AI Native Daily Paper Digest – 20241211

1. STIV: Scalable Text and Image Conditioned Video Generation
🔑 Keywords: Video Generation, STIV, Diffusion Transformer, VBench
💡 Category: Generative Models
🌟 Research Objective:
– To develop a robust and scalable text-image-conditioned video generation method, STIV, capable of handling T2V and TI2V tasks simultaneously.
🛠️ Research Methods:
– Integration of image condition into a Diffusion Transformer through frame replacement, and text conditioning via a joint image-text conditional classifier-free guidance.
💬 Research Conclusions:
– STIV demonstrates strong performance on T2V and I2V tasks, surpassing leading open and closed-source models, and can be extended to various applications.
👉 Paper link: https://huggingface.co/papers/2412.07730

2. Evaluating and Aligning CodeLLMs on Human Preference
🔑 Keywords: codeLLMs, CodeArena, human preference, synthetic instruction, Qwen2.5-SynCoder
💡 Category: Natural Language Processing
🌟 Research Objective:
– To bridge the gap between model-generated responses and human preference in code generation.
🛠️ Research Methods:
– Creation of CodeArena benchmark with 397 samples across 40 categories and 44 languages.
– Development of SynCode-Instruct corpus for large-scale synthetic instruction fine-tuning.
💬 Research Conclusions:
– Notable performance gap identified between open-source and proprietary code LLMs.
– Highlights the importance of aligning with human preferences.
👉 Paper link: https://huggingface.co/papers/2412.05210

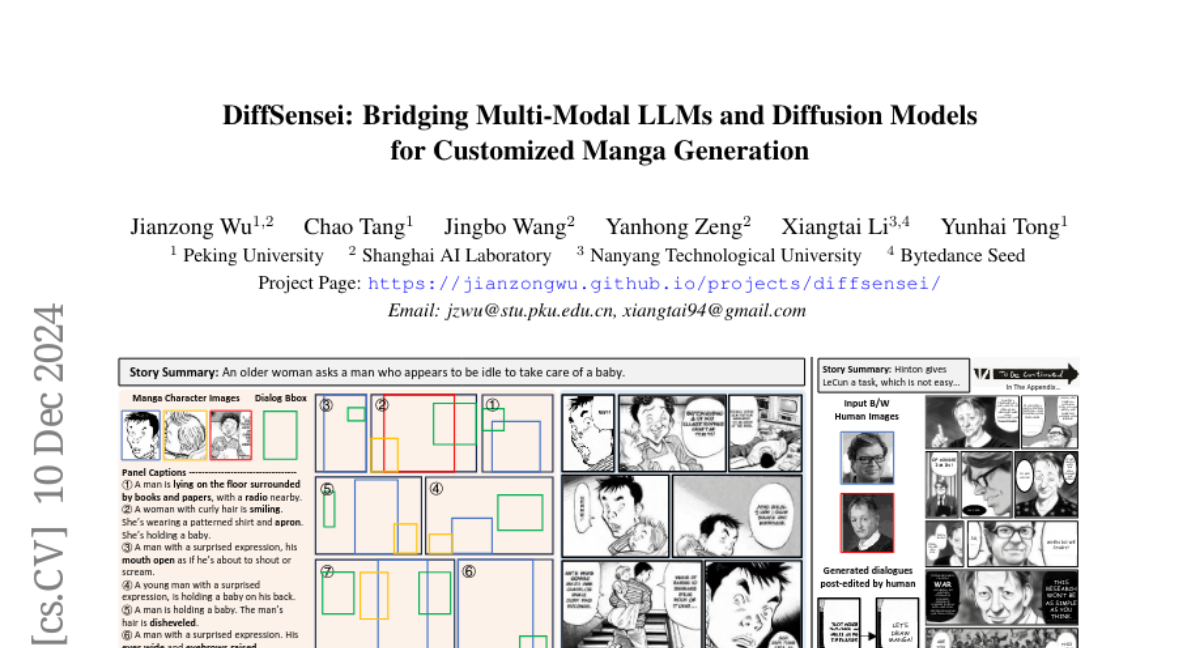
3. DiffSensei: Bridging Multi-Modal LLMs and Diffusion Models for Customized Manga Generation
🔑 Keywords: Story Visualization, Text-to-Image Generation, Dynamic Multi-Character Control, Customized Manga Generation, DiffSensei
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to address limitations in text-to-image models specifically related to character control in multi-character scenes by proposing customizable manga generation.
🛠️ Research Methods:
– The study introduces DiffSensei, a framework combining a diffusion-based image generator with a multimodal large language model, using techniques like masked cross-attention to maintain precise layout control.
💬 Research Conclusions:
– Extensive experiments demonstrate DiffSensei’s superiority over existing models, marking significant advancement by enabling text-adaptable character customization. The research is supported by MangaZero, a large-scale dataset.
👉 Paper link: https://huggingface.co/papers/2412.07589
4. ACDiT: Interpolating Autoregressive Conditional Modeling and Diffusion Transformer
🔑 Keywords: Multimodal Models, Autoregressive Modeling, Visual Generation, Diffusion Transformer, Image and Video Generation
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to explore the combination of autoregressive modeling and full-parameter diffusion for visual information processing in order to develop a unified multimodal model.
🛠️ Research Methods:
– The paper introduces ACDiT, an Autoregressive blockwise Conditional Diffusion Transformer, which allows for flexible interpolation between autoregressive and full-sequence diffusion approaches through adjustable block sizes.
💬 Research Conclusions:
– ACDiT is verified to be effective in image and video generation tasks and can be utilized in visual understanding tasks, demonstrating its potential for long-horizon visual generation and as a foundation for future unified models.
👉 Paper link: https://huggingface.co/papers/2412.07720

5. Hidden in the Noise: Two-Stage Robust Watermarking for Images
🔑 Keywords: Deepfakes, Image Watermarking, Diffusion Model, Forgery, Robustness
💡 Category: Computer Vision
🌟 Research Objective:
– To present a distortion-free image watermarking method that is robust against forgery and removal attacks.
🛠️ Research Methods:
– Developed a two-stage watermarking framework, utilizing initial noise from a diffusion model and augmented Fourier patterns for efficient detection.
💬 Research Conclusions:
– The proposed watermarking approach enhances robustness against attacks, capable of withstanding a broad range of forgery and removal techniques.
👉 Paper link: https://huggingface.co/papers/2412.04653

6. FiVA: Fine-grained Visual Attribute Dataset for Text-to-Image Diffusion Models
🔑 Keywords: Text-to-Image Generation, Visual Attributes, FiVA, Style Adaptation, AI Native
💡 Category: Generative Models
🌟 Research Objective:
– Develop a method to decompose and apply specific visual attributes like lighting and texture from source images to generate customized images.
🛠️ Research Methods:
– Constructed the FiVA dataset featuring visual attribute taxonomy with around 1 million annotated images.
– Proposed the FiVA-Adapter framework to decouple and adapt multiple visual attributes from source images.
💬 Research Conclusions:
– Enhanced the customization of generated images by allowing selective attribute application, improving user control over content creation.
👉 Paper link: https://huggingface.co/papers/2412.07674
7. UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics
🔑 Keywords: UniReal, image generation, video generation, consistency, visual variations
💡 Category: Generative Models
🌟 Research Objective:
– The aim is to establish UniReal, a unified framework to tackle diverse image generation and editing tasks using principles learned from recent video generation models.
🛠️ Research Methods:
– The approach involves treating image-level tasks as discontinuous video generation by using input and output images as frames to maintain consistency and capture variations.
💬 Research Conclusions:
– UniReal demonstrates advanced capabilities in managing shadows, reflections, pose variation, and object interaction, showing potential for novel applications by learning world dynamics from large-scale videos.
👉 Paper link: https://huggingface.co/papers/2412.07774

8. 3DTrajMaster: Mastering 3D Trajectory for Multi-Entity Motion in Video Generation
🔑 Keywords: 3DTrajMaster, 3D motion, multi-entity dynamics, video generation, 6DoF pose
💡 Category: Generative Models
🌟 Research Objective:
– Develop a robust controller, 3DTrajMaster, for manipulating multi-entity 3D motions in video generation.
🛠️ Research Methods:
– Introduce a plug-and-play 3D-motion grounded object injector using a gated self-attention mechanism.
– Preserve video diffusion prior via an injector architecture to enhance generalization.
– Construct a 360-Motion Dataset with GPT-generated trajectories for training.
💬 Research Conclusions:
– 3DTrajMaster achieves state-of-the-art accuracy and generalization in controlling multi-entity 3D motions.
👉 Paper link: https://huggingface.co/papers/2412.07759

9. Mobile Video Diffusion
🔑 Keywords: Video diffusion models, Mobile optimization, Spatio-temporal UNet, Adversarial finetuning
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to design a mobile-optimized video diffusion model that reduces computational demands while maintaining video quality.
🛠️ Research Methods:
– The research employs reductions in frame resolution, incorporation of multi-scale temporal representations, novel pruning schema, and adversarial finetuning to enhance model efficiency.
💬 Research Conclusions:
– The newly developed model, MobileVD, is shown to be 523 times more efficient than previous models with only a minor quality decrease, making it feasible for use on mobile devices.
👉 Paper link: https://huggingface.co/papers/2412.07583

10. Granite Guardian
🔑 Keywords: Granite Guardian, Risk Detection, LLM, AI Ethics, Responsible AI
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– Introduce the Granite Guardian models designed to provide risk detection for prompts and responses ensuring safe usage with any large language model.
🛠️ Research Methods:
– Developed a suite of models trained on a dataset combining human annotations from diverse sources and synthetic data for comprehensive risk coverage.
💬 Research Conclusions:
– Granite Guardian models offer robust detection across various risk dimensions such as social bias and context relevance, outperforming traditional models with competitive AUC scores and promoting responsible AI development.
👉 Paper link: https://huggingface.co/papers/2412.07724

11. OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations
🔑 Keywords: Document content extraction, Computer Vision, OmniDocBench, Evaluation Standard
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce OmniDocBench, a benchmark designed to enhance automated document content extraction by addressing limitations in diversity and evaluation.
🛠️ Research Methods:
– Development of a high-quality evaluation dataset with nine document types and multiple labels for comprehensive evaluation.
– Comparative analysis of modular pipelines and multimodal end-to-end methods using OmniDocBench.
💬 Research Conclusions:
– OmniDocBench provides a robust and fair evaluation standard for document content extraction, offering significant insights for future advancements in document parsing technologies.
👉 Paper link: https://huggingface.co/papers/2412.07626

12. MoViE: Mobile Diffusion for Video Editing
🔑 Keywords: Diffusion-based video editing, Mobile devices, Autoencoder, Adversarial distillation
💡 Category: Computer Vision
🌟 Research Objective:
– To optimize existing diffusion-based video editing methods for feasible deployment on mobile devices.
🛠️ Research Methods:
– Architecture optimization and incorporation of a lightweight autoencoder.
– Extension of classifier-free guidance distillation to multiple modalities.
– Introduction of a novel adversarial distillation scheme to reduce sampling steps.
💬 Research Conclusions:
– Achieved a threefold speedup and enabled video editing at 12 frames per second on mobile devices while maintaining high quality.
👉 Paper link: https://huggingface.co/papers/2412.06578

13. Video Motion Transfer with Diffusion Transformers
🔑 Keywords: DiTFlow, Diffusion Transformers, Attention Motion Flow, motion transfer, optimization
💡 Category: Generative Models
🌟 Research Objective:
– To propose DiTFlow, a method designed to transfer motion from a reference video to a newly synthesized one, specifically utilizing Diffusion Transformers.
🛠️ Research Methods:
– Process reference video using pre-trained Diffusion Transformers to analyze cross-frame attention maps.
– Extract patch-wise motion signal called Attention Motion Flow (AMF).
– Guide latent denoising process with an optimization-based, training-free strategy using AMF loss.
💬 Research Conclusions:
– DiTFlow demonstrates superior performance in zero-shot motion transfer capabilities, outperforming recent methods across multiple metrics and human evaluation.
👉 Paper link: https://huggingface.co/papers/2412.07776

14. Frame Representation Hypothesis: Multi-Token LLM Interpretability and Concept-Guided Text Generation
🔑 Keywords: Interpretability, Large Language Models, Frame Representation Hypothesis, Linguistic Concepts, Gender and Language Biases
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance interpretability of large language models (LLMs) by extending the Linear Representation Hypothesis (LRH) to multi-token words, enabling control and interpretation of LLMs using frame representations.
🛠️ Research Methods:
– Development of the Frame Representation Hypothesis to represent concepts as ordered sequences of vectors (frames).
– Implementation of Top-k Concept-Guided Decoding to steer text generation.
💬 Research Conclusions:
– Verified the approach on Llama 3.1, Gemma 2, and Phi 3 families, revealing gender and language biases, and potential for bias remediation, contributing to safer, more transparent LLMs.
👉 Paper link: https://huggingface.co/papers/2412.07334

15. ILLUME: Illuminating Your LLMs to See, Draw, and Self-Enhance
🔑 Keywords: ILLUME, Multimodal Large Language Model, Vision Tokenizer, Self-enhancing Multimodal Alignment
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduction of ILLUME, a unified model that integrates multimodal understanding and generation within a single framework.
🛠️ Research Methods:
– Implementation of a vision tokenizer with semantic information to improve data efficiency.
– A novel self-enhancing alignment scheme to promote synergy between understanding and generation.
💬 Research Conclusions:
– ILLUME achieves competitive or superior performance compared to existing models, demonstrating effectiveness in multimodal tasks.
👉 Paper link: https://huggingface.co/papers/2412.06673

16. Perception Tokens Enhance Visual Reasoning in Multimodal Language Models
🔑 Keywords: Multimodal Language Models, Perception Tokens, Reasoning, AURORA, Visual Inputs
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to enhance reasoning capabilities of Multimodal Language Models (MLMs) by introducing Perception Tokens for improved performance on visual perception tasks.
🛠️ Research Methods:
– The introduction of Perception Tokens as auxiliary reasoning tools akin to chain-of-thought prompts, and the development of the AURORA training method which uses a VQVAE to transform intermediate image representations into a tokenized format.
💬 Research Conclusions:
– AURORA, utilizing Perception Tokens, notably improves MLM performance on counting benchmarks and relative depth tasks, outperforming traditional finetuning methods and expanding MLM capabilities beyond language-based reasoning.
👉 Paper link: https://huggingface.co/papers/2412.03548

17. EMOv2: Pushing 5M Vision Model Frontier
🔑 Keywords: Lightweight Models, Dense Predictions, 5M Magnitude, Inverted Residual Block, EMOv2
💡 Category: Computer Vision
🌟 Research Objective:
– Develop parameter-efficient and lightweight models for dense predictions while optimizing parameters, FLOPs, and performance, aiming to establish a new frontier for 5M magnitude lightweight models across various tasks.
🛠️ Research Methods:
– Utilize an improved Inverted Residual Mobile Block (i2RMB) and enhance a hierarchical Efficient MOdel (EMOv2) without complex structures. Introduce a Meta Mobile Block (MMBlock) to unify CNN-based and attention-based designs.
💬 Research Conclusions:
– EMOv2 models demonstrate superior performance in vision recognition, dense prediction, and image generation tasks compared to state-of-the-art methods. EMOv2-5M, paired with RetinaNet, achieves significant gains in object detection tasks, with further improvements using robust training methods.
👉 Paper link: https://huggingface.co/papers/2412.06674

18. Fully Open Source Moxin-7B Technical Report
🔑 Keywords: Large Language Models, GPT-4, Moxin 7B, Open Science, Model Openness Framework
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Moxin 7B, a fully open-source LLM aligned with the Model Openness Framework to address transparency and reproducibility concerns.
🛠️ Research Methods:
– Developed a ranked classification system to evaluate AI models on openness, involving comprehensive release of pre-training code, configurations, datasets, and checkpoints.
💬 Research Conclusions:
– Moxin 7B achieves the highest MOF “open science” classification and demonstrates superior performance in zero-shot evaluation compared to popular 7B models.
👉 Paper link: https://huggingface.co/papers/2412.06845

19. LoRA.rar: Learning to Merge LoRAs via Hypernetworks for Subject-Style Conditioned Image Generation
🔑 Keywords: Image Generation, Personalization, LoRA.rar, Real-time, Multimodal Large Language Models
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to enhance personalized image creation by improving the merging process of low-rank adaptation parameters (LoRAs), focusing on both user-defined subjects and styles with efficiency suitable for real-time use.
🛠️ Research Methods:
– Introduces LoRA.rar, a method that pre-trains a hypernetwork to efficiently merge content-style LoRA pairs, achieving significant speedup and quality improvement.
– Proposes a new evaluation protocol using multimodal large language models (MLLM) to assess content-style quality.
💬 Research Conclusions:
– LoRA.rar demonstrates a 4000-times speedup in the merging process while surpassing existing methods in content and style fidelity, as confirmed by MLLM and human evaluations.
👉 Paper link: https://huggingface.co/papers/2412.05148
20. ObjCtrl-2.5D: Training-free Object Control with Camera Poses
🔑 Keywords: ObjCtrl-2.5D, object control, image-to-video generation, 3D trajectory
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to enhance precision and versatility in object control within image-to-video generation by introducing a new approach that goes beyond conventional 2D trajectories.
🛠️ Research Methods:
– The paper presents ObjCtrl-2.5D, a training-free object control method that utilizes a 3D trajectory (including depth information) as control signals, and models object movement as camera movement, employing a camera motion control model to facilitate this.
💬 Research Conclusions:
– ObjCtrl-2.5D significantly improves control accuracy and provides more diverse object control capabilities without training, surpassing traditional methods and enabling complex effects like object rotation.
👉 Paper link: https://huggingface.co/papers/2412.07721
21. Chimera: Improving Generalist Model with Domain-Specific Experts
🔑 Keywords: Large Multi-modal Models, domain-specific tasks, Generalist-Specialist Collaboration Masking, Chimera
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The main goal is to enhance the capabilities of existing Large Multi-modal Models (LMMs) by integrating domain-specific expert knowledge.
🛠️ Research Methods:
– Introduce a scalable multi-modal pipeline named Chimera, employing a progressive training strategy and a novel Generalist-Specialist Collaboration Masking (GSCM) mechanism.
💬 Research Conclusions:
– The resulting model demonstrates state-of-the-art performance in challenging multi-modal reasoning and visual content extraction tasks specific to various domains like charts, tables, math, and documents.
👉 Paper link: https://huggingface.co/papers/2412.05983

22. HARP: Hesitation-Aware Reframing in Transformer Inference Pass
🔑 Keywords: Computational demands, Transformer, HARP, performance improvement, inference times
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to enhance the performance of large language models by addressing variable computational demands during inference.
🛠️ Research Methods:
– The study introduces HARP, a modification for Transformer models that applies additional computation selectively, inspired by human cognitive processes such as hesitation and the framing effect.
💬 Research Conclusions:
– HARP shows performance improvements of up to +5.16% across various tasks and maintains faster inference times compared to traditional methods like beam search.
👉 Paper link: https://huggingface.co/papers/2412.07282

23. GraPE: A Generate-Plan-Edit Framework for Compositional T2I Synthesis
🔑 Keywords: Text-to-image generation, Diffusion models, Multi-Modal LLMs, Image editing, Compositional editing
💡 Category: Generative Models
🌟 Research Objective:
– The paper seeks to address the challenges in current text-to-image (T2I) generation methodologies, focusing on improving the accuracy of image synthesis from complex text prompts.
🛠️ Research Methods:
– The authors propose a three-step process: Generate images using diffusion models, use Multi-Modal LLMs to identify and correct errors, and employ text-guided image editing to align the image with the original instruction.
💬 Research Conclusions:
– The approach enhances current state-of-the-art model performance by up to 3 points, bridging the gap between less and more capable models, verified by extensive evaluations across benchmarks and various T2I models.
👉 Paper link: https://huggingface.co/papers/2412.06089

24. A New Federated Learning Framework Against Gradient Inversion Attacks
🔑 Keywords: Federated Learning, Gradient Inversion Attacks, Privacy-Preserving, Hypernetwork, Secure Multi-party Computing
💡 Category: Machine Learning
🌟 Research Objective:
– To design a privacy-preserving Federated Learning framework that mitigates the risk of privacy loss through Gradient Inversion Attacks.
🛠️ Research Methods:
– Introduction of Hypernetwork Federated Learning (HyperFL) framework that employs hypernetworks to produce parameters for local models while only sharing hypernetwork parameters with the central server.
💬 Research Conclusions:
– Theoretical analysis shows the convergence rate of HyperFL, and experiments demonstrate its capability to preserve privacy and maintain competitive performance.
👉 Paper link: https://huggingface.co/papers/2412.07187

25. Maximizing Alignment with Minimal Feedback: Efficiently Learning Rewards for Visuomotor Robot Policy Alignment
🔑 Keywords: Visuomotor robot policies, RLHF, Representation-Aligned Preference-based Learning, human feedback, visual reward
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To address the challenge of aligning visuomotor robot policies with end-user preferences using less human feedback.
🛠️ Research Methods:
– Introduction of Representation-Aligned Preference-based Learning (RAPL), which leverages an observation-only approach to learn visual rewards with reduced human preference feedback by fine-tuning pre-trained vision encoders.
💬 Research Conclusions:
– RAPL effectively learns rewards aligned with human preferences, uses preference data more efficiently, and generalizes across different robot embodiments, with a fivefold reduction in required human feedback for training visuomotor robot policies.
👉 Paper link: https://huggingface.co/papers/2412.04835

26. Contextualized Counterspeech: Strategies for Adaptation, Personalization, and Evaluation
🔑 Keywords: AI-generated counterspeech, civil discourse, contextualized counterspeech, personalized counterspeech, human-AI collaboration
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore strategies for generating AI-generated counterspeech that is tailored to moderation contexts and personalized for individual users.
🛠️ Research Methods:
– Implemented using LLaMA2-13B model with various configurations and fine-tuning strategies, evaluated through a mixed-design crowdsourcing experiment.
💬 Research Conclusions:
– Contextualized counterspeech shows superior adequacy and persuasiveness compared to generic counterspeech, revealing the need for nuanced evaluation methodologies and emphasizing the potential for enhanced human-AI collaboration in content moderation.
👉 Paper link: https://huggingface.co/papers/2412.07338
