AI Native Daily Paper Digest – 20250203

1. s1: Simple test-time scaling
🔑 Keywords: Test-time scaling, Language modeling, OpenAI, Reasoning performance, Budget forcing
💡 Category: Natural Language Processing
🌟 Research Objective:
– To find the simplest approach for achieving test-time scaling and enhancing reasoning performance in language models.
🛠️ Research Methods:
– Developed a curated small dataset (s1K) with 1,000 questions paired with reasoning traces focusing on difficulty, diversity, and quality.
– Introduced a method called budget forcing to manage test-time compute by terminating or extending the model’s thinking process.
💬 Research Conclusions:
– The finetuned model, incorporating budget forcing, outperformed OpenAI’s o1-preview model by up to 27% on competition math questions.
– The model showed improved extrapolation performance on AIME24 from 50% to 57% without further test-time intervention.
– The research artifacts are available as open-source resources.
👉 Paper link: https://huggingface.co/papers/2501.19393

2. Reward-Guided Speculative Decoding for Efficient LLM Reasoning
🔑 Keywords: Reward-Guided Speculative Decoding, Large Language Models, inference efficiency, Resource-Intensive Scenarios, Trade-off
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces Reward-Guided Speculative Decoding (RSD) to enhance inference efficiency in large language models by employing a lightweight draft model and a powerful target model to prioritize high-reward outputs.
🛠️ Research Methods:
– The approach utilizes a process reward model to evaluate decoding steps dynamically, employing a threshold-based mixture strategy to optimize the balance between computational cost and output quality.
💬 Research Conclusions:
– RSD shows significant efficiency gains, reducing computational cost by up to 4.4 times fewer FLOPs and improving accuracy by up to +3.5 over parallel decoding methods in tasks exemplified by Olympiad-level reasoning benchmarks.
👉 Paper link: https://huggingface.co/papers/2501.19324

3. Self-supervised Quantized Representation for Seamlessly Integrating Knowledge Graphs with Large Language Models
🔑 Keywords: Knowledge Graph, Large Language Models, Quantized Codes, LLaMA2, SSQR
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to achieve seamless integration of Knowledge Graphs (KGs) with Large Language Models (LLMs) through a novel framework.
🛠️ Research Methods:
– A two-stage framework is proposed where a Self-Supervised Quantized Representation (SSQR) method compresses KG data into discrete codes compatible with language format, which is then used as input to LLMs.
💬 Research Conclusions:
– The proposed SSQR method generates more distinguishable codes compared to existing methods and, when used with fine-tuned versions of LLaMA2 and LLaMA3.1, shows superior performance in KG link prediction and triple classification tasks using significantly fewer tokens.
👉 Paper link: https://huggingface.co/papers/2501.18119

4. PixelWorld: Towards Perceiving Everything as Pixels
🔑 Keywords: AI Native, Pixel-based Input, Multimodal Datasets, Perceptual Abilities, Spatial Sparsity
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To unify diverse data modalities as pixel inputs and evaluate the performance of foundation models using this approach with the PixelWorld evaluation suite.
🛠️ Research Methods:
– Introduced PixelWorld, a novel evaluation suite, to assess models’ performance by transforming all modalities into pixel space.
💬 Research Conclusions:
– PEAP (Perceive Everything as Pixels) outperforms token-based input in multimodal datasets but shows a decline in reasoning and coding capabilities; larger models maintain performance, smaller ones like Phi-3.5-V suffer.
– PEAP attention pattern aligns with text token input and can be accelerated by exploiting spatial sparsity.
👉 Paper link: https://huggingface.co/papers/2501.19339

5. DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning
🔑 Keywords: World Models, Offline Training, Task-Agnostic, Generative Models, DINOv2
💡 Category: Generative Models
🌟 Research Objective:
– To leverage world models for reasoning and planning across diverse problems using passive data.
🛠️ Research Methods:
– Introduction of the DINO World Model (DINO-WM), utilizing spatial patch features from DINOv2 to predict future outcomes without visual reconstruction.
– Application of DINO-WM across tasks such as maze navigation, tabletop pushing, and particle manipulation.
💬 Research Conclusions:
– DINO-WM enables zero-shot behavioral solutions at test time, showcasing strong generalization capabilities and task-agnostic planning without expert demonstrations or pre-learned models.
👉 Paper link: https://huggingface.co/papers/2411.04983

6. MatAnyone: Stable Video Matting with Consistent Memory Propagation
🔑 Keywords: Auxiliary-free human video matting, MatAnyone, memory propagation module, semantic stability, video matting
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a robust framework for target-assigned video matting that improves performance in complex or ambiguous backgrounds.
🛠️ Research Methods:
– Introduced a region-adaptive memory fusion module to integrate memory from previous frames, accompanied by a larger, high-quality dataset and a novel training strategy that leverages large-scale segmentation data.
💬 Research Conclusions:
– MatAnyone demonstrated superior and accurate video matting results across diverse scenarios, outmatching existing methods.
👉 Paper link: https://huggingface.co/papers/2501.14677

7. Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
🔑 Keywords: Large Language Models, Universal Jailbreaks, Constitutional Classifiers, Deployment Viability
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to develop safeguards to protect Large Language Models (LLMs) from universal jailbreaks, which can be used to bypass model safeguards for harmful activities.
🛠️ Research Methods:
– Introduced Constitutional Classifiers, which are safeguards trained on synthetic data derived from LLMs prompted with a set of natural language rules (“constitution”) to specify permitted and restricted content.
– Evaluated over 3,000 hours of red teaming and automated evaluations to test the defense against jailbreaks.
💬 Research Conclusions:
– Constitutional Classifiers provide a robust defense against universal jailbreaks with significant performance and maintain deployment viability, showing minimal increase in refusals and manageable inference overhead.
👉 Paper link: https://huggingface.co/papers/2501.18837

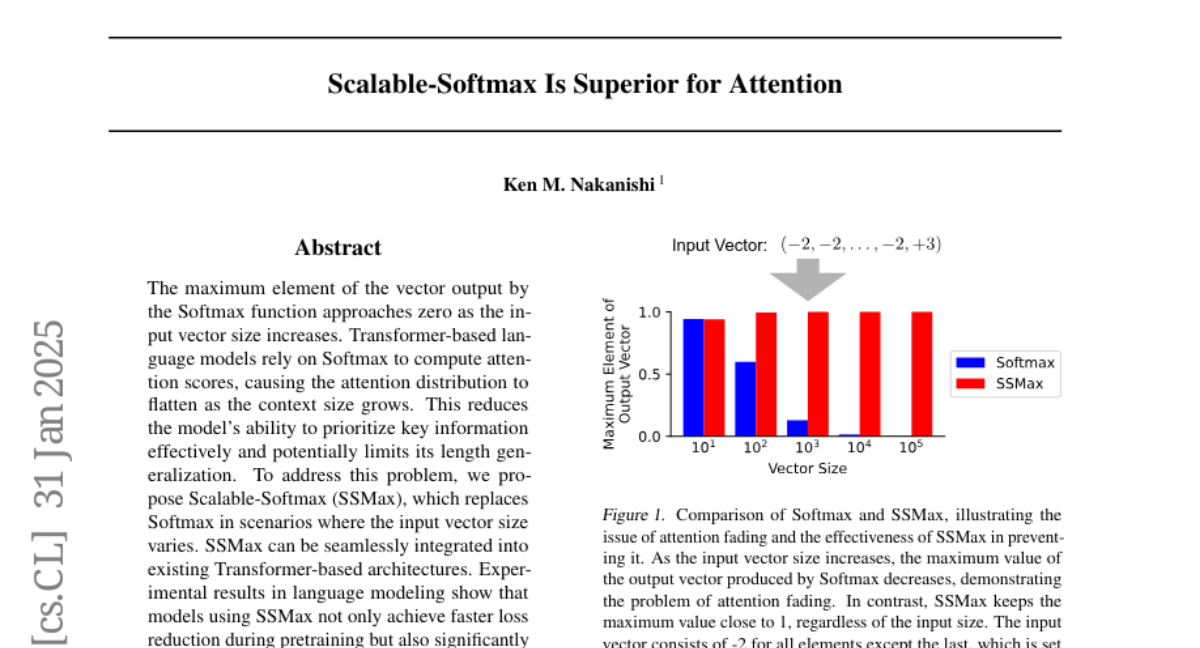
8. Scalable-Softmax Is Superior for Attention
🔑 Keywords: Transformer-based language models, Softmax, Scalable-Softmax, Attention distribution, Length generalization
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve the effectiveness of attention distribution in Transformer-based language models as context size increases by developing Scalable-Softmax (SSMax).
🛠️ Research Methods:
– Introducing SSMax to replace Softmax in scenarios with varying input vector sizes, integrating it into existing Transformer-based architectures, and evaluating language models on loss reduction and key information retrieval.
💬 Research Conclusions:
– SSMax allows for faster loss reduction, significantly improves performance in long contexts and key information retrieval, and enhances length generalization abilities, even when implemented in ongoing or completed pretrained models.
👉 Paper link: https://huggingface.co/papers/2501.19399
9. Trading Inference-Time Compute for Adversarial Robustness
🔑 Keywords: inference-time compute, adversarial attacks, robustness, Large Language Models, reasoning models
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To explore the impact of increasing inference-time compute on the robustness of reasoning models to adversarial attacks.
🛠️ Research Methods:
– Conduct experiments using OpenAI o1-preview and o1-mini models to analyze robustness against various adversarial attacks by increasing test-time compute without employing adversarial training.
💬 Research Conclusions:
– Increased inference-time compute generally enhances robustness against adversarial attacks, significantly reducing attack success rates, with exceptions noted where increased compute does not improve reliability.
👉 Paper link: https://huggingface.co/papers/2501.18841

10. The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model Training
🔑 Keywords: learning-rate schedules, performance bound, optimization theory
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to demonstrate the similarity between learning-rate schedules for large model training and performance bounds from non-smooth convex optimization theory, and to explore the practical benefits of cooldown in learning-rate scheduling.
🛠️ Research Methods:
– The methods include providing a bound for the constant schedule with linear cooldown and leveraging the similarity between theory and practice for tuning learning rates in large models.
💬 Research Conclusions:
– The authors found that extending the schedule with an optimal learning rate and transferring this rate across schedules can lead to noticeable improvements in training large Llama-type models.
👉 Paper link: https://huggingface.co/papers/2501.18965

11. SAeUron: Interpretable Concept Unlearning in Diffusion Models with Sparse Autoencoders
🔑 Keywords: Diffusion models, Ethical AI, Sparse autoencoders, Machine unlearning
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– Introduce SAeUron, a method to remove unwanted concepts from text-to-image diffusion models while maintaining performance.
🛠️ Research Methods:
– Utilizes features learned by sparse autoencoders (SAEs) trained unsupervised on multiple denoising timesteps.
– Proposes a feature selection method for precise interventions on model activations.
💬 Research Conclusions:
– SAeUron achieves state-of-the-art performance in unlearning tasks, outperforming others in competitive benchmarks.
– Demonstrates the capability to remove multiple concepts simultaneously and mitigates the generation of unwanted content under adversarial attacks.
👉 Paper link: https://huggingface.co/papers/2501.18052

12. Unraveling the Capabilities of Language Models in News Summarization
🔑 Keywords: language models, news summarization, zero-shot learning, few-shot learning, GPT-3.5-Turbo, GPT-4
💡 Category: Natural Language Processing
🌟 Research Objective:
– Provide a comprehensive benchmarking of 20 recent language models, focusing on smaller models for the news summarization task.
🛠️ Research Methods:
– Systematic testing of model capabilities in summarizing news articles across three datasets using zero-shot and few-shot learning settings, combined with a robust evaluation methodology.
💬 Research Conclusions:
– GPT-3.5-Turbo and GPT-4 performed exceptionally well, while models like Qwen1.5-7B and Zephyr-7B-Beta showed potential as competitive alternatives to larger models.
– Including demonstration examples in few-shot settings did not improve and sometimes worsened performance due to poor quality of reference summaries.
👉 Paper link: https://huggingface.co/papers/2501.18128

13. INT: Instance-Specific Negative Mining for Task-Generic Promptable Segmentation
🔑 Keywords: Task-generic prompt, Vision-Language Models, Instance-specific prompts, Negative Mining
💡 Category: Computer Vision
🌟 Research Objective:
– To enhance image segmentation for diverse samples using a single task-generic prompt by optimizing instance-specific prompts through a method called Instance-specific Negative Mining (INT).
🛠️ Research Methods:
– Utilization of Instance-specific Negative Mining to improve instance-specific prompt generation and semantic mask generation, filtering incorrect information and aligning segmentation with instance-specific prompts.
💬 Research Conclusions:
– The proposed INT method was validated across six datasets, showing effectiveness, robustness, and scalability in segmenting images such as camouflaged objects and medical images.
👉 Paper link: https://huggingface.co/papers/2501.18753

14. Zero-Shot Novel View and Depth Synthesis with Multi-View Geometric Diffusion
🔑 Keywords: 3D scene reconstruction, diffusion-based architecture, multi-view synthesis, image generation, depth estimation
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce MVGD, a new architecture for 3D scene reconstruction from sparse posed images, capable of direct pixel-level generation of images and depth maps from various viewpoints.
🛠️ Research Methods:
– Employ raymap conditioning to augment visual features with spatial information, and use learnable task embeddings for multi-task generation of images and depth maps.
– Train on a large dataset of over 60 million multi-view samples and use incremental fine-tuning for efficient training of larger models.
💬 Research Conclusions:
– MVGD achieves state-of-the-art results in novel view synthesis benchmarks and excels in multi-view stereo and video depth estimation tasks.
👉 Paper link: https://huggingface.co/papers/2501.18804

15. Fast Encoder-Based 3D from Casual Videos via Point Track Processing
🔑 Keywords: 3D reconstruction, dynamic content, TracksTo4D
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to efficiently reconstruct 3D structures and camera positions from casual videos containing dynamic content using a novel approach.
🛠️ Research Methods:
– Introduces TracksTo4D, a learning-based method employing a single feed-forward pass over 2D point tracks extracted from videos. The architecture is designed considering symmetries and low-rank approximation of movement patterns.
💬 Research Conclusions:
– TracksTo4D achieves comparable accuracy to state-of-the-art methods in reconstructing temporal point clouds and significantly reduces runtime by up to 95%. It also generalizes well to new videos and semantic categories during inference.
👉 Paper link: https://huggingface.co/papers/2404.07097
