AI Native Daily Paper Digest – 20250131

1. GuardReasoner: Towards Reasoning-based LLM Safeguards
🔑 Keywords: LLMs, GuardReasoner, reasoning, guard models, safety-critical applications
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to enhance the safety of LLMs (Large Language Models) in safety-critical applications by introducing a safeguard called GuardReasoner, focusing on learning to reason effectively.
🛠️ Research Methods:
– The methodology involves creating the GuardReasonerTrain dataset with 127K samples and 460K reasoning steps, implementing reasoning SFT, and utilizing hard sample DPO to improve reasoning abilities.
💬 Research Conclusions:
– GuardReasoner demonstrates superior performance, surpassing GPT-4o+CoT and LLaMA Guard in F1 scores, backed by extensive experiments on 13 benchmarks across 3 guardrail tasks.
👉 Paper link: https://huggingface.co/papers/2501.18492

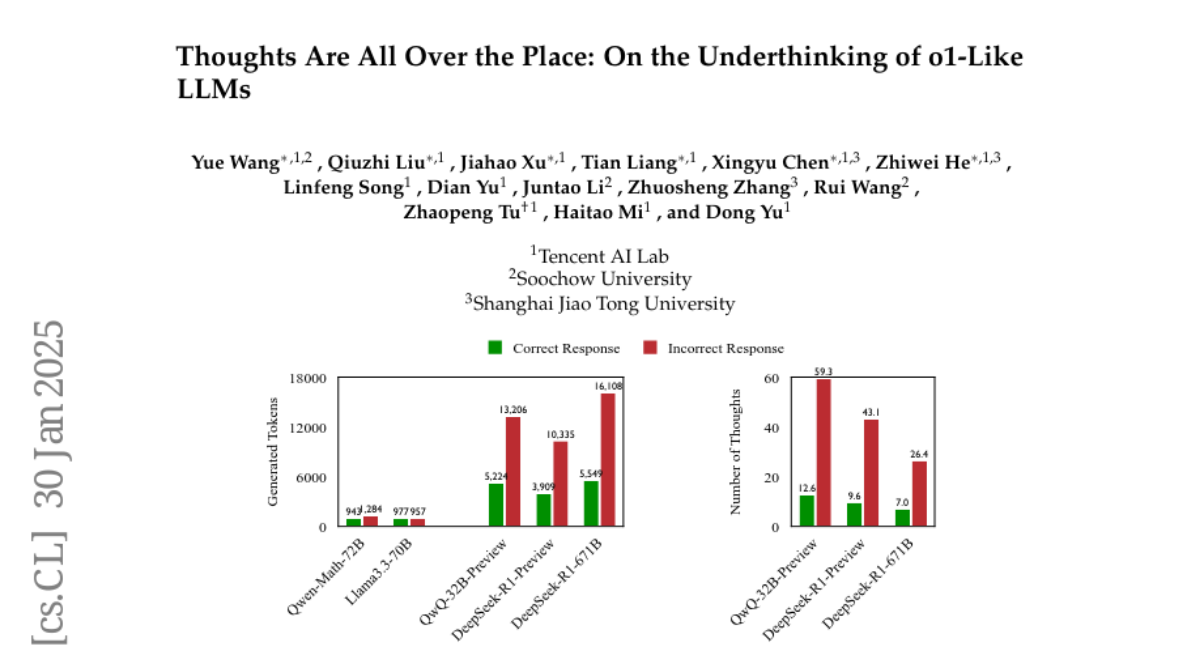
2. Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs
🔑 Keywords: Large language models, Reasoning inefficiencies, Problem-solving capabilities, Mathematical problems, Thought switching penalty
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to analyze the phenomenon of underthinking in OpenAI’s o1-like large language models (LLMs), particularly their tendency to frequently switch reasoning thoughts, impacting performance on complex reasoning tasks.
🛠️ Research Methods:
– The authors conducted experiments on three challenging test sets using two representative open-source o1-like models, developed a novel metric to measure underthinking, and proposed a decoding strategy with a thought switching penalty (TIP) to mitigate this issue.
💬 Research Conclusions:
– The research concludes that the proposed TIP strategy improves the accuracy of LLMs on challenging datasets, demonstrating a practical solution to address reasoning inefficiencies without model fine-tuning.
👉 Paper link: https://huggingface.co/papers/2501.18585
3. Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch
🔑 Keywords: Large Language Models, Accelerators, Distributed Algorithms, Synchronization, Bandwidth
💡 Category: Machine Learning
🌟 Research Objective:
– To enhance the DiLoCo distributed algorithm for training Large Language Models (LLMs) by reducing communication bandwidth while maintaining learning quality.
🛠️ Research Methods:
– Introducing selective synchronization of parameter subsets to lower peak bandwidth requirements.
– Allowing training to continue during synchronization to save clock time.
– Quantizing exchanged data to further reduce bandwidth across workers.
💬 Research Conclusions:
– Achieved similar training quality with billion-scale parameters while reducing necessary bandwidth by two orders of magnitude.
👉 Paper link: https://huggingface.co/papers/2501.18512

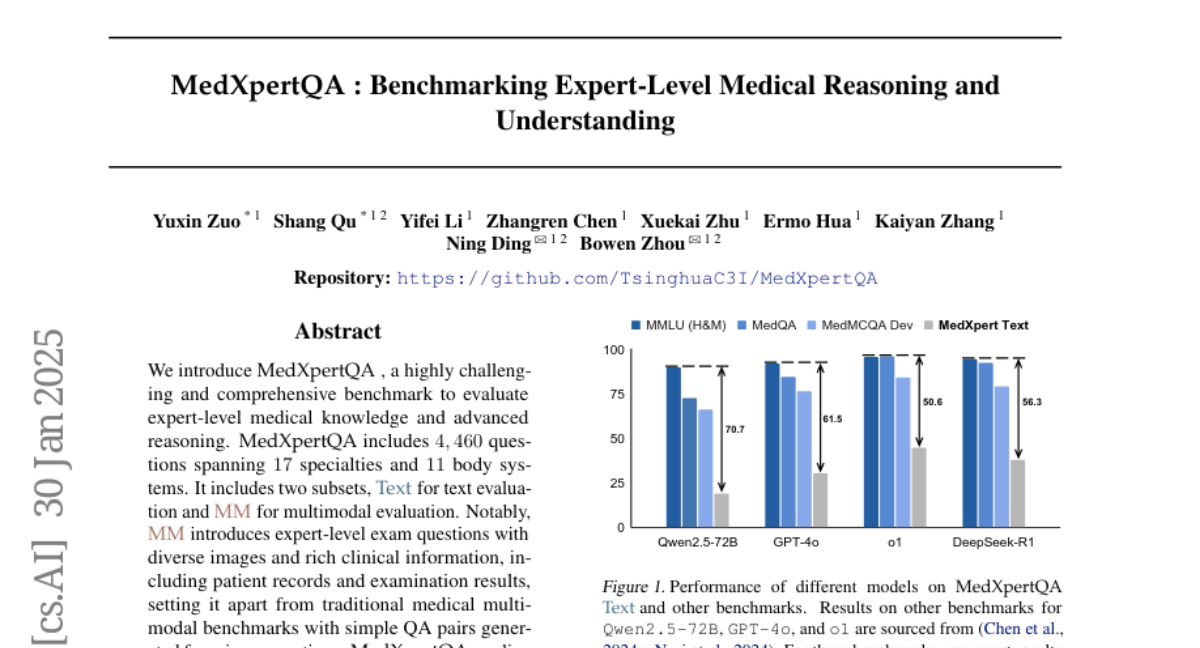
4. MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding
🔑 Keywords: MedXpertQA, multimodal evaluation, expert-level medical knowledge
💡 Category: AI in Healthcare
🌟 Research Objective:
– Introduce MedXpertQA as a comprehensive benchmark for evaluating expert-level medical knowledge and reasoning across multiple medical specialties and body systems.
🛠️ Research Methods:
– The benchmark incorporates two subsets: Text for text evaluation and MM for multimodal evaluation, including complex images and clinical information. Rigorous filtering, augmentation, and data synthesis are applied to ensure difficulty and mitigate data leakage.
💬 Research Conclusions:
– MedXpertQA sets itself apart by enhancing clinical relevance and comprehensiveness compared to existing benchmarks, assessing advanced reasoning in medical contexts with evaluations conducted on 16 leading models.
👉 Paper link: https://huggingface.co/papers/2501.18362
5. PhysBench: Benchmarking and Enhancing Vision-Language Models for Physical World Understanding
🔑 Keywords: Embodied AI, Vision-Language Models, Physical World Understanding, PhysBench, PhysAgent
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to enhance Vision-Language Models (VLMs) in understanding the physical world, allowing embodied agents to perform complex tasks and operate safely.
🛠️ Research Methods:
– Introduced PhysBench, a benchmark for evaluating VLMs’ physical world understanding, featuring interleaved video-image-text data across diverse tasks.
– Developed PhysAgent, a framework that combines VLMs’ generalization strengths with vision models to improve physical understanding capabilities.
💬 Research Conclusions:
– VLMs excel in common-sense reasoning but struggle with physical world comprehension due to a lack of physical knowledge and embedded priors.
– PhysAgent significantly enhances VLMs’ physical understanding, shown by an 18.4% improvement on GPT-4o, benefitting embodied agents like MOKA.
– PhysBench and PhysAgent provide insights into bridging the gap between VLMs and physical world understanding.
👉 Paper link: https://huggingface.co/papers/2501.16411

6. Large Language Models Think Too Fast To Explore Effectively
🔑 Keywords: Large Language Models, exploration, Little Alchemy 2, Sparse Autoencoders, empowerment
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate whether Large Language Models (LLMs) can surpass humans in exploration during an open-ended task.
🛠️ Research Methods:
– Utilized “Little Alchemy 2” as a paradigm to evaluate exploration by combining elements to discover new ones, alongside representational analysis with Sparse Autoencoders.
💬 Research Conclusions:
– Most LLMs underperform compared to humans, except the o1 model; LLMs tend to make premature decisions by prioritizing uncertainty over empowerment, limiting effective exploration and adaptability.
👉 Paper link: https://huggingface.co/papers/2501.18009

7. WILDCHAT-50M: A Deep Dive Into the Role of Synthetic Data in Post-Training
🔑 Keywords: post-training, synthetic data, WILDCHAT-50M, open-weight models, SFT mix
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to refine language model behaviors and unlock new skills through post-training techniques, particularly focusing on large-scale comparative analyses of synthetic data models and large language model (LLM) judges.
🛠️ Research Methods:
– The study introduces WILDCHAT-50M, an extensive chat dataset including responses from GPT and over 50 different open-weight models, ranging from 0.5B to 104B parameters, to facilitate comparative analysis.
💬 Research Conclusions:
– The research demonstrates the potential of the WILDCHAT-50M dataset by developing RE-WILD, a public SFT mix that outperforms Tulu-3 SFT mixture from Allen AI with only 40% of the sample size. The dataset, samples, and code are made publicly available on GitHub.
👉 Paper link: https://huggingface.co/papers/2501.18511

8. o3-mini vs DeepSeek-R1: Which One is Safer?
🔑 Keywords: DeepSeek-R1, LLMs, AI Ethics, automated safety testing, OpenAI’s o3-mini
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– To assess the safety level of DeepSeek-R1 and OpenAI’s o3-mini models, focusing on alignment with safety and human values.
🛠️ Research Methods:
– Utilized an automated safety testing tool named ASTRAL to systematically generate and execute test inputs on both models.
💬 Research Conclusions:
– DeepSeek-R1 demonstrated a higher unsafe response rate (11.98%) compared to OpenAI’s o3-mini (1.19%).
👉 Paper link: https://huggingface.co/papers/2501.18438

9. CowPilot: A Framework for Autonomous and Human-Agent Collaborative Web Navigation
🔑 Keywords: Autonomous agents, Human-Agent Collaboration, Task Efficiency, Web Navigation
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The aim is to propose CowPilot, a framework for enhancing web navigation through human-agent collaboration and improving task success and efficiency.
🛠️ Research Methods:
– CowPilot framework integrates autonomous operations with human intervention possibilities, allowing users to override agent suggestions, and conducting case studies across five common websites.
💬 Research Conclusions:
– The collaborative mode achieved a 95% success rate with human intervention required for only 15.2% of the steps, highlighting the effectiveness of human-agent collaboration in web task completion.
👉 Paper link: https://huggingface.co/papers/2501.16609

10. SANA 1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformer
🔑 Keywords: Diffusion Transformer, Efficient Scaling, Model Pruning, Text-to-Image Generation, SoTA
💡 Category: Generative Models
🌟 Research Objective:
– Introduce SANA-1.5, a linear Diffusion Transformer that enhances the efficiency of text-to-image generation by scaling models effectively while reducing computational resources.
🛠️ Research Methods:
– Implement a depth-growth paradigm for training to scale models from 1.6B to 4.8B parameters.
– Develop model depth pruning using block importance analysis for compression with minimal quality loss.
– Apply a repeated sampling strategy for inference-time scaling to allow smaller models to perform as well as larger ones.
💬 Research Conclusions:
– SANA-1.5 achieves a text-image alignment score of 0.72 on the GenEval benchmark and can further improve to 0.80 through inference scaling, setting a new state-of-the-art standard.
👉 Paper link: https://huggingface.co/papers/2501.18427
