hallucination, attention patterns, visual grounding, MSCOCO
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Investigate and address hallucination behavior in Large Vision Language Models (LVLMs).
🛠️ Research Methods:
– Analyze attention patterns across transformer layers and apply a novel attention modification approach combining selective token emphasis and head-specific modulation.
– Introduce dual-stream token selection and attention head-specific modulation strategies.
💬 Research Conclusions:
– The proposed method reduces hallucination rates by up to 62.3% on the MSCOCO dataset without requiring model retraining, maintaining comparable task performance.
👉 Paper link: https://huggingface.co/papers/2501.12206
