AI Native Daily Paper Digest – 20250113
1. VideoRAG: Retrieval-Augmented Generation over Video Corpus
🔑 Keywords: Retrieval-Augmented Generation, Multi-Modal Learning, VideoRAG, Large Video Language Models, Video Integration
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce VideoRAG, a framework to enhance factual accuracy in response generation by integrating multimodal video content.
🛠️ Research Methods:
– Utilizes Large Video Language Models (LVLMs) to dynamically retrieve and process both visual and textual information from videos in response generation.
💬 Research Conclusions:
– Demonstrated effectiveness of VideoRAG, outperforming existing baselines in generating factually accurate outputs using multimodal video information.
👉 Paper link: https://huggingface.co/papers/2501.05874

2. OmniManip: Towards General Robotic Manipulation via Object-Centric Interaction Primitives as Spatial Constraints
🔑 Keywords: Robotics, Vision-Language Models, Manipulation, Zero-shot Generalization, Object-Centric Representation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Develop a robotic system capable of effective manipulation in unstructured environments using a novel object-centric representation.
🛠️ Research Methods:
– Introduce a dual closed-loop, open-vocabulary robotic manipulation system with high-level planning and low-level execution to translate Vision-Language Model capabilities into actionable 3D spatial constraints without fine-tuning.
💬 Research Conclusions:
– Demonstrated strong zero-shot generalization across diverse robotic tasks, showcasing the system’s potential in automating large-scale simulation data generation.
👉 Paper link: https://huggingface.co/papers/2501.03841
3. LlamaV-o1: Rethinking Step-by-step Visual Reasoning in LLMs
🔑 Keywords: Visual Reasoning, LlamaV-o1, Multi-Step Reasoning, Benchmark, Curriculum Learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To advance step-by-step visual reasoning in large language models through a comprehensive framework, including a benchmark and new metrics.
🛠️ Research Methods:
– Introduction of a visual reasoning benchmark with diverse challenges, novel metric for assessing reasoning quality, and the development of a multimodal visual reasoning model named LlamaV-o1.
💬 Research Conclusions:
– LlamaV-o1 surpasses existing open-source models and performs well against proprietary models, achieving significant performance improvements with faster inference scaling.
👉 Paper link: https://huggingface.co/papers/2501.06186

4. OVO-Bench: How Far is Your Video-LLMs from Real-World Online Video Understanding?
🔑 Keywords: Temporal Awareness, Video LLMs, OVO-Bench, Online Video Understanding
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce and implement OVO-Bench, a novel benchmark for assessing online video understanding in video LLMs with an emphasis on temporal awareness.
🛠️ Research Methods:
– Developed an evaluation pipeline with tasks and fine-grained meta-annotations to test video LLMs across specific scenarios: backward tracing, real-time understanding, and forward active responding.
💬 Research Conclusions:
– Evaluations of existing video LLMs show significant challenges in online video understanding compared to human capabilities, revealing gaps and opportunities for improvement.
👉 Paper link: https://huggingface.co/papers/2501.05510

5. Enabling Scalable Oversight via Self-Evolving Critic
🔑 Keywords: Large Language Models, Scalable Oversight, Self-evolution, Critique Capabilities
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address the challenge of enhancing critique abilities in LLMs without human or external model supervision.
🛠️ Research Methods:
– Introduce the SCRIT framework, utilizing self-generated synthetic data and a contrastive-based self-critic mechanism for step-by-step critique.
💬 Research Conclusions:
– SCRIT framework significantly improves critique-correction and error identification, with performance enhancements up to 10.3%, especially benefiting from its self-validation component.
👉 Paper link: https://huggingface.co/papers/2501.05727

6. ReFocus: Visual Editing as a Chain of Thought for Structured Image Understanding
🔑 Keywords: Multimodal LLMs, Visual Thoughts, Structured Image Understanding, Visual Editing
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces ReFocus, a framework designed to enhance multimodal large language models (LLMs) by equipping them with the ability to perform multihop selective attention in structured image understanding tasks.
🛠️ Research Methods:
– ReFocus allows LLMs to generate Python code to modify input images, enabling visual editing through operations like sequential box drawing, section highlighting, and area masking to improve the visual reasoning process.
💬 Research Conclusions:
– ReFocus demonstrated substantial performance improvement with a 11.0% average gain on table tasks and 6.8% on chart tasks compared to models without visual editing. Additionally, the research showcased that visual chain-of-thought offers better supervision compared to traditional VQA data.
👉 Paper link: https://huggingface.co/papers/2501.05452

7. Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains
🔑 Keywords: Large language models, Synthetic data, Multiagent society, Self-improvement, Fine-tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore a complementary approach for the autonomous self-improvement of large language models through a multiagent society, enhancing beyond traditional training data limitations.
🛠️ Research Methods:
– Implement independent specialization of language models via multiagent interactions, generating diverse reasoning chains by training each model on unique datasets created through these interactions.
💬 Research Conclusions:
– Demonstrated efficacy in preserving diverse reasoning and successfully achieving more rounds of autonomous self-improvement compared to single-agent methods.
👉 Paper link: https://huggingface.co/papers/2501.05707

8. Infecting Generative AI With Viruses
🔑 Keywords: Large Language Model, Security Testing, EICAR, Generative AI
💡 Category: Generative Models
🌟 Research Objective:
– To explore and test the security boundaries of Vision-Large Language Models (VLM/ LLM) using the EICAR test file within JPEG images.
🛠️ Research Methods:
– Employed four protocols on various LLM platforms, embedding the EICAR test file in JPEGs, and using obfuscation techniques like base64 encoding and string reversal.
💬 Research Conclusions:
– Demonstrated the capability to mask EICAR strings, extract test files in LLM environments, and extended penetration testing principles to generative AI security evaluation in containerized setups.
👉 Paper link: https://huggingface.co/papers/2501.05542

9. Migician: Revealing the Magic of Free-Form Multi-Image Grounding in Multimodal Large Language Models
🔑 Keywords: Multimodal Large Language Models, multi-image grounding, Chain-of-Thought, MIG-Bench, open-sourced
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance precise grounding in complex multi-image scenarios using Multimodal Large Language Models.
🛠️ Research Methods:
– Introduced Migician, a new model for free-form and accurate grounding across multiple images.
– Developed MGrounding-630k dataset and proposed MIG-Bench benchmark for evaluating multi-image grounding capabilities.
💬 Research Conclusions:
– The new model outperformed existing models in multi-image grounding, surpassing even larger models by 21.61%.
– Comprehensive resources, including code, model, dataset, and benchmark, are made fully open-sourced.
👉 Paper link: https://huggingface.co/papers/2501.05767

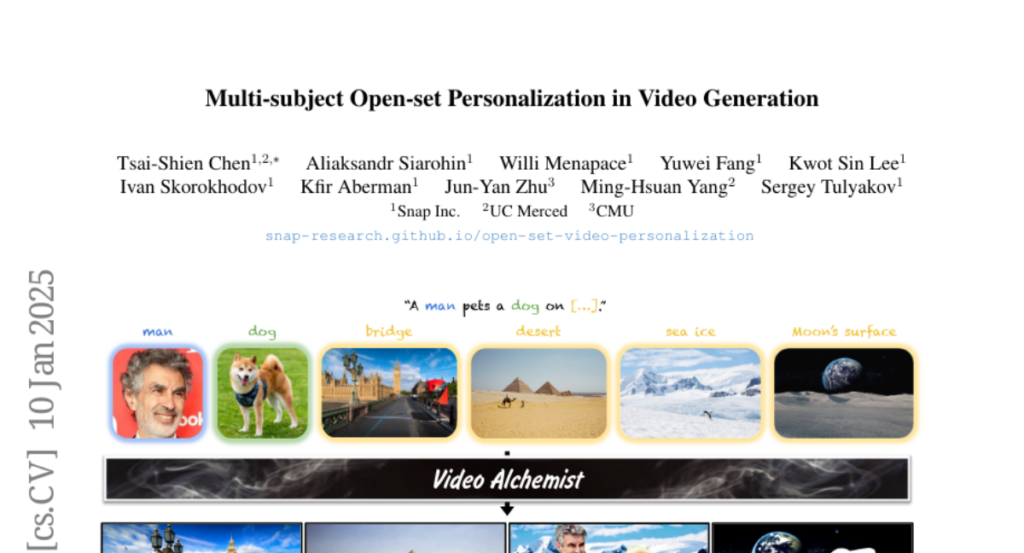
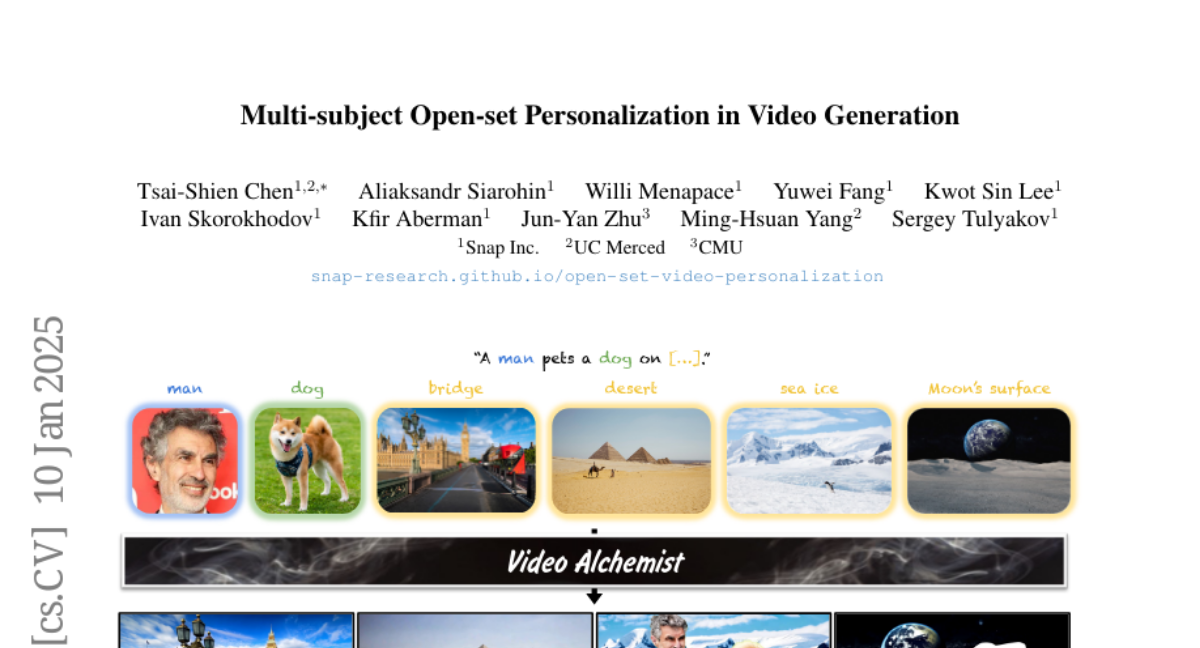
10. Multi-subject Open-set Personalization in Video Generation
🔑 Keywords: Video Alchemist, Diffusion Transformer, multi-subject personalization, video personalization
💡 Category: Generative Models
🌟 Research Objective:
– Present Video Alchemist, a video model for multi-subject, open-set personalization with no need for test-time optimization
🛠️ Research Methods:
– Developed a Diffusion Transformer module integrating conditional reference images and text prompts
– Created an automatic data construction pipeline with extensive image augmentations for better generalization
💬 Research Conclusions:
– Video Alchemist outperforms existing methods in quantitative and qualitative evaluations for video personalization
👉 Paper link: https://huggingface.co/papers/2501.06187
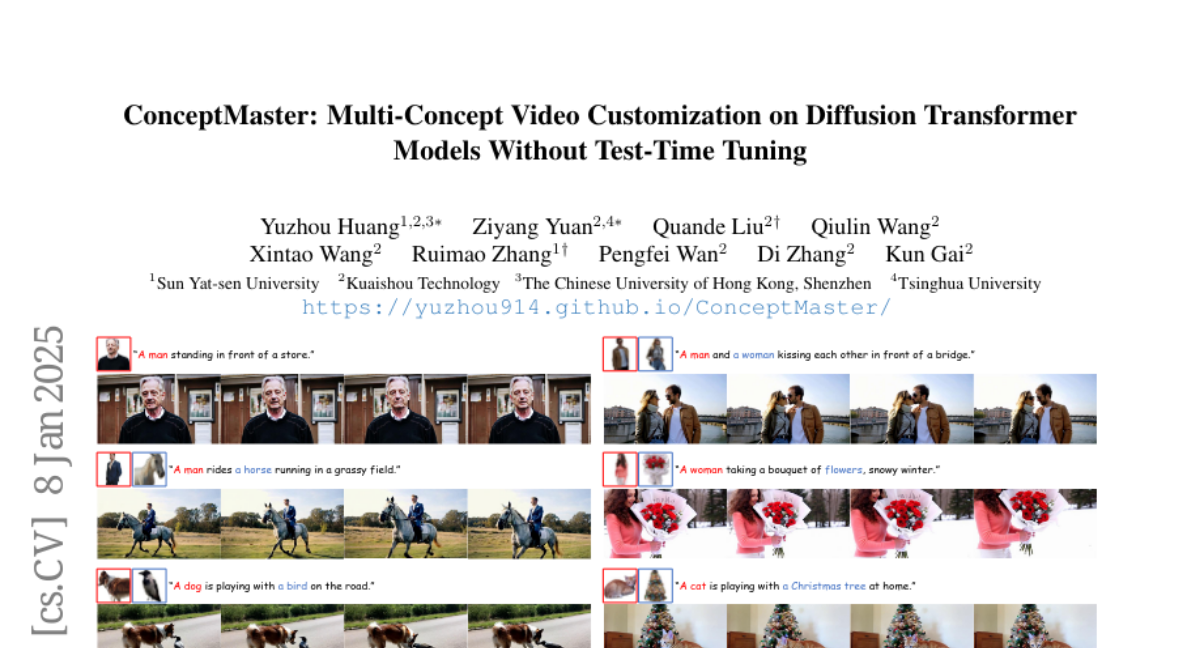
11. ConceptMaster: Multi-Concept Video Customization on Diffusion Transformer Models Without Test-Time Tuning
🔑 Keywords: Text-to-video generation, Multi-Concept Video Customization, ConceptMaster, identity decoupling
💡 Category: Generative Models
🌟 Research Objective:
– To address the identity decoupling problem and scarcity of high-quality video-entity pairs in Multi-Concept Video Customization (MCVC).
🛠️ Research Methods:
– Introduction of ConceptMaster, a framework using standalone decoupled multi-concept embeddings in diffusion models.
– Development of a data construction pipeline for collecting precise multi-concept video-entity data.
💬 Research Conclusions:
– ConceptMaster effectively tackles identity decoupling and maintains concept fidelity, outperforming previous methods in generating personalized and semantically accurate videos across multiple concepts.
👉 Paper link: https://huggingface.co/papers/2501.04698
12. Demystifying Domain-adaptive Post-training for Financial LLMs
🔑 Keywords: Domain-adaptive post-training, Large Language Models, Finance, Preference data distillation, Llama-Fin
💡 Category: AI in Finance
🌟 Research Objective:
– Investigate domain-adaptive post-training of Large Language Models in the finance domain to address adaptation challenges.
🛠️ Research Methods:
– Implement FINDAP for systematic analysis; evaluate continual pretraining, instruction tuning, and preference alignment; introduce a novel preference data distillation method.
💬 Research Conclusions:
– Developed Llama-Fin achieving state-of-the-art performance in financial tasks, and provided insights into specific challenges and solutions for domain adaptation of LLMs.
👉 Paper link: https://huggingface.co/papers/2501.04961

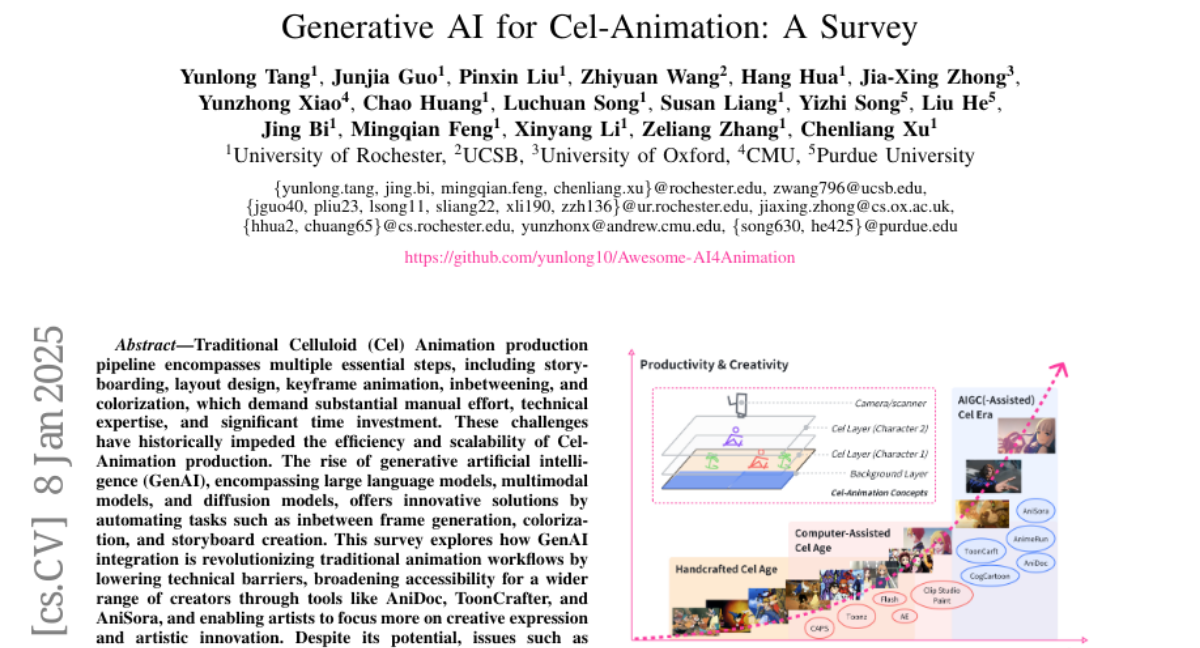
13. Generative AI for Cel-Animation: A Survey
🔑 Keywords: GenAI, AI-assisted animation, storyboard creation, AniDoc, ToonCrafter
💡 Category: Generative Models
🌟 Research Objective:
– To explore how GenAI is transforming traditional celluloid animation workflows by automating key tasks and broadening accessibility.
🛠️ Research Methods:
– A survey of the application of GenAI, using tools like AniDoc, ToonCrafter, and AniSora to integrate AI into animation production processes.
💬 Research Conclusions:
– GenAI lowers the technical barriers and enhances the creative process for artists, despite challenges with visual consistency and ethical considerations. The paper also explores future advancements in AI-assisted animation.
👉 Paper link: https://huggingface.co/papers/2501.06250