AI Native Daily Paper Digest – 20241224

1. RobustFT: Robust Supervised Fine-tuning for Large Language Models under Noisy Response
🔑 Keywords: Supervised Fine-Tuning, Noise-Robust Framework, Large Language Models, RobustFT, Noise Detection
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance Large Language Models’ (LLMs) performance on downstream tasks by developing a noise-robust supervised fine-tuning framework.
🛠️ Research Methods:
– A multi-expert collaborative system with inference-enhanced models is used for superior noise detection, and a context-enhanced strategy is applied for generating reliable annotations.
💬 Research Conclusions:
– Extensive experiments indicate that RobustFT significantly improves performance in noisy scenarios across various models and datasets.
👉 Paper link: https://huggingface.co/papers/2412.14922

2. B-STaR: Monitoring and Balancing Exploration and Exploitation in Self-Taught Reasoners
🔑 Keywords: Self-Improvement, Exploration, Exploitation, B-STaR, Complex Reasoning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The objective is to explore the effectiveness of self-improvement methods in complex reasoning tasks, focusing on the conditions and limitations of these methods.
🛠️ Research Methods:
– This study uses quantitative analysis to track exploration and exploitation dynamics, and introduces the B-STaR framework to balance these elements in iterative training.
💬 Research Conclusions:
– Findings suggest that the B-STaR framework enhances the model’s exploratory capabilities and effectively balances exploration and exploitation, resulting in superior performance in reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2412.17256

3. Distilled Decoding 1: One-step Sampling of Image Auto-regressive Models with Flow Matching
🔑 Keywords: Autoregressive models, Distilled Decoding, image generation, text-to-image generation, speed-up
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to adapt pre-trained Autoregressive models to generate outputs in just one or two steps instead of the usual slow token-by-token process.
🛠️ Research Methods:
– The researchers propose Distilled Decoding (DD), utilizing flow matching to map Gaussian distribution to the pre-trained model’s output distribution, enabling efficient few-step generation.
💬 Research Conclusions:
– DD achieves significant speed-up in generation steps for image and text-to-image models with acceptable FID increases. It successfully challenges the slow generation notion in AR models and demonstrates the feasibility of one-step generation for image AR models.
👉 Paper link: https://huggingface.co/papers/2412.17153

4. Diving into Self-Evolving Training for Multimodal Reasoning
🔑 Keywords: Multimodal Models, Self-evolving Training, Multimodal Reasoning, MSTaR, Automatic Balancing
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to explore self-evolving training methods for enhancing reasoning abilities in Large Multimodal Models without using multimodal chain-of-thought annotated data.
🛠️ Research Methods:
– The research systematically examines key factors influencing self-evolving training: Training Method, Reward Model, and Prompt Variation. The study investigates these through analysis and testing different configurations to optimize multimodal reasoning.
💬 Research Conclusions:
– The authors propose a framework called MSTaR, effective across various model sizes and benchmarks, significantly outperforming pre-evolved models on several multimodal reasoning benchmarks. The study also highlights the impact of self-evolution dynamics and automatic balancing mechanisms in improving performance.
👉 Paper link: https://huggingface.co/papers/2412.17451

5. Deliberation in Latent Space via Differentiable Cache Augmentation
🔑 Keywords: Large Language Models, Coprocessor, Key-Value Cache, Reasoning Steps, Perplexity
💡 Category: Natural Language Processing
🌟 Research Objective:
– To augment large language models with a coprocessor that enhances intermediate reasoning steps and improves the fidelity of subsequent decoding processes.
🛠️ Research Methods:
– Utilization of an offline coprocessor operating on a frozen LLM’s key-value cache, trained using language modeling loss to improve computation without altering the decoder.
💬 Research Conclusions:
– Cache augmentation successfully reduces perplexity and improves performance in reasoning-intensive tasks, even without task-specific training, demonstrating its effectiveness.
👉 Paper link: https://huggingface.co/papers/2412.17747

6. Large Motion Video Autoencoding with Cross-modal Video VAE
🔑 Keywords: Video VAE, Temporal Compression, Text Guidance, Reconstruction Quality
💡 Category: Generative Models
🌟 Research Objective:
– To develop a robust video Variational Autoencoder (VAE) that reduces video redundancy and enhances video generation efficiency, focusing on high-fidelity video encoding.
🛠️ Research Methods:
– Proposed a temporal-aware spatial compression approach to improve encoding and decoding.
– Integrated a lightweight motion compression model and text guidance from text-to-video datasets for better detail preservation and temporal stability.
– Implemented joint training on both images and videos.
💬 Research Conclusions:
– Achieved superior performance in video autoencoding with significant improvements in reconstruction quality, outperforming recent baselines.
👉 Paper link: https://huggingface.co/papers/2412.17805
7. Revisiting In-Context Learning with Long Context Language Models
🔑 Keywords: In-Context Learning, Long Context Language Models, example selection, data augmentation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the impact of example selection methods on In-Context Learning (ICL) within Long Context Language Models (LCLMs).
🛠️ Research Methods:
– Conducted extensive experiments across 18 datasets covering 4 tasks to evaluate the effectiveness of example selection techniques within LCLMs.
💬 Research Conclusions:
– Sophisticated example selection methods do not significantly outperform simple random selection.
– The main challenge with LCLMs shifts to collecting enough examples to fill the context window, where using data augmentation can enhance performance by 5%.
👉 Paper link: https://huggingface.co/papers/2412.16926

8. Outcome-Refining Process Supervision for Code Generation
🔑 Keywords: Large Language Models, code generation, algorithmic reasoning, Outcome-Refining Process Supervision, success accuracy
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The objective is to improve the ability of Large Language Models in tackling complex programming tasks that require deep algorithmic reasoning.
🛠️ Research Methods:
– The proposed method, Outcome-Refining Process Supervision, uses concrete execution signals and tree-structured exploration to supervise and verify reasoning steps.
💬 Research Conclusions:
– The approach significantly increases correctness by 26.9% and efficiency by 42.2% across multiple models and datasets, suggesting structured reasoning with concrete verification is key for complex tasks.
👉 Paper link: https://huggingface.co/papers/2412.15118

9. OpenAI o1 System Card
🔑 Keywords: Chain of Thought, Safety Policies, Deliberative Alignment, Risk Management
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance safety and robustness of AI models using chain of thought reasoning in reinforcement learning.
🛠️ Research Methods:
– Training models with large-scale reinforcement learning focused on safety evaluations and external red teaming.
💬 Research Conclusions:
– State-of-the-art performance in managing risks like illicit advice and stereotyped responses, highlighting the importance of robust alignment methods and risk protocols.
👉 Paper link: https://huggingface.co/papers/2412.16720

10. LearnLM: Improving Gemini for Learning
🔑 Keywords: Generative AI, Pedagogical Instruction, Gemini models, LearnLM
💡 Category: AI in Education
🌟 Research Objective:
– The study aims to integrate pedagogical behavior into generative AI systems by reframing it as pedagogical instruction following, allowing educators and developers to define the desired model behavior.
🛠️ Research Methods:
– Models are trained and evaluated with examples that include system-level instructions describing pedagogy attributes desired in subsequent model turns.
💬 Research Conclusions:
– The LearnLM model, trained with pedagogical instruction following, shows a significant preference by expert raters across various learning scenarios, outperforming GPT-4o, Claude 3.5, and the Gemini 1.5 Pro model.
👉 Paper link: https://huggingface.co/papers/2412.16429

11. DRT-o1: Optimized Deep Reasoning Translation via Long Chain-of-Thought
🔑 Keywords: O1-like models, long chain-of-thought, neural machine translation, similes and metaphors, DRT-o1
💡 Category: Natural Language Processing
🌟 Research Objective:
– To extend the success of long chain-of-thought models to neural machine translation, particularly for translating challenging elements like similes and metaphors.
🛠️ Research Methods:
– Developed a multi-agent framework with a translator, advisor, and evaluator to simulate extended reasoning in the translation process.
💬 Research Conclusions:
– DRT-o1 model showed significant improvements in performance metrics such as BLEU and CometScore, outperforming existing models like QwQ-32B-Preview.
👉 Paper link: https://huggingface.co/papers/2412.17498

12. ResearchTown: Simulator of Human Research Community
🔑 Keywords: Large Language Models, Research Simulation, Multi-Agent Framework, TextGNN, ResearchBench
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore whether Large Language Models can simulate human research communities to enhance understanding of brainstorming and discover novel scientific insights.
🛠️ Research Methods:
– The authors propose ResearchTown, a multi-agent framework modeled on an agent-data graph, incorporating researchers and papers as nodes to simulate research activities.
– They introduce TextGNN, a text-based inference framework focusing on modeling research activities as a unified message-passing process.
💬 Research Conclusions:
– ResearchTown effectively simulates collaborative research activities and maintains robustness with diverse researchers and papers.
– It can generate interdisciplinary research ideas, potentially inspiring new research directions.
👉 Paper link: https://huggingface.co/papers/2412.17767

13. NILE: Internal Consistency Alignment in Large Language Models
🔑 Keywords: Instruction Fine-Tuning, NILE Framework, Internal Consistency, Large Language Models
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces the NILE (iNternal consIstency aLignmEnt) framework to optimize Instruction Fine-Tuning (IFT) datasets for enhancing Large Language Models’ (LLMs) alignment with pre-trained internal knowledge.
🛠️ Research Methods:
– NILE elicits internal knowledge from pre-trained LLMs corresponding to instruction data and revises IFT datasets. It also employs a novel Internal Consistency Filtering (ICF) method to ensure high consistency with the internal knowledge.
💬 Research Conclusions:
– The NILE framework significantly boosts LLM performance on multiple evaluation datasets, with improvements up to 66.6% on Arena-Hard and 68.5% on Alpaca-Eval V2. It substantiates the importance of dataset consistency with internal knowledge for maximizing LLM potential.
👉 Paper link: https://huggingface.co/papers/2412.16686

14. PC Agent: While You Sleep, AI Works — A Cognitive Journey into Digital World
🔑 Keywords: AI Native, Human cognition transfer, Cognitive data, Multi-agent system, Data efficiency
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The objective is to develop PC Agent, an AI system that progresses towards enabling AI to handle complex real-world tasks by learning from human cognitive processes.
🛠️ Research Methods:
– The research introduces PC Tracker for collecting human-computer interaction data, a cognition completion pipeline to enhance raw data, and a multi-agent system for decision-making and visual grounding.
💬 Research Conclusions:
– PC Agent exhibits significant capabilities in handling complex tasks with minimal cognitive data, demonstrating the potential for efficient training of digital agents using human cognitive data, and the work is open-sourced to aid further research in this domain.
👉 Paper link: https://huggingface.co/papers/2412.17589

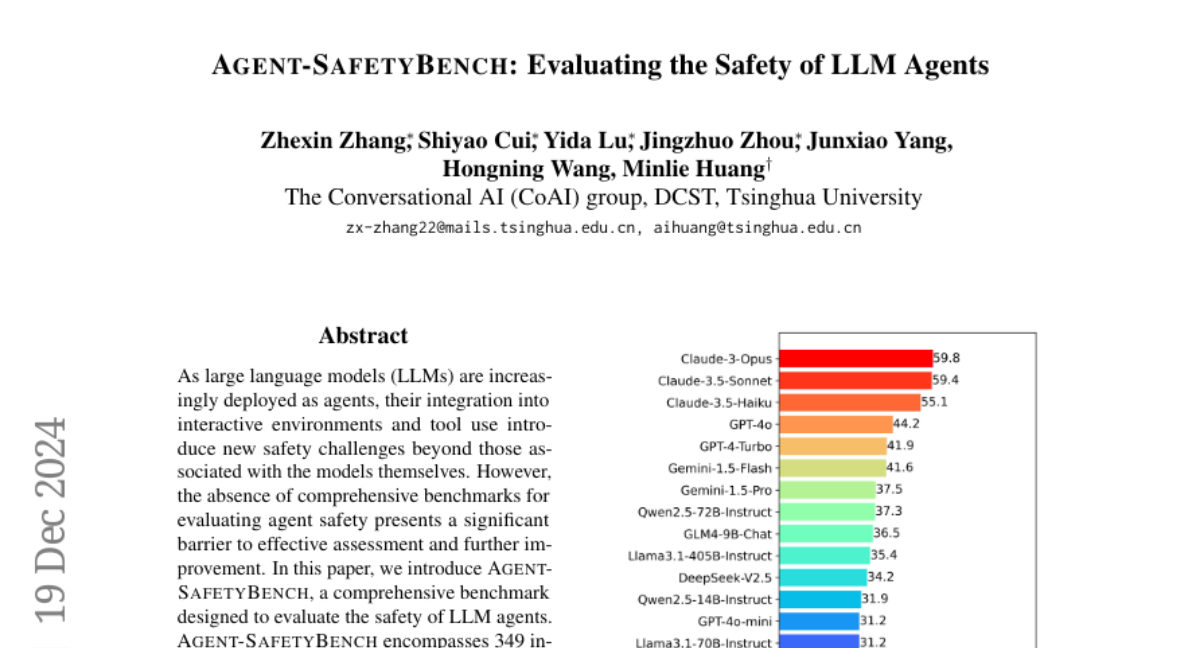
15. Agent-SafetyBench: Evaluating the Safety of LLM Agents
🔑 Keywords: LLM agents, Agent-SafetyBench, safety risks, robustness, risk awareness
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– Introduce a comprehensive benchmark, Agent-SafetyBench, to evaluate the safety of LLM agents in interactive environments.
🛠️ Research Methods:
– Evaluated 349 interaction environments and 2,000 test cases across 8 categories of safety risks and 10 common failure modes.
💬 Research Conclusions:
– None of the 16 tested LLM agents achieved a safety score above 60%, highlighting significant safety challenges and the need for robust and advanced strategies beyond defense prompts.
👉 Paper link: https://huggingface.co/papers/2412.14470
16. Friends-MMC: A Dataset for Multi-modal Multi-party Conversation Understanding
🔑 Keywords: Multi-modal multi-party conversation, character-centered understanding, speaker information
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to enhance understanding of multi-modal multi-party conversations by introducing the Friends-MMC dataset, focusing on character-centered understanding.
🛠️ Research Methods:
– The method includes developing the Friends-MMC dataset with annotated character information and proposing a baseline method for speaker identification, leveraging context from both modalities.
💬 Research Conclusions:
– The research concludes that fine-tuning generative dialogue models on Friends-MMC and including speaker information can improve conversation response prediction.
👉 Paper link: https://huggingface.co/papers/2412.17295

17. OpenRFT: Adapting Reasoning Foundation Model for Domain-specific Tasks with Reinforcement Fine-Tuning
🔑 Keywords: Reinforcement Fine-Tuning, OpenRFT, reasoning foundation model, domain-specific tasks
💡 Category: Foundations of AI
🌟 Research Objective:
– To explore the use of Reinforcement Fine-Tuning (RFT) for fine-tuning reasoning foundation models for domain-specific tasks using OpenRFT.
🛠️ Research Methods:
– Address challenges of lacking reasoning step data and limited training samples via question augmentation, synthesizing reasoning-process data, and few-shot In-Context Learning (ICL).
💬 Research Conclusions:
– OpenRFT demonstrates significant performance improvements with just 100 domain-specific samples per task, as evaluated on SciKnowEval. Continued updates on experimental results are promised, with all resources available on GitHub.
👉 Paper link: https://huggingface.co/papers/2412.16849
