AI Native Daily Paper Digest – 20250219

1. Soundwave: Less is More for Speech-Text Alignment in LLMs
🔑 Keywords: Efficient Training, Speech Large Language Models, Soundwave, Representation Space Gap, Sequence Length Inconsistency
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance data-efficient training in end-to-end speech large language models by addressing the representation space gap and sequence length inconsistency between speech and text.
🛠️ Research Methods:
– The introduction of Soundwave, a novel architecture employing an efficient training strategy that significantly reduces the need for large-scale annotated data.
💬 Research Conclusions:
– Soundwave demonstrates superior performance in speech translation and AIR-Bench speech tasks compared to Qwen2-Audio, using only one-fiftieth of the training data, while maintaining conversational intelligence.
👉 Paper link: https://huggingface.co/papers/2502.12900

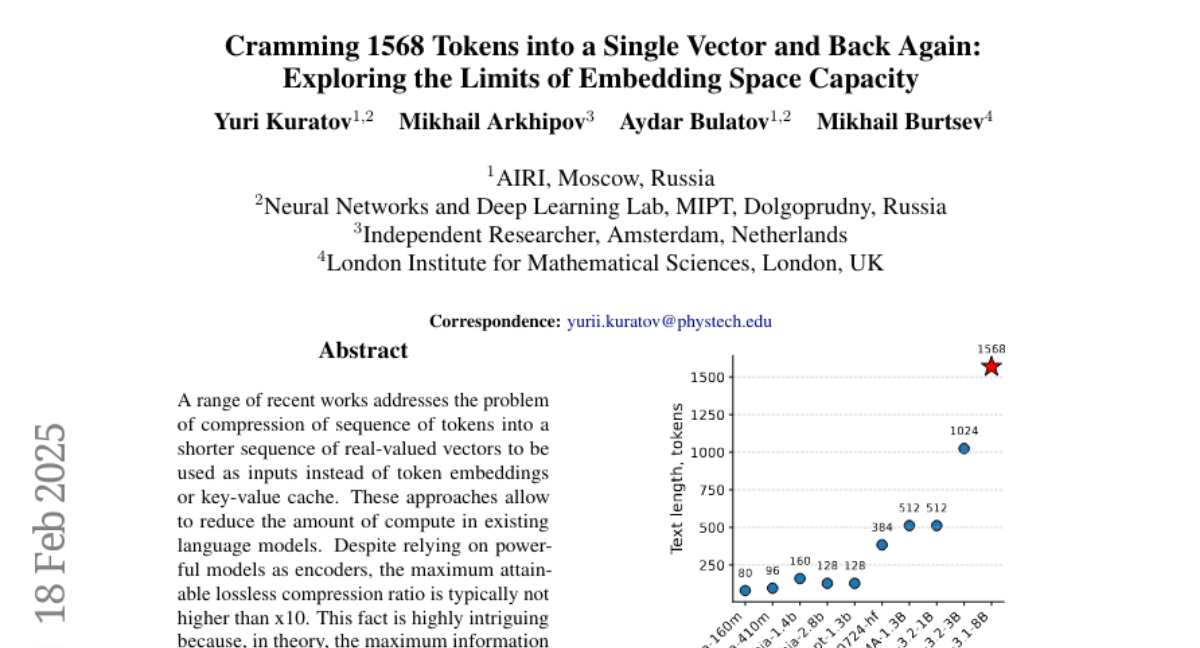
2. Cramming 1568 Tokens into a Single Vector and Back Again: Exploring the Limits of Embedding Space Capacity
🔑 Keywords: Compression, Sequence of Tokens, Real-Valued Vectors, Cross-Entropy Loss, Model Optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore the limits of compressing sequences of tokens into shorter sequences of real-valued vectors for use in language models.
🛠️ Research Methods:
– The authors replace traditional encoders with a per-sample optimization procedure to achieve higher compression ratios.
💬 Research Conclusions:
– The research demonstrates that compression ratios of up to x1500 are achievable, identifying a significant gap between current methods and practical potential. The limits are influenced by cross-entropy loss rather than input length, indicating room for optimization in model design.
👉 Paper link: https://huggingface.co/papers/2502.13063
3. Continuous Diffusion Model for Language Modeling
🔑 Keywords: Diffusion models, discrete categorical data, language modeling, statistical manifold
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose a continuous diffusion model for language modeling that utilizes the geometry of the categorical distribution and improves upon existing discrete diffusion models.
🛠️ Research Methods:
– Establishing the connection between discrete diffusion and continuous flow on the statistical manifold, and generalizing previous discrete diffusion models.
– Implementing a simulation-free training framework based on radial symmetry to handle high dimensionality.
💬 Research Conclusions:
– The proposed method outperforms existing discrete diffusion models and approaches the performance of autoregressive models in language modeling benchmarks.
👉 Paper link: https://huggingface.co/papers/2502.11564

4. Phantom: Subject-consistent video generation via cross-modal alignment
🔑 Keywords: Subject-to-Video, Phantom, cross-modal alignment, subject consistency, video generation
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to explore subject-consistent video generation by balancing dual-modal prompts of text and image through a process called Subject-to-Video.
🛠️ Research Methods:
– Introduction of Phantom, a unified framework that builds on text-to-video and image-to-video architectures, employing a redesigned joint text-image injection model to achieve cross-modal alignment with text-image-video triplet data.
💬 Research Conclusions:
– Phantom emphasizes subject consistency in video generation, enhancing advantages in human ID-preserving video production while achieving alignment between textual instructions and visual content.
👉 Paper link: https://huggingface.co/papers/2502.11079
5. Rethinking Diverse Human Preference Learning through Principal Component Analysis
🔑 Keywords: Personalized AI, Decomposed Reward Models (DRMs), Principal Component Analysis (PCA), Interpretable LLM Alignment
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To improve foundation models and build personalized AI systems by understanding diverse and complex human preferences through Decomposed Reward Models (DRMs).
🛠️ Research Methods:
– Utilized DRMs to extract diverse preferences from binary comparisons without fine-grained annotations.
– Applied Principal Component Analysis (PCA) to represent human preferences as vectors and identify distinct preference aspects through orthogonal basis vectors.
💬 Research Conclusions:
– Demonstrated that DRMs effectively extract meaningful preference dimensions such as helpfulness, safety, and humor.
– Showed that DRMs can adapt to new users without additional training, providing a scalable and interpretable alternative to traditional reward models for personalized LLM alignment.
👉 Paper link: https://huggingface.co/papers/2502.13131

6. Magma: A Foundation Model for Multimodal AI Agents
🔑 Keywords: Magma, multimodal AI, spatial-temporal intelligence, trace-of-mark, agentic tasks
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Magma, a foundation model designed to perform multimodal AI agentic tasks in both digital and physical environments, extending the capabilities of vision-language models.
🛠️ Research Methods:
– Magma is pretrained on large multimodal datasets including images, videos, and robotics data. Uses Set-of-Mark (SoM) and Trace-of-Mark (ToM) for labeling actionable objects and planning actions to enhance spatial-temporal intelligence.
💬 Research Conclusions:
– Magma achieves state-of-the-art results in UI navigation and robotic manipulation tasks, and competes effectively with large multimodal models on image and video-related tasks, proving its enhanced capabilities with significantly smaller datasets.
👉 Paper link: https://huggingface.co/papers/2502.13130

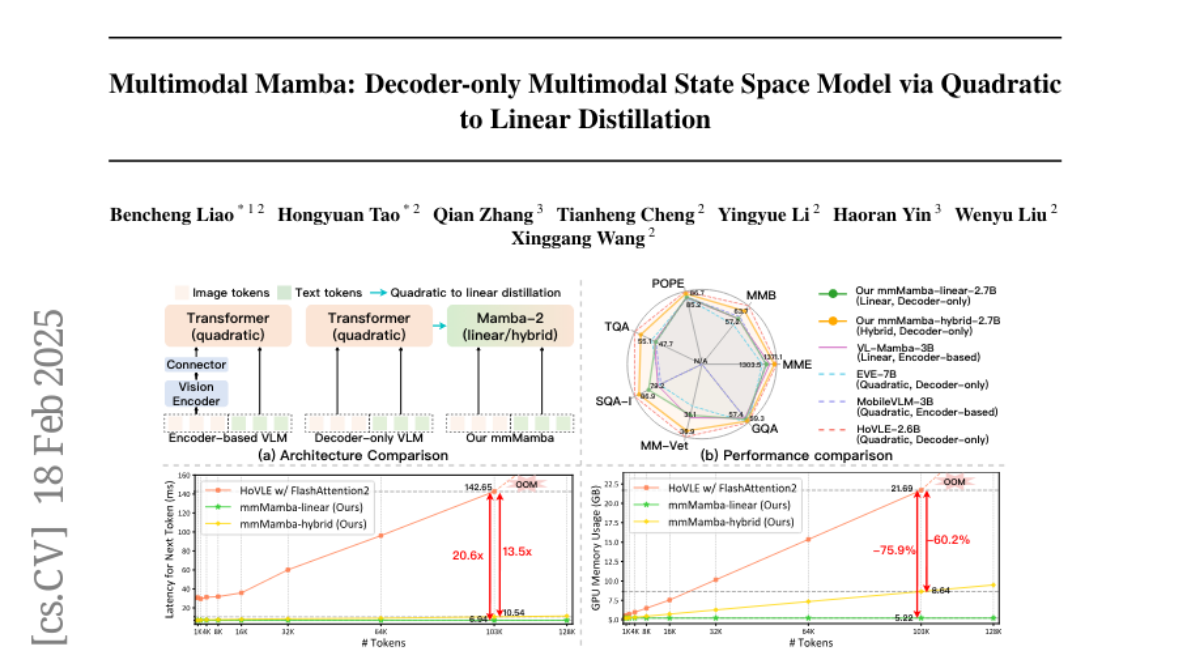
7. Multimodal Mamba: Decoder-only Multimodal State Space Model via Quadratic to Linear Distillation
🔑 Keywords: Multimodal Large Language Models, quadratic computational complexity, linear-complexity architectures, mmMamba, progressive distillation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to develop linear-complexity native multimodal state space models through a progressive distillation strategy from existing Multimodal Large Language Models (MLLMs).
🛠️ Research Methods:
– A seeding strategy and a three-stage distillation process are proposed to convert decoder-only MLLMs to linear-complexity architectures without the need for pre-trained RNN-based LLMs or separate vision encoders.
💬 Research Conclusions:
– The mmMamba framework achieves significant performance improvements and memory efficiency, demonstrating up to 20.6 times speedup and 75.8% GPU memory reduction compared to traditional models. The mmMamba-hybrid further enhances performance, closely matching the capabilities of existing quadratic-complexity models.
👉 Paper link: https://huggingface.co/papers/2502.13145
8. SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
🔑 Keywords: Spatial intelligence, Embodied AI, Semantic orientation, Geometric reasoning, Natural language
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper aims to enhance the spatial intelligence of embodied AI by introducing a concept called semantic orientation to better understand object orientations and improve robots’ interaction with environments.
🛠️ Research Methods:
– The authors propose using natural language as a representation space for object orientations and introduce a dataset, OrienText300K, to link geometric understanding with functional semantics.
💬 Research Conclusions:
– The integration of semantic orientation into a VLM system significantly improves robotic manipulation capabilities, achieving notable accuracy levels in both simulation and real-world experiments.
👉 Paper link: https://huggingface.co/papers/2502.13143

9. SafeRoute: Adaptive Model Selection for Efficient and Accurate Safety Guardrails in Large Language Models
🔑 Keywords: Large Language Models, Safety Guard Models, Computational Cost, Model Distillation, Adaptive Model Selection
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose SafeRoute, a binary router that enhances efficiency and maintains accuracy by distinguishing between hard and easy examples for deploying large language models in real-world applications.
🛠️ Research Methods:
– The use of SafeRoute to selectively apply larger safety guard models on hard examples, while allowing smaller distilled models to handle the easier ones, optimizing the trade-off between computational cost and safety performance.
💬 Research Conclusions:
– Experimental results on various benchmark datasets indicate that the proposed adaptive model selection method outperforms previous baselines, effectively balancing computational cost and safety guard model performance.
👉 Paper link: https://huggingface.co/papers/2502.12464

10. FLAG-Trader: Fusion LLM-Agent with Gradient-based Reinforcement Learning for Financial Trading
🔑 Keywords: Large language models, Multimodal financial data, Reinforcement learning, Trading rewards
💡 Category: AI in Finance
🌟 Research Objective:
– To enhance the decision-making capabilities of Large Language Models (LLMs) for complex trading scenarios in financial markets.
🛠️ Research Methods:
– Integration of LLMs with gradient-driven reinforcement learning to create FLAG-Trader, a framework that uses partially fine-tuned LLMs for trading policy networks.
💬 Research Conclusions:
– The proposed framework improves LLM performance in trading and other financial-domain tasks, supported by extensive empirical evidence.
👉 Paper link: https://huggingface.co/papers/2502.11433

11. You Do Not Fully Utilize Transformer’s Representation Capacity
🔑 Keywords: Transformers, Layer-Integrated Memory, Representation Collapse, Hidden States
💡 Category: Natural Language Processing
🌟 Research Objective:
– To address representation collapse in standard Transformers by introducing Layer-Integrated Memory (LIMe)
🛠️ Research Methods:
– Conduct extensive experiments across various architectures and lookup mechanisms to test LIMe’s effectiveness
💬 Research Conclusions:
– Demonstrated consistent performance improvements and provided insight into representation dynamics and integration across layers with LIMe
👉 Paper link: https://huggingface.co/papers/2502.09245

12. RealSyn: An Effective and Scalable Multimodal Interleaved Document Transformation Paradigm
🔑 Keywords: Vision-Language Representation, RealSyn, Semantic Augmentation, Synthetic Text, Contrastive Language-Image Pre-Training
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To fully utilize non-paired multimodal data for enhanced vision-language representation learning by creating the RealSyn dataset.
🛠️ Research Methods:
– Establishing a Real-World Data Extraction pipeline and a hierarchical retrieval method to associate images with semantically relevant texts.
– Implementing an image semantic augmented generation module for synthetic text production.
– Using a semantic balance sampling strategy to improve dataset diversity.
💬 Research Conclusions:
– RealSyn dataset significantly advances vision-language representation learning and offers strong scalability.
– Models pre-trained on RealSyn achieve state-of-the-art performance on multiple downstream tasks.
👉 Paper link: https://huggingface.co/papers/2502.12513

13. MUDDFormer: Breaking Residual Bottlenecks in Transformers via Multiway Dynamic Dense Connections
🔑 Keywords: MUltiway Dynamic Dense, MUDD connections, Transformers, MUDDFormer, language modeling
💡 Category: Natural Language Processing
🌟 Research Objective:
– The main objective is to introduce MUltiway Dynamic Dense (MUDD) connections to overcome the limitations of residual connections and enhance cross-layer information flow in Transformers.
🛠️ Research Methods:
– MUDD generates dynamic connection weights based on hidden states for each sequence position and decoupled input stream in a Transformer block. It integrates into any Transformer architecture to create MUDDFormer.
💬 Research Conclusions:
– MUDDFormer significantly outperforms traditional Transformers across different architectures and scales in language modeling. MUDDPythia-2.8B matches larger models like Pythia-6.9B and rivals Pythia-12B in some settings while adding minimal parameters and computation.
👉 Paper link: https://huggingface.co/papers/2502.12170

14. PAFT: Prompt-Agnostic Fine-Tuning
🔑 Keywords: Large Language Models, Prompt Robustness, PAFT, Fine-Tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to address the issue of compromised prompt robustness in Large Language Models (LLMs) after fine-tuning by proposing a novel approach called Prompt-Agnostic Fine-Tuning (PAFT).
🛠️ Research Methods:
– PAFT involves two stages: constructing a diverse set of meaningful, synthetic candidate prompts, and randomly sampling these prompts during fine-tuning for dynamic training inputs.
💬 Research Conclusions:
– Models trained with PAFT demonstrate strong robustness, improved performance, and faster inference across various prompts, including unseen ones. The effectiveness of PAFT is confirmed through extensive experiments and ablation studies.
👉 Paper link: https://huggingface.co/papers/2502.12859

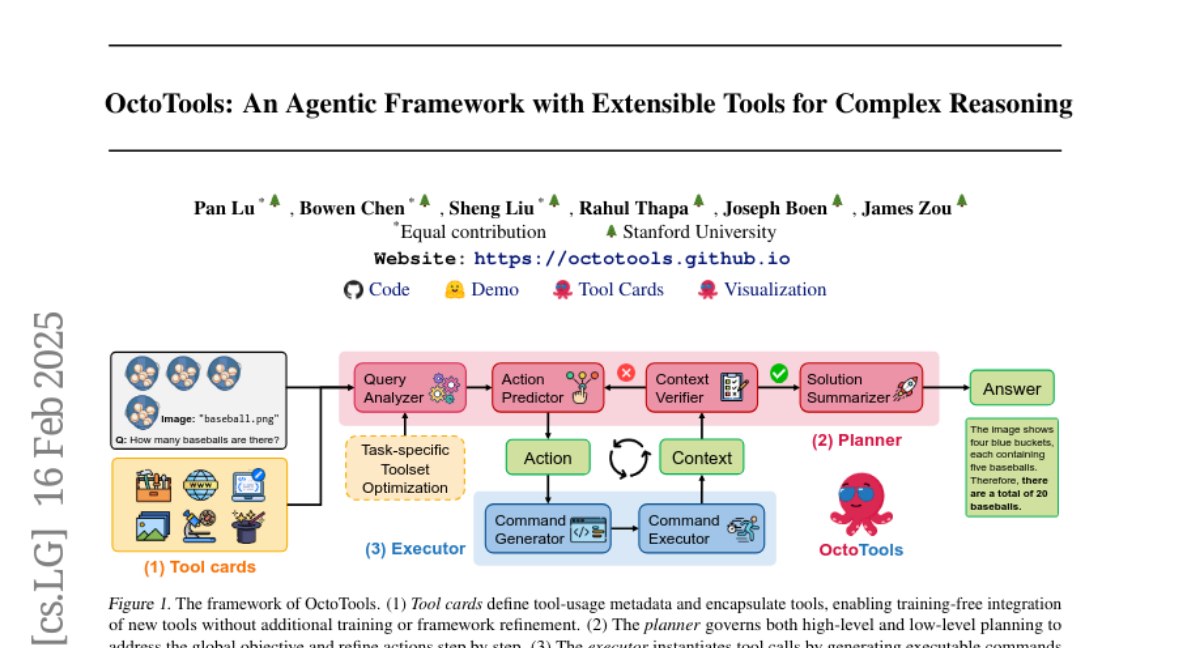
15. OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning
🔑 Keywords: AI Systems and Tools, Multi-step Problem Solving, Tool Usage, Open-source
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce OctoTools, an open-source framework designed to solve complex reasoning tasks across diverse domains without the need for additional training data.
🛠️ Research Methods:
– Development of standardized tool cards for encapsulating tool functionality, along with a planner for high-level and low-level planning, and an executor for utilizing the tools effectively.
💬 Research Conclusions:
– OctoTools validated its generality across 16 diverse tasks, showing a substantial average accuracy gain of 9.3% compared to GPT-4o, and outperformed other frameworks like AutoGen and LangChain by up to 10.6% when using the same tool set.
👉 Paper link: https://huggingface.co/papers/2502.11271
16. Revisiting the Test-Time Scaling of o1-like Models: Do they Truly Possess Test-Time Scaling Capabilities?
🔑 Keywords: Test-time scaling, OpenAI’s o1 series, Self-revision, Sequential and parallel scaling, Shortest Majority Vote
💡 Category: Natural Language Processing
🌟 Research Objective:
– This study investigates the true test-time scaling capabilities in newer large language models inspired by OpenAI’s o1 series.
🛠️ Research Methods:
– The study examines the performance impact of chain-of-thought (CoT) lengths and compares sequential versus parallel scaling strategies on models like QwQ, R1, and LIMO.
💬 Research Conclusions:
– Longer CoTs do not consistently enhance accuracy; performance may degrade due to increased self-revisions. Parallel scaling offers better results, and the Shortest Majority Vote method significantly improves test-time scalability compared to traditional approaches.
👉 Paper link: https://huggingface.co/papers/2502.12215

17. Text2World: Benchmarking Large Language Models for Symbolic World Model Generation
🔑 Keywords: Large Language Models, Text2World, Reinforcement Learning, World Modeling
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to address challenges in world modeling using Large Language Models (LLMs) by introducing a novel benchmark called Text2World based on planning domain definition language (PDDL).
🛠️ Research Methods:
– The authors use hundreds of diverse domains and employ multi-criteria, execution-based metrics to evaluate LLMs more robustly using the Text2World benchmark.
💬 Research Conclusions:
– Large-scale reinforcement learning-trained reasoning models outperform others, but still face limitations in world modeling. The authors suggest strategies like test-time scaling and agent training to improve LLM world modeling capabilities and hope Text2World aids future research in this field.
👉 Paper link: https://huggingface.co/papers/2502.13092

18. HealthGPT: A Medical Large Vision-Language Model for Unifying Comprehension and Generation via Heterogeneous Knowledge Adaptation
🔑 Keywords: HealthGPT, Medical Large Vision-Language Model, Heterogeneous Low-Rank Adaptation, Health-AI
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study introduces HealthGPT, a Medical Large Vision-Language Model (Med-LVLM) with integrated medical visual comprehension and generation capabilities in a unified autoregressive paradigm.
🛠️ Research Methods:
– Utilization of a novel Heterogeneous Low-Rank Adaptation (H-LoRA) technique, along with a tailored hierarchical visual perception approach and a three-stage learning strategy to adapt LLMs.
💬 Research Conclusions:
– HealthGPT demonstrates exceptional performance and scalability in medical visual unified tasks, supported by the creation of a comprehensive medical domain-specific dataset, VL-Health.
👉 Paper link: https://huggingface.co/papers/2502.09838

19. Eager Updates For Overlapped Communication and Computation in DiLoCo
🔑 Keywords: Distributed optimization, DiLoCo, Eager updates
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research aims to address communication slowdowns in distributed optimization methods, particularly focusing on large model training across datacenters.
🛠️ Research Methods:
– The study explores techniques to overlap communication with computation, particularly using a variant method called eager updates, to synchronize the outer optimization step with the inner phase.
💬 Research Conclusions:
– It was found that eager updates deliver competitive performance with traditional DiLoCo, especially in settings with low bandwidth between workers.
👉 Paper link: https://huggingface.co/papers/2502.12996

20. HeadInfer: Memory-Efficient LLM Inference by Head-wise Offloading
🔑 Keywords: Transformer-based LLMs, Memory Footprint, HEADINFER, KV Cache Offloading, Computational Efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to address the challenge of the disproportionate memory footprint in key-value (KV) cache during inference in Transformer-based large language models by introducing a new method, HEADINFER.
🛠️ Research Methods:
– HEADINFER offloads the KV cache to CPU RAM, selectively maintaining specific attention heads’ KV cache on the GPU, and utilizes a head-wise offloading strategy to compute attention output dynamically.
💬 Research Conclusions:
– The implementation of HEADINFER demonstrates a significant reduction in GPU memory usage, achieving a 92% reduction, and enables more extensive inference capabilities on consumer-grade GPUs without reliance on approximation methods.
👉 Paper link: https://huggingface.co/papers/2502.12574

21. Atom of Thoughts for Markov LLM Test-Time Scaling
🔑 Keywords: Large Language Models, Reasoning, Markov process, Atom of Thoughts, HotpotQA
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve the reasoning capabilities of Large Language Models by addressing the inefficiencies in existing test-time scaling methods.
🛠️ Research Methods:
– Introduced Atom of Thoughts (AoT), a method that involves breaking down complex reasoning processes into a sequence of independent, verifiable subquestions resembling Markov transitions.
💬 Research Conclusions:
– AoT serves as both a standalone framework and a plug-in enhancement, demonstrating effectiveness in experiments across six benchmarks, notably achieving an 80.6% F1 score on HotpotQA, surpassing existing methods.
👉 Paper link: https://huggingface.co/papers/2502.12018

22. Crowd Comparative Reasoning: Unlocking Comprehensive Evaluations for LLM-as-a-Judge
🔑 Keywords: LLM-as-a-Judge, Chain-of-Thought (CoT) Judgments, Crowd-based Comparative Evaluation, Supervised Fine-Tuning (SFT), Evaluation Reliability
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to address the limitations of LLM-as-a-Judge in capturing comprehensive details by introducing a Crowd-based Comparative Evaluation method.
🛠️ Research Methods:
– The researchers propose incorporating additional crowd responses to compare with candidate responses, enhancing the Chain-of-Thought (CoT) judgments and exposing deeper insights.
💬 Research Conclusions:
– The proposed approach increases evaluation reliability with an average accuracy gain of 6.7% across benchmarks and improves the quality of CoTs, facilitating efficient Supervised Fine-Tuning through crowd rejection sampling.
👉 Paper link: https://huggingface.co/papers/2502.12501

23. Flow-of-Options: Diversified and Improved LLM Reasoning by Thinking Through Options
🔑 Keywords: Flow-of-Options, Large Language Models, AutoML, Therapeutic Chemistry, Cost-Sensitive Applications
💡 Category: Machine Learning
🌟 Research Objective:
– Introduce the Flow-of-Options (FoO) approach to address intrinsic biases in Large Language Models and enhance solution diversity.
🛠️ Research Methods:
– Develop an FoO-based agentic system for autonomously solving Machine Learning tasks and validate its performance against state-of-the-art baselines.
💬 Research Conclusions:
– The FoO framework improves performance significantly on standard data science and therapeutic chemistry tasks with lower costs, while also demonstrating broader applicability in other domains like reinforcement learning and image generation.
👉 Paper link: https://huggingface.co/papers/2502.12929

24. Injecting Domain-Specific Knowledge into Large Language Models: A Comprehensive Survey
🔑 Keywords: Large Language Models, Domain-Specific Applications, Knowledge Injection, Natural Language Understanding
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance the performance of Large Language Models (LLMs) in domain-specific applications by integrating specialized knowledge.
🛠️ Research Methods:
– The paper categorizes methods to enhance LLMs into dynamic knowledge injection, static knowledge embedding, modular adapters, and prompt optimization, each with unique strengths and trade-offs.
💬 Research Conclusions:
– The research provides a comprehensive overview of methods to make LLMs more effective in specialized tasks and discusses the balance between their flexibility, scalability, and efficiency. It also highlights ongoing challenges and maintains an open-source resource for updated studies.
👉 Paper link: https://huggingface.co/papers/2502.10708

25. The Hidden Risks of Large Reasoning Models: A Safety Assessment of R1
🔑 Keywords: safety assessment, adversarial attacks, reasoning models, OpenAI-o3, DeepSeek-R1
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– The study aims to conduct a comprehensive safety assessment of reasoning models like OpenAI-o3 and DeepSeek-R1, focusing on their compliance with safety regulations and susceptibility to misuse.
🛠️ Research Methods:
– Leveraging established safety benchmarks to evaluate reasoning models, investigating adversarial attacks such as jailbreaking and prompt injection to assess robustness in real-world applications.
💬 Research Conclusions:
– Identified a significant safety gap between the open-source R1 models and o3-mini on benchmarks and attacks.
– Distilled reasoning models exhibit poorer safety performance compared to their base models.
– Stronger reasoning ability increases the potential harm from unsafe question responses.
– The thinking process in R1 models poses greater safety concerns than the final answers, indicating a need for increased focus on improving safety in R1 models.
👉 Paper link: https://huggingface.co/papers/2502.12659

26. Multilingual Encoder Knows more than You Realize: Shared Weights Pretraining for Extremely Low-Resource Languages
🔑 Keywords: multilingual language models, low-resource languages, text generation, multilingual encoders, XLM-SWCM
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose a novel framework for adapting multilingual encoders to text generation in extremely low-resource languages.
🛠️ Research Methods:
– Reusing the weights between the encoder and decoder to leverage the learned semantic space for efficient learning and generalization.
💬 Research Conclusions:
– XLM-SWCM achieves superior performance on various downstream tasks in four Chinese minority languages, even compared to much larger models.
👉 Paper link: https://huggingface.co/papers/2502.10852
27. Pre-training Auto-regressive Robotic Models with 4D Representations
🔑 Keywords: Foundation models, Pre-training, Robotics, 4D Representations, Transfer learning
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To introduce ARM4R, an Auto-regressive Robotic Model that enhances pre-trained robotic models using low-level 4D Representations from human video data.
🛠️ Research Methods:
– Utilization of 3D point tracking representations derived from videos by lifting 2D representations into 3D space through monocular depth estimation, enabling efficient transfer learning for robotic control.
💬 Research Conclusions:
– ARM4R facilitates efficient transfer from human video data to robotics, showing consistent performance improvements across various robotic tasks and environments.
👉 Paper link: https://huggingface.co/papers/2502.13142

28. Perovskite-LLM: Knowledge-Enhanced Large Language Models for Perovskite Solar Cell Research
🔑 Keywords: Knowledge Representation, Perovskite Solar Cells, Knowledge Graph, Large Language Models
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Develop a comprehensive knowledge-enhanced system for perovskite solar cells (PSCs) to manage and reason over scientific literature effectively.
🛠️ Research Methods:
– Constructed Perovskite-KG, a domain-specific knowledge graph from 1,517 research papers.
– Created Perovskite-Chat and Perovskite-Reasoning datasets containing question-answer pairs and materials science problems, respectively.
– Introduced specialized large language models (LLMs) for domain-specific knowledge assistance and scientific reasoning.
💬 Research Conclusions:
– The system significantly surpasses existing models in domain-specific knowledge retrieval and scientific reasoning, aiding researchers in literature review, experimental design, and complex problem-solving in PSC research.
👉 Paper link: https://huggingface.co/papers/2502.12669

29. Harnessing Vision Models for Time Series Analysis: A Survey
🔑 Keywords: Time Series Analysis, Large Vision Models, Large Language Models, Vision Language Models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to explore the advantages of using vision models over Large Language Models (LLMs) for time series analysis.
🛠️ Research Methods:
– The paper provides a comprehensive overview and detailed taxonomy of existing methods to encode time series as images and models these images for various tasks.
💬 Research Conclusions:
– The survey identifies the benefits and challenges of using vision models in time series analysis, highlighting future directions to advance this field.
👉 Paper link: https://huggingface.co/papers/2502.08869

30. FinMTEB: Finance Massive Text Embedding Benchmark
🔑 Keywords: Embedding Models, Financial Domain, FinMTEB, Domain-Specific Evaluation, AI in Finance
💡 Category: AI in Finance
🌟 Research Objective:
– The paper introduces the Finance Massive Text Embedding Benchmark (FinMTEB) for enhancing domain-specific embedding model evaluation in the financial sector.
🛠️ Research Methods:
– Developed FinMTEB with 64 datasets across 7 tasks for financial text.
– Created FinPersona-E5 model using a persona-based data synthetic method.
💬 Research Conclusions:
– Performance of general-purpose models has limited correlation with financial domain tasks.
– Domain-adapted models perform better than general-purpose models in financial contexts.
– A simple Bag-of-Words approach often surpasses dense embeddings in financial STS tasks, revealing limitations of current dense embedding techniques.
👉 Paper link: https://huggingface.co/papers/2502.10990

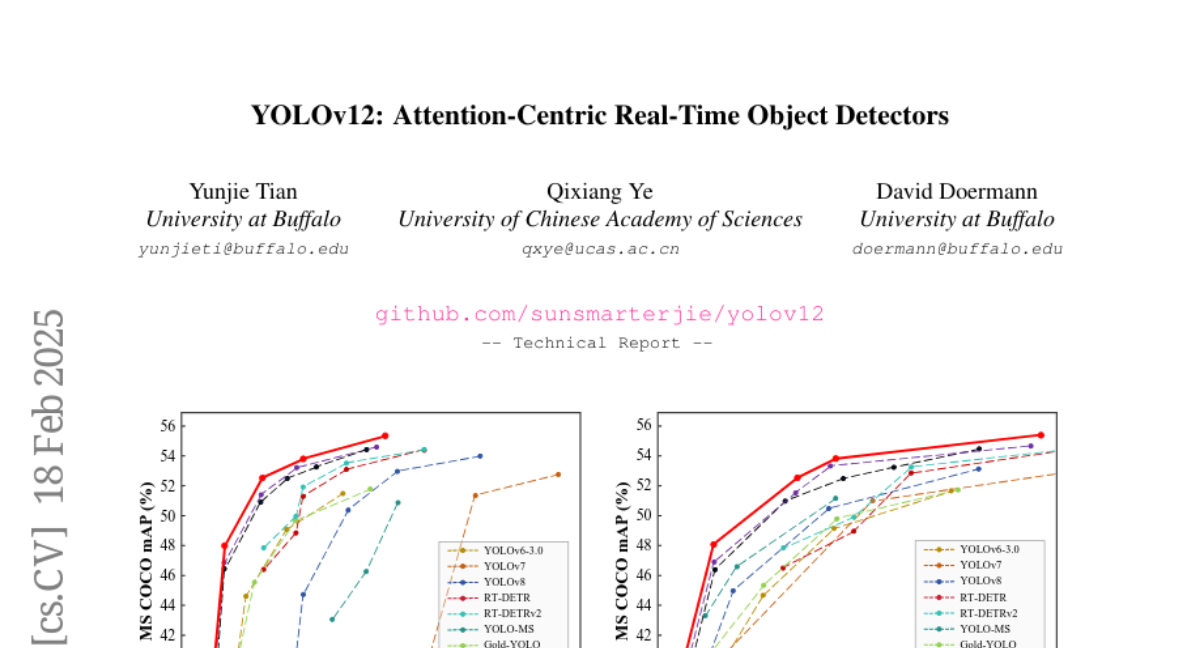
31. YOLOv12: Attention-Centric Real-Time Object Detectors
🔑 Keywords: YOLOv12, Attention Mechanisms, Real-time Object Detection
💡 Category: Computer Vision
🌟 Research Objective:
– Propose an attention-centric YOLO framework, YOLOv12, combining the accuracy benefits of attention mechanisms with the speed of CNN-based models.
🛠️ Research Methods:
– Develop an attention-focused architecture that matches the speed of previous CNN-centric YOLO models.
💬 Research Conclusions:
– YOLOv12 achieves higher accuracy than other real-time detectors, such as YOLOv10-N and YOLOv11-N, and outperforms enhanced DETR-based models with less computational cost and parameters.
👉 Paper link: https://huggingface.co/papers/2502.12524
32. Scaling Autonomous Agents via Automatic Reward Modeling And Planning
🔑 Keywords: Large Language Models, Decision-Making, Reward Model, AI Agents, Task Planning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve the decision-making capabilities of Large Language Models (LLMs) by developing a framework that learns a reward model from environmental interaction without human annotations.
🛠️ Research Methods:
– Utilizes LLM-based agents to randomly navigate environments to generate diverse action trajectories.
– Leverages a separate LLM to assign task intents and synthesize both positive and negative responses for training a reward model.
💬 Research Conclusions:
– The proposed framework effectively enhances LLM agents’ decision-making by automating the learning of reward models, addressing data scarcity and API limitations.
– Demonstrated effectiveness and generalizability through evaluations on different agent benchmarks, paving the way for sophisticated AI agents in complex environments.
👉 Paper link: https://huggingface.co/papers/2502.12130
