AI Native Daily Paper Digest – 20250212

1. Expect the Unexpected: FailSafe Long Context QA for Finance
🔑 Keywords: LLM, Query Failure, Context Failure, Robustness, Financial Applications
💡 Category: AI in Finance
🌟 Research Objective:
– To test the robustness and context-awareness of LLMs in financial query-answer systems using the FailSafeQA benchmark.
🛠️ Research Methods:
– Implement perturbations in queries and document contexts, using a LLM-as-a-Judge methodology with models like Qwen2.5-72B-Instruct and assessing them on criteria such as Robustness, Context Grounding, and Compliance.
💬 Research Conclusions:
– Some models can mitigate input perturbations but struggle with hallucinations; for instance, while Palmyra-Fin-128k-Instruct excelled in compliance, it faced challenges in maintaining robust predictions in 17% of cases, and OpenAI o3-mini fabricated information in 41% of cases. The study emphasizes the potential of FailSafeQA in enhancing LLM dependability for financial tasks.
👉 Paper link: https://huggingface.co/papers/2502.06329

2. Competitive Programming with Large Reasoning Models
🔑 Keywords: Reinforcement Learning, Large Language Models, Domain-Specific Techniques, General-Purpose Models, Competitive Programming
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance performance of large language models in complex coding and reasoning tasks through reinforcement learning.
🛠️ Research Methods:
– Comparison between general-purpose reasoning models (OpenAI o1 and o3) and a domain-specific system (o1-ioi) designed for the International Olympiad in Informatics (IOI).
💬 Research Conclusions:
– General-purpose model o3 achieves superior results without the need for hand-crafted domain-specific strategies, demonstrating the potential of scaled-up models in AI reasoning domains.
👉 Paper link: https://huggingface.co/papers/2502.06807

3. Retrieval-augmented Large Language Models for Financial Time Series Forecasting
🔑 Keywords: Stock movement prediction, Financial time-series forecasting, Retrieval-augmented generation, StockLLM, FinSeer
💡 Category: AI in Finance
🌟 Research Objective:
– The study aims to improve financial time-series forecasting by identifying and retrieving critical influencing factors using a novel retrieval-augmented generation (RAG) framework.
🛠️ Research Methods:
– The research introduces StockLLM, a fine-tuned large language model, and FinSeer, a retriever that maximizes similarity between queries and significant historical sequences.
💬 Research Conclusions:
– The RAG framework and FinSeer offer enhanced performance over existing methods, achieving 8% higher accuracy on BIGDATA22 and retrieving more impactful financial sequences, indicating a significant advancement in tailored retrieval models for financial forecasting.
👉 Paper link: https://huggingface.co/papers/2502.05878

4. CodeI/O: Condensing Reasoning Patterns via Code Input-Output Prediction
🔑 Keywords: Large Language Models, CodeI/O, Chain-of-Thought, Reasoning Tasks, Code Input-Output
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To enhance reasoning capabilities in Large Language Models by proposing CodeI/O, which utilizes contextually-grounded code transformed into a code input-output prediction format.
🛠️ Research Methods:
– Training models using natural language as Chain-of-Thought (CoT) rationales to predict inputs/outputs and decoupling structured reasoning from code-specific syntax.
💬 Research Conclusions:
– CodeI/O leads to consistent improvements in various reasoning tasks, and further enhancements are achieved with multi-turn revisions, resulting in CodeI/O++ with higher performance.
👉 Paper link: https://huggingface.co/papers/2502.07316

5. LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters!
🔑 Keywords: Large reasoning models, Long CoT, Qwen2.5-32B-Instruct, Low-rank adaptation, AI Native
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To explore how a Large Language Model can learn complex reasoning through Long CoT using data-efficient supervised fine-tuning and parameter-efficient low-rank adaptation.
🛠️ Research Methods:
– Utilized a Large Language Model (Qwen2.5-32B-Instruct) and trained it with 17k long CoT training samples to improve math and coding benchmarks.
💬 Research Conclusions:
– Found that the structure of Long CoT significantly impacts learning, with structural disruptions degrading model performance, while content perturbations have minimal effects.
👉 Paper link: https://huggingface.co/papers/2502.07374

6. Magic 1-For-1: Generating One Minute Video Clips within One Minute
🔑 Keywords: Magic 1-For-1, Video Generation, Diffusion Step Distillation, Optimization
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Magic 1-For-1, a model that efficiently generates video with optimized memory and latency.
🛠️ Research Methods:
– Factorizes text-to-video generation into text-to-image and image-to-video tasks.
– Uses multi-modal prior condition injection, adversarial step distillation, and parameter sparsification for optimization.
💬 Research Conclusions:
– Achieves quick video generation with improved visual quality and motion dynamics.
– Demonstrates potential for open-source explorations with reduced computational cost.
👉 Paper link: https://huggingface.co/papers/2502.07701

7. Gemstones: A Model Suite for Multi-Faceted Scaling Laws
🔑 Keywords: Scaling laws, Hyper-parameter, Model architecture, Transformers
💡 Category: Machine Learning
🌟 Research Objective:
– To study the impact of varying architecture and hyper-parameter choices on scaling laws prescriptions, releasing a comprehensive dataset called Gemstones.
🛠️ Research Methods:
– Analyzing over 4000 checkpoints from transformers trained with different configurations, such as learning rates and architectural shapes.
💬 Research Conclusions:
– Scaling laws prescriptions are sensitive to the experimental design and specific model checkpoints used during fitting, highlighting the complexity of predicting language modeling performance.
👉 Paper link: https://huggingface.co/papers/2502.06857

8. Teaching Language Models to Critique via Reinforcement Learning
🔑 Keywords: LLM critics, code generation, CTRL, reinforcement learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To teach large language models (LLMs) to critique and refine their outputs for improved code generation.
🛠️ Research Methods:
– Implemented CTRL, a framework using reinforcement learning to train critic models for providing useful feedback without human oversight.
💬 Research Conclusions:
– Critics trained with CTRL enhance pass rates and reduce errors, achieving up to 106.1% relative improvement in challenging benchmarks.
👉 Paper link: https://huggingface.co/papers/2502.03492

9. Scaling Pre-training to One Hundred Billion Data for Vision Language Models
🔑 Keywords: pre-training, vision-language models, cultural diversity, multilinguality
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Investigate the potential of pre-training vision-language models using an unprecedented scale of 100 billion examples.
🛠️ Research Methods:
– Analyze performance saturation on Western-centric benchmarks and gains in tasks involving cultural diversity.
– Examine multilingual enhancements in low-resource languages.
– Study effects of dataset quality filtering on cultural diversity.
💬 Research Conclusions:
– Large-scale datasets may not improve traditional benchmarks significantly but are crucial for inclusive multimodal systems.
– Cultural diversity and low-resource language tasks benefit more from extensive data scales.
👉 Paper link: https://huggingface.co/papers/2502.07617

10. NatureLM: Deciphering the Language of Nature for Scientific Discovery
🔑 Keywords: Foundation models, NatureLM, Scientific discovery, Sequence-based, Cross-domain generation
💡 Category: Generative Models
🌟 Research Objective:
– Introduce NatureLM, a sequence-based science foundation model designed for scientific discovery, integrating data from multiple scientific domains.
🛠️ Research Methods:
– Pre-training NatureLM with data from diverse scientific domains and developing models with parameters ranging from 1 billion to 46.7 billion.
💬 Research Conclusions:
– NatureLM exhibits notable improvement in performance with larger models, demonstrating versatility across applications including molecule optimization, cross-domain generation, and state-of-the-art task performance.
👉 Paper link: https://huggingface.co/papers/2502.07527

11. Enhance-A-Video: Better Generated Video for Free
🔑 Keywords: DiT-based video generation, Enhance-A-Video, temporal attention distributions
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a training-free approach to improve coherence and quality of DiT-based generated videos.
🛠️ Research Methods:
– Enhance cross-frame correlations using non-diagonal temporal attention distributions, applicable without retraining or fine-tuning.
💬 Research Conclusions:
– The approach improves temporal consistency and visual quality across various DiT-based video generation models, potentially inspiring further research in video generation enhancement.
👉 Paper link: https://huggingface.co/papers/2502.07508

12. Hephaestus: Improving Fundamental Agent Capabilities of Large Language Models through Continual Pre-Training
🔑 Keywords: LLM agents, API function calling, intrinsic reasoning, pre-training corpus
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduction of Hephaestus-Forge, a large-scale pre-training corpus to enhance LLM agents’ capabilities.
🛠️ Research Methods:
– Exploration of effective training protocols and scaling laws to find optimal data mixing ratios.
💬 Research Conclusions:
– Hephaestus-Forge significantly improves LLM capabilities, outperforming open-source models and rivaling commercial models on agent benchmarks.
👉 Paper link: https://huggingface.co/papers/2502.06589

13. Éclair — Extracting Content and Layout with Integrated Reading Order for Documents
🔑 Keywords: Optical Character Recognition, Document Structure, Semantic Information, Large Language Models, Vision Language Models
💡 Category: Computer Vision
🌟 Research Objective:
– The research introduces ‘Éclair’, a tool designed for comprehensive text extraction and document structure understanding from images, which is crucial for tasks like retrieval and training Large Language Models (LLMs) and Vision Language Models (VLMs).
🛠️ Research Methods:
– Éclair is evaluated through a diverse human-annotated benchmark for document-level OCR and semantic classification to showcase its novel capabilities.
💬 Research Conclusions:
– Éclair achieves state-of-the-art accuracy on custom and established benchmarks, outperforming other methods on key metrics, demonstrating its versatility and robust performance in document processing.
👉 Paper link: https://huggingface.co/papers/2502.04223

14. CAD-Editor: A Locate-then-Infill Framework with Automated Training Data Synthesis for Text-Based CAD Editing
🔑 Keywords: CAD-Editor, text-based CAD editing, Large Vision-Language Models, Large Language Models
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The main goal is to develop a framework for text-based CAD editing that leverages automated data synthesis and large-scale models.
🛠️ Research Methods:
– Introduction of CAD-Editor, a framework using a locate-then-infill method with automated data synthesis pipelines.
– Utilization of Large Vision-Language Models (LVLMs) and Large Language Models (LLMs) to generate and understand editing instructions.
💬 Research Conclusions:
– CAD-Editor demonstrates superior quantitative and qualitative performance in text-based CAD editing tasks.
👉 Paper link: https://huggingface.co/papers/2502.03997

15. VidCRAFT3: Camera, Object, and Lighting Control for Image-to-Video Generation
🔑 Keywords: VidCRAFT3, Spatial Triple-Attention Transformer, VideoLightingDirection dataset, image-to-video generation
💡 Category: Generative Models
🌟 Research Objective:
– Introduce VidCRAFT3 to achieve precise control over multiple visual elements in image-to-video generation, including camera motion, object motion, and lighting direction.
🛠️ Research Methods:
– Developed the Spatial Triple-Attention Transformer to integrate various visual elements symmetrically.
– Constructed the VideoLightingDirection (VLD) dataset with detailed lighting annotations to support the framework.
– Proposed a three-stage training strategy to eliminate the need for simultaneous multi-element data annotation.
💬 Research Conclusions:
– VidCRAFT3 demonstrated superior performance in control granularity and visual coherence compared to state-of-the-art methods, as shown through extensive experiments on benchmark datasets.
– All code and data for the project will be publicly accessible.
👉 Paper link: https://huggingface.co/papers/2502.07531

16. Mask-Enhanced Autoregressive Prediction: Pay Less Attention to Learn More
🔑 Keywords: Large Language Models, Mask-Enhanced Autoregressive Prediction, Masked Language Modeling, Next-Token Prediction
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance large language models’ in-context retrieval capabilities by integrating Masked Language Modeling into Next-Token Prediction.
🛠️ Research Methods:
– Introduced Mask-Enhanced Autoregressive Prediction (MEAP), which masks a small fraction of input tokens and uses a decoder-only Transformer for next-token prediction without additional computational overhead.
💬 Research Conclusions:
– MEAP substantially improves key information retrieval and long-context reasoning tasks, shows notable performance in commonsense reasoning, and demonstrates advantages in supervised fine-tuning, especially in lost-in-the-middle scenarios.
👉 Paper link: https://huggingface.co/papers/2502.07490

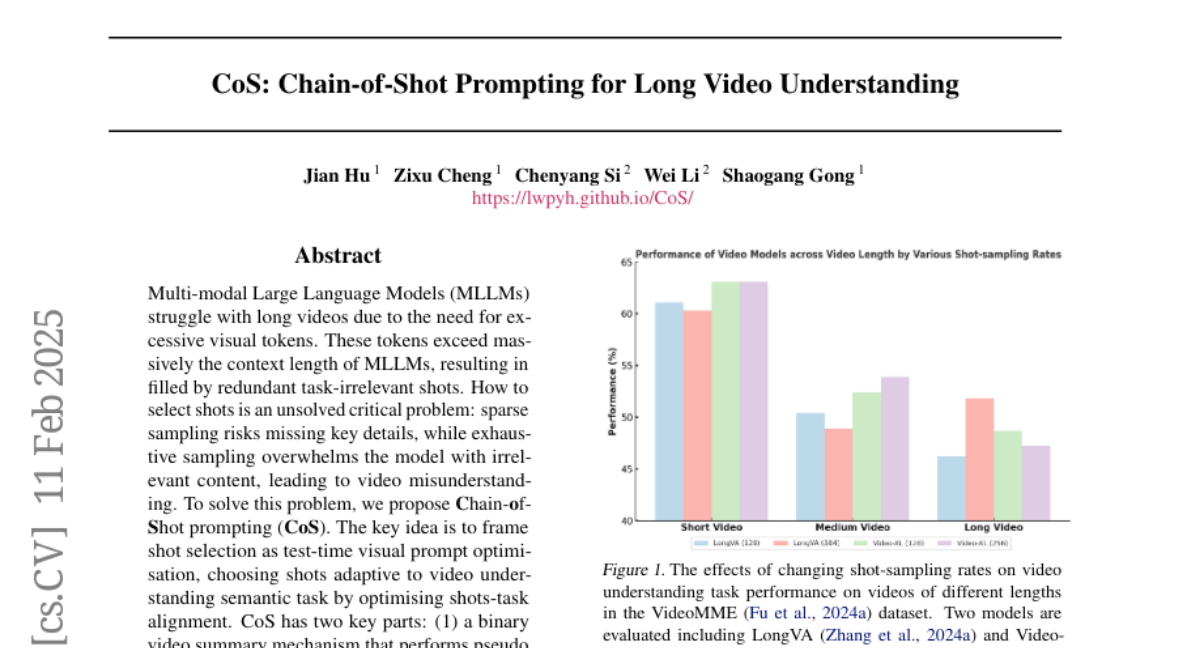
17. CoS: Chain-of-Shot Prompting for Long Video Understanding
🔑 Keywords: Multi-modal Large Language Models, long video understanding, Chain-of-Shot prompting, video reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address the issue of excessive and task-irrelevant visual tokens in long video processing by MLLMs, and to optimize shot selection for improved video understanding.
🛠️ Research Methods:
– Introduces Chain-of-Shot prompting which optimizes shot-task alignment through a binary video summary mechanism for pseudo temporal grounding and a video co-reasoning module.
💬 Research Conclusions:
– Demonstrates that the CoS method effectively enhances long video understanding by focusing on task-relevant context and shows adaptability across various datasets and baselines.
👉 Paper link: https://huggingface.co/papers/2502.06428
18. Hypencoder: Hypernetworks for Information Retrieval
🔑 Keywords: Hypencoder, Neural Network, Relevance Score, Dense Retrieval, Search Algorithm
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce a new paradigm for retrieval models using a small neural network, named Hypencoder, to improve relevance scoring in search tasks.
🛠️ Research Methods:
– Utilize a hypernetwork to generate the weights for the Hypencoder, which acts as a query encoder by taking a document representation and outputting a relevance score.
💬 Research Conclusions:
– Hypencoder significantly outperforms traditional dense retrieval models, shows superior performance on challenging retrieval tasks, and efficiently processes large document sets in milliseconds.
👉 Paper link: https://huggingface.co/papers/2502.05364

19. Forget What You Know about LLMs Evaluations – LLMs are Like a Chameleon
🔑 Keywords: Large language models, overfitting, Chameleon Benchmark Overfit Detector, dataset-agnostic, robust language understanding
💡 Category: Natural Language Processing
🌟 Research Objective:
– To detect overreliance on dataset-specific cues in large language models (LLMs) through the Chameleon Benchmark Overfit Detector (C-BOD).
🛠️ Research Methods:
– Implementation of C-BOD which systematically distorts benchmark prompts and evaluates performance changes to reveal model overfitting.
💬 Research Conclusions:
– The study showed that LLMs, especially bigger ones or those with higher baseline accuracy, tend to rely on memorized patterns as demonstrated by significant performance drops under perturbations.
– C-BOD promotes more robust language understanding and can be integrated into training pipelines, challenging the focus on leaderboard scores by emphasizing resilience and generalization.
👉 Paper link: https://huggingface.co/papers/2502.07445

20. Pippo: High-Resolution Multi-View Humans from a Single Image
🔑 Keywords: Pippo, generative model, multi-view diffusion transformer, 3D consistency, single image
💡 Category: Generative Models
🌟 Research Objective:
– To develop Pippo, a model that generates 1K resolution dense turnaround videos of a person from a single photo without additional inputs.
🛠️ Research Methods:
– Pre-training on 3 billion human images, and performing multi-view mid-training and post-training with studio-captured humans, employing a multi-view diffusion transformer and attention biasing techniques.
💬 Research Conclusions:
– Pippo effectively produces multi-view human generations with improved 3D consistency, outperforming existing models in generating views from a single image.
👉 Paper link: https://huggingface.co/papers/2502.07785
21. Sparse Autoencoders for Scientifically Rigorous Interpretation of Vision Models
🔑 Keywords: Sparse Autoencoders, Vision Models, Interpretable Features, Model Behavior
💡 Category: Computer Vision
🌟 Research Objective:
– To establish a framework that both interprets and verifies the causal influence of learned features in vision models.
🛠️ Research Methods:
– Utilization of sparse autoencoders to discover and manipulate human-interpretable visual features.
💬 Research Conclusions:
– Demonstrated differences in semantic abstractions in models with various pre-training objectives and provided a tool without needing model re-training for understanding and controlling vision model behavior.
👉 Paper link: https://huggingface.co/papers/2502.06755

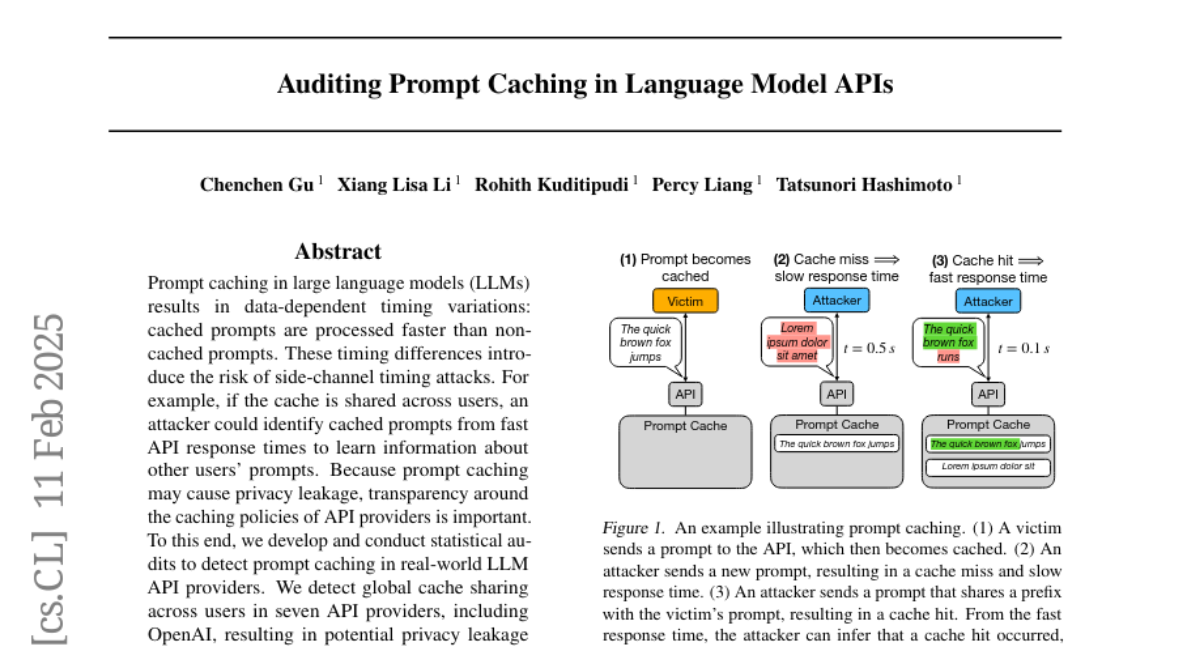
22. Auditing Prompt Caching in Language Model APIs
🔑 Keywords: Prompt caching, Side-channel timing attacks, Privacy leakage, API providers, Decoder-only Transformer
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– To investigate the potential privacy risks associated with prompt caching in large language models by examining data-dependent timing variations.
🛠️ Research Methods:
– Developed and conducted statistical audits to detect prompt caching across various large language model API providers.
💬 Research Conclusions:
– Identified global cache sharing across multiple API providers, including OpenAI, resulting in potential privacy leakage.
– Discovered that prompt caching can reveal information about the model architecture, such as confirming OpenAI’s embedding model as a decoder-only Transformer.
👉 Paper link: https://huggingface.co/papers/2502.07776
23. FocalCodec: Low-Bitrate Speech Coding via Focal Modulation Networks
🔑 Keywords: Large Language Models, Neural Audio Codecs, FocalCodec, Voice Conversion, Speech Resynthesis
💡 Category: Generative Models
🌟 Research Objective:
– To develop a low-bitrate codec called FocalCodec to efficiently compress speech at lower bitrates while preserving semantic and acoustic information.
🛠️ Research Methods:
– Utilization of focal modulation and a single binary codebook to compress continuous audio into tokens, facilitating speech processing across multilingual and noisy environments.
💬 Research Conclusions:
– FocalCodec achieves competitive performance in speech resynthesis and voice conversion, surpassing existing models by maintaining necessary information for downstream tasks and generative modeling at reduced bitrates.
👉 Paper link: https://huggingface.co/papers/2502.04465

24. Skill Expansion and Composition in Parameter Space
🔑 Keywords: Parametric Skill Expansion, Skill Composition, Autonomous Agents, Low-Rank Adaptation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Propose a framework (PSEC) to improve efficiency in skill expansion and new task learning for autonomous agents.
🛠️ Research Methods:
– Utilize a skill library with a plug-and-play Low-Rank Adaptation (LoRA) approach for parameter-efficient finetuning and direct skill composition in parameter space.
💬 Research Conclusions:
– Demonstrated superior capacity of PSEC to efficiently leverage prior knowledge and expand skill libraries, showing robust results on benchmarks such as D4RL, DSRL, and the DeepMind Control Suite.
👉 Paper link: https://huggingface.co/papers/2502.05932

25. Goedel-Prover: A Frontier Model for Open-Source Automated Theorem Proving
🔑 Keywords: Goedel-Prover, Automated Formal Proof Generation, Large Language Model, Lean 4
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces Goedel-Prover, an open-source large language model designed to achieve state-of-the-art performance in automated formal proof generation for mathematical problems.
🛠️ Research Methods:
– It tackles the challenge of scarce formalized math statements by training statement formalizers to translate natural language math problems into formal language (Lean 4), creating a large dataset. A series of provers are trained iteratively, each building on the last to generate a substantial dataset of formal proofs.
💬 Research Conclusions:
– Goedel-Prover outperforms existing models in whole-proof generation, with significant success rates on benchmarks like miniF2F and PutnamBench, and produces a substantial increase in formal proofs for Lean Workbook problems compared to prior efforts.
👉 Paper link: https://huggingface.co/papers/2502.07640

26. Learning Conformal Abstention Policies for Adaptive Risk Management in Large Language and Vision-Language Models
🔑 Keywords: Large Language Models, Vision-Language Models, Uncertainty Quantification, Conformal Prediction, Reinforcement Learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Address the limitations of static thresholds in conformal prediction for safety-critical applications by integrating reinforcement learning to optimize abstention dynamically.
🛠️ Research Methods:
– Combine reinforcement learning with conformal prediction to create dynamic abstention thresholds and evaluate performance across multiple benchmarks.
💬 Research Conclusions:
– The proposed method improves accuracy by up to 3.2%, increases AUROC for hallucination detection by 22.19%, enhances uncertainty-guided selective generation by 21.17%, and reduces calibration error by 70%-85%, consistently meeting a 90% coverage target.
👉 Paper link: https://huggingface.co/papers/2502.06884
