AI Native Daily Paper Digest – 20250207

1. Analyze Feature Flow to Enhance Interpretation and Steering in Language Models
🔑 Keywords: Sparse Autoencoder, Inter-layer Feature Links, Feature Evolution, Text Generation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces a new approach to mapping features discovered by sparse autoencoder across consecutive layers of large language models.
🛠️ Research Methods:
– Utilizes a data-free cosine similarity technique to trace the persistence, transformation, or emergence of specific features at various stages of the model.
💬 Research Conclusions:
– Demonstrates that cross-layer feature maps can steer model behavior by amplifying or suppressing features, achieving thematic control in text generation. The findings suggest a framework for causal interpretability and transparent manipulation of large language models.
👉 Paper link: https://huggingface.co/papers/2502.03032

2. DynVFX: Augmenting Real Videos with Dynamic Content
🔑 Keywords: zero-shot, dynamic content, text-to-video diffusion, Vision Language Model
💡 Category: Generative Models
🌟 Research Objective:
– To develop a method for dynamically augmenting real-world videos with new content based on user-provided text instructions.
🛠️ Research Methods:
– Utilizes a zero-shot, training-free framework with a pre-trained text-to-video diffusion transformer and a pre-trained Vision Language Model.
– Introduces a novel inference-based method manipulating features in the attention mechanism for seamless content integration.
💬 Research Conclusions:
– Demonstrates effectiveness in seamlessly integrating new dynamic objects or effects in videos, maintaining realism and coherence with the original scene over diverse scenarios.
👉 Paper link: https://huggingface.co/papers/2502.03621

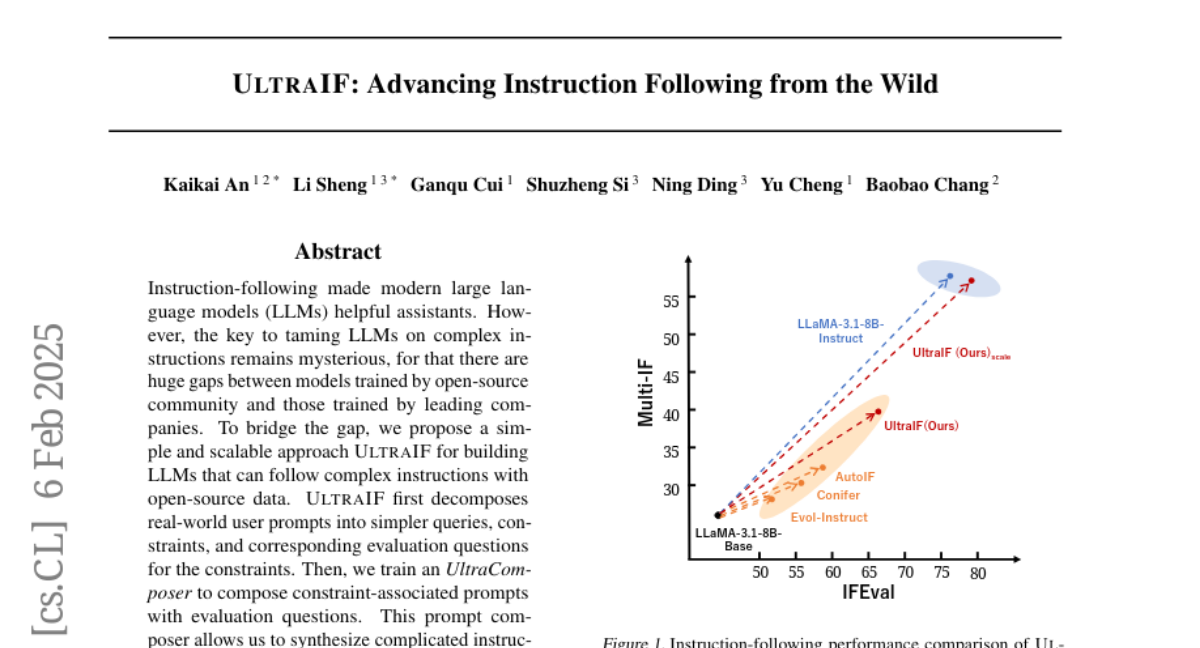
3. UltraIF: Advancing Instruction Following from the Wild
🔑 Keywords: Large Language Models, UltraIF, LLaMA-3.1-8B, Instruction-following, AI Models
💡 Category: Natural Language Processing
🌟 Research Objective:
– To bridge the gap between large language models trained by open-source communities and leading companies by proposing a scalable approach called UltraIF for handling complex instructions.
🛠️ Research Methods:
– UltraIF decomposes complex user prompts into simpler queries and constraints, then trains an UltraComposer to compose these into constraint-associated prompts, enabling synthesis of complex instructions and response filtering.
💬 Research Conclusions:
– UltraIF aligned LLaMA-3.1-8B-Base successfully with its instruct version across multiple benchmarks and improved LLaMA-3.1-8B-Instruct through self-alignment, suggesting broader applicability.
👉 Paper link: https://huggingface.co/papers/2502.04153
4. Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2
🔑 Keywords: AlphaGeometry2, International Math Olympiads, language modeling, geometry problems
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces AlphaGeometry2, aiming to improve the solving of Olympiad geometry problems beyond the average gold medalist level.
🛠️ Research Methods:
– Enhancements include an extended language model for tackling complex problem types and the use of Gemini architecture alongside a novel knowledge-sharing mechanism.
💬 Research Conclusions:
– AlphaGeometry2 increased its problem-solving coverage from 66% to 88% on IMO problems and improved overall solving rate to 84% over 25 years.
👉 Paper link: https://huggingface.co/papers/2502.03544

5. Ola: Pushing the Frontiers of Omni-Modal Language Model with Progressive Modality Alignment
🔑 Keywords: Omni-modal, Language Models, Modality Alignment, Image, Video, Audio
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop Ola, an omni-modal language model that achieves competitive performance across image, video, and audio understanding, compared to specialized single-modality models.
🛠️ Research Methods:
– Implemented a progressive modality alignment strategy, starting with image and text, and gradually integrating speech and video data.
– Developed a sentence-wise decoding solution for streaming speech generation.
💬 Research Conclusions:
– Ola surpasses existing open omni-modal LLMs across all modalities while maintaining a relatively small cross-modal alignment dataset, making it efficient to develop from existing vision-language models. It aims to advance omni-modal understanding for future research.
👉 Paper link: https://huggingface.co/papers/2502.04328

6. Great Models Think Alike and this Undermines AI Oversight
🔑 Keywords: AI Oversight, Language Model, Model Similarity, Weak-to-Strong Generalization
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore AI Oversight by examining how model similarity affects the evaluation and supervision of language models (LMs).
🛠️ Research Methods:
– A probabilistic metric for determining LM similarity based on mistake overlap is proposed and utilized to assess the impact of model similarity.
💬 Research Conclusions:
– It is found that model similarity impacts judgment scores, with a concerning trend of increasing mistake similarity, emphasizing the need to report and address this in AI oversight.
👉 Paper link: https://huggingface.co/papers/2502.04313

7. MotionLab: Unified Human Motion Generation and Editing via the Motion-Condition-Motion Paradigm
🔑 Keywords: Human motion generation, MotionLab, Motion-Condition-Motion, Conditional generation
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to provide a versatile and unified framework for both human motion generation and editing through a novel paradigm called Motion-Condition-Motion.
🛠️ Research Methods:
– The proposed methodology involves using the MotionLab framework, which includes rectified flows, a MotionFlow Transformer for enhancement, Aligned Rotational Position Encoding for time synchronization, Task Specified Instruction Modulation, and Motion Curriculum Learning for effective multi-task learning.
💬 Research Conclusions:
– The MotionLab framework exhibits promising generalization capabilities and inference efficiency across multiple benchmarks in human motion, indicating its potential effectiveness in real-world applications.
👉 Paper link: https://huggingface.co/papers/2502.02358

8. MAGA: MAssive Genre-Audience Reformulation to Pretraining Corpus Expansion
🔑 Keywords: MAGA, pretraining data, synthetic language models, prompt engineering
💡 Category: Natural Language Processing
🌟 Research Objective:
– To address the scarcity of high-quality pretraining data for large language models by proposing the MAssive Genre-Audience (MAGA) reformulation method.
🛠️ Research Methods:
– Introduced MAGA, a scalable and lightweight method for expanding pretraining corpuses, constructing a 770B tokens MAGACorpus and evaluating it with different data scaling strategies.
💬 Research Conclusions:
– Demonstrated that MAGA can consistently enhance model performance across a range of sizes by generating diverse and contextually-rich training datasets, thereby offering a viable solution for overcoming data limitations in scaling models.
👉 Paper link: https://huggingface.co/papers/2502.04235

9. ScoreFlow: Mastering LLM Agent Workflows via Score-based Preference Optimization
🔑 Keywords: Large Language Models, Multi-Agent Systems, Optimization, ScoreFlow, Gradient-Based Optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to optimize multi-agent systems in large language models for complex problem-solving with reduced manual effort.
🛠️ Research Methods:
– Introduces a framework called ScoreFlow utilizing gradient-based optimization in a continuous space, which incorporates a novel method, Score-DPO, for effective preference optimization.
💬 Research Conclusions:
– ScoreFlow demonstrated an 8.2% improvement over existing baselines in benchmarks such as question answering, coding, and mathematical reasoning, allowing smaller models to surpass larger ones with lower inference costs.
👉 Paper link: https://huggingface.co/papers/2502.04306

10. Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis
🔑 Keywords: Large Language Models, TTS systems, Llasa framework, Inference-time compute
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore the scaling of train-time and inference-time compute for speech synthesis.
🛠️ Research Methods:
– Proposed a simple framework named Llasa using a single-layer vector quantizer (VQ) codec and a Transformer architecture aligned with LLMs like Llama.
💬 Research Conclusions:
– Scaling train-time compute improves speech naturalness and complex prosody patterns.
– Scaling inference-time compute with speech understanding models enhances emotional expressiveness, timbre consistency, and content accuracy.
– Released the TTS model checkpoint and training code publicly.
👉 Paper link: https://huggingface.co/papers/2502.04128

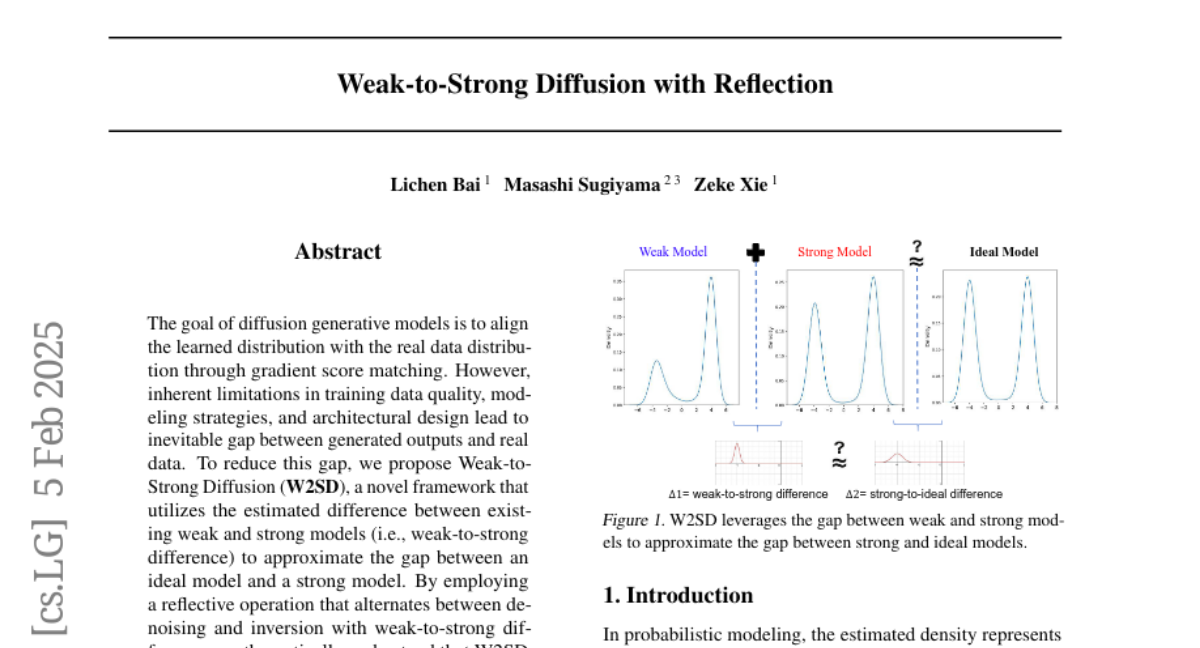
11. Weak-to-Strong Diffusion with Reflection
🔑 Keywords: Diffusion Generative Models, Weak-to-Strong Diffusion, SOTA Performance, Latent Variables
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to address the inherent limitations in diffusion generative models by proposing the Weak-to-Strong Diffusion (W2SD) framework to reduce the gap between generated outputs and real data.
🛠️ Research Methods:
– W2SD utilizes the estimated difference between weak and strong models to guide latent variables along sampling trajectories, alternating between denoising and inversion operations.
💬 Research Conclusions:
– W2SD significantly enhances human preference, aesthetic quality, and prompt adherence, achieving state-of-the-art (SOTA) performance across different modalities and architectures, with performance gains that outweigh the additional computational overhead.
👉 Paper link: https://huggingface.co/papers/2502.00473
12. ConceptAttention: Diffusion Transformers Learn Highly Interpretable Features
🔑 Keywords: Multi-Modal Diffusion Transformers, DiT, ConceptAttention, Saliency Maps, Zero-Shot Image Segmentation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Investigate the unique properties of Multi-Modal Diffusion Transformers (DiTs) to enhance their interpretability.
🛠️ Research Methods:
– Introduced a novel method, ConceptAttention, which repurposes DiT attention layers for generating high-quality saliency maps, leveraging their rich representations without additional training.
💬 Research Conclusions:
– ConceptAttention outperformed 11 other zero-shot interpretability methods in benchmarks like ImageNet-Segmentation and a subset of PascalVOC, providing the first evidence that DiT models’ representations are highly transferable to vision tasks like segmentation.
👉 Paper link: https://huggingface.co/papers/2502.04320

13. MotionCanvas: Cinematic Shot Design with Controllable Image-to-Video Generation
🔑 Keywords: MotionCanvas, image-to-video, shot design, video diffusion models
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to develop a method, MotionCanvas, for intuitive cinematic shot design in image-to-video generation systems.
🛠️ Research Methods:
– Integrates user-driven controls into I2V models to allow 3D-aware motion control without requiring expensive 3D training data by leveraging insights from classical graphics and contemporary video techniques.
💬 Research Conclusions:
– MotionCanvas successfully enhances creative workflows in digital content creation by enabling intuitive control of scene-space motions and adapts to various image and video editing scenarios.
👉 Paper link: https://huggingface.co/papers/2502.04299

14. BOLT: Bootstrap Long Chain-of-Thought in Language Models without Distillation
🔑 Keywords: Large language models, LongCoT, BOLT, Knowledge Distillation, Llama-3.1-70B-Instruct
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce a novel approach (BOLT) to enable LongCoT capacity in LLMs without relying on o1-like models or expensive annotations.
🛠️ Research Methods:
– Utilized a three-stage process: in-context bootstrapping, supervised finetuning, and online training, with minimal example construction (10 examples used).
💬 Research Conclusions:
– Achieved impressive performance on benchmarks like Arena-Hard and MATH500, demonstrating the effectiveness of BOLT in enhancing task-solving and reasoning capabilities across various model scales.
👉 Paper link: https://huggingface.co/papers/2502.03860

15. PILAF: Optimal Human Preference Sampling for Reward Modeling
🔑 Keywords: Reinforcement Learning, Human Values, RLHF, Reward Models, Policy-Interpolated Learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to address the alignment of large language models with human values by improving preference alignment techniques.
🛠️ Research Methods:
– Introduces Policy-Interpolated Learning for Aligned Feedback (PILAF), a response sampling strategy designed to optimize preference learning in reinforcement learning from human feedback.
💬 Research Conclusions:
– PILAF is theoretically optimal from optimization and statistical perspectives and is effective in both iterative and online RLHF environments, enhancing the alignment of preference learning with underlying reward models.
👉 Paper link: https://huggingface.co/papers/2502.04270

16. ChartCitor: Multi-Agent Framework for Fine-Grained Chart Visual Attribution
🔑 Keywords: Large Language Models, Answer Attribution, Generative AI, Explainability
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to improve chart question-answering performance by developing a framework called ChartCitor that provides fine-grained bounding box citations.
🛠️ Research Methods:
– A multi-agent framework is used to conduct chart-to-table extraction, answer reformulation, table augmentation, and evidence retrieval, culminating in table-to-chart mapping for effective answer attribution.
💬 Research Conclusions:
– ChartCitor achieves superior performance over existing baselines and enhances user trust in Generative AI by improving the explainability of chart question-answering tasks, thus boosting professionals’ productivity.
👉 Paper link: https://huggingface.co/papers/2502.00989

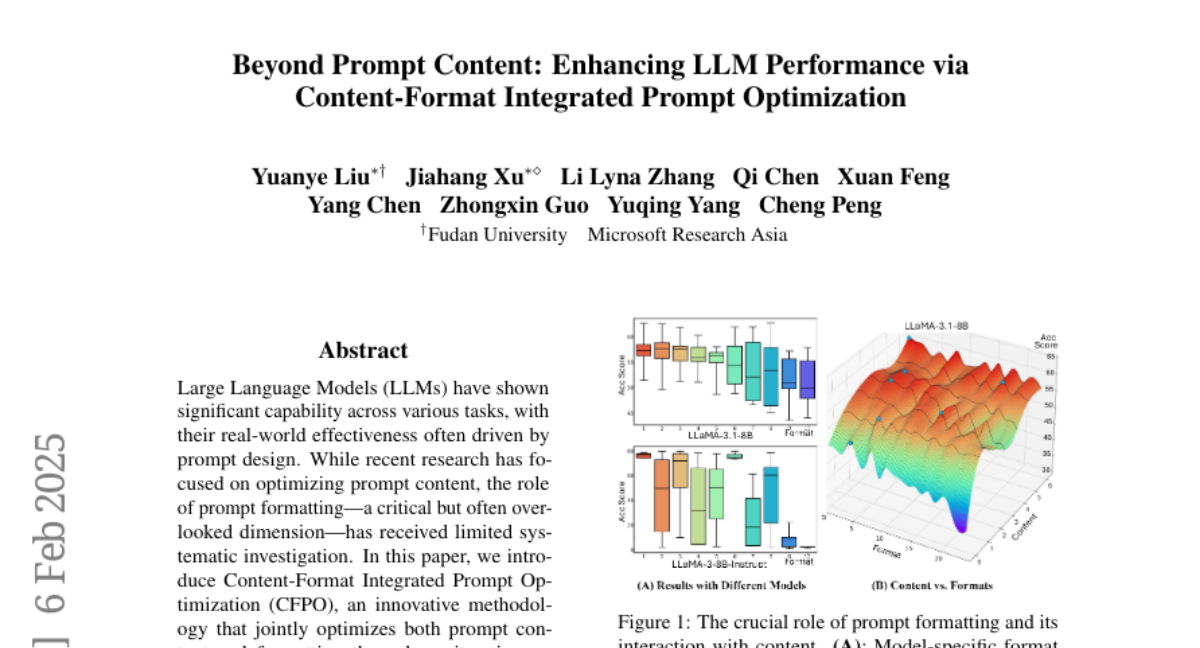
17. Beyond Prompt Content: Enhancing LLM Performance via Content-Format Integrated Prompt Optimization
🔑 Keywords: Large Language Models, Content-Format Integrated Prompt Optimization, natural language mutations, dynamic format exploration
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Content-Format Integrated Prompt Optimization (CFPO) to enhance the effectiveness of prompt design in LLMs.
🛠️ Research Methods:
– Utilize an iterative refinement process integrating natural language mutations for content variation and dynamic format exploration to evaluate diverse formatting options.
💬 Research Conclusions:
– CFPO shows measurable performance improvements over content-only optimization methods, emphasizing the importance of integrated optimization for better LLM performance.
👉 Paper link: https://huggingface.co/papers/2502.04295
18. Towards Physical Understanding in Video Generation: A 3D Point Regularization Approach
🔑 Keywords: video generation, 3D geometry, latent diffusion model, task-oriented videos, 3D consistency
💡 Category: Generative Models
🌟 Research Objective:
– To create a novel video generation framework that integrates 3D geometry and dynamic awareness for improved video quality.
🛠️ Research Methods:
– Augmenting 2D videos with 3D point trajectories and aligning them in pixel space to fine-tune a latent diffusion model.
– Regularizing object shape and motion to eliminate undesired artifacts like nonphysical deformations.
💬 Research Conclusions:
– Enhanced the quality of generated RGB videos by addressing common issues such as object morphing, improving 3D consistency in task-oriented scenarios.
👉 Paper link: https://huggingface.co/papers/2502.03639

19. Enhancing Code Generation for Low-Resource Languages: No Silver Bullet
🔑 Keywords: Large Language Models, automated code generation, low-resource languages, fine-tuning, in-context learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore and enhance techniques for improving the performance of Large Language Models (LLMs) on low-resource programming languages.
🛠️ Research Methods:
– The research conducts an empirical study with several approaches including fine-tuning, in-context learning with crafted prompts, and a pre-training objective related to language translation.
💬 Research Conclusions:
– Fine-tuning is generally more effective for smaller LLMs due to smaller parameter architectures.
– In-context learning becomes increasingly effective with larger models, offering a consistent improvement in performance.
– Very large LLMs might experience performance degradation when fine-tuning is applied due to insufficient data for effective parameter updates.
👉 Paper link: https://huggingface.co/papers/2501.19085

20. PlotGen: Multi-Agent LLM-based Scientific Data Visualization via Multimodal Feedback
🔑 Keywords: Scientific data visualization, Large Language Models, PlotGen, Multi-agent framework
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To propose PlotGen, a framework automating precise scientific visualizations through orchestrated LLM-based agents.
🛠️ Research Methods:
– Utilizing multiple LLM-based agents, including Query Planning and Code Generation Agents, alongside retrieval feedback agents using multimodal LLMs for iterative refinement.
💬 Research Conclusions:
– PlotGen achieves a 4-6% performance improvement on the MatPlotBench dataset, enhancing user trust and productivity by reducing debugging time.
👉 Paper link: https://huggingface.co/papers/2502.00988

21. Speak Easy: Eliciting Harmful Jailbreaks from LLMs with Simple Interactions
🔑 Keywords: Jailbreak attacks, Large language models (LLMs), Safety vulnerabilities, Human-LLM interactions
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– Investigate the effectiveness of LLM jailbreaks in enabling harmful actions and explore vulnerabilities in common human-LLM interactions.
🛠️ Research Methods:
– Developed HarmScore metric for assessing LLM response impact and introduced Speak Easy, a multilingual attack framework.
💬 Research Conclusions:
– Revealed that simple, common interaction patterns can be exploited for harmful intentions, with increased attack success rates and HarmScore.
👉 Paper link: https://huggingface.co/papers/2502.04322

22. Learning Real-World Action-Video Dynamics with Heterogeneous Masked Autoregression
🔑 Keywords: Heterogeneous Masked Autoregression, Robotics, Video Predictions, Interactive Video Models
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective of the research is to model action-video dynamics for generating high-quality data and scaling robot learning using the proposed Heterogeneous Masked Autoregression (HMA).
🛠️ Research Methods:
– The research employs heterogeneous pre-training from observations and action sequences across different robotic embodiments, domains, and tasks to implement HMA. It utilizes masked autoregression for generating quantized or soft tokens for video predictions.
💬 Research Conclusions:
– The conclusions highlight that HMA achieves better visual fidelity and controllability compared to previous models, delivering video predictions 15 times faster in real-world applications, and can function as a video simulator for evaluating policies and generating synthetic data post-training.
👉 Paper link: https://huggingface.co/papers/2502.04296
