AI Native Daily Paper Digest – 20250220

1. Qwen2.5-VL Technical Report
🔑 Keywords: Qwen2.5-VL, AI Native, Vision Transformer, Bounding Boxes, Document Parsing
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Qwen2.5-VL, showcasing advanced visual recognition, object localization, and long-video comprehension.
🛠️ Research Methods:
– Utilize a native dynamic-resolution Vision Transformer with Window Attention to enhance spatial and temporal dynamics.
💬 Research Conclusions:
– Qwen2.5-VL excels in interactive visual tasks, robust document parsing, and matches state-of-the-art models in document and diagram understanding.
👉 Paper link: https://huggingface.co/papers/2502.13923

2. RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning
🔑 Keywords: 3DGS, Reinforcement Learning, Autonomous Driving, Imitation Learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To address challenges of Imitation Learning in autonomous driving by establishing a closed-loop Reinforcement Learning training paradigm using 3DGS techniques.
🛠️ Research Methods:
– Construct a photorealistic digital replica of the physical world for policy exploration and learning through trial and error.
– Integrate Imitation Learning into Reinforcement Learning as a regularization term to improve human-like driving behavior.
💬 Research Conclusions:
– The proposed method, RAD, demonstrates improved performance over Imitation Learning-based methods, significantly reducing collision rates in closed-loop metrics.
👉 Paper link: https://huggingface.co/papers/2502.13144

3. SongGen: A Single Stage Auto-regressive Transformer for Text-to-Song Generation
🔑 Keywords: Text-to-song generation, SongGen, auto-regressive transformer, voice cloning
💡 Category: Generative Models
🌟 Research Objective:
– The paper presents SongGen, a single-stage, auto-regressive transformer model designed for controllable song generation.
🛠️ Research Methods:
– SongGen integrates fine-grained control over musical attributes and evaluates diverse token pattern strategies within a unified framework.
– Implements an automated data preprocessing pipeline with quality control measures.
💬 Research Conclusions:
– SongGen improves control over song generation with two output modes and shares resources to promote future research, including model weights and annotated data.
👉 Paper link: https://huggingface.co/papers/2502.13128

4. MoM: Linear Sequence Modeling with Mixture-of-Memories
🔑 Keywords: Linear sequence modeling, Mixture-of-Memories, neuroscience, memory interference, recall-intensive tasks
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce and develop the Mixture-of-Memories (MoM) architecture to improve recall performance in linear sequence models by leveraging multiple independent memory states inspired by neuroscience.
🛠️ Research Methods:
– Implementation of a router network to direct input tokens to specific memory states, which increases memory capacity while maintaining linear complexity in computation.
💬 Research Conclusions:
– MoM significantly enhances performance on recall-intensive language tasks, surpassing existing linear sequence models and achieving comparable results to Transformer models while maintaining computational efficiency.
👉 Paper link: https://huggingface.co/papers/2502.13685

5. Is That Your Final Answer? Test-Time Scaling Improves Selective Question Answering
🔑 Keywords: Test-time Compute, Large Language Models, Confidence Scores, Reasoning Benchmarks
💡 Category: Natural Language Processing
🌟 Research Objective:
– This research aims to improve the evaluation of large language models by incorporating confidence scores during reasoning to allow for thresholding responses.
🛠️ Research Methods:
– The study extracts confidence scores in the process of reasoning and examines how increased computational resources at inference time affect the models’ correctness and confidence.
💬 Research Conclusions:
– Findings indicate that more compute resources improve both the accuracy of responses and model confidence. A new evaluation paradigm considering response risks is proposed.
👉 Paper link: https://huggingface.co/papers/2502.13962

6. Craw4LLM: Efficient Web Crawling for LLM Pretraining
🔑 Keywords: Web Crawl, LLM Pretraining, Crawling Efficiency, High-Quality Data
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop an efficient web crawling method named Crawl4LLM that enhances the quality of pretraining data for large language models (LLMs).
🛠️ Research Methods:
– Introduces a priority score system in the crawler’s scheduler based on a webpage’s influence on LLM pretraining, instead of traditional graph connectivity.
💬 Research Conclusions:
– Crawl4LLM demonstrates efficiency by achieving the same downstream performances with only 21% of URLs crawled, thereby reducing data waste and the burden on websites.
👉 Paper link: https://huggingface.co/papers/2502.13347

7. LongPO: Long Context Self-Evolution of Large Language Models through Short-to-Long Preference Optimization
🔑 Keywords: Large Language Models, LongPO, short-context alignment, long-context performance
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enable short-context LLMs to improve their performance in long-context tasks through self-evolution using the LongPO method.
🛠️ Research Methods:
– LongPO transfers short-context capabilities to long-context tasks by learning from self-generated short-to-long preference data and incorporating a short-to-long KL constraint to retain performance.
💬 Research Conclusions:
– LongPO significantly enhances long-context performance of LLMs while retaining short-context capabilities, outperforming naive SFT and DPO, and achieving results comparable to or better than models like GPT-4-128K.
👉 Paper link: https://huggingface.co/papers/2502.13922

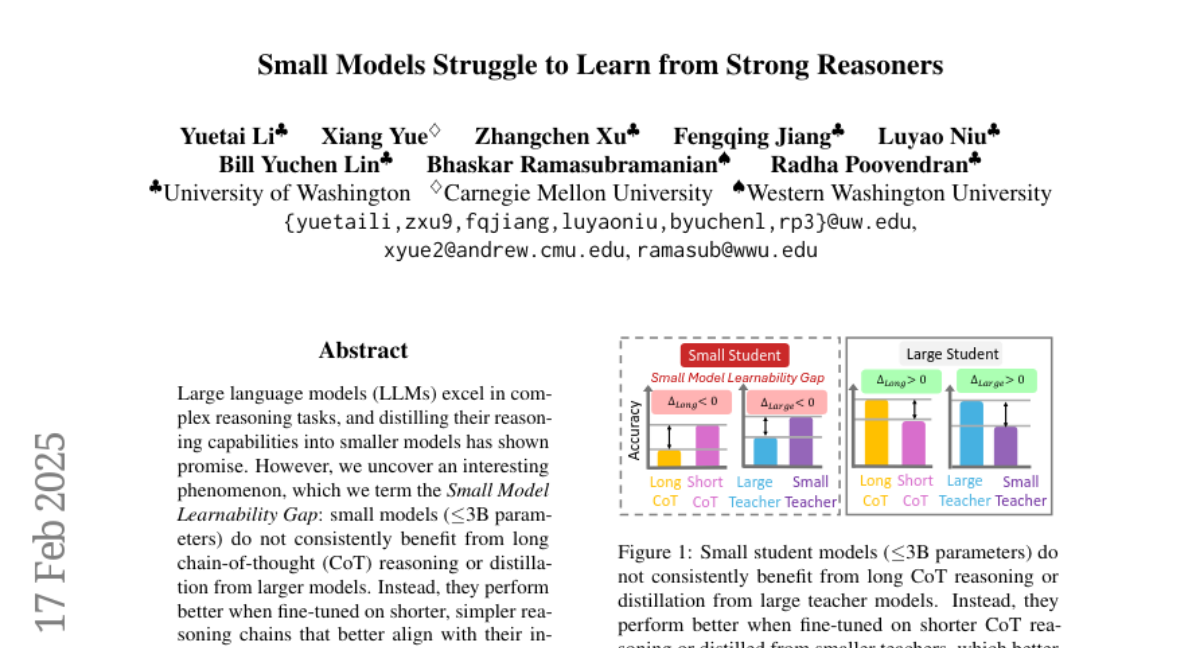
8. Small Models Struggle to Learn from Strong Reasoners
🔑 Keywords: Large Language Models, Small Model Learnability Gap, Mix Distillation, Chain-of-Thought Reasoning, Model Distillation
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the challenges small language models face in learning complex reasoning from larger models and propose a solution.
🛠️ Research Methods:
– Introduce Mix Distillation, a strategy that combines both long and short chain-of-thought examples to improve reasoning performance of small models.
💬 Research Conclusions:
– Mix Distillation enhances the reasoning performance of small models and highlights the need to adapt reasoning complexity for effective knowledge transfer.
👉 Paper link: https://huggingface.co/papers/2502.12143
9. Autellix: An Efficient Serving Engine for LLM Agents as General Programs
🔑 Keywords: Large Language Models, AI Agents, Autellix, Scheduling Algorithms, Optimization
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To optimize LLM serving systems by addressing the dependencies between programs and LLM calls to minimize end-to-end latencies for complex tasks.
🛠️ Research Methods:
– Introduction of Autellix, an LLM serving system that enriches schedulers with program-level context. Two scheduling algorithms for single-threaded and distributed programs prioritize LLM calls based on previous completions.
💬 Research Conclusions:
– Autellix significantly improves throughput of programs by 4-15 times with the same latency compared to current state-of-the-art systems, enhancing efficiency in LLM applications.
👉 Paper link: https://huggingface.co/papers/2502.13965

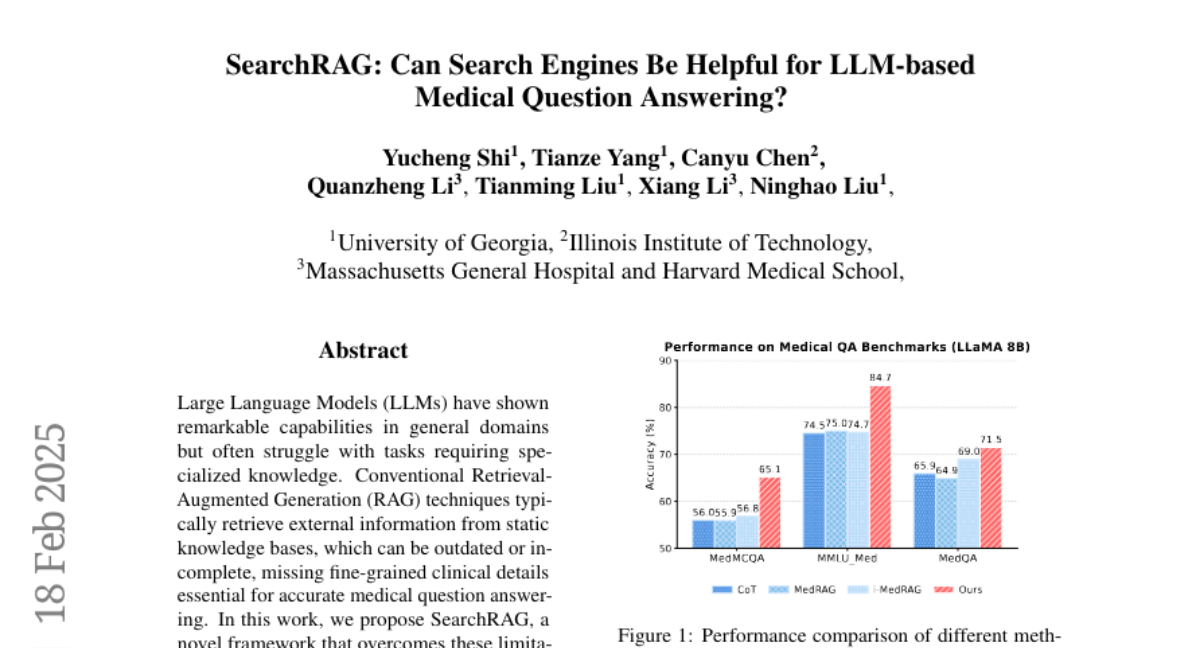
10. SearchRAG: Can Search Engines Be Helpful for LLM-based Medical Question Answering?
🔑 Keywords: Large Language Models, Retrieval-Augmented Generation, SearchRAG, medical knowledge
💡 Category: AI in Healthcare
🌟 Research Objective:
– The objective is to improve the accuracy of medical question answering by leveraging real-time search engines rather than static knowledge bases.
🛠️ Research Methods:
– The paper introduces SearchRAG, which utilizes synthetic query generation and uncertainty-based knowledge selection to process complex medical queries for better integration with LLMs.
💬 Research Conclusions:
– SearchRAG significantly enhances response accuracy for complex medical questions by using detailed and up-to-date information.
👉 Paper link: https://huggingface.co/papers/2502.13233
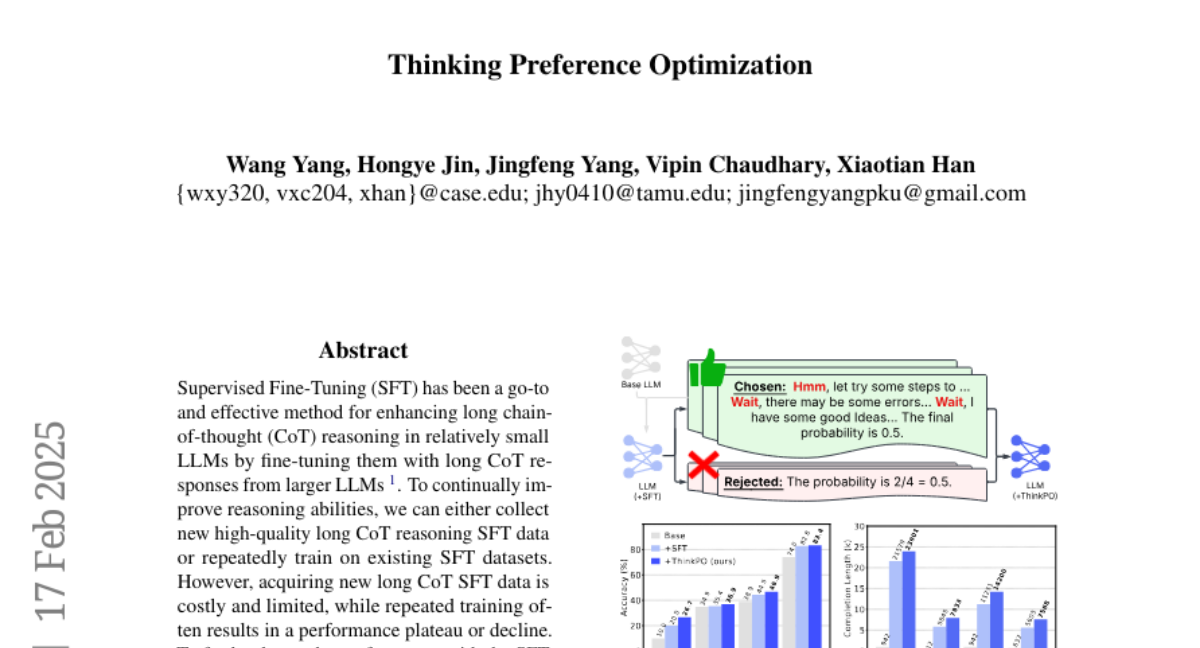
11. Thinking Preference Optimization
🔑 Keywords: Supervised Fine-Tuning, Chain-of-Thought reasoning, Thinking Preference Optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance long Chain-of-Thought (CoT) reasoning in small LLMs without the need for new data.
🛠️ Research Methods:
– Proposes Thinking Preference Optimization (ThinkPO) that optimizes preferences by using available short and long CoT responses to favor longer reasoning outputs.
💬 Research Conclusions:
– ThinkPO significantly improves reasoning performance in SFT-ed models, evident by an 8.6% increase in math reasoning accuracy and a 25.9% growth in output length.
– It effectively boosts the performance of publicly distilled models, e.g., increasing performance on MATH500 from 87.4% to 91.2%.
👉 Paper link: https://huggingface.co/papers/2502.13173
12. Why Safeguarded Ships Run Aground? Aligned Large Language Models’ Safety Mechanisms Tend to Be Anchored in The Template Region
🔑 Keywords: Large Language Models, Safety Alignment, Jailbreak Attacks, Template-Anchored, Vulnerabilities
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the safety alignment vulnerabilities of Large Language Models and explore how template regions contribute to these issues.
🛠️ Research Methods:
– Conduct extensive experiments to explore the impact of template regions on LLMs and analyze their susceptibility to jailbreak attacks.
💬 Research Conclusions:
– Template-anchored safety alignment is a widespread vulnerability in LLMs, and detaching safety mechanisms from template regions may mitigate these vulnerabilities, suggesting a need for robust safety alignment techniques.
👉 Paper link: https://huggingface.co/papers/2502.13946

13. Presumed Cultural Identity: How Names Shape LLM Responses
🔑 Keywords: cultural identity, personalisation, bias, LLMs, stereotypes
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– To study biases associated with names by analyzing cultural presumptions in LLM responses during common suggestion-seeking queries.
🛠️ Research Methods:
– Analyzed responses generated by LLMs, focusing on cultural assumptions linked to user names across various cultures.
💬 Research Conclusions:
– Demonstrated strong cultural identity assumptions tied to names in LLM outputs, emphasizing the need for personalisation systems that avoid stereotypes while allowing meaningful customisation.
👉 Paper link: https://huggingface.co/papers/2502.11995

14. AdaptiveStep: Automatically Dividing Reasoning Step through Model Confidence
🔑 Keywords: Process Reward Models, AdaptiveStep, mathematical reasoning, code generation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop AdaptiveStep, a new method for dividing reasoning steps based on model confidence, aimed at enhancing downstream tasks like reward model learning.
🛠️ Research Methods:
– The use of AdaptiveStep in training Process Reward Models (PRMs) and evaluating its performance in mathematical reasoning and code generation tasks.
💬 Research Conclusions:
– AdaptiveStep-trained PRMs achieved state-of-the-art performance in Best-of-N comparisons, outperforming existing methods and reducing construction costs by over 30%.
👉 Paper link: https://huggingface.co/papers/2502.13943

15. MMTEB: Massive Multilingual Text Embedding Benchmark
🔑 Keywords: Text Embeddings, MMTEB, Multilingual Benchmarks, Language Models, Task Optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) which works as an expansion of MTEB and covers a wide range of 500+ evaluation tasks in 250+ languages, focusing on comprehensive assessment beyond the limitations of typical task evaluations.
🛠️ Research Methods:
– Development of multiple highly multilingual benchmarks using MMTEB to evaluate a diverse set of models.
– Introduction of a novel downsampling method based on inter-task correlation to reduce computational cost while preserving model ranking diversity.
– Optimization of retrieval tasks by sampling hard negatives to create efficient task splits.
💬 Research Conclusions:
– Large language models (LLMs) with billions of parameters show state-of-the-art performance in some languages and tasks, but a smaller, publicly available model, multilingual-e5-large-instruct, also performs exceptionally well with only 560 million parameters.
– The newly introduced zero-shot English benchmark maintains effective ranking order at reduced computational demands, validating the efficiency of the proposed benchmarks and optimizations.
👉 Paper link: https://huggingface.co/papers/2502.13595

16. NExT-Mol: 3D Diffusion Meets 1D Language Modeling for 3D Molecule Generation
🔑 Keywords: 3D Molecule Generation, 1D SELFIES, Language Models, 3D Diffusion Model
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to integrate the advantages of 3D diffusion models and 1D SELFIES-based Language Models for effective 3D molecule generation in drug discovery and material design.
🛠️ Research Methods:
– Utilization of a pretrained molecule Language Model for 1D molecule generation, and a 3D diffusion model for predicting 3D conformers, enhanced by scaling model size, refining architecture, and applying transfer learning.
💬 Research Conclusions:
– NExT-Mol shows a significant improvement: 26% relative gain in 3D FCD for de novo generation on GEOM-DRUGS and a 13% average gain for conditional generation on QM9-2014.
👉 Paper link: https://huggingface.co/papers/2502.12638

17. Train Small, Infer Large: Memory-Efficient LoRA Training for Large Language Models
🔑 Keywords: Large Language Models, Low-Rank Adaption, Memory Efficiency, Structured Pruning
💡 Category: Natural Language Processing
🌟 Research Objective:
– Propose a memory-efficient training scheme called LoRAM to optimize Low-Rank Adaption for large language models.
🛠️ Research Methods:
– Developed a unique approach by training on pruned, low-rank matrices and recovering them with the original model for inference.
– Implemented structured pruning combined with 4-bit quantization to enhance memory efficiency.
💬 Research Conclusions:
– LoRAM demonstrates significant memory savings and performance gains over traditional methods, enabling effective training with reduced GPU resources.
👉 Paper link: https://huggingface.co/papers/2502.13533

18. AIDE: AI-Driven Exploration in the Space of Code
🔑 Keywords: AI-Driven Exploration, Machine Learning, Large Language Models, Optimization
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces AI-Driven Exploration (AIDE) to address the tedious trial-and-error process involved in machine learning model development.
🛠️ Research Methods:
– Machine learning engineering is approached as a code optimization problem using AIDE, powered by large language models (LLMs), formulating trial-and-error as a tree search in the solution space.
💬 Research Conclusions:
– AIDE enhances performance by reusing and refining solutions, achieving state-of-the-art results on benchmarks like Kaggle evaluations, OpenAI MLE-Bench, and METRs RE-Bench.
👉 Paper link: https://huggingface.co/papers/2502.13138

19. ActionPiece: Contextually Tokenizing Action Sequences for Generative Recommendation
🔑 Keywords: Generative recommendation, ActionPiece, Context-awareness, Tokenization
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance the performance of Generative Recommendation systems by introducing context-awareness in action tokenization.
🛠️ Research Methods:
– Proposes ActionPiece, a model that incorporates context by representing actions as item feature sets and constructs vocabulary through feature pattern merging based on their co-occurrence frequency.
💬 Research Conclusions:
– Experiments reveal that ActionPiece outperforms existing tokenization methods, achieving a 6.00% to 12.82% improvement in NDCG@10.
👉 Paper link: https://huggingface.co/papers/2502.13581

20. InfiR : Crafting Effective Small Language Models and Multimodal Small Language Models in Reasoning
🔑 Keywords: Large Language Models, Multimodal Models, Small Language Models, Edge Devices, Privacy Concerns
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To develop efficient Small Language Models (SLMs) and Multimodal Small Language Models (MSLMs) that maintain competitive reasoning abilities while addressing computational and privacy challenges.
🛠️ Research Methods:
– Introduction of a novel training pipeline that enhances reasoning capabilities and facilitates deployment on edge devices.
💬 Research Conclusions:
– Achieves state-of-the-art performance with reduced model sizes, lowering development costs and adoption barriers while addressing privacy concerns.
👉 Paper link: https://huggingface.co/papers/2502.11573

21. REFIND: Retrieval-Augmented Factuality Hallucination Detection in Large Language Models
🔑 Keywords: Hallucinations, Large Language Model, REFIND, Context Sensitivity Ratio
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to address hallucinations in large language model outputs, which affect the reliability of knowledge-intensive tasks like question answering.
🛠️ Research Methods:
– Introduction of REFIND, a framework using retrieval-augmented methods to detect hallucinated spans by leveraging retrieved documents.
– Proposal of the Context Sensitivity Ratio (CSR), a metric to quantify the sensitivity of LLM outputs to retrieved evidence.
💬 Research Conclusions:
– REFIND demonstrates robustness across multiple languages and settings, significantly outperforming baseline models with superior IoU scores in hallucination detection.
– The work highlights the importance of quantifying context sensitivity for improving LLM reliability and trustworthiness across diverse languages.
👉 Paper link: https://huggingface.co/papers/2502.13622

22. TESS 2: A Large-Scale Generalist Diffusion Language Model
🔑 Keywords: TESS 2, diffusion language model, autoregressive models, instruction tuning, reward guidance
💡 Category: Generative Models
🌟 Research Objective:
– To introduce TESS 2, a general-purpose instruction-following diffusion language model that competes with and sometimes exceeds strong autoregressive models.
🛠️ Research Methods:
– Training involved adapting a strong autoregressive model through continued pretraining with cross-entropy as diffusion loss, followed by further instruction tuning.
– Proposed reward guidance as a novel inference-time guidance procedure to align model outputs without additional training of the underlying model.
💬 Research Conclusions:
– TESS 2 shows significant improvements with increased inference-time compute, indicating diffusion language models offer fine-grained controllability over compute resources used during inference.
👉 Paper link: https://huggingface.co/papers/2502.13917

23. MVL-SIB: A Massively Multilingual Vision-Language Benchmark for Cross-Modal Topical Matching
🔑 Keywords: Multilingual VL, Low-Resource Languages, LVLMs, Cross-Modal Matching, MVL-SIB
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The main objective was to introduce MVL-SIB, a multilingual vision-language benchmark covering 205 languages, addressing gaps in performance evaluation across low-resource languages.
🛠️ Research Methods:
– A variety of open-weight large vision-language models (LVLMs) and GPT-4o(-mini) were benchmarked using the MVL-SIB across these languages to evaluate their capabilities in cross-modal and text-only topical matching.
💬 Research Conclusions:
– LVLMs struggle with cross-modal topic matching in lower-resource languages, performing at chance levels, and the support declines disproportionately compared to textual capabilities. Additionally, representing a topic with more than one image does not significantly improve LVLM performance, suggesting limitations in handling multi-image tasks.
👉 Paper link: https://huggingface.co/papers/2502.12852

24. From Tools to Teammates: Evaluating LLMs in Multi-Session Coding Interactions
🔑 Keywords: Large Language Models, MemoryCode, Long-Term Interactions, Coding Instructions, GPT-4o
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to evaluate the ability of Large Language Models (LLMs) to collaborate effectively over long-term interactions using a synthetic multi-session dataset, MemoryCode.
🛠️ Research Methods:
– MemoryCode, a dataset simulating realistic conditions, is used to assess LLMs’ capability to track and execute simple coding instructions amidst irrelevant information across multiple sessions.
💬 Research Conclusions:
– The study finds that although LLMs can handle isolated instructions well, their performance significantly declines in long instruction chains, indicating a fundamental limitation in their ability to retrieve and integrate information over extended interactions.
👉 Paper link: https://huggingface.co/papers/2502.13791

25. GIMMICK — Globally Inclusive Multimodal Multitask Cultural Knowledge Benchmarking
🔑 Keywords: Large Vision-Language Models, multicultural benchmarks, Western cultural bias, multimodal input
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a comprehensive benchmark (GIMMICK) for evaluating Large Vision-Language Models (LVLMs) across diverse global cultures.
🛠️ Research Methods:
– Introduction of GIMMICK, a multimodal benchmark with six tasks and three new datasets to assess cultural knowledge from 144 countries.
– Evaluation of 20 LVLMs and 11 LLMs, focusing on cultural biases, model size influence, input modalities, and external cues.
💬 Research Conclusions:
– Identified strong Western cultural biases in LVLMs and correlations between model size and performance.
– Highlighted that LVLMs perform better with tangible cultural elements but struggle with nuanced understanding.
👉 Paper link: https://huggingface.co/papers/2502.13766

26. Reducing Hallucinations in Language Model-based SPARQL Query Generation Using Post-Generation Memory Retrieval
🔑 Keywords: SPARQL query generation, Large Language Models (LLMs), knowledge graphs (KG), URI hallucinations, Post-Generation Memory Retrieval (PGMR)
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve the accuracy and reliability of SPARQL query generation from natural language questions by minimizing hallucinations in generating knowledge graph elements using large language models.
🛠️ Research Methods:
– Introduced PGMR, a modular framework that employs a non-parametric memory module to enhance LLM-based SPARQL query generation by retrieving correct knowledge graph elements.
💬 Research Conclusions:
– PGMR significantly reduces URI hallucinations, showing strong performance across various datasets and effectively eliminating the problem in several scenarios.
👉 Paper link: https://huggingface.co/papers/2502.13369

27. Judging the Judges: A Collection of LLM-Generated Relevance Judgements
🔑 Keywords: Large Language Models, Relevance Assessments, Information Retrieval, Natural Language Processing, LLMJudge challenge
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the potential improvements in Information Retrieval and NLP by using Large Language Models (LLMs) for relevance assessments.
🛠️ Research Methods:
– Conducted the LLMJudge challenge at SIGIR 2024, benchmarking 42 LLM-generated labels for relevance judgments from the TREC 2023 Deep Learning track, involving eight international teams.
💬 Research Conclusions:
– Automatic relevance judgments by LLMs offer insights into systematic biases, effectiveness of ensemble models, and enhance methodologies for automated evaluation in low-resource scenarios.
👉 Paper link: https://huggingface.co/papers/2502.13908

28. REALTALK: A 21-Day Real-World Dataset for Long-Term Conversation
🔑 Keywords: Emotional Intelligence, REALTALK, long-term memory, persona simulation, authentic dialogues
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce REALTALK, a 21-day corpus of genuine messaging app dialogues, addressing the gap in understanding real-world conversational patterns compared to synthetic, LLM-generated data.
🛠️ Research Methods:
– Conducting a dataset analysis focusing on Emotional Intelligence (EI) attributes and persona consistency.
– Comparing real-world dialogues with LLM-generated conversations and introducing benchmark tasks for persona simulation and memory probing.
💬 Research Conclusions:
– Models face challenges in simulating user personas solely from dialogue history but show improvement with fine-tuning on specific user interactions.
– Existing models also struggle with recalling and utilizing long-term context in real-world interactions.
👉 Paper link: https://huggingface.co/papers/2502.13270

29. High-Fidelity Novel View Synthesis via Splatting-Guided Diffusion
🔑 Keywords: Novel View Synthesis, SplatDiff, High-Fidelity Views, Texture Bridge, Zero-Shot Performance
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to address the challenge of generating high-fidelity novel views from single or sparse observations in Novel View Synthesis.
🛠️ Research Methods:
– Introduces SplatDiff, a pixel-splatting-guided video diffusion model utilizing an aligned synthesis strategy and a texture bridge module for improved synthesis.
💬 Research Conclusions:
– SplatDiff exhibits state-of-the-art performance in single-view NVS and shows remarkable zero-shot performance in diverse tasks without the need for additional training.
👉 Paper link: https://huggingface.co/papers/2502.12752

30. Noise May Contain Transferable Knowledge: Understanding Semi-supervised Heterogeneous Domain Adaptation from an Empirical Perspective
🔑 Keywords: Semi-supervised heterogeneous domain adaptation, Knowledge Transfer Framework, transferable knowledge
💡 Category: Machine Learning
🌟 Research Objective:
– The study investigates the nature of knowledge transferred across heterogeneous domains in SHDA from an empirical perspective.
🛠️ Research Methods:
– Conducted extensive experiments on about 330 SHDA tasks using two supervised learning methods and seven representative SHDA methods.
– Designed a unified Knowledge Transfer Framework (KTF) to analyze transferable knowledge.
💬 Research Conclusions:
– Discovered that both category and feature information of source samples do not significantly impact target domain performance.
– Found that transferable knowledge in SHDA primarily arises from the transferability and discriminability of source domain properties.
– Ensuring these properties in source samples, regardless of their origin, enhances knowledge transfer effectiveness.
👉 Paper link: https://huggingface.co/papers/2502.13573
