AI Native Daily Paper Digest – 20250206
1. SmolLM2: When Smol Goes Big — Data-Centric Training of a Small Language Model
🔑 Keywords: Large Language Models, SmolLM2, Multistage Training, Specialized Datasets, Small Language Models
💡 Category: Natural Language Processing
🌟 Research Objective:
– Develop and document a state-of-the-art small language model, SmolLM2, with 1.7 billion parameters that is computationally efficient for resource-constrained environments.
🛠️ Research Methods:
– Overtrained on ~11 trillion tokens using a multi-stage training process combining web text with specialized math, code, and instruction-following data; introduced new specialized datasets and performed small-scale ablations with a manual refinement process for dataset mixing.
💬 Research Conclusions:
– SmolLM2 outperforms other small language models such as Qwen2.5-1.5B and Llama3.2-1B and both the model and datasets are released to support future research in small language models.
👉 Paper link: https://huggingface.co/papers/2502.02737

2. TwinMarket: A Scalable Behavioral and Social Simulation for Financial Markets
🔑 Keywords: Social Emergence, Large Language Models, Agent-Based Models, Socio-Economic Dynamics, Financial Bubbles
💡 Category: AI in Finance
🌟 Research Objective:
– The paper aims to explore how LLM agents can simulate human behavior in socio-economic systems, emphasizing collective dynamics and emergent phenomena.
🛠️ Research Methods:
– The study introduces TwinMarket, a multi-agent framework leveraging LLMs to simulate a stock market environment to observe individual interactions and feedback mechanisms.
💬 Research Conclusions:
– The research demonstrates that individual actions can lead to group behaviors and emergent outcomes like financial bubbles, providing insights into the interplay between individual decision-making and collective socio-economic patterns.
👉 Paper link: https://huggingface.co/papers/2502.01506

3. Demystifying Long Chain-of-Thought Reasoning in LLMs
🔑 Keywords: Reinforcement Learning, Chain-of-Thought, Large Language Models, Error Correction, STEM Reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To systematically investigate the mechanics of long Chain-of-Thought (CoT) reasoning in large language models.
🛠️ Research Methods:
– Extensive supervised fine-tuning and reinforcement learning experiments to explore factors enabling long CoTs.
💬 Research Conclusions:
– Supervised fine-tuning simplifies training, although not necessary.
– Increased training compute encourages reasoning capabilities but requires reward shaping for consistency.
– Verifiable reward signals are crucial, with noisy solutions showing potential for out-of-distribution tasks.
– Core abilities like error correction are inherent but optimizing them for complex tasks demands significant compute and careful measurement.
👉 Paper link: https://huggingface.co/papers/2502.03373

4. LIMO: Less is More for Reasoning
🔑 Keywords: LIMO, Complex Reasoning, Mathematical Reasoning, Less-Is-More Reasoning Hypothesis, Cognitive Templates
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to demonstrate that complex mathematical reasoning in large language models can be effectively achieved with minimal training examples.
🛠️ Research Methods:
– Through comprehensive experiments, the proposed model LIMO is evaluated using 817 curated training samples, significantly less than the conventional requirement.
💬 Research Conclusions:
– LIMO outperformed previous models in mathematical reasoning tasks with far fewer data, suggesting that high performance can be achieved with minimal yet effectively demonstrated cognitive processes.
– Introduces the “Less-Is-More Reasoning Hypothesis,” highlighting the importance of pre-training encoded knowledge and the role of targeted post-training examples as “cognitive templates.”
👉 Paper link: https://huggingface.co/papers/2502.03387

5. Boosting Multimodal Reasoning with MCTS-Automated Structured Thinking
🔑 Keywords: Multimodal large language models, Complex visual reasoning, Monte Carlo Tree Search, Automated Structured thinking, AStar
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to address the inefficiency in complex visual reasoning tasks of multimodal large language models by introducing an Automated Structured thinking paradigm, named AStar.
🛠️ Research Methods:
– AStar employs Monte Carlo Tree Search (MCTS) to automatically derive high-level cognitive reasoning patterns from limited data, integrating models’ internal reasoning capabilities with external guidelines for efficient inference.
💬 Research Conclusions:
– The AStar framework achieves significant improvements in accuracy (54.0%) on the MathVerse benchmark compared to GPT-4o (50.2%), with enhanced data and computational efficiency.
👉 Paper link: https://huggingface.co/papers/2502.02339

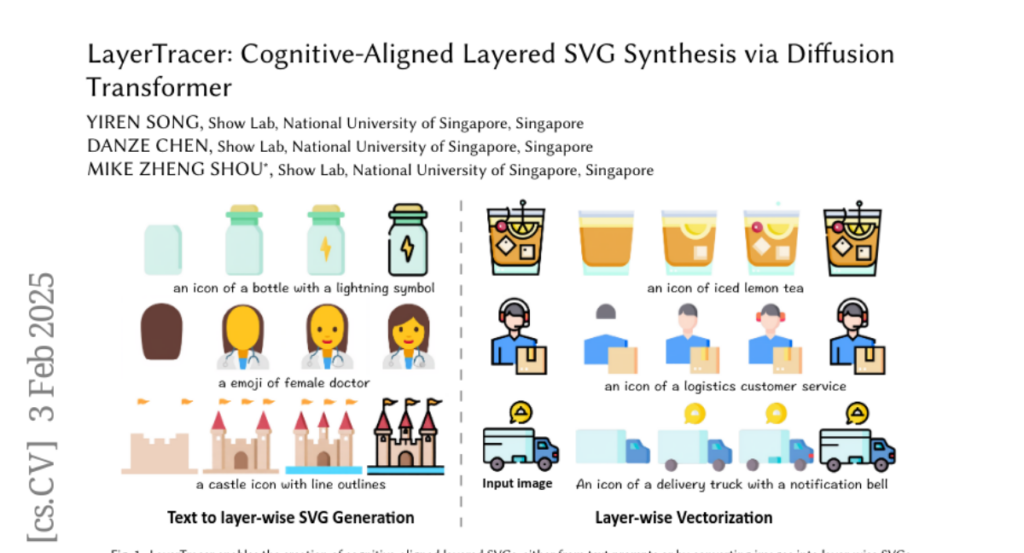
6. LayerTracer: Cognitive-Aligned Layered SVG Synthesis via Diffusion Transformer
🔑 Keywords: Layered SVG, LayerTracer, Diffusion Transformer, Image Vectorization
💡 Category: Generative Models
🌟 Research Objective:
– To address challenges in generating cognitive-aligned layered SVGs by bridging the gap between oversimplification and shape redundancies in existing methods.
🛠️ Research Methods:
– Utilization of a diffusion transformer-based framework, LayerTracer, which learns designers’ processes from a novel dataset of sequential design operations.
– Implementation in two phases: text-conditioned DiT for multi-phase blueprint generation and layer-wise vectorization with path deduplication for clean SVG output.
💬 Research Conclusions:
– LayerTracer demonstrates superior performance in generation quality and editability compared to optimization-based and neural baselines, effectively aligning AI-generated vectors with professional design cognition.
👉 Paper link: https://huggingface.co/papers/2502.01105
7. On Teacher Hacking in Language Model Distillation
🔑 Keywords: Knowledge Distillation, Reinforcement Learning from Human Feedback, Reward Hacking, Teacher Hacking, Data Diversity
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the occurrence of “teacher hacking” during the knowledge distillation process in language models.
🛠️ Research Methods:
– Experimental setup with oracle, teacher, and student language models to analyze distillation effects.
💬 Research Conclusions:
– Teacher hacking can occur with fixed offline datasets; using online data generation and ensuring data diversity helps mitigate this issue.
👉 Paper link: https://huggingface.co/papers/2502.02671

8. A Probabilistic Inference Approach to Inference-Time Scaling of LLMs using Particle-Based Monte Carlo Methods
🔑 Keywords: Large Language Models, Inference-Time Scaling, Probabilistic Inference, Particle-Based Monte Carlo
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve inference-time scaling for large language models using probabilistic inference and sampling-based methods.
🛠️ Research Methods:
– Approaching inference-time scaling as a probabilistic inference task.
– Adapting particle-based Monte Carlo methods to explore the typical set of the state distribution.
💬 Research Conclusions:
– The proposed method achieves 4-16x better scaling rates on mathematical reasoning tasks compared to deterministic search methods.
– Demonstrated Qwen2.5-Math-Instruct variations surpassing GPT-4o accuracy with significantly fewer rollouts.
👉 Paper link: https://huggingface.co/papers/2502.01618
9. Large Language Model Guided Self-Debugging Code Generation
🔑 Keywords: Automated code generation, PyCapsule, AI systems, code parsing, self-debugging
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study introduces PyCapsule, a novel framework aimed at improving computational efficiency, stability, safety, and correctness in Python code generation.
🛠️ Research Methods:
– PyCapsule employs a two-agent pipeline with effective self-debugging modules that include sophisticated prompt inference, iterative error handling, and case testing.
💬 Research Conclusions:
– Empirically, PyCapsule achieves significant improvements in success rates on benchmarks such as HumanEval, HumanEval-ET, and BigCodeBench compared to state-of-the-art methods, although more self-debugging attempts may reduce normalized success rates due to limited and noisy error feedback.
👉 Paper link: https://huggingface.co/papers/2502.02928

10. Jailbreaking with Universal Multi-Prompts
🔑 Keywords: Large Language Models, AI Ethics, Jailbreaking, Universal Multi-Prompts
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the development of universal attackers and defend against them using multi-prompts strategies in LLMs.
🛠️ Research Methods:
– Introduce JUMP for jailbreaking large language models and DUMP for defense, utilizing prompt-based methods.
💬 Research Conclusions:
– The JUMP method for optimizing universal multi-prompts outperforms existing techniques in dealing with unseen tasks.
👉 Paper link: https://huggingface.co/papers/2502.01154

11. Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning
🔑 Keywords: Large Language Models, reasoning, latent discrete tokens, VQ-VAE, hybrid representation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore a hybrid representation method for reasoning in Large Language Models (LLMs) that reduces computational resource consumption and input length.
🛠️ Research Methods:
– Utilizing latent discrete tokens via VQ-VAE to partially summarize initial reasoning steps.
– Implementing a training procedure that mixes latent and text tokens for effective learning.
– Conducting experiments on the Keys-Finding Maze problem and logical/mathematical reasoning problems with this hybrid dataset.
💬 Research Conclusions:
– The proposed method consistently outperforms baseline methods across various benchmarks.
– Demonstrated efficient adaptation to new latent tokens, enhancing reasoning capabilities with extended vocabularies.
👉 Paper link: https://huggingface.co/papers/2502.03275

12. Riddle Me This! Stealthy Membership Inference for Retrieval-Augmented Generation
🔑 Keywords: Retrieval-Augmented Generation, Large Language Models, membership inference, Interrogation Attack
💡 Category: Natural Language Processing
🌟 Research Objective:
– To present the Interrogation Attack, a novel membership inference technique targeting documents in the Retrieval-Augmented Generation (RAG) datastore.
🛠️ Research Methods:
– Using natural-text queries specifically crafted to infer the presence of target documents with high stealth, minimizing detection by standard techniques.
💬 Research Conclusions:
– Demonstrates a 2x improvement in True Positive Rate at 1% False Positive Rate over previous methods across various RAG configurations, while maintaining cost-effective document inference.
👉 Paper link: https://huggingface.co/papers/2502.00306

13. Activation-Informed Merging of Large Language Models
🔑 Keywords: Model merging, Activation-Informed Merging (AIM), large language models (LLMs), continual learning, model compression
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce a technique called Activation-Informed Merging (AIM) to enhance performance and robustness of model merging in large language models.
🛠️ Research Methods:
– Integrate activation space information and utilize a task-agnostic calibration set to selectively prioritize essential weights during model merging.
💬 Research Conclusions:
– AIM significantly enhances merged model performance, demonstrating an up to 40% increase in benchmark performance by leveraging activation-space information.
👉 Paper link: https://huggingface.co/papers/2502.02421

14. HackerRank-ASTRA: Evaluating Correctness & Consistency of Large Language Models on cross-domain multi-file project problems
🔑 Keywords: Large Language Models, Software Development, Model Consistency, Project-Based Scenarios
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to evaluate the real-world applicability of large language models (LLMs) in software development tasks, focusing on project-based coding problems.
🛠️ Research Methods:
– The study introduces the HackerRank-ASTRA Benchmark to assess model consistency through 32 runs and median standard deviation, using taxonomy-level analysis for evaluating sub-skill capabilities.
💬 Research Conclusions:
– Initial evaluations on 65 problems reveal that the top models (o1, o1-preview, and Claude-3.5-Sonnet-1022) have similar average scores of 75%, with Claude-3.5-Sonnet-1022 showing the highest consistency (SD = 0.0497), emphasizing its reliability in real-world software development contexts.
👉 Paper link: https://huggingface.co/papers/2502.00226
