AI Native Daily Paper Digest – 20250221

1. MLGym: A New Framework and Benchmark for Advancing AI Research Agents
🔑 Keywords: Meta MLGym, MLGym-Bench, LLM agents, AI Research Tasks, Reinforcement Learning
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce Meta MLGym and MLGym-Bench as a framework and benchmark for evaluating LLM agents on AI research tasks, focusing on reinforcement learning algorithms.
🛠️ Research Methods:
– Development of the first Gym environment for machine learning tasks, featuring 13 diverse AI research tasks across various domains like computer vision, NLP, and game theory.
💬 Research Conclusions:
– Current frontier models, such as GPT-4o and Llama-3.1, show potential by improving hyperparameters but lack in generating novel hypotheses or substantial improvements. The framework and benchmark are open-sourced to promote further AI research.
👉 Paper link: https://huggingface.co/papers/2502.14499

2. SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
🔑 Keywords: SigLIP 2, Multilingual, Vision-Language Models, Self-Supervised, Fairness
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces SigLIP 2, an enhancement of the original SigLIP, focusing on improving multilingual vision-language encoding capabilities.
🛠️ Research Methods:
– The research integrates various techniques such as captioning-based pretraining, self-supervised losses, and online data curation into a unified training recipe for superior model performance.
💬 Research Conclusions:
– SigLIP 2 significantly outperforms its predecessor in tasks like zero-shot classification and image-text retrieval, and introduces improved localization, dense prediction, and fairness in multilingual understanding.
👉 Paper link: https://huggingface.co/papers/2502.14786

3. SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
🔑 Keywords: Large language models, Knowledge domains, Graduate-level knowledge
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The objective of the research is to evaluate the capabilities of Large Language Models (LLMs) across 285 disciplines, especially in lesser-studied fields like light industry and agriculture.
🛠️ Research Methods:
– The research employs a benchmark called SuperGPQA, which uses a Human-LLM collaborative filtering mechanism to refine questions through LLM responses and expert feedback.
💬 Research Conclusions:
– The study highlights a significant performance gap between current LLMs and the goal of achieving artificial general intelligence, as illustrated by a top accuracy of 61.82% in certain models on the benchmark.
– Insights from managing a large annotation process with over 80 expert annotators provide valuable methodological guidance for future research efforts.
👉 Paper link: https://huggingface.co/papers/2502.14739

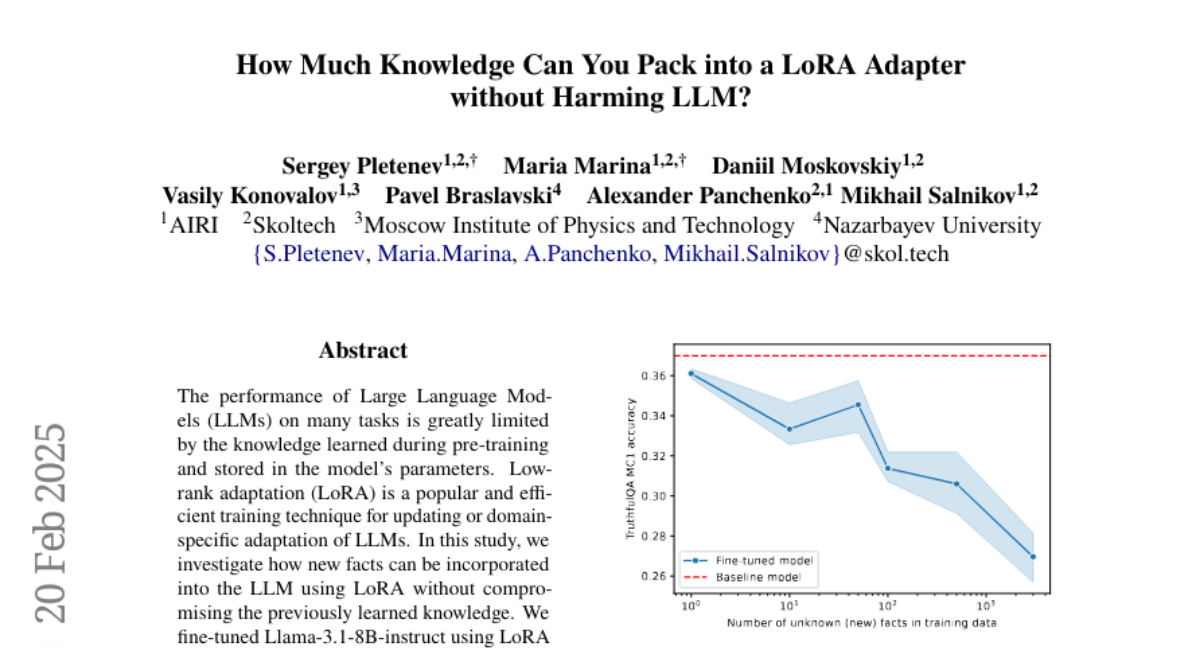
4. How Much Knowledge Can You Pack into a LoRA Adapter without Harming LLM?
🔑 Keywords: Large Language Models, Low-rank adaptation, LoRA, Training Data Composition, Model Performance
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the integration of new facts into Large Language Models (LLMs) using Low-rank adaptation (LoRA) without compromising existing knowledge.
🛠️ Research Methods:
– Fine-tuning Llama-3.1-8B-instruct with varying amounts of new knowledge using LoRA.
💬 Research Conclusions:
– Best results observed with mixed training data of known and new facts.
– Post fine-tuning performance decline on external benchmarks highlights potential pitfalls.
– Imbalance toward biased entities can lead to regression of overrepresented answers; importance of careful training data composition and tuning parameters is underscored.
👉 Paper link: https://huggingface.co/papers/2502.14502
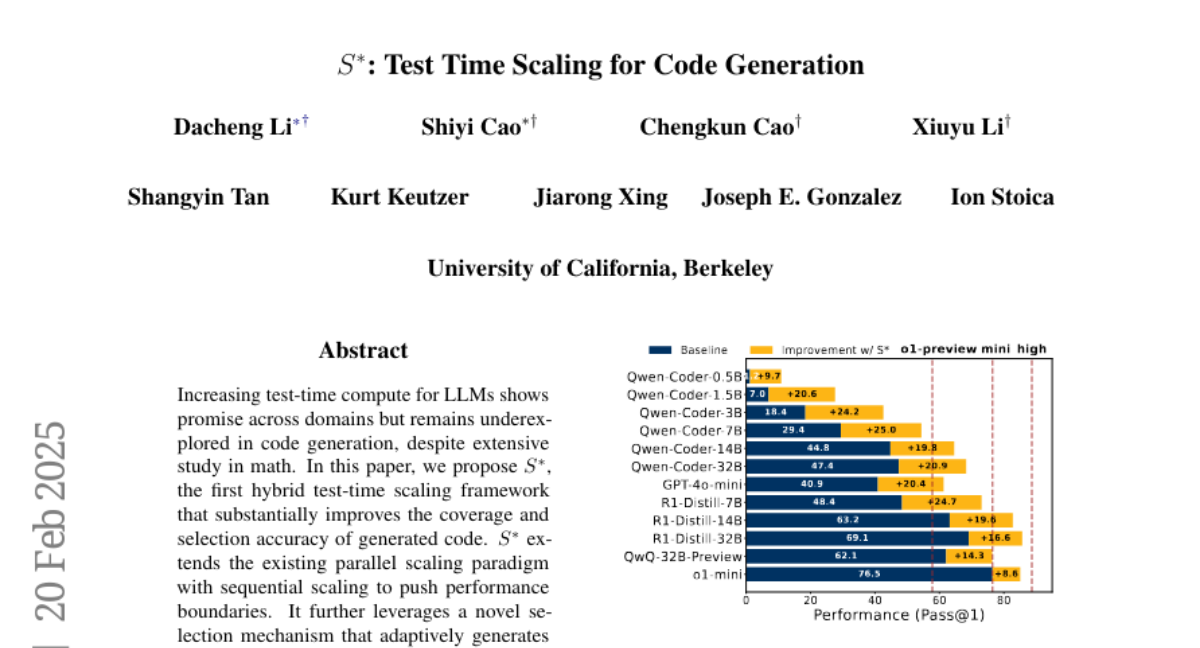
5. S*: Test Time Scaling for Code Generation
🔑 Keywords: LLMs, code generation, test-time scaling, selection mechanism
💡 Category: Generative Models
🌟 Research Objective:
– Introduce S*, a hybrid test-time scaling framework for improving code generation accuracy and coverage in Large Language Models (LLMs).
🛠️ Research Methods:
– Utilize a combination of parallel scaling and sequential scaling, along with a novel input selection mechanism for pairwise comparison in code generation.
💬 Research Conclusions:
– Demonstrated across 12 models, S* significantly enhances performance, allowing smaller models to outperform larger reasoning-focused models, such as enabling a 3B model to outperform GPT-4o-mini and boosting state-of-the-art reasoning model performance.
👉 Paper link: https://huggingface.co/papers/2502.14382
6. Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
🔑 Keywords: Rule-Based Reinforcement Learning, Logic Puzzles, Reasoning Dynamics, Generalization, Stable Training
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To explore the potential of rule-based reinforcement learning (RL) in large reasoning models by using logic puzzles for training.
🛠️ Research Methods:
– Utilized synthetic logic puzzles due to their controllable complexity.
– Developed a system prompt and format reward function to ensure effective and stable RL training.
💬 Research Conclusions:
– The 7B model developed advanced reasoning skills like reflection and verification.
– Demonstrated strong generalization abilities by performing well on challenging math benchmarks such as AIME and AMC.
👉 Paper link: https://huggingface.co/papers/2502.14768

7. Discovering highly efficient low-weight quantum error-correcting codes with reinforcement learning
🔑 Keywords: Quantum Computing, Quantum Error-Correcting Codes, Reinforcement Learning, Fault Tolerance, qLDPC Codes
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To optimize the measurement weight in quantum error-correcting codes to reduce implementation costs and errors.
🛠️ Research Methods:
– Introduced a reinforcement learning-based approach to stabilize code weight reduction, producing lower-weight quantum codes.
💬 Research Conclusions:
– The new approach significantly outperforms existing codes by reducing physical qubit overhead by 1 to 2 orders of magnitude, making it feasible for near-future experiments.
– Demonstrates the effectiveness of reinforcement learning in advancing quantum code discovery towards practical fault-tolerant quantum technologies.
👉 Paper link: https://huggingface.co/papers/2502.14372

8. LongWriter-V: Enabling Ultra-Long and High-Fidelity Generation in Vision-Language Models
🔑 Keywords: Large Vision-Language Models, LongWriter-V-22k, Direct Preference Optimization, IterDPO
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Address the challenge of generating coherent outputs over 1,000 words in Large Vision-Language Models by introducing a novel supervised fine-tuning dataset and methodology.
🛠️ Research Methods:
– Introduced LongWriter-V-22k, a dataset with 22,158 examples designed for extended output generation.
– Employed Direct Preference Optimization (DPO) and proposed IterDPO for efficient handling of lengthy outputs through segmenting and iterative corrections.
💬 Research Conclusions:
– The 7B parameter model, utilizing LongWriter-V-22k and IterDPO, demonstrated superior performance in long-generation tasks, surpassing larger models like GPT-4o.
👉 Paper link: https://huggingface.co/papers/2502.14834

9. Does Time Have Its Place? Temporal Heads: Where Language Models Recall Time-specific Information
🔑 Keywords: Temporal Heads, temporal knowledge, attention heads, language models
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to explore how language models handle temporally changing facts and identify specific attention heads, named Temporal Heads, responsible for processing temporal knowledge.
🛠️ Research Methods:
– The study involves circuit analysis to discover Temporal Heads and examines their presence across various models. It also involves experiments to disable these heads and assess the impact on time-specific knowledge recall versus general capabilities.
💬 Research Conclusions:
– Temporal Heads are crucial for processing temporal information in language models, as disabling them reduces the model’s ability to recall time-specific knowledge. These heads can be activated by both numeric and textual conditions, suggesting they encode a temporal dimension. Additionally, temporal knowledge can be edited by adjusting values in these heads.
👉 Paper link: https://huggingface.co/papers/2502.14258

10. S$^2$R: Teaching LLMs to Self-verify and Self-correct via Reinforcement Learning
🔑 Keywords: LLM test-time scaling, self-verification, self-correction, reinforcement learning, Qwen2.5-math-7B
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce the S^2R framework to enhance LLM reasoning by teaching models to self-verify and self-correct during inference.
🛠️ Research Methods:
– Utilize supervised fine-tuning on curated data followed by outcome-level and process-level reinforcement learning to fortify self-verification and self-correction skills.
💬 Research Conclusions:
– The S^2R framework significantly improves reasoning accuracy from 51.0% to 81.6% on Qwen2.5-math-7B with minimal resources, surpassing comparable models trained on long-CoT distilled data.
👉 Paper link: https://huggingface.co/papers/2502.12853

11. PC-Agent: A Hierarchical Multi-Agent Collaboration Framework for Complex Task Automation on PC
🔑 Keywords: MLLM-based GUI agents, Active Perception Module, hierarchical multi-agent collaboration, PC Eval
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To address the challenges of complex interactive environments and intricate workflows in PC scenarios using MLLM-based GUI agents.
🛠️ Research Methods:
– Developed a hierarchical agent framework named PC-Agent with a perception and decision-making perspective, including an Active Perception Module and a hierarchical multi-agent collaboration architecture.
💬 Research Conclusions:
– The proposed PC-Agent demonstrates a 32% improvement in task success rate on the PC-Eval benchmark compared to previous state-of-the-art methods.
👉 Paper link: https://huggingface.co/papers/2502.14282

12. Dynamic Concepts Personalization from Single Videos
🔑 Keywords: Generative Models, Diffusion Transformers, Text-to-Video, Dynamic Concepts
💡 Category: Generative Models
🌟 Research Objective:
– To extend personalization in generative models from text-to-image to text-to-video, focusing on capturing dynamic concepts through motion and appearance.
🛠️ Research Methods:
– Introducing the Set-and-Sequence framework using Diffusion Transformers with a two-stage process: first, fine-tuning Low-Rank Adaptation layers for learning appearance, and second, freezing these and augmenting with Motion Residuals to capture motion dynamics.
💬 Research Conclusions:
– The new Set-and-Sequence framework enables effective embedding of dynamic concepts in generative video models, offering improved editability and compositionality and setting a new benchmark for personalizing dynamic content.
👉 Paper link: https://huggingface.co/papers/2502.14844

13. Scaling Text-Rich Image Understanding via Code-Guided Synthetic Multimodal Data Generation
🔑 Keywords: Vision-Language Models (VLMs), Synthetic Data, Large Language Models (LLMs), Instruction-Tuning Data, Multimodal Agents
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to address the challenges faced by vision-language models (VLMs) in text-rich environments such as charts and documents by creating high-quality synthetic text-rich multimodal data.
🛠️ Research Methods:
– CoSyn framework leverages the coding capabilities of text-only large language models (LLMs) to automatically generate code for rendering synthetic images and produce corresponding instruction-tuning data.
💬 Research Conclusions:
– Models trained on synthetic data generated by CoSyn achieved state-of-the-art performance on seven benchmarks and surpassed proprietary models, indicating the potential for developing multimodal agents for real-world applications.
👉 Paper link: https://huggingface.co/papers/2502.14846

14. How to Get Your LLM to Generate Challenging Problems for Evaluation
🔑 Keywords: Large Language Models, CHASE, Synthetic Benchmarks, Evaluation, AI Systems and Tools
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce CHASE, a framework for generating challenging problems for LLMs without human involvement.
🛠️ Research Methods:
– CHASE constructs problems in a bottom-up manner and decomposes processes into independently verifiable sub-tasks.
💬 Research Conclusions:
– State-of-the-art LLMs achieved 40-60% accuracy on benchmarks in three domains, showcasing CHASE’s effectiveness in problem generation.
– The public release of benchmarks and code for broader use and evaluation.
👉 Paper link: https://huggingface.co/papers/2502.14678

15. NAVIG: Natural Language-guided Analysis with Vision Language Models for Image Geo-localization
🔑 Keywords: Image Geo-localization, Vision Language Models, Analytical Reasoning, NaviClues, Navig
💡 Category: Computer Vision
🌟 Research Objective:
– To improve image geo-localization accuracy by leveraging a new high-quality dataset and a novel framework.
🛠️ Research Methods:
– Creation of the NaviClues dataset from the GeoGuessr game, which provides expert reasoning examples.
– Development of the Navig framework that integrates image information globally and in fine detail.
💬 Research Conclusions:
– Navig reduces the average distance error by 14% compared to the latest models, using fewer than 1000 training samples.
– Both the dataset and code are publicly available for further research.
👉 Paper link: https://huggingface.co/papers/2502.14638

16. From RAG to Memory: Non-Parametric Continual Learning for Large Language Models
🔑 Keywords: Retrieval-Augmented Generation (RAG), Long-term Memory, Vector Retrieval, Personalized PageRank, Non-parametric Continual Learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To address the limitations of traditional RAG in mimicking the dynamic and interconnected nature of human long-term memory and improve its performance on factual, sense-making, and associative memory tasks.
🛠️ Research Methods:
– Enhanced the Personalized PageRank algorithm and integrated deeper passage schemes for improved online use of large language models (LLM).
💬 Research Conclusions:
– The proposed HippoRAG 2 framework significantly improves over standard RAG, achieving a 7% enhancement in associative memory tasks while excelling in factual and sense-making tasks, thus aiding non-parametric continual learning for LLMs.
👉 Paper link: https://huggingface.co/papers/2502.14802

17. AlphaMaze: Enhancing Large Language Models’ Spatial Intelligence via GRPO
🔑 Keywords: Large Language Models (LLMs), Supervised Fine Tuning (SFT), Group Relative Policy Optimization (GRPO), visual spatial reasoning, maze navigation.
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop a novel training framework that enhances standard Large Language Models (LLMs) with visual reasoning capabilities for maze navigation.
🛠️ Research Methods:
– Employed a two-stage training framework combining Supervised Fine Tuning (SFT) on a tokenized maze dataset with Group Relative Policy Optimization (GRPO) to improve step-by-step movement command prediction and decision-making.
💬 Research Conclusions:
– The approach significantly increased maze navigation accuracy in LLMs from a baseline failure to 93% after GRPO fine-tuning, demonstrating improved emergent chain-of-thought behaviors and potential applications in robotics and autonomous navigation.
👉 Paper link: https://huggingface.co/papers/2502.14669

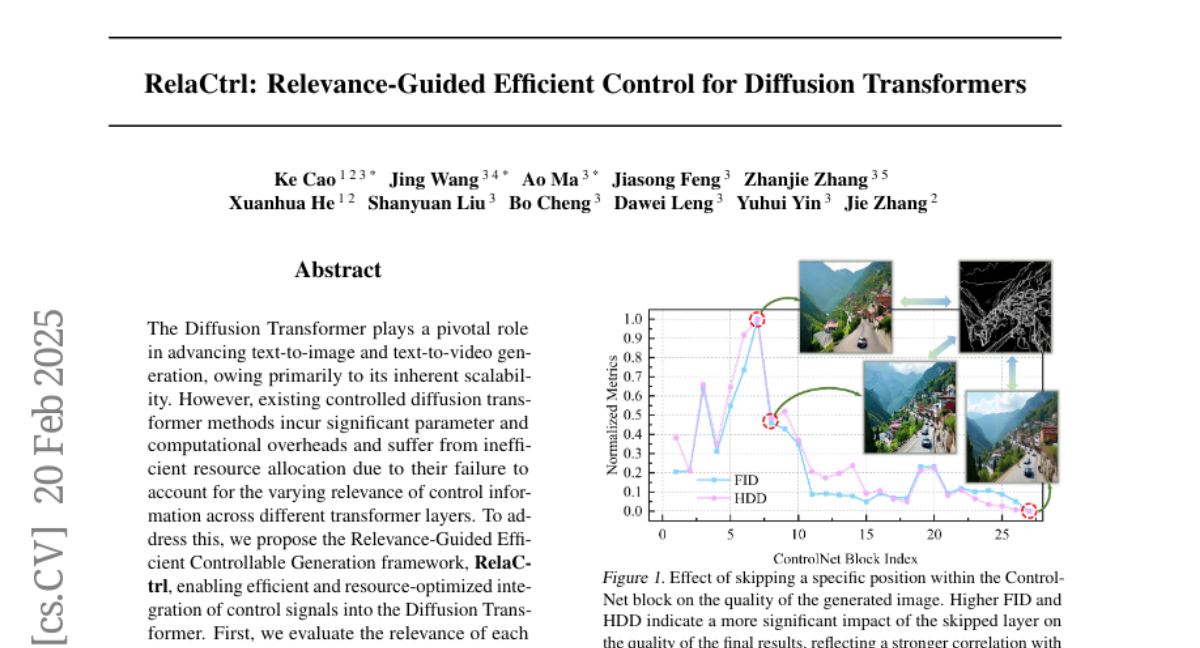
18. RelaCtrl: Relevance-Guided Efficient Control for Diffusion Transformers
🔑 Keywords: Diffusion Transformer, Relevance-Guided, Controllable Generation, Two-Dimensional Shuffle Mixer, ControlNet Relevance Score
💡 Category: Generative Models
🌟 Research Objective:
– To propose the Relevance-Guided Efficient Controllable Generation framework (RelaCtrl) for integrating control signals efficiently into the Diffusion Transformer.
🛠️ Research Methods:
– Introduction of the ControlNet Relevance Score to evaluate layers’ relevance in the Diffusion Transformer, enhancing control information positioning and parameter allocation.
– Replacing existing mechanisms with the Two-Dimensional Shuffle Mixer (TDSM) for improved token and channel mixing efficiency.
💬 Research Conclusions:
– RelaCtrl achieves superior performance with only 15% of the parameters and computational complexity compared to PixArt-delta, showcasing both qualitative and quantitative superiority.
👉 Paper link: https://huggingface.co/papers/2502.14377
19. LLM-based User Profile Management for Recommender System
🔑 Keywords: Large Language Models, zero-shot recommendation, user-generated textual data, PURE
💡 Category: Natural Language Processing
🌟 Research Objective:
– Propose PURE, a novel LLM-based recommendation framework that enhances zero-shot recommendation by incorporating user-generated textual data like reviews.
🛠️ Research Methods:
– PURE involves three components: a Review Extractor, a Profile Updater, and a Recommender, and it is evaluated on a continuous sequential recommendation task.
💬 Research Conclusions:
– PURE outperforms existing LLM-based methods by effectively using long-term user information and managing token limitations.
👉 Paper link: https://huggingface.co/papers/2502.14541

20. Enhancing Cognition and Explainability of Multimodal Foundation Models with Self-Synthesized Data
🔑 Keywords: Large Multimodal Models, Visual Reasoning, Explainability, Visual Rejection Sampling, Specialized Visual Classification
💡 Category: Computer Vision
🌟 Research Objective:
– Propose a novel framework to enhance the cognition and explainability of Large Multimodal Models (LMMs) in visual tasks.
🛠️ Research Methods:
– Develop a visual rejection sampling framework using self-synthesized data and iterative data synthesis with expert-defined concepts for fine-tuning.
💬 Research Conclusions:
– The proposed method improves both the accuracy and explainability in specialized visual classification tasks.
👉 Paper link: https://huggingface.co/papers/2502.14044

21. LServe: Efficient Long-sequence LLM Serving with Unified Sparse Attention
🔑 Keywords: Large language models, Hybrid sparse attention, LServe, Long-sequence processing, AI Systems and Tools
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces LServe, aiming to efficiently serve long-sequence large language models by addressing computational complexity and memory issues.
🛠️ Research Methods:
– The LServe system accelerates LLM serving through hybrid sparse attention, unifying structured sparsity patterns for prefilling and decoding stages, and dynamically pruning KV pages based on query-centric similarity.
💬 Research Conclusions:
– LServe achieves significant acceleration in LLM prefilling and decoding phases while maintaining long-context accuracy, with speedups up to 2.9x for prefilling and 1.3-2.1x for decoding compared to vLLM.
👉 Paper link: https://huggingface.co/papers/2502.14866

22. Geolocation with Real Human Gameplay Data: A Large-Scale Dataset and Human-Like Reasoning Framework
🔑 Keywords: Geolocation, GeoComp, GeoCoT, GeoEval, Large Vision Models
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce a comprehensive framework addressing current challenges in geolocation tasks, enhancing precision and interpretability.
🛠️ Research Methods:
– Development of a large-scale dataset (GeoComp) with diverse difficulty levels.
– Introduction of GeoCoT, a novel multi-step reasoning framework for improving geolocation tasks in Large Vision Models.
– Implementation of GeoEval, a new evaluation metric to measure the effectiveness of geolocation processes.
💬 Research Conclusions:
– GeoComp provides a rich dataset enhancing analysis of geolocation difficulties.
– GeoCoT significantly improves geolocation accuracy by up to 25% and enhances interpretability.
👉 Paper link: https://huggingface.co/papers/2502.13759

23. Unstructured Evidence Attribution for Long Context Query Focused Summarization
🔑 Keywords: Large Language Models, Summarization, Evidence Citation, Positional Biases, SUnsET
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to address the challenge of generating summaries with unstructured evidence citation from long contexts using Large Language Models (LLMs).
🛠️ Research Methods:
– The authors created a synthetic dataset named SUnsET using a novel domain-agnostic pipeline to supervise and adapt LLMs for the task of long-context query-focused summarization.
💬 Research Conclusions:
– LLMs adapted with SUnsET data produce more relevant and factually consistent evidence and summaries, overcoming positional biases by extracting evidence from diverse locations in their context.
👉 Paper link: https://huggingface.co/papers/2502.14409

24. How Much Do LLMs Hallucinate across Languages? On Multilingual Estimation of LLM Hallucination in the Wild
🔑 Keywords: Hallucination, Large Language Models (LLMs), Multilingual, Misinformation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to quantify LLM hallucination across languages in knowledge-intensive long-form question answering.
🛠️ Research Methods:
– A multilingual hallucination detection model is trained using MT-generated datasets for 30 languages and annotations for five high-resource languages, with additional large-scale studies across various LLM families.
💬 Research Conclusions:
– LLMs generate more hallucinated content for higher-resource languages, with smaller models showing larger hallucination rates; no correlation was found between hallucination rates and digital representation of languages.
👉 Paper link: https://huggingface.co/papers/2502.12769

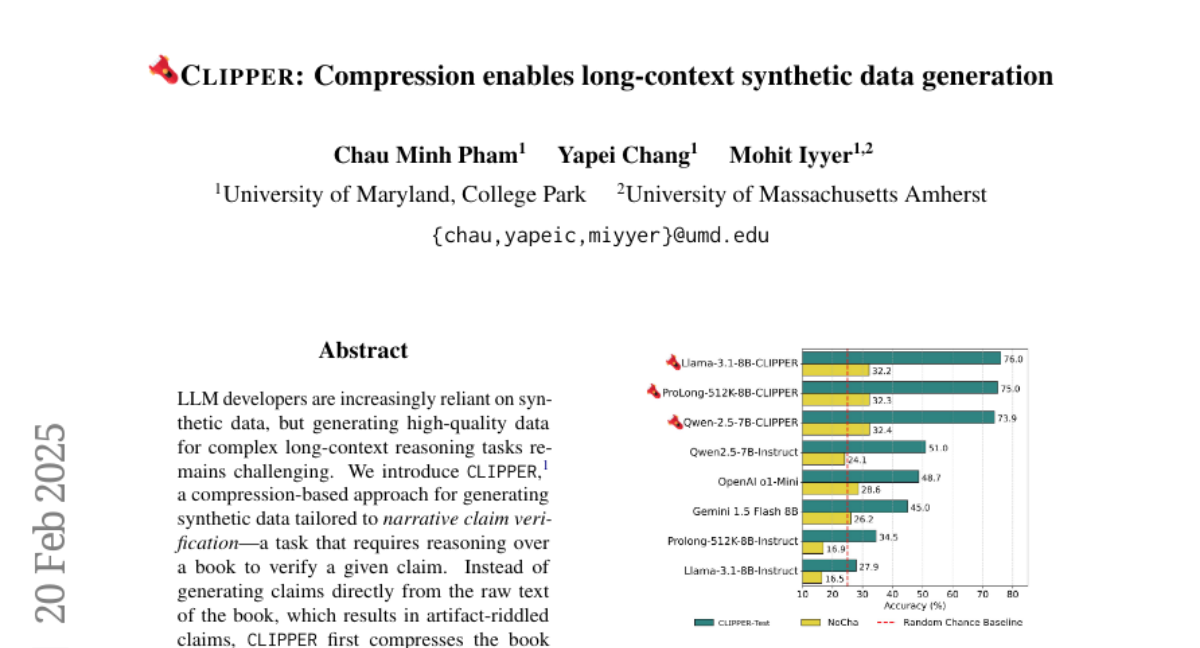
25. CLIPPER: Compression enables long-context synthetic data generation
🔑 Keywords: Synthetic Data, Narrative Claim Verification, CLIPPER, Chain-of-Thought Reasoning, State-of-the-Art
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address the challenge of generating high-quality synthetic data for complex long-context reasoning tasks, specifically for narrative claim verification.
🛠️ Research Methods:
– Introduced CLIPPER, a compression-based approach, which generates synthetic data by compressing books into chapter outlines and summaries before creating complex claims and chain-of-thought reasoning.
– Constructed a dataset of 19K synthetic book claims with source texts and reasoning chains, using it to fine-tune three models.
💬 Research Conclusions:
– CLIPPER-generated claims are more valid, grounded, and complex compared to naive methods.
– The best model significantly improved narrative claim verification accuracy from 28% to 76%, setting a new state-of-the-art for models under 10B parameters.
– The approach enhances detailed chain-of-thought reasoning and improves performance on other narrative understanding tasks like NarrativeQA.
👉 Paper link: https://huggingface.co/papers/2502.14854
26. Multimodal RewardBench: Holistic Evaluation of Reward Models for Vision Language Models
🔑 Keywords: Reward Models, Vision-Language Models, Multimodal RewardBench, Reasoning, Safety
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces Multimodal RewardBench, a benchmark to evaluate multimodal reward models in vision-language models (VLMs) across six domains.
🛠️ Research Methods:
– An expert-annotated dataset of 5,211 annotated triplets from various VLMs is used to assess the models.
💬 Research Conclusions:
– Even top-performing models like Gemini 1.5 Pro and Claude 3.5 Sonnet achieve only 72% accuracy, with significant challenges in reasoning and safety domains.
👉 Paper link: https://huggingface.co/papers/2502.14191

27. Symmetrical Visual Contrastive Optimization: Aligning Vision-Language Models with Minimal Contrastive Images
🔑 Keywords: Large Vision-Language Models, Visual Grounding, Symmetrical Visual Contrastive Optimization, Minimal Visual Contrasts
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Address the issue of Large Vision-Language Models neglecting image content by enhancing their ability to generate text grounded in fine-grained visual details.
🛠️ Research Methods:
– Introduced S-VCO (Symmetrical Visual Contrastive Optimization) for improved visual feedback during model training.
– Developed MVC, a paired image-text dataset with challenging contrastive cases to align visual details with text tokens.
💬 Research Conclusions:
– The proposed method reduces hallucinations by up to 22% and improves performance in both vision-centric and general tasks.
– Improvements are most significant in benchmarks with a higher reliance on visual information.
– S-VCO demonstrates enhanced performance in visually-dependent tasks while maintaining or boosting overall model abilities.
👉 Paper link: https://huggingface.co/papers/2502.13928

28. Generating $π$-Functional Molecules Using STGG+ with Active Learning
🔑 Keywords: Molecular Discovery, Supervised Learning, Reinforcement Learning, Active Learning, Organic Pi-functional Materials
💡 Category: Generative Models
🌟 Research Objective:
– The goal is to generate novel molecules with out-of-distribution properties, focusing on highly absorptive molecules with high oscillator strength and absorptive molecules in the near-infrared range.
🛠️ Research Methods:
– The integration of STGG+, a state-of-the-art supervised learning method, into an active learning loop, termed STGG+AL, to iteratively generate, evaluate, and fine-tune for expanding molecular knowledge.
💬 Research Conclusions:
– STGG+AL is effective in generating novel molecules with high oscillator strength, outperforming existing methods like reinforcement learning. The approach is validated using in-silico methods, and resources such as the active-learning code and Conjugated-xTB dataset are open-sourced.
👉 Paper link: https://huggingface.co/papers/2502.14842
