AI Native Daily Paper Digest – 20241231
1. Explanatory Instructions: Towards Unified Vision Tasks Understanding and Zero-shot Generalization
🔑 Keywords: Computer Vision, zero-shot task generalization, Explanatory Instructions, vision-language model
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to address the challenge in Computer Vision of achieving zero-shot task generalization through the introduction of Explanatory Instructions, bridging the gap with Natural Language Processing.
🛠️ Research Methods:
– The researchers developed a large-scale dataset of 12 million image-input/explanatory-instruction/output triplets and trained an auto-regressive-based vision-language model to understand and follow given instructions.
💬 Research Conclusions:
– The model demonstrated strong zero-shot generalization capabilities for unseen tasks in Computer Vision, highlighting the potential of instruction-based guidance for future advancements.
👉 Paper link: https://huggingface.co/papers/2412.18525

2. On the Compositional Generalization of Multimodal LLMs for Medical Imaging
🔑 Keywords: Multimodal large language models, Medical field, Compositional generalization, Multi-task training, Medical datasets
💡 Category: AI in Healthcare
🌟 Research Objective:
– To understand how Multimodal large language models can generalize and select appropriate medical images for enhanced medical applications.
🛠️ Research Methods:
– The study employed compositional generalization as a guiding framework and created a dataset called Med-MAT from 106 medical datasets for comprehensive experimentation.
💬 Research Conclusions:
– The experiments demonstrated that Multimodal large language models could leverage compositional generalization to understand novel medical images, showing consistent performance and versatility across datasets with limited data and different backbones.
👉 Paper link: https://huggingface.co/papers/2412.20070

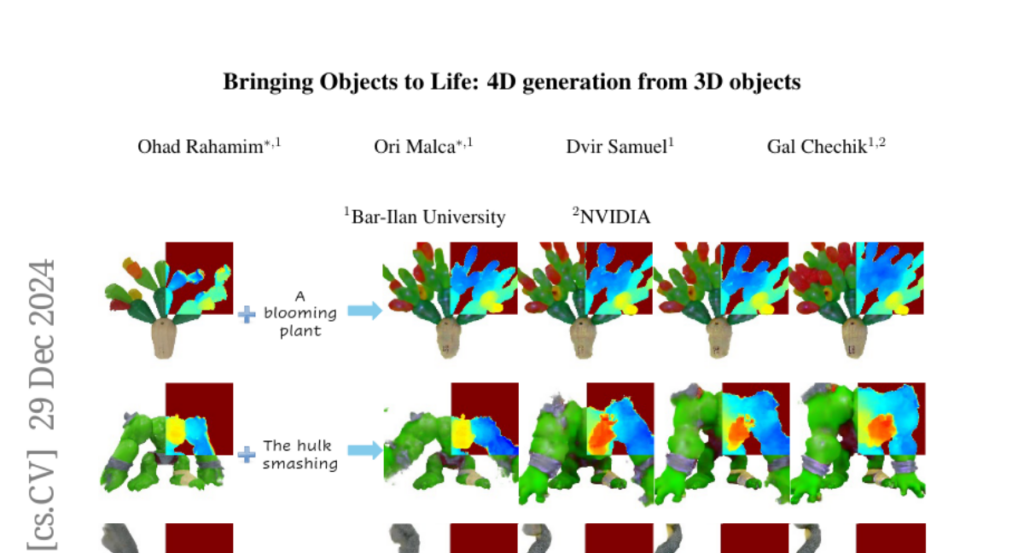
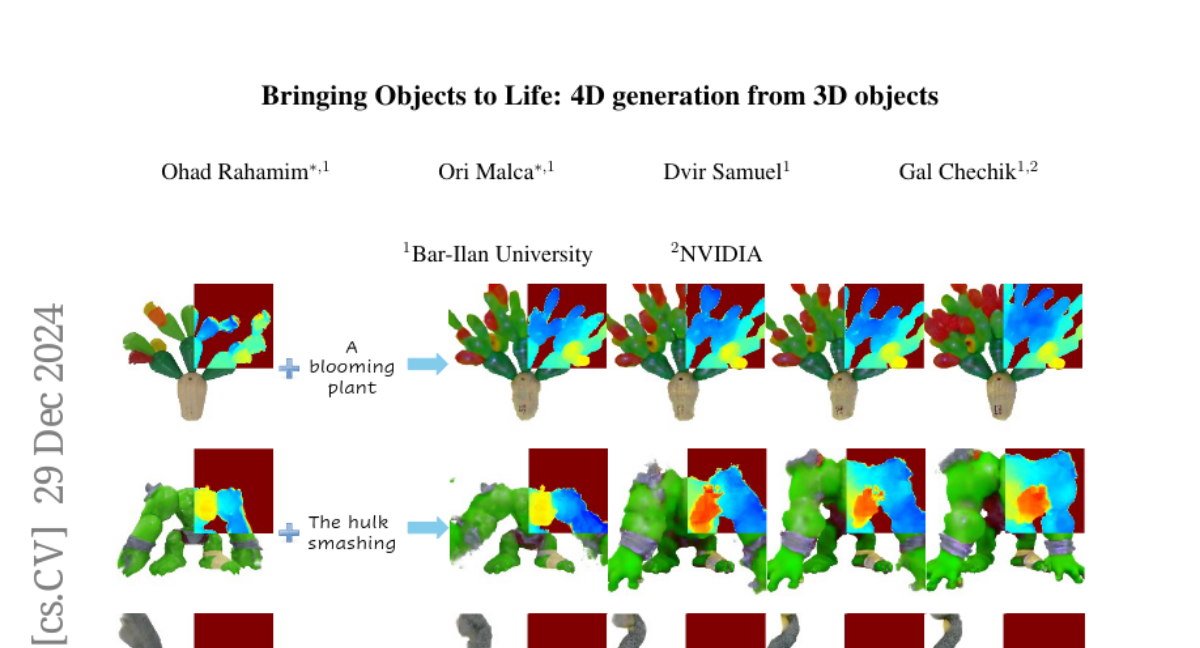
3. Bringing Objects to Life: 4D generation from 3D objects
🔑 Keywords: Generative Modeling, 4D Content, Text Prompts, Neural Radiance Field, Image-to-Video Diffusion
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance 4D content generation, allowing for the animation of user-provided 3D objects using text prompts to create custom animations while preserving the original object’s identity.
🛠️ Research Methods:
– The process involves converting a 3D mesh into a static 4D Neural Radiance Field and animating it through an Image-to-Video diffusion model driven by text, employing an incremental viewpoint selection protocol and a masked Score Distillation Sampling (SDS) loss to improve realism.
💬 Research Conclusions:
– The proposed method surpasses existing approaches in temporal coherence, prompt adherence, and visual fidelity, achieving significant improvements in identity preservation per LPIPS scores and effectively balancing visual quality with dynamic content.
👉 Paper link: https://huggingface.co/papers/2412.20422
4. Efficiently Serving LLM Reasoning Programs with Certaindex
🔑 Keywords: Large Language Models, Inference-Time Reasoning, Compute Optimization, Resource Efficiency, Dynasor
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To optimize inference-time compute for large language model reasoning queries, improving efficiency and meeting latency targets.
🛠️ Research Methods:
– Introduces Dynasor, a system that tracks and schedules requests, dynamically allocating compute resources based on model certainty using a proxy called Certaindex.
💬 Research Conclusions:
– Dynasor successfully reduces compute by up to 50% and sustains higher query rates or tighter latency service level objectives, enhancing resource efficiency.
👉 Paper link: https://huggingface.co/papers/2412.20993

5. Edicho: Consistent Image Editing in the Wild
🔑 Keywords: consistent editing, diffusion models, attention manipulation, plug-and-play
💡 Category: Generative Models
🌟 Research Objective:
– Address the technical challenge of maintaining consistent editing across in-the-wild images despite various uncontrollable factors.
🛠️ Research Methods:
– Develop Edicho, a training-free solution utilizing diffusion models with an attention manipulation module and a refined classifier-free guidance denoising strategy.
💬 Research Conclusions:
– Demonstrated that Edicho effectively enables consistent cross-image editing and is compatible with most diffusion-based editing methods.
👉 Paper link: https://huggingface.co/papers/2412.21079

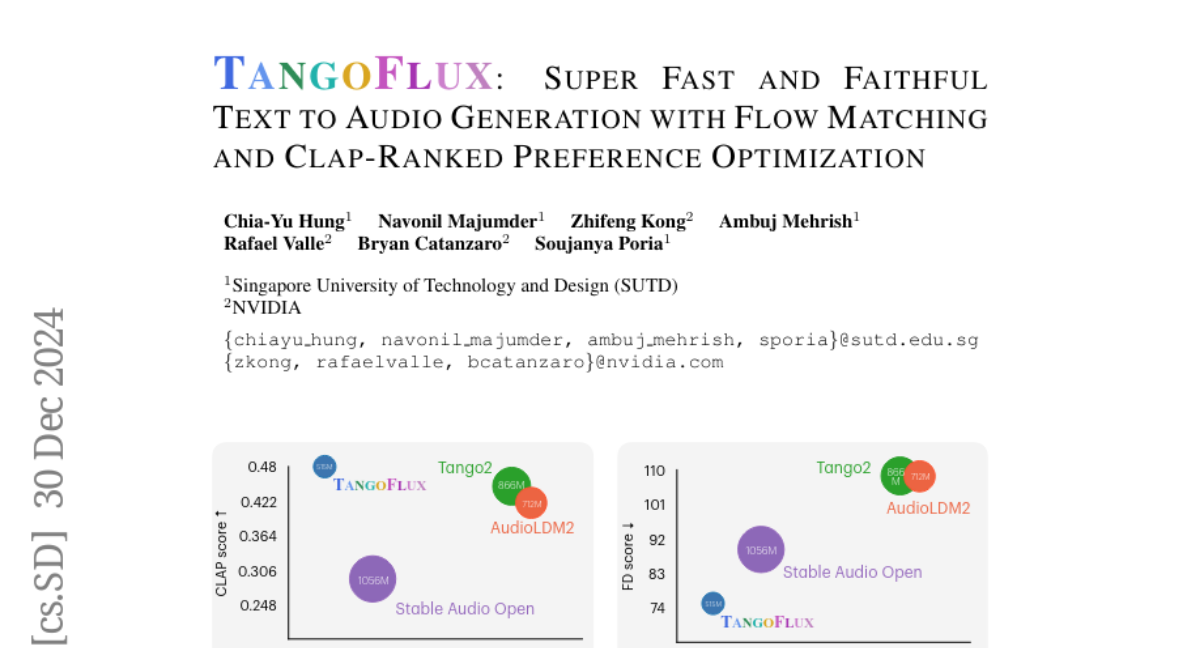
6. TangoFlux: Super Fast and Faithful Text to Audio Generation with Flow Matching and Clap-Ranked Preference Optimization
🔑 Keywords: TangoFlux, Text-to-Audio, CLAP-Ranked Preference Optimization, Generative Model
💡 Category: Generative Models
🌟 Research Objective:
– Present TangoFlux, an efficient Text-to-Audio generative model capable of generating high-quality audio efficiently.
🛠️ Research Methods:
– Introduce CLAP-Ranked Preference Optimization (CRPO) to generate and optimize preference data, improving TTA model alignment.
💬 Research Conclusions:
– Demonstration of the state-of-the-art performance of TangoFlux across benchmarks, with open-sourced models and code to facilitate further TTA research.
👉 Paper link: https://huggingface.co/papers/2412.21037
7. Facilitating large language model Russian adaptation with Learned Embedding Propagation
🔑 Keywords: Large Language Model, Instruction-Tuning, Multilingual, Learned Embedding Propagation, Cost-Efficient
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose a method to reduce the costs and limitations of language adaptation pipelines for large language models.
🛠️ Research Methods:
– Development and implementation of Learned Embedding Propagation (LEP), which incorporates a novel ad-hoc embedding propagation procedure to implant new language knowledge without traditional instruction-tuning.
💬 Research Conclusions:
– LEP is shown to be competitive with traditional instruction-tuning methods, achieving comparable performance while requiring less training data and offering further improvements through self-calibration and continued tuning.
👉 Paper link: https://huggingface.co/papers/2412.21140

8. OneKE: A Dockerized Schema-Guided LLM Agent-based Knowledge Extraction System
🔑 Keywords: OneKE, knowledge extraction, schema configuration, multi-domain, dockerized
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop OneKE, a flexible knowledge extraction system that operates across various domains by utilizing multiple agents and a configurable knowledge base.
🛠️ Research Methods:
– Implementation of OneKE as a dockerized system with specialized agents and a configurable knowledge base to support diverse extraction scenarios and improve performance through schema configuration and error correction.
💬 Research Conclusions:
– OneKE shows efficacy on benchmark datasets and adaptability across tasks, suggesting its potential for wide applications. Code and demonstration resources have been made publicly available.
👉 Paper link: https://huggingface.co/papers/2412.20005

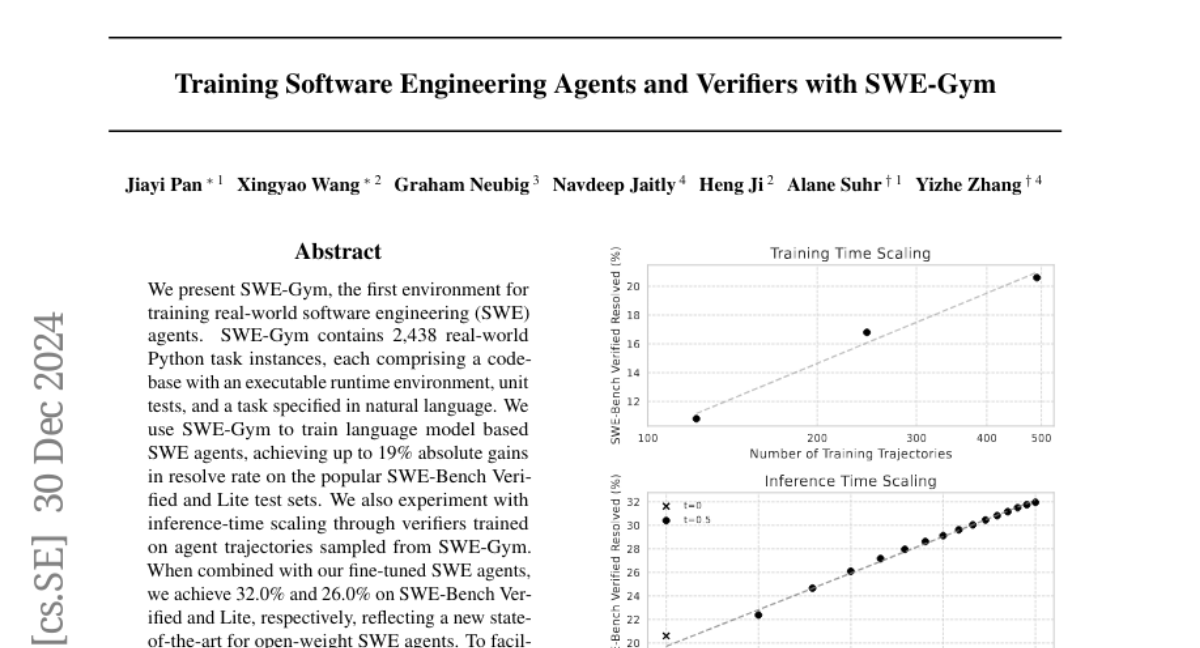
9. Training Software Engineering Agents and Verifiers with SWE-Gym
🔑 Keywords: SWE-Gym, software engineering agents, language model, open-weight SWE agents
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce SWE-Gym, an environment for training real-world software engineering agents.
🛠️ Research Methods:
– Utilized 2,438 Python task instances in SWE-Gym to train language model-based agents and experimented with inference-time scaling using verifiers trained on agent trajectories from SWE-Gym.
💬 Research Conclusions:
– Achieved up to 19% gains in resolve rate on SWE-Bench test sets and established a new state-of-the-art with 32.0% and 26.0% on SWE-Bench Verified and Lite test sets for open-weight SWE agents.
👉 Paper link: https://huggingface.co/papers/2412.21139
10. HumanEval Pro and MBPP Pro: Evaluating Large Language Models on Self-invoking Code Generation
🔑 Keywords: self-invoking code generation, LLMs, benchmarks, code reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the progressive reasoning and problem-solving capabilities of LLMs through a new task called self-invoking code generation.
🛠️ Research Methods:
– Creation of upgraded benchmarks: HumanEval Pro, MBPP Pro, and BigCodeBench-Lite Pro to test LLMs’ self-invoking code generation.
💬 Research Conclusions:
– Traditional benchmarks see high success rates, but performance drops in self-invoking tasks.
– Instruction-tuned models show marginal improvements over base models in self-invoking tasks.
– Identified failure modes and emphasized the need for further advancements to enhance code reasoning capabilities in LLMs.
👉 Paper link: https://huggingface.co/papers/2412.21199

11. Slow Perception: Let’s Perceive Geometric Figures Step-by-step
🔑 Keywords: Visual o1, Slow Perception, Large Vision Language Models
💡 Category: Computer Vision
🌟 Research Objective:
– To address the limitations of current LVLMs in understanding geometric shapes through a new “slow perception” concept.
🛠️ Research Methods:
– Introducing “slow perception” with two stages: perception decomposition, breaking down complex figures into basic units, and perception flow, tracing line segments using a “perceptual ruler.”
💬 Research Conclusions:
– Slowing down the model’s perception can improve its understanding and accuracy in visual reasoning tasks, adopting a step-by-step, human-like approach.
👉 Paper link: https://huggingface.co/papers/2412.20631

12. PERSE: Personalized 3D Generative Avatars from A Single Portrait
🔑 Keywords: Personalized Avatar, Facial Attribute Editing, Latent Space, Photorealistic 2D Videos
💡 Category: Generative Models
🌟 Research Objective:
– To build an animatable personalized generative avatar from a reference portrait with distinct facial attribute control while preserving individual identity.
🛠️ Research Methods:
– Creation of large-scale synthetic 2D video datasets to demonstrate consistent facial expression and viewpoint changes.
– Development of a novel pipeline using 3D Gaussian Splatting for learning a continuous and disentangled latent space.
– Introduction of a latent space regularization technique leveraging interpolated 2D faces.
💬 Research Conclusions:
– PERSE outperforms previous methods by generating high-quality avatars with interpolated attributes and maintaining the identity of the reference person.
👉 Paper link: https://huggingface.co/papers/2412.21206
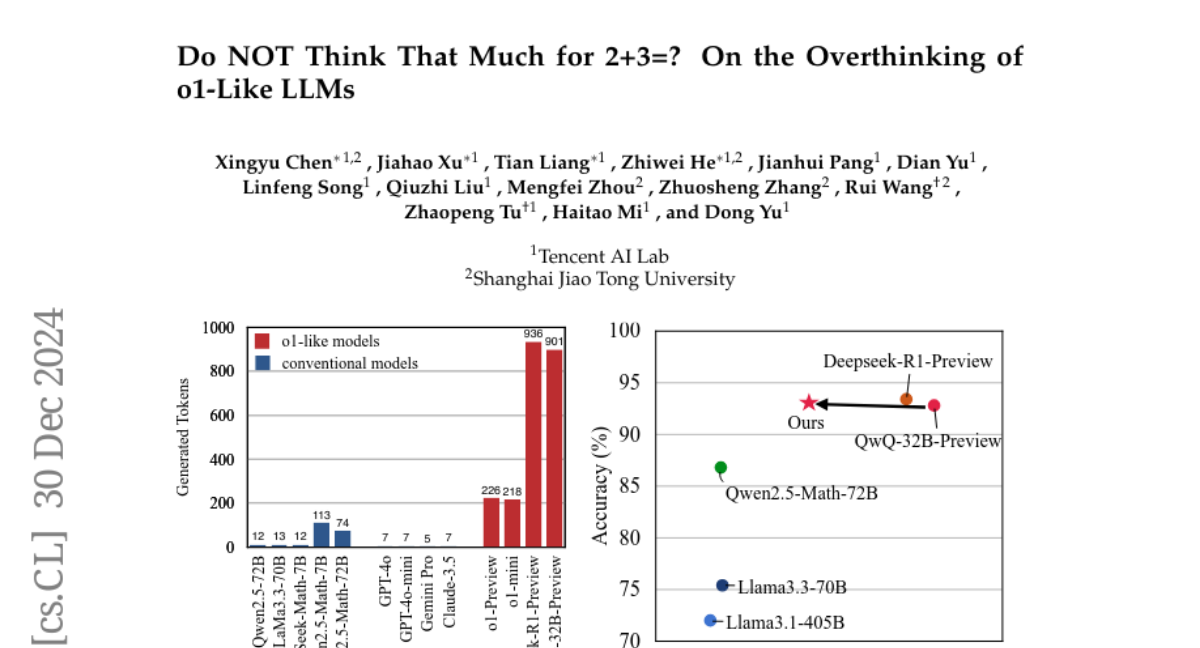
13. Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
🔑 Keywords: overthinking, computational resources, self-training paradigm, reasoning processes, AI Systems
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Investigate how to scale computational resources intelligently during model testing and address the issue of overthinking in AI models like OpenAI o1.
🛠️ Research Methods:
– Introduced efficiency metrics to evaluate the rational use of computational resources and proposed strategies using a self-training paradigm to mitigate overthinking.
💬 Research Conclusions:
– Successfully reduced computational overhead and preserved model performance across various test sets by streamlining reasoning processes.
👉 Paper link: https://huggingface.co/papers/2412.21187