AI Native Daily Paper Digest – 20250213
1. Fino1: On the Transferability of Reasoning Enhanced LLMs to Finance
🔑 Keywords: Large Language Models, Financial Reasoning, CoT Fine-Tuning, Reinforcement Learning, Llama
💡 Category: AI in Finance
🌟 Research Objective:
– Evaluate the effectiveness of large language models in complex financial tasks involving text, tables, and equations.
🛠️ Research Methods:
– Comprehensive assessment of 16 reasoning and general LLMs with a focus on numerical reasoning, tabular interpretation, and equation solving.
– Development and fine-tuning of a financial reasoning-enhanced model utilizing CoT fine-tuning and reinforcement learning.
💬 Research Conclusions:
– General enhancements like CoT fine-tuning do not consistently improve financial reasoning, highlighting the necessity for domain-specific adaptations.
– The newly developed model shows a consistent 10% performance improvement across tasks, outperforming existing models.
– Emphasizes future research directions such as multi-table reasoning and financial terminology comprehension.
👉 Paper link: https://huggingface.co/papers/2502.08127

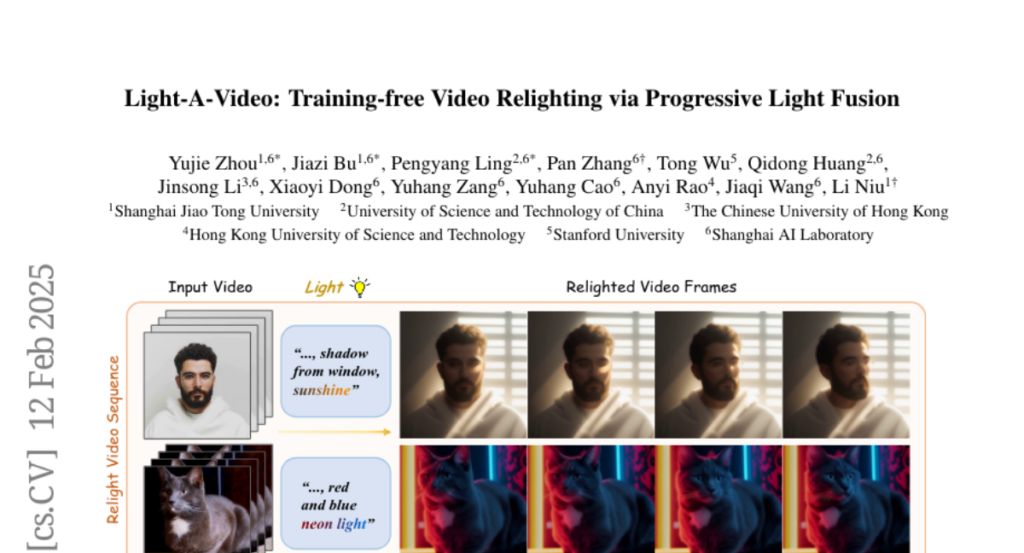
2. Light-A-Video: Training-free Video Relighting via Progressive Light Fusion
🔑 Keywords: video relighting, Consistent Light Attention, Progressive Light Fusion, training-free, temporal consistency
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a training-free approach for achieving temporally smooth video relighting.
🛠️ Research Methods:
– Introduction of the Consistent Light Attention (CLA) module to enhance cross-frame interactions and stabilize background lighting.
– Use of Progressive Light Fusion (PLF) to ensure smooth temporal transitions in video relighting by blending source and relighted appearances.
💬 Research Conclusions:
– Light-A-Video significantly improves the temporal consistency of relighted videos while maintaining high image quality and ensuring coherent lighting transitions across frames.
👉 Paper link: https://huggingface.co/papers/2502.08590
3. TextAtlas5M: A Large-scale Dataset for Dense Text Image Generation
🔑 Keywords: Text-conditioned image generation, TextAtlas5M, Long-text rendering
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to address the challenge of generating images with long-form text by introducing a new dataset, TextAtlas5M, for evaluating long-text rendering in text-conditioned image generation.
🛠️ Research Methods:
– Created TextAtlas5M, comprising 5 million long-text generated and collected images across diverse data types and a human-improved test set of 3000 images (TextAtlasEval) across three data domains to establish a comprehensive benchmark.
💬 Research Conclusions:
– The TextAtlasEval benchmarks reveal significant challenges for advanced proprietary models and even larger gaps for open-source models, highlighting the dataset’s value for training and evaluating future-generation text-conditioned image generation models.
👉 Paper link: https://huggingface.co/papers/2502.07870

4. BenchMAX: A Comprehensive Multilingual Evaluation Suite for Large Language Models
🔑 Keywords: BenchMAX, multilingual evaluation, instruction following, reasoning, translation challenge
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce BenchMAX for evaluating advanced language model capabilities across languages.
🛠️ Research Methods:
– Use three native-speaking annotators for independent annotation of machine-translated samples.
💬 Research Conclusions:
– BenchMAX highlights significant performance gaps across languages that scaling model size cannot overcome.
👉 Paper link: https://huggingface.co/papers/2502.07346

5. CineMaster: A 3D-Aware and Controllable Framework for Cinematic Text-to-Video Generation
🔑 Keywords: 3D-aware, text-to-video generation, CineMaster, controllability, data annotation
💡 Category: Generative Models
🌟 Research Objective:
– Present CineMaster, a framework for 3D-aware and controllable text-to-video generation to allow users controlled filmmaking comparable to professionals.
🛠️ Research Methods:
– Implement a two-stage process that includes an interactive workflow for constructing 3D-aware conditional signals and leveraging these signals in a text-to-video diffusion model.
– Develop an automated data annotation pipeline to address the scarcity of 3D motion datasets.
💬 Research Conclusions:
– CineMaster significantly outperforms existing methods, showcasing advanced capabilities in 3D-aware text-to-video generation.
👉 Paper link: https://huggingface.co/papers/2502.08639

6. TransMLA: Multi-head Latent Attention Is All You Need
🔑 Keywords: Large Language Models, Multi-head Latent Attention, Inference Acceleration, Deepseek, TransMLA
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address communication bottlenecks in large language models on current hardware by introducing Multi-head Latent Attention (MLA).
🛠️ Research Methods:
– Utilize low-rank matrices in key-value layers for compressing and caching latent states.
– Introduce TransMLA to convert Group Query Attention-based models into MLA-based models for improved efficiency.
💬 Research Conclusions:
– MLA reduces KV cache size and inference time while increasing expressiveness.
– Demonstrated potential for broader use with TransMLA converting existing models without increasing KV cache size.
👉 Paper link: https://huggingface.co/papers/2502.07864

7. WorldGUI: Dynamic Testing for Comprehensive Desktop GUI Automation
🔑 Keywords: GUI agents, GUI element grounding, WorldGUI, GUI-Thinker, critical-thinking
💡 Category: Human-AI Interaction
🌟 Research Objective:
– Develop WorldGUI to assess the impact of varying initial GUI states on planning accuracy in GUI automation tasks.
🛠️ Research Methods:
– Introduce a benchmark, WorldGUI, that simulates real user interactions across multiple software applications.
– Propose GUI-Thinker, a comprehensive framework using critique mechanisms to tackle unpredictability in GUI interactions.
💬 Research Conclusions:
– GUI-Thinker significantly improves GUI automation success rates by 14.9% compared to existing models like Claude-3.5, demonstrating enhanced effectiveness in dynamic GUI environments.
👉 Paper link: https://huggingface.co/papers/2502.08047

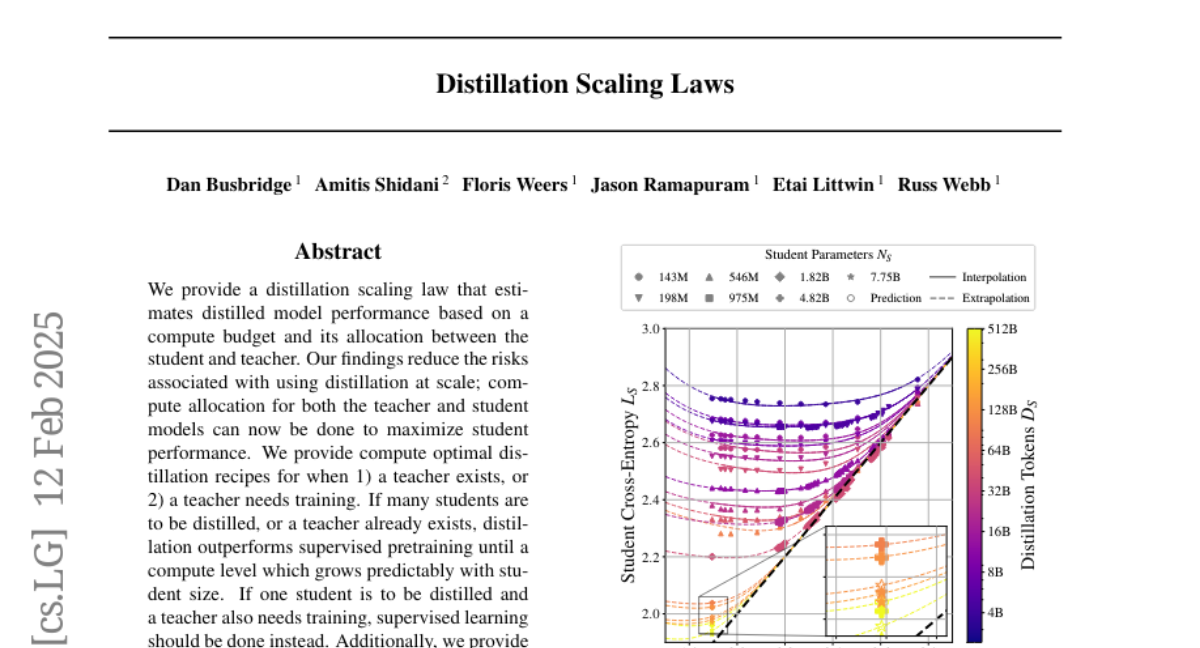
8. Distillation Scaling Laws
🔑 Keywords: Distillation Scaling Law, Compute Budget, Teacher Model, Student Model
💡 Category: Machine Learning
🌟 Research Objective:
– The paper aims to establish a distillation scaling law that estimates the performance of distilled models based on the compute budget allocation between student and teacher models, reducing risks associated with large-scale distillation.
🛠️ Research Methods:
– The study analyzes compute allocation for maximizing student performance through distillation, offering optimal recipes for scenarios where a teacher is pre-existing or requires training.
💬 Research Conclusions:
– Distillation is more effective than supervised pretraining when many students are involved or if a teacher already exists. However, if only one student is to be distilled and a teacher also needs training, supervised learning is advised. The study enhances understanding of distillation and aids in experimental design.
👉 Paper link: https://huggingface.co/papers/2502.08606
9. LASP-2: Rethinking Sequence Parallelism for Linear Attention and Its Hybrid
🔑 Keywords: Linear attention, Sequence parallelism, LASP-2, LASP-2H
💡 Category: Machine Learning
🌟 Research Objective:
– To enhance communication and computation parallelism in training linear attention transformer models with very-long input sequences using a novel SP method called LASP-2.
🛠️ Research Methods:
– Introduction of LASP-2 which rethinks the minimal communication needs and reorganizes the communication-computation workflow for linear attention models.
– Complementary extension to LASP-2H for hybrid models that integrate linear and standard attention layers to improve SP efficiency.
💬 Research Conclusions:
– LASP-2 achieves considerable training speed improvements: 15.2% over LASP and 36.6% over Ring Attention, with a sequence length of 2048K across 64 GPUs.
👉 Paper link: https://huggingface.co/papers/2502.07563

10. DPO-Shift: Shifting the Distribution of Direct Preference Optimization
🔑 Keywords: Direct Preference Optimization, likelihood displacement, downstream tasks, MT-Bench, distribution shift
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces a new method, \method, to address the likelihood displacement issue in Direct Preference Optimization (DPO) to improve alignment of language models with human preferences.
🛠️ Research Methods:
– A theoretical and experimental analysis demonstrates a trade-off between enhancing chosen response probabilities and sacrificing reward margins, showcasing the method’s effectiveness compared to existing DPO on tasks like MT-Bench.
💬 Research Conclusions:
– The study concludes that \method effectively mitigates the likelihood displacement problem in DPO, offering a simple and theoretically grounded approach, validated by experiments such as a designed win rate test.
👉 Paper link: https://huggingface.co/papers/2502.07599

11. SARChat-Bench-2M: A Multi-Task Vision-Language Benchmark for SAR Image Interpretation
🔑 Keywords: SARChat-2M, Vision Language Models, multimodal datasets, SAR images, object detection
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To propose and develop the first large-scale multimodal dialogue dataset for synthetic aperture radar (SAR) images, named SARChat-2M.
🛠️ Research Methods:
– Creation of SARChat-2M, a dataset consisting of approximately 2 million high-quality image-text pairs with diverse scenarios and detailed target annotations.
– Conduct experiments on 16 mainstream Vision Language Models (VLMs) to verify the effectiveness of the dataset.
💬 Research Conclusions:
– The proposed dataset supports several tasks such as visual understanding and object detection in the SAR domain.
– Establishes the first multi-task dialogue benchmark in the SAR field.
– The project aims to promote further development and application of SAR visual language models.
👉 Paper link: https://huggingface.co/papers/2502.08168

12. Ignore the KL Penalty! Boosting Exploration on Critical Tokens to Enhance RL Fine-Tuning
🔑 Keywords: large language models, reinforcement learning, exploration, fine-tuning, critical tokens
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to address the challenge of achieving long-term goals in large language models (LLMs) by utilizing reinforcement learning (RL) for fine-tuning these models.
🛠️ Research Methods:
– Investigation of exploration dynamics in a small language model using a simple arithmetic task, examining the impact of pre-training on exploration and the role of critical tokens.
💬 Research Conclusions:
– Introduction of a modification to the KL penalty that enhances RL fine-tuning efficiency by favoring exploration on critical tokens.
👉 Paper link: https://huggingface.co/papers/2502.06533

13. LLM Pretraining with Continuous Concepts
🔑 Keywords: Next token prediction, Continuous Concept Mixing, Sparse autoencoder, Interpretability, Sample efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduces Continuous Concept Mixing (CoCoMix) to combine discrete next token prediction with continuous concepts for improved language model pretraining.
🛠️ Research Methods:
– Utilizes CoCoMix which integrates continuous concepts from a pretrained sparse autoencoder with token hidden representations to enhance model performance.
💬 Research Conclusions:
– CoCoMix demonstrates higher sample efficiency and outperforms traditional training objectives, enhancing both interpretability and steerability by enabling inspection and modification of predicted concepts.
👉 Paper link: https://huggingface.co/papers/2502.08524

14. PDE-Controller: LLMs for Autoformalization and Reasoning of PDEs
🔑 Keywords: PDE-Controller, Partial Differential Equations, LLMs, Generative Models, AI Native
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces a framework called PDE-Controller to leverage large language models (LLMs) for controlling systems governed by partial differential equations (PDEs).
🛠️ Research Methods:
– The approach involves transforming informal natural language instructions into formal specifications, utilizing datasets, and implementing math-reasoning models along with novel evaluation metrics.
💬 Research Conclusions:
– The PDE-Controller significantly improves reasoning, autoformalization, and program synthesis with up to a 62% utility gain in PDE control and underscores the capability of LLMs in tackling complex scientific and engineering issues.
👉 Paper link: https://huggingface.co/papers/2502.00963

15. Next Block Prediction: Video Generation via Semi-Autoregressive Modeling
🔑 Keywords: Next-Token Prediction, Semi-Autoregressive, Bidirectional Attention, Video Generation
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to improve video generation methods by replacing traditional autoregressive models with a semi-autoregressive framework called Next-Block Prediction (NBP).
🛠️ Research Methods:
– Video content is uniformly divided into blocks, and bidirectional attention is used within blocks to capture spatial dependencies, allowing simultaneous prediction of multiple tokens for faster inference.
💬 Research Conclusions:
– The NBP model demonstrates better performance with improved FVD scores on UCF101 and K600 datasets, achieving significant speedup in video generation, and showing scalable improvements with models ranging from 700M to 3B parameters.
👉 Paper link: https://huggingface.co/papers/2502.07737

16. NoLiMa: Long-Context Evaluation Beyond Literal Matching
🔑 Keywords: Large Language Models, Contextual Attention, Needle-in-a-Haystack, Semantic Reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the limitations of large language models in long-context scenarios by introducing a benchmark called NoLiMa that reduces lexical overlap and requires semantic reasoning.
🛠️ Research Methods:
– Development and implementation of NoLiMa benchmark, assessing 12 popular large language models with contexts of at least 128K tokens.
💬 Research Conclusions:
– Performance of language models drastically declines in longer contexts without literal matches, evidenced by significant drops in accuracy at increased token lengths.
👉 Paper link: https://huggingface.co/papers/2502.05167

17. Animate Anyone 2: High-Fidelity Character Image Animation with Environment Affordance
🔑 Keywords: Animate Anyone, environment affordance, diffusion models, object interactions, pose modulation
💡 Category: Computer Vision
🌟 Research Objective:
– To animate characters with environment affordance by capturing environmental representations as conditional inputs.
🛠️ Research Methods:
– Introduced shape-agnostic mask strategy and an object guider for enhanced object interaction fidelity.
– Proposed pose modulation strategy for handling diverse motion patterns.
💬 Research Conclusions:
– The proposed method demonstrates superior performance in generating coherent character animations with environmental context.
👉 Paper link: https://huggingface.co/papers/2502.06145

18. Towards Trustworthy Retrieval Augmented Generation for Large Language Models: A Survey
🔑 Keywords: Retrieval-Augmented Generation, Artificial Intelligence-Generated Content, robustness, privacy, accountability
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– The paper aims to provide a comprehensive roadmap for developing trustworthy Retrieval-Augmented Generation (RAG) systems by addressing critical risks impacting trustworthiness, such as robustness, privacy, and accountability.
🛠️ Research Methods:
– The authors discuss five key perspectives: reliability, privacy, safety, fairness, explainability, and accountability, and present a general framework and taxonomy to evaluate current challenges and solutions.
💬 Research Conclusions:
– The study highlights the importance of a structured approach in understanding challenges and encourages broader adoption and innovation in downstream applications where trustworthy RAG systems can have a significant impact.
👉 Paper link: https://huggingface.co/papers/2502.06872

19. Mediator: Memory-efficient LLM Merging with Less Parameter Conflicts and Uncertainty Based Routing
🔑 Keywords: Model merging, Large Language Models, Parameter conflicts, Sparse experts, Task uncertainty
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve the aggregation of Large Language Models (LLMs) fine-tuned on diverse tasks by addressing parameter conflicts without incurring high storage and compute costs.
🛠️ Research Methods:
– Utilize varying levels of layer parameter conflicts to average layers with minimal conflicts and apply a task-level expert routing for significant conflicts.
– Decouple fine-tuned experts into dense and sparse counterparts inspired by task arithmetic sparsity for reduced storage.
– Merge experts based on task uncertainty of input data out-of-distribution.
💬 Research Conclusions:
– This method achieves consistent performance improvements in reasoning tasks with less system cost compared to existing techniques.
👉 Paper link: https://huggingface.co/papers/2502.04411

20. MetaSC: Test-Time Safety Specification Optimization for Language Models
🔑 Keywords: Dynamic Safety Framework, Language Models, Safety Optimization, Self-Critique, Adversarial Requests
💡 Category: Natural Language Processing
🌟 Research Objective:
– Propose a dynamic safety framework to optimize language model safety reasoning at inference time without altering model weights.
🛠️ Research Methods:
– Utilize a meta-critique mechanism with iterative safety prompts updates to enhance critique and revision processes.
💬 Research Conclusions:
– The dynamic approach significantly improves safety scores in language models for adversarial and general safety-related tasks compared to fixed prompts and static defenses.
👉 Paper link: https://huggingface.co/papers/2502.07985

21. LLM Modules: Knowledge Transfer from a Large to a Small Model using Enhanced Cross-Attention
🔑 Keywords: LLM Modules, Enhanced Cross-Attention, Qwen2-1.5B, GPT-Neo-125M, Modular approach
💡 Category: Natural Language Processing
🌟 Research Objective:
– Propose an architecture that enables knowledge transfer from a large pre-trained model to a smaller one using Enhanced Cross-Attention.
🛠️ Research Methods:
– Utilization of a frozen Qwen2-1.5B model and specially designed attention layers to train the GPT-Neo-125M model with limited computational resources.
💬 Research Conclusions:
– The combined model after training shows quality responses comparable to distillation, demonstrating the advantages and potential extensions of the modular approach.
👉 Paper link: https://huggingface.co/papers/2502.08213

22. Homeomorphism Prior for False Positive and Negative Problem in Medical Image Dense Contrastive Representation Learning
🔑 Keywords: Dense contrastive representation learning, medical image, false positive and negative pairs, homeomorphism, GEMINI
💡 Category: AI in Healthcare
🌟 Research Objective:
– Enhance the efficiency and reliability of Dense contrastive representation learning for medical images by addressing the issue of unreliable correspondence discovery.
🛠️ Research Methods:
– Introduction of GEoMetric vIsual deNse sImilarity (GEMINI) learning which includes deformable homeomorphism learning (DHL) for reliable correspondence discovery and geometric semantic similarity (GSS) for effective semantic alignment.
💬 Research Conclusions:
– GEMINI demonstrates superior performance over existing methods across seven datasets, showing its potential in improving learning efficiency and deformation performance in medical imaging tasks.
👉 Paper link: https://huggingface.co/papers/2502.05282
