AI Native Daily Paper Digest – 20250128
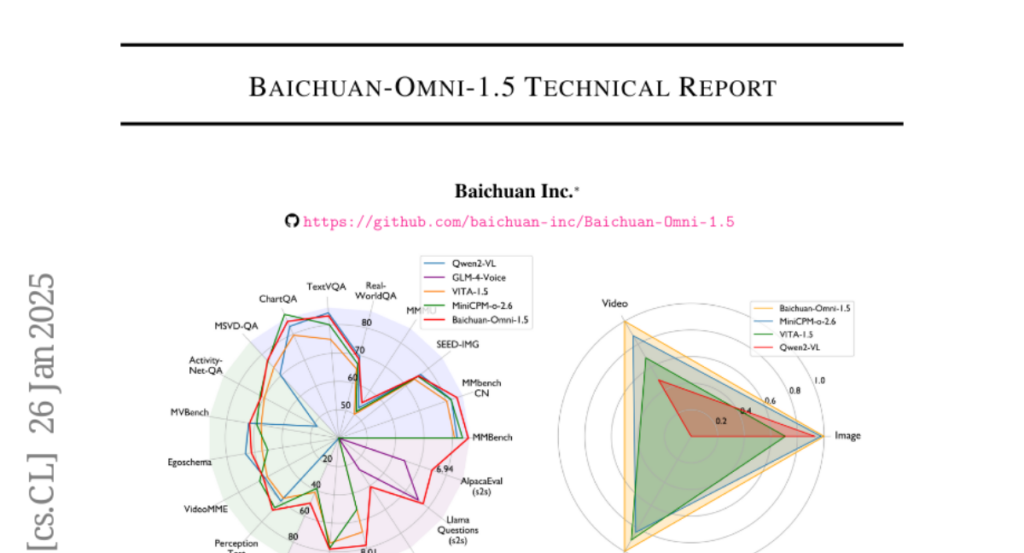
1. Baichuan-Omni-1.5 Technical Report
🔑 Keywords: Baichuan-Omni-1.5, omni-modal, audio generation, MLLM
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce Baichuan-Omni-1.5, a model with omni-modal understanding and end-to-end audio generation capabilities.
🛠️ Research Methods:
– Developed a data pipeline for multimodal data and created an audio-tokenizer for semantic and acoustic integration.
– Employed a multi-stage training strategy for multimodal alignment and multitask fine-tuning.
💬 Research Conclusions:
– Baichuan-Omni-1.5 surpasses contemporary models in omni-modal capabilities and performs comparably to leading models on multimodal medical benchmarks.
👉 Paper link: https://huggingface.co/papers/2501.15368
2. Qwen2.5-1M Technical Report
🔑 Keywords: Long-context capabilities, Long data synthesis, Inference framework, Sparse attention, Qwen2.5-1M
💡 Category: Natural Language Processing
🌟 Research Objective:
– To extend the context length capacity of models to 1 million tokens, enhancing their long-context processing ability while maintaining short-context performance.
🛠️ Research Methods:
– Implemented techniques such as long data synthesis, progressive pre-training, multi-stage supervised fine-tuning, and a sparse attention method alongside chunked prefill optimization for efficient inference.
💬 Research Conclusions:
– Developed Qwen2.5-1M models achieve superior long-context task performance and a 3x to 7x prefill speedup, outperforming other models like GPT-4o-mini in long-context scenarios while preserving efficiency in short-context usage.
👉 Paper link: https://huggingface.co/papers/2501.15383

3. Towards General-Purpose Model-Free Reinforcement Learning
🔑 Keywords: Model-Free RL, Model-Based Representations, MR.Q
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To develop a unifying model-free deep reinforcement learning (RL) algorithm capable of addressing diverse domains and problem settings.
🛠️ Research Methods:
– Utilization of model-based representations to approximately linearize the value function, aiming for efficiency without the typical costs associated with planning or simulated trajectories.
💬 Research Conclusions:
– The MR.Q algorithm demonstrates competitive performance on common RL benchmarks using a single set of hyperparameters, moving towards general-purpose model-free deep RL solutions.
👉 Paper link: https://huggingface.co/papers/2501.16142

4. ARWKV: Pretrain is not what we need, an RNN-Attention-Based Language Model Born from Transformer
🔑 Keywords: RNN Expressiveness, RWKV-7 Attention, LLM Distillation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance the expressiveness of RNNs using the RWKV-7 attention model, surpassing traditional transformer models.
🛠️ Research Methods:
– Introduces models distilled from Qwen 2.5 based on RWKV-7 attention, focusing on efficient knowledge transfer to smaller models with fewer tokens.
💬 Research Conclusions:
– Demonstrates improved state tracking capabilities and reduced knowledge processing time using efficient GPU setups, providing insights for building more powerful foundational models.
👉 Paper link: https://huggingface.co/papers/2501.15570

5. Emilia: A Large-Scale, Extensive, Multilingual, and Diverse Dataset for Speech Generation
🔑 Keywords: Speech Generation, Emilia-Pipe, Multilingual Dataset, Spontaneous Speech, AI Native
💡 Category: Generative Models
🌟 Research Objective:
– To address the limitations of current speech generation models in capturing spontaneity and variability by introducing Emilia-Pipe, a preprocessing pipeline for in-the-wild speech data.
🛠️ Research Methods:
– Leveraged Emilia-Pipe to extract a multilingual dataset, Emilia, from spontaneous real-world speech data, resulting in over 101k hours of speech in six languages, and expanded to Emilia-Large exceeding 216k hours.
💬 Research Conclusions:
– Extensive experiments show Emilia outperforms traditional datasets by generating spontaneous and human-like speech, highlighting the importance of dataset scalability in advancing speech generation.
👉 Paper link: https://huggingface.co/papers/2501.15907

6. iFormer: Integrating ConvNet and Transformer for Mobile Application
🔑 Keywords: Mobile Hybrid Vision Networks, iFormer, Mobile Applications, Self-Attention, ImageNet-1k
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to optimize latency and accuracy for mobile applications using a new family of networks called iFormer.
🛠️ Research Methods:
– iFormer integrates convolution’s local representation with self-attention for global modeling. It adapts ConvNeXt to a lightweight design and introduces mobile modulation attention to enhance efficiency.
💬 Research Conclusions:
– iFormer outperforms existing lightweight networks, achieving a Top-1 accuracy of 80.4% on ImageNet-1k with only 1.10 ms latency on an iPhone 13, and demonstrates notable improvements in tasks like object detection and semantic segmentation.
👉 Paper link: https://huggingface.co/papers/2501.15369

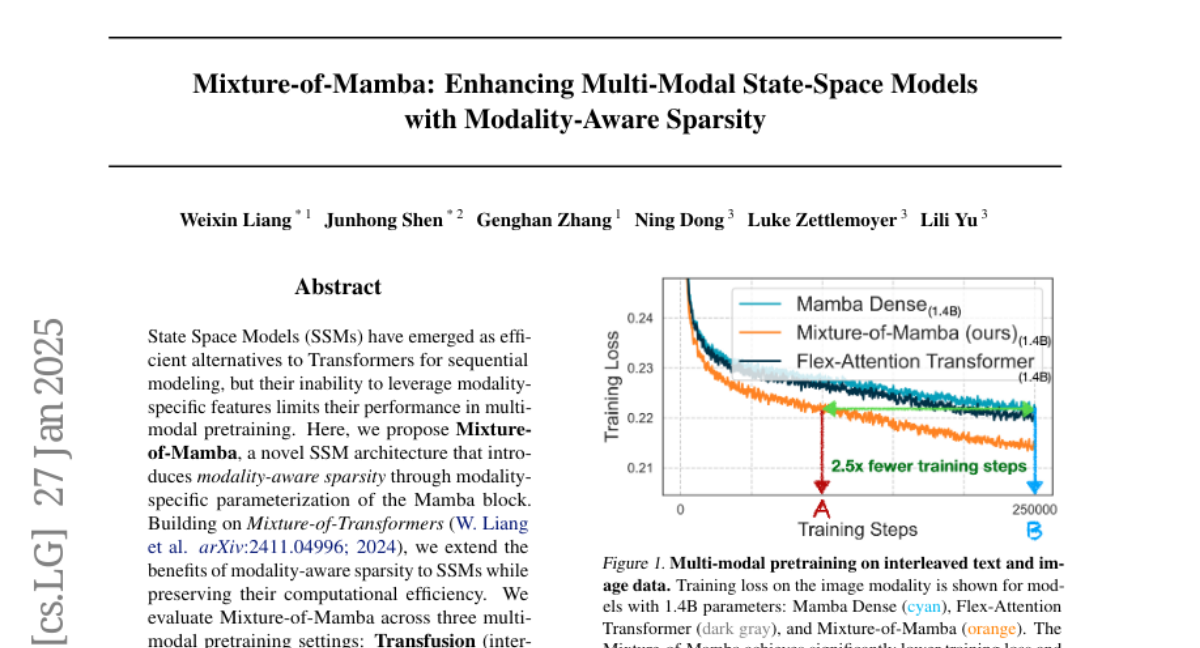
7. Mixture-of-Mamba: Enhancing Multi-Modal State-Space Models with Modality-Aware Sparsity
🔑 Keywords: State Space Models, Modality-aware sparsity, Multi-modal pretraining, Mamba block, Mixture-of-Mamba
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to enhance the performance of State Space Models (SSMs) in multi-modal pretraining by introducing modality-aware sparsity through a novel architecture named Mixture-of-Mamba.
🛠️ Research Methods:
– Introduces Mixture-of-Mamba, a framework extending modality-aware sparsity to SSMs, evaluated across three multi-modal pretraining settings involving text, image, and speech.
💬 Research Conclusions:
– Mixture-of-Mamba notably reduces computational costs while maintaining performance, setting new benchmarks in multi-modal pretraining and demonstrating the efficacy of modality-aware sparsity in SSMs.
👉 Paper link: https://huggingface.co/papers/2501.16295
8. Are Vision Language Models Texture or Shape Biased and Can We Steer Them?
🔑 Keywords: Vision Language Models, Zero-Shot Image Classification, Human-Induced Visual Biases
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Investigate how Vision Language Models (VLMs) align with human vision, particularly in terms of visual biases like texture vs. shape bias.
🛠️ Research Methods:
– Examined a wide range of popular VLMs to study their visual biases, and conducted experiments to analyze the influence of text in modulating these biases.
💬 Research Conclusions:
– Found that VLMs often exhibit a stronger shape bias compared to their vision encoders and demonstrated the capability to steer visual biases through language prompting, although human-level shape bias is not yet achieved.
👉 Paper link: https://huggingface.co/papers/2403.09193

9. CodeMonkeys: Scaling Test-Time Compute for Software Engineering
🔑 Keywords: Test-time Compute, CodeMonkeys, GitHub Issues, LLM, Parallel Scaling
💡 Category: Natural Language Processing
🌟 Research Objective:
– Explore methods to scale test-time compute for improving LLM capabilities in resolving GitHub issues.
🛠️ Research Methods:
– Developed a system called CodeMonkeys for iterative code editing and testing.
– Utilized parallel scaling to increase trajectory iterations and amortize costs.
💬 Research Conclusions:
– CodeMonkeys effectively resolved 57.4% of issues from SWE-bench with a $2300 budget.
– The system selects edits by combining model-generated tests and achieves higher performance through ensemble selection.
👉 Paper link: https://huggingface.co/papers/2501.14723

10. Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models
🔑 Keywords: Sparse Mixture-of-Experts, Scalability, Model Performance
💡 Category: Natural Language Processing
🌟 Research Objective:
– Explore the relationship between model parameters and compute per example in the scaling of language models, particularly focusing on sparse Mixture-of-Experts (MoEs).
🛠️ Research Methods:
– Investigate the impact of varying levels of sparsity on model performance during pretraining and downstream few-shot evaluation, examining constraints like parameter size and total training compute.
💬 Research Conclusions:
– Identified an optimal level of sparsity that enhances both training efficiency and model performance, improving understanding of sparsity impact within scaling laws for MoEs.
👉 Paper link: https://huggingface.co/papers/2501.12370

11. OpenCharacter: Training Customizable Role-Playing LLMs with Large-Scale Synthetic Personas
🔑 Keywords: Large language models, Character generalization, Role-playing dialogue, Synthetic data
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to equip large language models with character generalization capabilities for customizable role-playing dialogue agents.
🛠️ Research Methods:
– Employed large-scale data synthesis, including character profiles from Persona Hub, and applied response rewriting and response generation strategies.
– Performed supervised fine-tuning using the LLaMA-3 8B model to validate synthetic instruction tuning data.
💬 Research Conclusions:
– The fine-tuned model enhanced the LLaMA-3 8B Instruct model, achieving performance comparable to GPT-4o on role-playing dialogue.
– Synthetic characters and dialogues were released to the public to aid in further research.
👉 Paper link: https://huggingface.co/papers/2501.15427

12. Visual Generation Without Guidance
🔑 Keywords: Classifier-Free Guidance, Guidance-Free Training, generative models, sampling, computational cost
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to develop visual models that eliminate the need for guided sampling, proposing Guidance-Free Training (GFT) to reduce computational cost.
🛠️ Research Methods:
– Introduces GFT, which achieves comparable performance to Classifier-Free Guidance (CFG) by training directly from scratch, using a similar maximum likelihood objective with minimal parameterization modifications.
💬 Research Conclusions:
– GFT matches or improves upon CFG’s performance across different visual model domains, showing versatility and effectiveness with reduced computational requirements. The implementation requires minimal codebase adjustments.
👉 Paper link: https://huggingface.co/papers/2501.15420

13. Feasible Learning
🔑 Keywords: Feasible Learning, Empirical Risk Minimization, primal-dual approach, slack variables, large language models
💡 Category: Machine Learning
🌟 Research Objective:
– Introduce Feasible Learning (FL) which requires satisfactory performance on individual data points, differing from the Empirical Risk Minimization (ERM) framework’s average performance focus.
🛠️ Research Methods:
– Utilize a primal-dual approach to dynamically re-weight sample importance during training and incorporate slack variables for setting feasible thresholds.
💬 Research Conclusions:
– FL models show improved performance on less frequent data points compared to ERM, with minimal negative impact on average performance.
👉 Paper link: https://huggingface.co/papers/2501.14912

14. Return of the Encoder: Maximizing Parameter Efficiency for SLMs
🔑 Keywords: Encoder-Decoder Architecture, Small Language Models, Edge Devices, Computational Efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– To analyze and demonstrate the efficiency and advantages of encoder-decoder architectures for small language models across different platforms like GPU, CPU, and NPU, specifically in the context of edge devices.
🛠️ Research Methods:
– A systematic analysis comparing encoder-decoder and decoder-only models concerning first-token latency and throughput, alongside a novel knowledge distillation framework to leverage benefits from large decoder-only models.
💬 Research Conclusions:
– Encoder-decoder architectures achieved significant efficiency improvements over decoder-only models, including 47% lower latency and 4.7x higher throughput on edge devices, and better performance on asymmetric sequence tasks, challenging current industry trends favoring decoder-only scaling.
👉 Paper link: https://huggingface.co/papers/2501.16273
