AI Native Daily Paper Digest – 20241223

1. Parallelized Autoregressive Visual Generation
🔑 Keywords: Autoregressive models, Parallel generation, Visual generation, Inference speed
💡 Category: Generative Models
🌟 Research Objective:
– To enhance the efficiency of visual generation using autoregressive models by introducing a method for parallelized token generation.
🛠️ Research Methods:
– Developed a parallel generation strategy that generates tokens with weak dependencies in parallel while maintaining sequential generation for strongly dependent tokens, integrated without altering existing model architectures.
💬 Research Conclusions:
– The method achieves a significant speedup in the generation process (up to 9.5x) with minimal impact on quality, as demonstrated in experiments on both image and video datasets like ImageNet and UCF-101.
👉 Paper link: https://huggingface.co/papers/2412.15119
2. Offline Reinforcement Learning for LLM Multi-Step Reasoning
🔑 Keywords: Offline Reinforcement Learning, Multi-Step Reasoning, Direct Preference Optimization, Value Function, Multi-Iteration Framework
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance the multi-step reasoning capability of large language models (LLMs) using offline reinforcement learning.
🛠️ Research Methods:
– Developed OREO (Offline Reasoning Optimization), leveraging the soft Bellman Equation to jointly learn a policy model and value function.
– Compared OREO to existing methods on benchmarks such as GSM8K, MATH, and ALFWorld.
💬 Research Conclusions:
– OREO reduces reliance on pairwise preference data and enhances credit assignment.
– Demonstrated superior performance over existing offline learning methods for multi-step reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2412.16145

3. SCOPE: Optimizing Key-Value Cache Compression in Long-context Generation
🔑 Keywords: KV cache, LLMs, long-context generation, SCOPE, decoding phase
💡 Category: Generative Models
🌟 Research Objective:
– Address bottlenecks in KV cache optimization during the decoding phase for long-context generation in LLMs.
🛠️ Research Methods:
– Proposed a framework called SCOPE with novel strategies for preserving essential information and optimizing memory usage.
💬 Research Conclusions:
– SCOPE demonstrates effectiveness and generalization in experiments on LongGenBench, showing its compatibility as a plug-in for other KV compression methods.
👉 Paper link: https://huggingface.co/papers/2412.13649

4. Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis
🔑 Keywords: Multimodal Training, Audio-Visual Synchronization, State-of-the-Art, Semantic Alignment
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Propose a novel multimodal joint training framework, MMAudio, to synthesize high-quality synchronized audio from video and optional text inputs.
🛠️ Research Methods:
– Jointly train MMAudio using large-scale text-audio data with a conditional synchronization module for frame-level alignment.
– Optimize with a flow matching objective to achieve superior video-to-audio performance.
💬 Research Conclusions:
– MMAudio achieves state-of-the-art performance in generating audio quality, semantic alignment, and synchronization, with low inference time and compact model size.
– The framework performs competitively in text-to-audio generation, indicating joint training benefits both multi-modal and single-modality tasks.
👉 Paper link: https://huggingface.co/papers/2412.15322
5. CLEAR: Conv-Like Linearization Revs Pre-Trained Diffusion Transformers Up
🔑 Keywords: Diffusion Transformers, linear attention mechanism, CLEAR, high-resolution images, zero-shot generalization
💡 Category: Generative Models
🌟 Research Objective:
– To develop a linear attention mechanism to reduce the complexity of pre-trained Diffusion Transformers while maintaining high performance in high-resolution image generation.
🛠️ Research Methods:
– Analyzed existing efficient attention mechanisms.
– Identified key factors for successful linearization: locality, formulation consistency, high-rank attention maps, and feature integrity.
– Proposed a local attention strategy called CLEAR to limit feature interactions to a local window.
💬 Research Conclusions:
– Successfully reduced attention computations by 99.5% and accelerated generation by 6.3 times for 8K-resolution images.
– Achieved similar results to the teacher model with significantly lower complexity.
– Demonstrated advantageous properties in distilled layers, including zero-shot generalization and improved support for multi-GPU parallel inference.
👉 Paper link: https://huggingface.co/papers/2412.16112

6. Toward Robust Hyper-Detailed Image Captioning: A Multiagent Approach and Dual Evaluation Metrics for Factuality and Coverage
🔑 Keywords: Multimodal large language models, hallucination detection, LLM-MLLM collaboration, GPT-4V
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Address hallucinations in detailed captions generated by Multimodal large language models (MLLMs).
🛠️ Research Methods:
– Introduce a multiagent approach with LLM-MLLM collaboration to correct captions and develop an evaluation framework and benchmark dataset.
💬 Research Conclusions:
– The proposed method enhances the factual accuracy of captions and better aligns with human judgment compared to existing metrics, even outperforming in hyper-detailed image captioning tasks.
👉 Paper link: https://huggingface.co/papers/2412.15484

7. Sequence Matters: Harnessing Video Models in 3D Super-Resolution
🔑 Keywords: 3D Super-Resolution, Video Super-Resolution, Spatial Consistency, Low-Resolution Images, Benchmark Datasets
💡 Category: Computer Vision
🌟 Research Objective:
– To improve 3D super-resolution models by leveraging video super-resolution techniques to enhance spatial consistency and accuracy in reconstructed 3D models from low-resolution multi-view images.
🛠️ Research Methods:
– A comprehensive study was conducted utilizing video super-resolution models to align low-resolution images effectively, without the need for fine-tuning, ensuring consistent spatial information.
💬 Research Conclusions:
– The study demonstrates that video super-resolution models effectively handle sequences lacking precise spatial alignment, achieving state-of-the-art results in 3D super-resolution on datasets such as NeRF-synthetic and MipNeRF-360.
👉 Paper link: https://huggingface.co/papers/2412.11525

8. MixLLM: LLM Quantization with Global Mixed-precision between Output-features and Highly-efficient System Design
🔑 Keywords: Quantization, Mixed-Precision, System Efficiency, LLMs, Output Features
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To analyze and optimize quantization principles to improve the accuracy, memory consumption, and efficiency of quantized LLMs.
🛠️ Research Methods:
– Developed MixLLM, employing mixed-precision quantization that focuses on globally significant output features.
– Utilized two-step dequantization and a software pipeline for minimizing dequantization overhead and enhancing system performance.
💬 Research Conclusions:
– MixLLM achieves reduced PPL increasement and enhances accuracy with less memory usage and improved system efficiency over state-of-the-art methods.
👉 Paper link: https://huggingface.co/papers/2412.14590

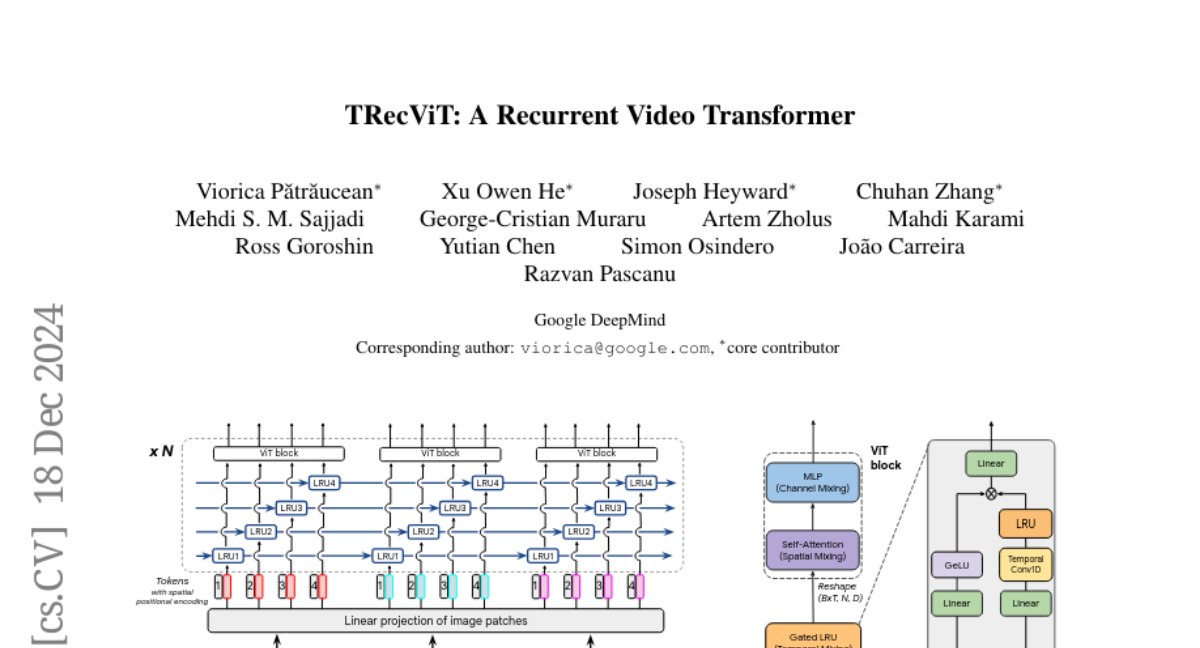
9. TRecViT: A Recurrent Video Transformer
🔑 Keywords: Gated Linear Recurrent Units, Self-Attention, Video Modelling, TRecViT
💡 Category: Computer Vision
🌟 Research Objective:
– The development of a novel block specifically designed for video modelling through a unique time-space-channel factorisation approach.
🛠️ Research Methods:
– Utilization of gated linear recurrent units for temporal information mixing, self-attention for spatial mixing, and MLPs for channel mixing, integrated into the architecture known as TRecViT.
💬 Research Conclusions:
– TRecViT demonstrates superior or equivalent performance compared to a pure attention model (ViViT-L) on large-scale video datasets, with significantly fewer parameters, smaller memory footprint, and lower FLOPs count.
👉 Paper link: https://huggingface.co/papers/2412.14294
10. Fietje: An open, efficient LLM for Dutch
🔑 Keywords: Small Language Models, Dutch language, Transparency, Reproducibility, Evaluation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce Fietje, a family of small language models specifically designed for processing the Dutch language.
🛠️ Research Methods:
– Utilization of Phi 2, an English-centric model with 2.7 billion parameters, to develop Fietje, ensuring the model is fully open-source with publicly accessible resources for transparency and reproducibility.
💬 Research Conclusions:
– Fietje, despite being a smaller language model, demonstrates competitive performance against larger models, showcasing the potential and rapid progress for compact language models in Dutch language processing.
👉 Paper link: https://huggingface.co/papers/2412.15450

11. LLMs Lost in Translation: M-ALERT uncovers Cross-Linguistic Safety Gaps
🔑 Keywords: Large Language Models, M-ALERT, multilingual benchmark, safety analysis, linguistic diversity
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– The research introduces M-ALERT, a multilingual benchmark designed to evaluate the safety of Large Language Models (LLMs) across five languages, aiming to ensure safe access and promote linguistic diversity.
🛠️ Research Methods:
– The study employs 15k high-quality prompts per language across five languages, totaling 75k prompts, following the ALERT taxonomy, to assess the safety of 10 state-of-the-art LLMs.
💬 Research Conclusions:
– Experiments reveal significant inconsistencies in safety across languages and categories; for example, the Llama3.2 model shows a high level of unsafety in the crime_tax category in Italian, while remaining safer in other languages. The need for robust multilingual safety practices in LLMs is emphasized to promote safe usage across diverse communities.
👉 Paper link: https://huggingface.co/papers/2412.15035

12. IDOL: Instant Photorealistic 3D Human Creation from a Single Image
🔑 Keywords: High-fidelity, 3D full-body avatar, Transformer model, Photorealistic, Single image
💡 Category: Computer Vision
🌟 Research Objective:
– To create a high-fidelity, animatable 3D full-body avatar from a single image leveraging a new dataset and model architecture.
🛠️ Research Methods:
– Development of HuGe100K, a large-scale dataset of diverse human images.
– Use of a feed-forward transformer model to predict a 3D human Gaussian representation for pose and body shape disentanglement.
💬 Research Conclusions:
– The model efficiently reconstructs photorealistic humans at 1K resolution from a single input image using a single GPU and supports shape and texture editing without post-processing.
👉 Paper link: https://huggingface.co/papers/2412.14963

13. Multi-LLM Text Summarization
🔑 Keywords: Multi-LLM, Summarization, Decentralized, Centralized
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper proposes a Multi-LLM summarization framework.
🛠️ Research Methods:
– It investigates centralized and decentralized multi-LLM strategies for text summarization, with crucial steps of generation and evaluation.
💬 Research Conclusions:
– The Multi-LLM approaches significantly outperform single LLM baselines by up to 3x, demonstrating their effectiveness in summarization tasks.
👉 Paper link: https://huggingface.co/papers/2412.15487
