AI Native Daily Paper Digest – 20250205

1. VideoJAM: Joint Appearance-Motion Representations for Enhanced Motion Generation in Video Models
🔑 Keywords: VideoJAM, motion coherence, generative video models, pixel reconstruction
💡 Category: Generative Models
🌟 Research Objective:
– Address the limitation of generative video models in capturing real-world motion by introducing VideoJAM.
🛠️ Research Methods:
– Develop a joint appearance-motion representation and use the Inner-Guidance mechanism for coherent motion generation.
💬 Research Conclusions:
– VideoJAM enhances both motion coherence and visual quality, outperforming existing competitive models without needing modifications to training data.
👉 Paper link: https://huggingface.co/papers/2502.02492

2. Inverse Bridge Matching Distillation
🔑 Keywords: Diffusion Bridge Models, Distillation Technique, Image-to-Image Translation, Super-resolution, Inference Acceleration
💡 Category: Generative Models
🌟 Research Objective:
– Addressing the slow inference problem in diffusion bridge models used for image-to-image translation and other similar applications.
🛠️ Research Methods:
– Introduced a novel distillation technique based on inverse bridge matching to create a tractable objective that can distill both conditional and unconditional DBMs using only corrupted images.
💬 Research Conclusions:
– The proposed distillation technique successfully accelerates DBM inference by 4x to 100x and can enhance generation quality over traditional models, depending on the setup.
👉 Paper link: https://huggingface.co/papers/2502.01362

3. ACECODER: Acing Coder RL via Automated Test-Case Synthesis
🔑 Keywords: Reinforcement Learning, Code Model Training, Supervised Fine-tuning, Reward Models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– This study explores the untapped potential of Reinforcement Learning (RL) in coder models by improving model training with reliable reward data through automated test-case synthesis.
🛠️ Research Methods:
– The authors create a pipeline that generates extensive (question, test-cases) pairs from existing code data and constructs preference pairs using pass rates to train reward models using Bradley-Terry loss.
– Conducted reinforcement learning using reward models and test-case pass rewards, applied to various benchmarks including HumanEval, MBPP, BigCodeBench, and LiveCodeBench (V4).
💬 Research Conclusions:
– The study demonstrates significant improvements: a 10-point average enhancement for Llama-3.1-8B-Ins, a 5-point gain for Qwen2.5-Coder-7B-Ins, bringing the 7B model to par with a 236B model.
– Reinforcement Learning training showed over 25% improvement in HumanEval-plus and 6% in MBPP-plus with just 80 optimization steps, highlighting RL’s potential in enhancing coder models.
👉 Paper link: https://huggingface.co/papers/2502.01718

4. QLASS: Boosting Language Agent Inference via Q-Guided Stepwise Search
🔑 Keywords: Language agents, Reward model, Q-guided, Stepwise guidance, Complex interactive tasks
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve the performance of language agents on complex interactive tasks by optimizing intermediate interactions and addressing sub-optimal policies through stepwise guidance.
🛠️ Research Methods:
– Introduction of QLASS (Q-guided Language Agent Stepwise Search) which uses Q-value estimation in a stepwise manner along with reasoning trees to provide intermediate guidance and optimize long-term decision-making strategies.
💬 Research Conclusions:
– QLASS significantly enhances performance with reduced annotated data, proving effective in decision making and improving language agent inference on complex tasks, demonstrating efficiency even with limited supervision.
👉 Paper link: https://huggingface.co/papers/2502.02584

5. Satori: Reinforcement Learning with Chain-of-Action-Thought Enhances LLM Reasoning via Autoregressive Search
🔑 Keywords: Large language models, Reasoning capabilities, Autoregressive searching, Reinforcement learning, Open-source
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate if internalizing searching capabilities can fundamentally enhance a single LLM’s reasoning abilities.
🛠️ Research Methods:
– Developing Chain-of-Action-Thought (COAT) reasoning.
– Implementing a two-stage training paradigm: small-scale format tuning and large-scale self-improvement using reinforcement learning.
💬 Research Conclusions:
– The resulting model, Satori, achieves state-of-the-art performance in mathematical reasoning and exhibits strong generalization to out-of-domain tasks.
👉 Paper link: https://huggingface.co/papers/2502.02508

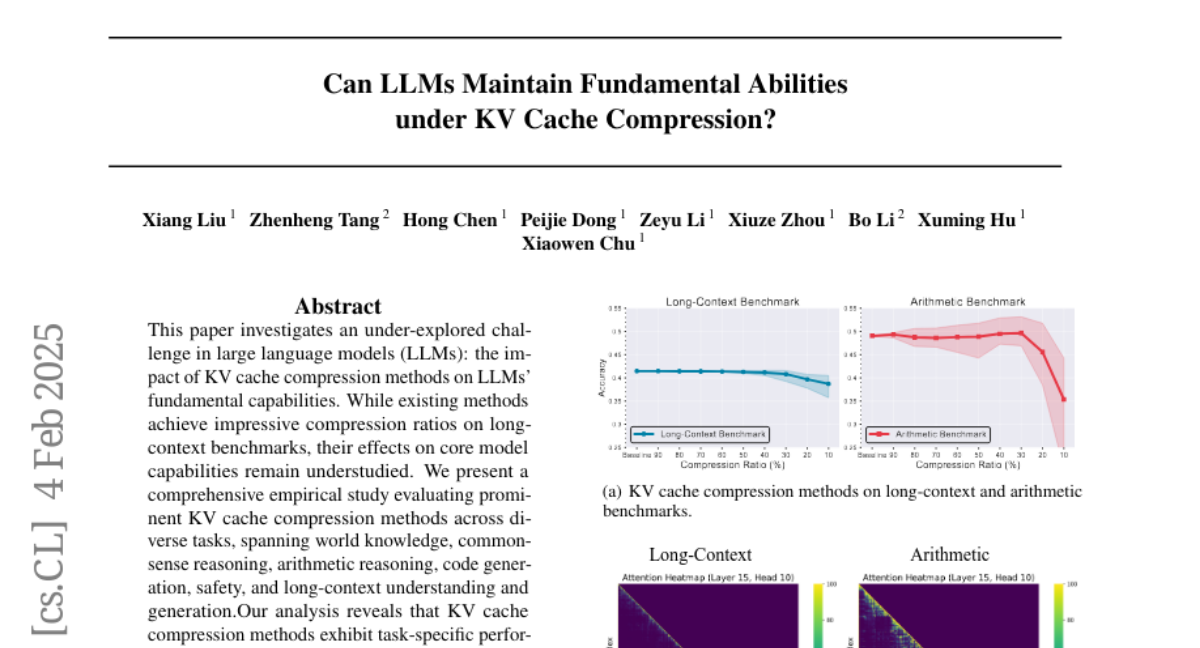
6. Can LLMs Maintain Fundamental Abilities under KV Cache Compression?
🔑 Keywords: KV cache compression, large language models, arithmetic reasoning, ShotKV, DeepSeek R1 Distill
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore how KV cache compression methods affect the core capabilities of large language models (LLMs).
🛠️ Research Methods:
– Comprehensive empirical evaluation across various tasks including world knowledge, commonsense reasoning, arithmetic reasoning, code generation, safety, and long-context understanding and generation.
💬 Research Conclusions:
– KV cache compression methods cause task-specific performance degradation, particularly significant in arithmetic reasoning tasks.
– The DeepSeek R1 Distill model demonstrates more robust compression tolerance.
– A new approach named ShotKV is proposed, which shows significant performance improvements in long-context generation tasks.
👉 Paper link: https://huggingface.co/papers/2502.01941
7. COCONut-PanCap: Joint Panoptic Segmentation and Grounded Captions for Fine-Grained Understanding and Generation
🔑 Keywords: COCONut-PanCap dataset, panoptic segmentation, grounded image captioning, vision-language models, multi-modal learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce the COCONut-PanCap dataset to enhance panoptic segmentation and grounded image captioning.
🛠️ Research Methods:
– Utilizes fine-grained, region-level captions based on advanced COCONut panoptic masks and human-edited, densely annotated descriptions to ensure consistency and detail in captions.
💬 Research Conclusions:
– COCONut-PanCap significantly improves the performance of vision-language models for understanding and generative models for text-to-image tasks, providing complementary benefits to large-scale datasets and establishing a new benchmark for joint panoptic segmentation and grounded captioning tasks.
👉 Paper link: https://huggingface.co/papers/2502.02589

8. Concept Steerers: Leveraging K-Sparse Autoencoders for Controllable Generations
🔑 Keywords: adversarial attacks, unethical content, k-sparse autoencoders, concept manipulation, diffusion models
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to address the challenges of adversarial attacks and unethical content generation in text-to-image models by proposing a novel framework using k-sparse autoencoders for efficient and interpretable concept manipulation.
🛠️ Research Methods:
– The research introduces the use of k-sparse autoencoders to identify monosemantic concepts in the latent space, steering generation away from unwanted concepts without retraining the model.
💬 Research Conclusions:
– The proposed method demonstrates a 20.01% improvement in removing unsafe concepts, effective style manipulation, and achieves a speed that is 5 times faster than current state-of-the-art methods without compromising generation quality.
👉 Paper link: https://huggingface.co/papers/2501.19066

9. Rethinking Mixture-of-Agents: Is Mixing Different Large Language Models Beneficial?
🔑 Keywords: Mixture-of-Agents, Large Language Models, Self-MoA, Ensembling, AI Native
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study investigates the effectiveness of mixing different Large Language Models (LLMs) in ensemble settings and introduces Self-MoA, which uses only the top-performing LLM.
🛠️ Research Methods:
– Extensive experiments are conducted comparing Self-MoA with standard MoA across various benchmarks, including AlpacaEval 2.0, MMLU, CRUX, and MATH. The paper also explores the quality-diversity trade-off in MoA settings.
💬 Research Conclusions:
– Self-MoA outperforms the standard MoA in many scenarios, achieving significant improvements in benchmark scores. The research highlights the sensitivity of MoA performance to quality and identifies situations where mixing different LLMs could be advantageous. Additionally, a sequential version of Self-MoA is introduced for dynamic aggregation of LLM outputs.
👉 Paper link: https://huggingface.co/papers/2502.00674

10. Generating Multi-Image Synthetic Data for Text-to-Image Customization
🔑 Keywords: Text-to-Image, Customization, Synthetic Customization Dataset, Encoder Architecture, Inference Technique
💡 Category: Generative Models
🌟 Research Objective:
– To enhance the text-to-image model by enabling customization with improved image quality and concept generation in unseen settings.
🛠️ Research Methods:
– Development of a high-quality Synthetic Customization Dataset with diverse images of the same object.
– Implementation of a new encoder architecture using shared attention mechanisms.
– Introduction of an inference technique to address overexposure issues.
💬 Research Conclusions:
– The proposed model, with its novel dataset and encoder, surpasses existing tuning-free methods in standard customization benchmarks.
👉 Paper link: https://huggingface.co/papers/2502.01720

11. Sample, Scrutinize and Scale: Effective Inference-Time Search by Scaling Verification
🔑 Keywords: Sampling-based search, Implicit scaling, Self-verification, Test-time compute, Reasoning capabilities
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To investigate the scaling trends in sampling-based search and its impact on model reasoning capabilities.
🛠️ Research Methods:
– Study and analysis of the scaling up of a minimalist implementation using random sampling and self-verification, focusing on testing different response outputs to locate errors.
💬 Research Conclusions:
– Scaling up sampling-based search improves performance, notably enhancing reasoning capabilities of models like Gemini v1.5 Pro. Implicit scaling through larger samples boosts verification accuracy, though current models show weak verification capabilities, necessitating a new benchmark for measurement.
👉 Paper link: https://huggingface.co/papers/2502.01839

12. Federated Sketching LoRA: On-Device Collaborative Fine-Tuning of Large Language Models
🔑 Keywords: Federated Fine-Tuning, Low-Rank Adaptation, Computational Constraints, LLMs, FSLoRA
💡 Category: Natural Language Processing
🌟 Research Objective:
– To address the challenges of device model sizes and data scarcity in fine-tuning large language models using federated sketching LoRA (FSLoRA).
🛠️ Research Methods:
– Leveraging a sketching mechanism to enable devices to selectively update submatrices of global LoRA modules maintained by a server.
– Adjusting sketching ratios to flexibly adapt to device-specific communication and computational constraints.
💬 Research Conclusions:
– FSLoRA provides a theoretically-grounded solution with superior performance, as demonstrated through comprehensive experiments on multiple datasets and LLM models.
– The convergence analysis illustrates the impact of sketching ratios on the convergence rate.
👉 Paper link: https://huggingface.co/papers/2501.19389

13. Activation Approximations Can Incur Safety Vulnerabilities Even in Aligned LLMs: Comprehensive Analysis and Defense
🔑 Keywords: Large Language Models, inference efficiency, activation approximation, safety evaluation
💡 Category: Foundations of AI
🌟 Research Objective:
– To conduct the first systematic safety evaluation of activation approximations in Large Language Models (LLMs).
🛠️ Research Methods:
– Evaluated seven state-of-the-art (sota) techniques across three popular categories to assess safety implications.
💬 Research Conclusions:
– The study reveals consistent safety degradation across ten safety-aligned LLMs when employing activation approximations.
👉 Paper link: https://huggingface.co/papers/2502.00840
