AI Native Flow Case Study #6 – n8n – AI agent that can scrape webpages
🌟 Scenario
Looking for a solution to fetch and process webpage content effortlessly? Efficient HTTP requests, seamless content extraction, and Markdown conversion—this workflow on n8n [https://n8n.io/workflows/2006-ai-agent-that-can-scrape-webpages/] has it all. I found it both flexible and highly effective!
🔍 Workflow Breakdown
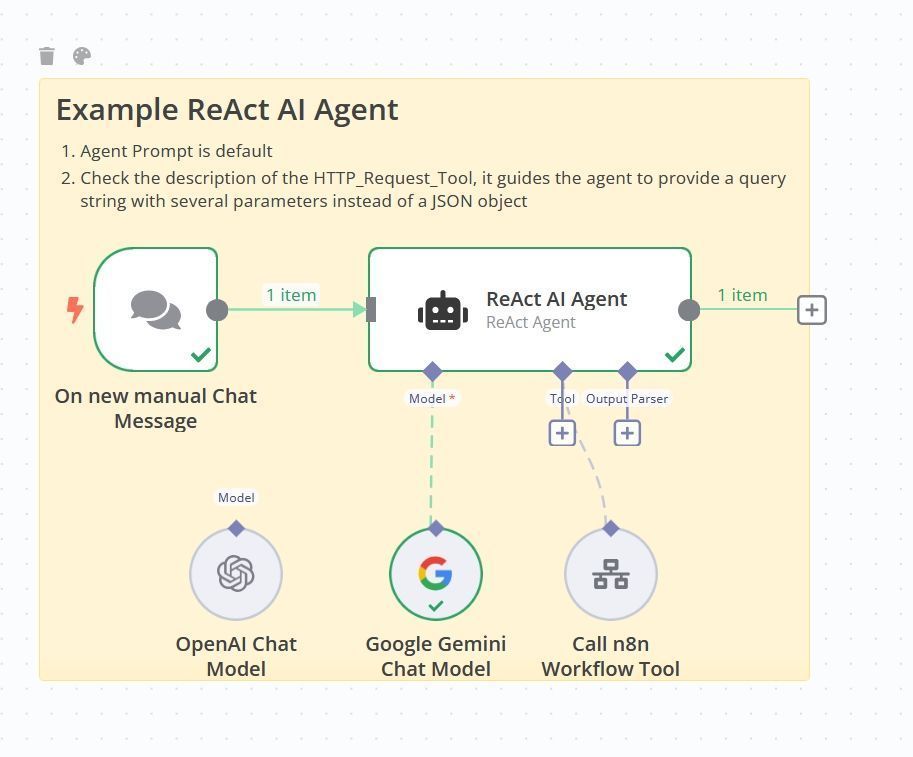
1️⃣ Trigger : The process begins with a manual or event-driven trigger.
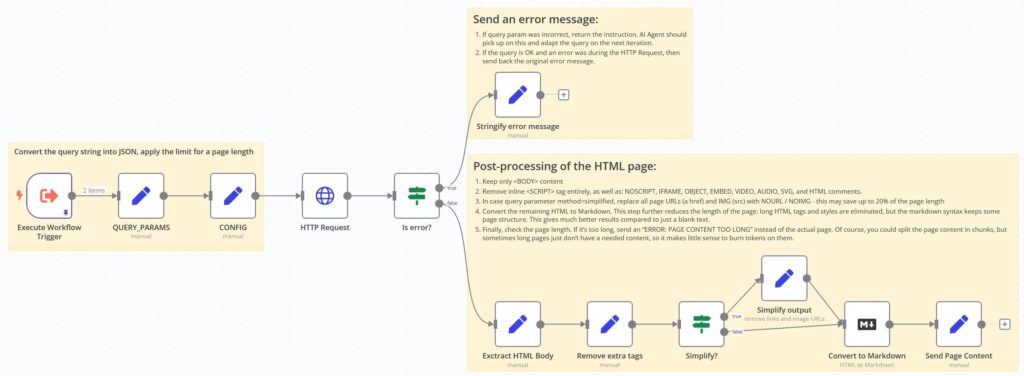
2️⃣ HTTP Request : Fetches the webpage content based on the provided URL and parameters.
3️⃣ Content Processing : Extracts the <body> content, cleans it, and converts it to Markdown.
4️⃣ Validation : Ensures the processed content meets the maximum length constraint.
5️⃣ Response Output : Returns the cleaned Markdown content or an error message if issues occur.
💡 Insights
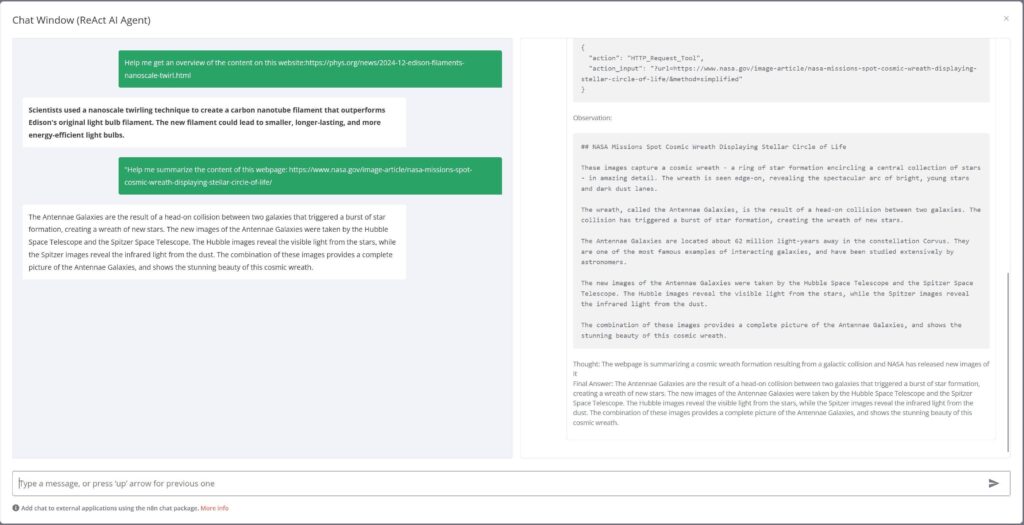
After testing this workflow, I found it to be highly effective and well-aligned with my requirements. The process successfully fetched and processed webpage content, delivering results that meet my expectations.
I made an enhancement by replacing the AI model to better suit my specific needs. However, I noticed that the workflow does not clearly illustrate how to transition to the HTTP_Request_Tool within the provided structure. Despite this minor limitation, the workflow has already fulfilled my requirements and demonstrated its flexibility and adaptability.
That’s all for the workflow insights. Join us at AI Native Foundation Membership Dashboard for the latest insights on AI Native, or follow our linkedin account at AI Native Foundation and our twitter account at AINativeF.