AI Native Daily Paper Digest – 20250225

1. Thus Spake Long-Context Large Language Model
🔑 Keywords: Long context, Large Language Models, Lifelong learning, Architecture
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the challenges and opportunities associated with long context in Large Language Models (LLMs) and illustrate its essential role in NLP development.
🛠️ Research Methods:
– This survey draws an analogy between the extension of context in LLMs and human transcendence, by provides a comprehensive overview of long-context LLMs from architecture, infrastructure, training, and evaluation perspectives.
💬 Research Conclusions:
– Long-context mechanisms remain a core advantage for LLMs, akin to human lifelong learning. The survey outlines the significant progress in extending context length to millions of tokens and highlights ten unanswered questions in the long-context LLM field.
👉 Paper link: https://huggingface.co/papers/2502.17129

2. VideoGrain: Modulating Space-Time Attention for Multi-grained Video Editing
🔑 Keywords: Video Generation, Video Editing, Diffusion Models, Multi-grained Editing
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to address challenges in multi-grained video editing by enhancing text-to-region control and feature coupling within diffusion models.
🛠️ Research Methods:
– Introduced VideoGrain, a zero-shot approach that utilizes modulated space-time attention mechanisms to achieve fine-grained video content control.
💬 Research Conclusions:
– VideoGrain demonstrated state-of-the-art performance in real-world scenarios, offering improved control over video content. The project’s resources are publicly available online.
👉 Paper link: https://huggingface.co/papers/2502.17258

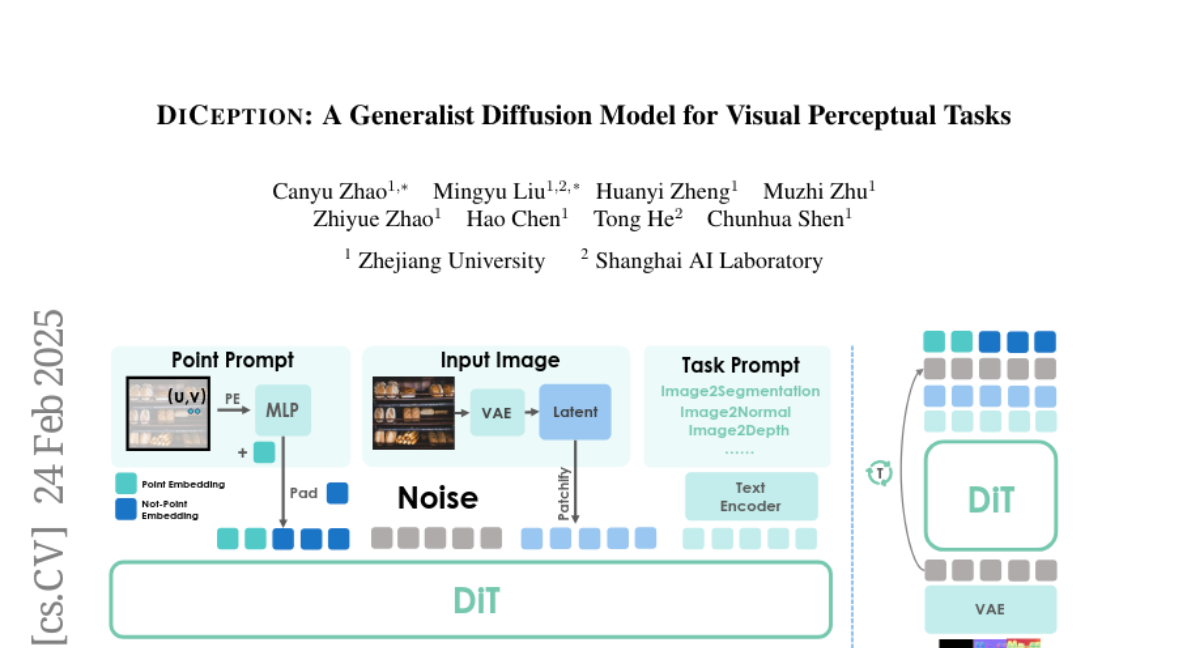
3. DICEPTION: A Generalist Diffusion Model for Visual Perceptual Tasks
🔑 Keywords: Generalist Perception Model, Text-to-Image Diffusion Models, DICEPTION, Semantic Segmentation
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a robust generalist perception model capable of handling multiple perception tasks with limited computational resources and training data.
🛠️ Research Methods:
– Utilize pre-trained text-to-image diffusion models on a large dataset of images and apply color encoding strategies for various perception tasks.
💬 Research Conclusions:
– DICEPTION effectively performs multiple perception tasks with performance comparable to state-of-the-art models while using significantly less data and resources.
– The model can be efficiently adapted to new tasks with minimal fine-tuning, offering a cost-effective solution for developing visual generalist models.
👉 Paper link: https://huggingface.co/papers/2502.17157
4. Slamming: Training a Speech Language Model on One GPU in a Day
🔑 Keywords: Speech Language Models, Synthetic Training Data, Model Initialization, Preference Optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to develop a recipe, termed “Slam,” for training high-quality Speech Language Models (SLMs) on a single academic GPU within 24 hours.
🛠️ Research Methods:
– An empirical analysis was conducted focusing on model initialization and architecture, the use of synthetic training data, and preference optimization with synthetic data. Additional refinements were made to other components of the training process.
💬 Research Conclusions:
– The study demonstrated that the Slam recipe not only facilitates quick and efficient training but also scales effectively with increased computational resources, achieving performance comparable to leading SLMs at a reduced computational cost. This approach offers a more accessible pathway to SLM research and suggests optimistic feasibility regarding SLM scaling laws, surpassing predicted compute optimal performance.
👉 Paper link: https://huggingface.co/papers/2502.15814

5. Audio-FLAN: A Preliminary Release
🔑 Keywords: audio tokenization, large language models, instruction tuning, Audio-FLAN, zero-shot learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Audio-FLAN, a dataset designed to unify audio understanding and generation for large language models.
🛠️ Research Methods:
– Development of a large-scale instruction-tuning dataset with 80 diverse tasks across speech, music, and sound domains.
💬 Research Conclusions:
– Audio-FLAN facilitates the creation of unified audio-language models, enabling effective zero-shot learning for both understanding and generation tasks.
👉 Paper link: https://huggingface.co/papers/2502.16584

6. GCC: Generative Color Constancy via Diffusing a Color Checker
🔑 Keywords: Color Constancy, Diffusion Models, Illumination Estimation, Cross-Camera Robustness
💡 Category: Computer Vision
🌟 Research Objective:
– To improve the generalization of color constancy methods across different camera sensors through the use of diffusion models and innovative techniques.
🛠️ Research Methods:
– Utilized diffusion models to inpaint color checkers into images for illumination estimation.
– Implemented a single-step deterministic inference and a Laplacian decomposition technique for color adaptation.
– Developed a mask-based data augmentation strategy to handle imprecise color checker annotations.
💬 Research Conclusions:
– The GCC method demonstrated superior robustness in cross-camera scenarios, achieving state-of-the-art worst-25% error rates, showcasing stability and generalization without sensor-specific training.
👉 Paper link: https://huggingface.co/papers/2502.17435
7. CodeCriticBench: A Holistic Code Critique Benchmark for Large Language Models
🔑 Keywords: Large Language Models, CodeCriticBench, critique capacity, code generation, code QA
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to address limitations in existing critique benchmarks for Large Language Models (LLMs), particularly in diverse reasoning tasks and insufficient evaluation on code tasks.
🛠️ Research Methods:
– The authors introduce CodeCriticBench, a comprehensive code critique benchmark featuring two main code tasks: code generation and code QA. Evaluation protocols include both basic and advanced critique evaluations with fine-grained checklists.
💬 Research Conclusions:
– The experimental results demonstrate the effectiveness of CodeCriticBench in evaluating the critique capacity of current LLMs.
👉 Paper link: https://huggingface.co/papers/2502.16614

8. Make LoRA Great Again: Boosting LoRA with Adaptive Singular Values and Mixture-of-Experts Optimization Alignment
🔑 Keywords: Low-Rank Adaptation, Large Language Models, Mixture-of-Experts, Singular Value Decomposition, Performance Improvement
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to enhance the performance of Low-Rank Adaptation (LoRA) for Large Language Models by incorporating a Mixture-of-Experts (MoE) architecture using a novel framework, GOAT.
🛠️ Research Methods:
– The study proposes GOAT, a framework that uses an adaptively integrated SVD-structured MoE and strategic optimization alignment with Full Fine-Tuning to boost LoRA’s efficiency.
💬 Research Conclusions:
– The GOAT framework improves the efficiency and performance of LoRA, demonstrating state-of-the-art results across 25 datasets, effectively closing the performance gap with Full Fine-Tuning.
👉 Paper link: https://huggingface.co/papers/2502.16894

9. Linguistic Generalizability of Test-Time Scaling in Mathematical Reasoning
🔑 Keywords: Multilingual math benchmark, MCLM, Outcome Reward Modeling, Budget Forcing, multilingual LLM
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the effectiveness of test-time scaling methods on multilingual tasks using the newly introduced MCLM benchmark.
🛠️ Research Methods:
– Evaluated three test-time scaling methods: Outcome Reward Modeling (ORM), Process Reward Modeling, and Budget Forcing (BF) on multilingual LLMs like Qwen2.5-1.5B Math and MR1-1.5B.
💬 Research Conclusions:
– Test-time scaling methods show limited performance improvements across multilingual tasks compared to English AIME, indicating challenges in generalization.
– Qwen2.5-1.5B Math with ORM and BF on MR1-1.5B showed comparable performance, with ORM slightly outperforming.
– Highlighted the constrained effectiveness of “thinking LLMs” when scaled with similar inference FLOPs.
👉 Paper link: https://huggingface.co/papers/2502.17407

10. Multimodal Inconsistency Reasoning (MMIR): A New Benchmark for Multimodal Reasoning Models
🔑 Keywords: Multimodal Inconsistency Reasoning, MLLMs, Cross-Modal Conflicts, Chain-of-Thought, Set-of-Mark
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces the Multimodal Inconsistency Reasoning (MMIR) benchmark to evaluate the ability of Multimodal Large Language Models (MLLMs) in detecting and reasoning about inconsistencies across various semantic mismatches in layout-rich content.
🛠️ Research Methods:
– Developed the MMIR benchmark comprising 534 samples with synthetically injected errors across five reasoning-heavy categories.
– Evaluated the performance of six state-of-the-art MLLMs regarding their ability to detect inconsistencies, especially in cross-modal contexts.
💬 Research Conclusions:
– Models with dedicated multimodal reasoning capabilities performed better than others, especially in text-related inconsistencies.
– Open-source models are particularly susceptible to errors regarding cross-modal and complex layout inconsistencies.
– Probing experiments show minimal improvements with single-modality prompts, indicating a significant bottleneck in cross-modal reasoning capabilities.
👉 Paper link: https://huggingface.co/papers/2502.16033

11. RIFLEx: A Free Lunch for Length Extrapolation in Video Diffusion Transformers
🔑 Keywords: video generation, temporal coherence, RIFLEx, frequency components, extrapolation
💡 Category: Generative Models
🌟 Research Objective:
– To address the challenge of generating long videos with temporal coherence by analyzing frequency components in positional embeddings.
🛠️ Research Methods:
– Systematic analysis of frequency components and development of RIFLEx to reduce intrinsic frequency, enhancing extrapolation capabilities.
💬 Research Conclusions:
– RIFLEx suppresses repetition and preserves motion consistency, enabling high-quality video extrapolation up to three times without extensive training.
👉 Paper link: https://huggingface.co/papers/2502.15894

12. Stable-SPAM: How to Train in 4-Bit More Stably than 16-Bit Adam
🔑 Keywords: 4-bit training, low-bit precision, Stable-SPAM, gradient normalization, spike-aware gradient clipping
💡 Category: Machine Learning
🌟 Research Objective:
– The objective is to improve performance in 4-bit training by addressing the sensitivity to learning rates and unstable gradient norms seen in recent optimizers.
🛠️ Research Methods:
– Introduction of Stable-SPAM, which includes techniques like adaptive clipping threshold updates, gradient matrix normalization using historical statistics, and momentum reset to prevent gradient spikes.
💬 Research Conclusions:
– Stable-SPAM effectively stabilizes gradients in 4-bit LLM training, outperforming existing methods such as Adam, and achieves similar loss with half the training steps compared to Adam in 4-bit scenarios.
👉 Paper link: https://huggingface.co/papers/2502.17055

13. Mobile-Agent-V: Learning Mobile Device Operation Through Video-Guided Multi-Agent Collaboration
🔑 Keywords: Mobile-Agent-V, video guidance, mobile automation, task management
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce a framework, Mobile-Agent-V, to provide operational knowledge for mobile automation using video guidance.
🛠️ Research Methods:
– Leverages video inputs with a sliding window strategy, integrating a video agent and deep-reflection agent to align actions with user instructions.
💬 Research Conclusions:
– Achieves a 30% improvement in performance compared to existing frameworks, enhancing task execution capabilities without needing specialized preprocessing.
👉 Paper link: https://huggingface.co/papers/2502.17110

14. Forecasting Open-Weight AI Model Growth on Hugging Face
🔑 Keywords: Open-weight AI, Model Development, Innovation, AI Ecosystems
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to predict which open-weight AI models will drive innovation and shape AI ecosystems.
🛠️ Research Methods:
– The researchers adapt a citation dynamics model, originally by Wang et al., to quantify the influence of open-weight models using parameters like immediacy, longevity, and relative fitness.
💬 Research Conclusions:
– The citation-style framework effectively captures the adoption trajectories of open-weight models, distinguishing standard from unique patterns or sudden usage increases.
👉 Paper link: https://huggingface.co/papers/2502.15987

15. Reflective Planning: Vision-Language Models for Multi-Stage Long-Horizon Robotic Manipulation
🔑 Keywords: Vision-Language Models, Robotic Manipulation, Physical Reasoning, Generative Models
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To introduce a novel test-time computation framework to enhance Vision-Language Models’ capabilities in physical reasoning for multi-stage robotic manipulation tasks.
🛠️ Research Methods:
– Developed a “reflection” mechanism for pre-trained VLMs to predict future world states and guide action selection effectively.
💬 Research Conclusions:
– The proposed method outperformed state-of-the-art commercial Vision-Language Models and other post-training approaches like Monte Carlo Tree Search.
👉 Paper link: https://huggingface.co/papers/2502.16707

16. Beyond Release: Access Considerations for Generative AI Systems
🔑 Keywords: Generative AI, System Components, Access Variables
💡 Category: Generative Models
🌟 Research Objective:
– To examine how access to Generative AI system components influences potential risks and benefits beyond mere release.
🛠️ Research Methods:
– Deconstruction of access along resourcing, technical usability, and utility axes, and comparison of four language models based on accessibility.
💬 Research Conclusions:
– Access variables are crucial for scaling user access and managing risks; the framework enhances understanding of release impacts on system engagement, research, and policy.
👉 Paper link: https://huggingface.co/papers/2502.16701

17. X-Dancer: Expressive Music to Human Dance Video Generation
🔑 Keywords: Zero-shot, Image Animation, Transformer-Diffusion, Music-driven, Dance Videos
💡 Category: Generative Models
🌟 Research Objective:
– To develop X-Dancer, a zero-shot music-driven image animation pipeline capable of generating diverse and lifelike human dance videos from a single static image.
🛠️ Research Methods:
– Employed a unified transformer-diffusion framework using an autoregressive transformer to synthesize music-synchronized token sequences for 2D poses.
– Utilized a diffusion model to produce coherent dance video frames aligned with musical beats, leveraging monocular videos for data.
💬 Research Conclusions:
– X-Dancer significantly surpasses existing methods in creating diverse, expressive, and realistic dance videos.
– Demonstrates enhanced scalability and data efficiency compared to traditional 3D motion generation methods.
👉 Paper link: https://huggingface.co/papers/2502.17414

18. Benchmarking Temporal Reasoning and Alignment Across Chinese Dynasties
🔑 Keywords: Temporal Reasoning, Large Language Models, Chinese Time Reasoning, Cultural Context
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to introduce Chinese Time Reasoning (CTM) as a benchmark for evaluating Large Language Models (LLMs) on temporal reasoning within Chinese dynastic chronology.
🛠️ Research Methods:
– CTM focuses on cross-entity relationships, pairwise temporal alignment, and contextualized reasoning, offering a culturally-grounded approach.
💬 Research Conclusions:
– Extensive experiments with CTM underline its challenges for LLMs and suggest areas for future improvement.
👉 Paper link: https://huggingface.co/papers/2502.16922

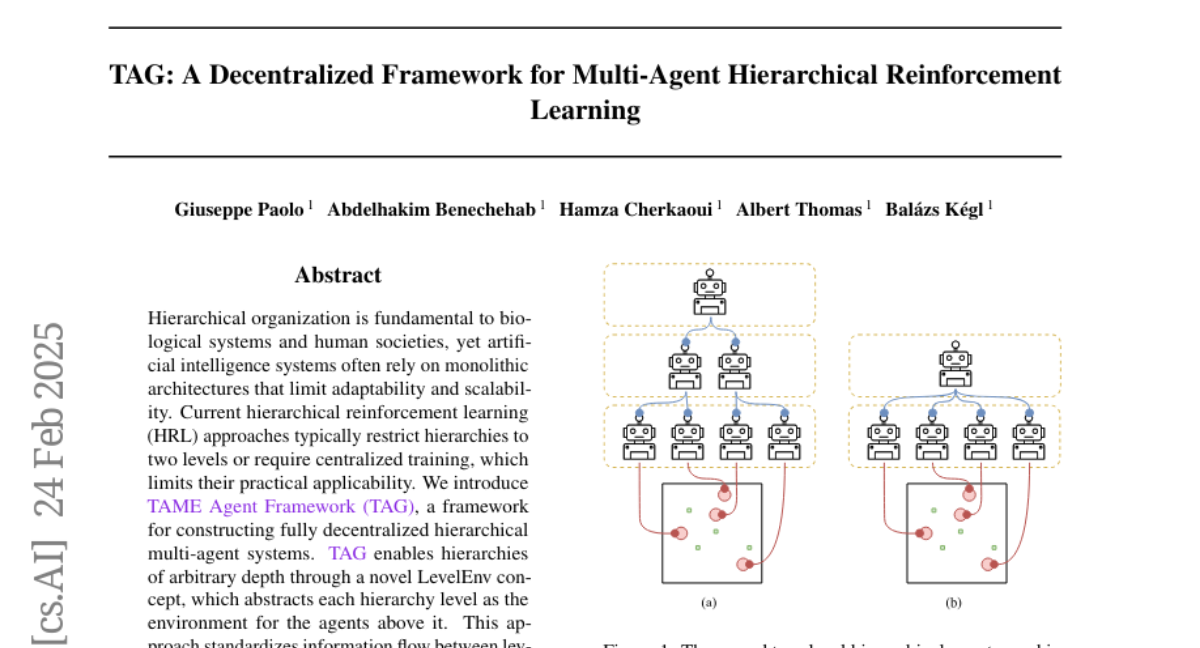
19. TAG: A Decentralized Framework for Multi-Agent Hierarchical Reinforcement Learning
🔑 Keywords: Hierarchical organization, Decentralized, Multi-agent systems, Hierarchical Reinforcement Learning (HRL)
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce TAME Agent Framework (TAG) to construct fully decentralized hierarchical multi-agent systems.
🛠️ Research Methods:
– Develop a novel LevelEnv concept to enable hierarchies of arbitrary depth and standardize information flow between levels.
💬 Research Conclusions:
– Demonstrate improved performance and learning speed using decentralized hierarchical organization with TAG, surpassing classical multi-agent RL baselines.
👉 Paper link: https://huggingface.co/papers/2502.15425
20. InductionBench: LLMs Fail in the Simplest Complexity Class
🔑 Keywords: Large Language Models, Inductive Reasoning, InductionBench
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– This paper introduces InductionBench, a new benchmark to evaluate the inductive reasoning capabilities of Large Language Models (LLMs).
🛠️ Research Methods:
– The study involves testing LLMs against InductionBench to assess their capacity to infer underlying rules from observed data, simulating scientific discovery processes.
💬 Research Conclusions:
– Experimental results indicate that even advanced LLMs perform poorly on basic inductive reasoning tasks, highlighting a critical gap in their current capabilities.
👉 Paper link: https://huggingface.co/papers/2502.15823

21. Grounded Persuasive Language Generation for Automated Marketing
🔑 Keywords: Large Language Models, Automation, Real Estate Marketing, Personalization
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to develop an agentic framework utilizing Large Language Models (LLMs) to automate the generation of persuasive and grounded marketing content specifically for real estate listings.
🛠️ Research Methods:
– The proposed framework consists of three key modules: a Grounding Module for predicting marketable features, a Personalization Module for aligning content with user preferences, and a Marketing Module to ensure factual accuracy and the inclusion of localized features.
💬 Research Conclusions:
– Systematic experiments with potential house buyers reveal that the LLM-generated marketing descriptions are preferred over those created by human experts, indicating the potential of this approach to automate large-scale targeted marketing responsibly using factual content.
👉 Paper link: https://huggingface.co/papers/2502.16810

22. Can Community Notes Replace Professional Fact-Checkers?
🔑 Keywords: misinformation, fact-checking, community moderation, social media, crowdsourced notes
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to explore the dependencies between professional fact-checking and community moderation, particularly in the context of social media platforms like Twitter/X and Meta.
🛠️ Research Methods:
– The researchers used language models to annotate a corpus of Twitter/X community notes, assessing attributes such as topic, cited sources, and whether they refute misinformation narratives.
💬 Research Conclusions:
– The analysis shows that community notes reference fact-checking sources significantly more than previously reported, with an emphasis on posts linked to broader narratives. The study concludes that professional fact-checking is integral to effective community moderation.
👉 Paper link: https://huggingface.co/papers/2502.14132

23. Investigating the Impact of Quantization Methods on the Safety and Reliability of Large Language Models
🔑 Keywords: Large Language Models, Quantization, OpenSafetyMini, Safety, Trustworthiness
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore the safety and trustworthiness of quantized models, which has been underexplored in current research.
🛠️ Research Methods:
– Four state-of-the-art quantization techniques were evaluated on LLaMA and Mistral models using four different benchmarks, including human evaluations, to discern the best performance.
💬 Research Conclusions:
– The research finds that the optimal quantization method differs at 4-bit precision, while vector quantization techniques offer superior safety and trustworthiness at 2-bit precision, indicating a pathway for future research advances.
👉 Paper link: https://huggingface.co/papers/2502.15799

24. MONSTER: Monash Scalable Time Series Evaluation Repository
🔑 Keywords: Time Series Classification, Scalability, Datasets, Benchmarks
💡 Category: Machine Learning
🌟 Research Objective:
– Introduce a collection of larger datasets called MONSTER to diversify time series classification benchmarks.
🛠️ Research Methods:
– Develop and utilize larger datasets compared to UCR and UEA repositories to foster models that address scalability issues.
💬 Research Conclusions:
– Larger datasets provide potential for advancement in learning from considerable data volumes, moving beyond models focused solely on minimizing variance.
👉 Paper link: https://huggingface.co/papers/2502.15122

25. Early-Exit and Instant Confidence Translation Quality Estimation
🔑 Keywords: Quality Estimation, Machine Translation, Uncertainty Estimation, Early-Exit, Computational Efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to reduce the cost of quality estimation in machine translation at scale and develop an inexpensive method for uncertainty estimation.
🛠️ Research Methods:
– Introduction of Instant Confidence COMET, an uncertainty-aware quality estimation model that performs efficiently at reduced costs.
– Development of Early-Exit COMET, enabling early computation of quality scores and confidences to optimize evaluation and reranking processes.
💬 Research Conclusions:
– The proposed methods significantly reduce computational requirements by 50% with minimal performance loss, enhancing efficiency in evaluation and reranking tasks in machine translation.
👉 Paper link: https://huggingface.co/papers/2502.14429

26. Pandora3D: A Comprehensive Framework for High-Quality 3D Shape and Texture Generation
🔑 Keywords: 3D shape generation, texture generation, Variational Autoencoder, diffusion network, neural architectures
💡 Category: Generative Models
🌟 Research Objective:
– The report aims to present a framework for generating high-quality 3D shapes and textures from inputs such as single images, multi-view images, and text descriptions.
🛠️ Research Methods:
– The framework utilizes a 3D shape generation pipeline with a Variational Autoencoder and a diffusion network to handle input prompts. It explores an Artist-Created Mesh approach for simpler geometries. The texture generation process involves multi-stage efforts for generating and refining textures from different viewpoints, including a consistency scheduler to ensure pixel-wise consistency.
💬 Research Conclusions:
– The framework effectively handles diverse input formats and uses advanced methodologies to produce high-quality 3D content. Future directions and the availability of source code and pretrained weights provide a solid foundation for further exploration and expansion.
👉 Paper link: https://huggingface.co/papers/2502.14247

27. M3-AGIQA: Multimodal, Multi-Round, Multi-Aspect AI-Generated Image Quality Assessment
🔑 Keywords: AI-generated image, Multimodal Large Language Models, Low-Rank Adaptation, Mean Opinion Scores
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to address challenges in evaluating the quality of AI-generated images by considering multiple dimensions such as perceptual quality, prompt correspondence, and authenticity.
🛠️ Research Methods:
– The study introduces M3-AGIQA, a comprehensive framework that is multimodal, multi-round, and multi-aspect, leveraging Multimodal Large Language Models (MLLMs) and Low-Rank Adaptation (LoRA) for fine-tuning.
💬 Research Conclusions:
– M3-AGIQA achieves state-of-the-art performance in capturing nuanced aspects of AI-generated image quality, confirmed by extensive experiments and cross-dataset validation demonstrating its strong generalizability. Code is available at https://github.com/strawhatboy/M3-AGIQA.
👉 Paper link: https://huggingface.co/papers/2502.15167

28. Diagnosing COVID-19 Severity from Chest X-Ray Images Using ViT and CNN Architectures
🔑 Keywords: Machine Learning, Chest X-rays, COVID-19, Transfer Learning, Vision Transformers
💡 Category: AI in Healthcare
🌟 Research Objective:
– To assess the effectiveness of machine learning models in predicting the severity of COVID-19 from chest x-rays.
🛠️ Research Methods:
– Utilized transfer learning with ImageNet- and CXR-pretrained models and vision transformers (ViTs).
– Developed a large COVID severity dataset by merging data from three sources.
– Conducted severity regression and classification tasks.
💬 Research Conclusions:
– The pretrained DenseNet161 model showed the highest accuracy in a three-class severity prediction, achieving 80% overall accuracy.
– Vision transformers (ViTs) excelled in regression tasks with the lowest mean absolute error compared to radiologist assessments.
– The project’s source code is made publicly accessible.
👉 Paper link: https://huggingface.co/papers/2502.16622

29. Self-Taught Agentic Long Context Understanding
🔑 Keywords: AgenticLU, Chain-of-Clarifications, context retrieval, long-context understanding
💡 Category: Natural Language Processing
🌟 Research Objective:
– Enhance large language models’ ability to answer complex, long-context questions through a framework called Agentic Long-Context Understanding (AgenticLU).
🛠️ Research Methods:
– Implement Chain-of-Clarifications (CoC) for self-generated clarification questions and contextual grounding, using a tree search model with a specific search depth and branching factor.
– Use a two-stage model finetuning process with supervised finetuning and direct preference optimization.
💬 Research Conclusions:
– Demonstrated significant performance improvements over state-of-the-art methods in multi-hop reasoning across various long-context tasks, maintaining consistent quality as context length increases.
👉 Paper link: https://huggingface.co/papers/2502.15920

30. The snake in the Brownian sphere
🔑 Keywords: Brownian sphere, random metric space, Cori–Vauquelin–Schaeffer bijection, Brownian snake, measurable function
💡 Category: Foundations of AI
🌟 Research Objective:
– To describe the inverse of the continuous Cori–Vauquelin–Schaeffer (CVS) bijection by constructing the Brownian snake as a measurable function of the Brownian sphere.
🛠️ Research Methods:
– Utilization of the continuous analogue of the CVS bijection and orientation handling of the Brownian sphere to achieve the construction.
💬 Research Conclusions:
– Successfully mapped the Brownian snake, represented by Aldous’ continuum random tree with Brownian labels, to the Brownian sphere.
👉 Paper link: https://huggingface.co/papers/2502.13074

31. MegaLoc: One Retrieval to Place Them All
🔑 Keywords: MegaLoc, Visual Place Recognition, Landmark Retrieval, Visual Localization
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a retrieval model, MegaLoc, that is effective across multiple computer vision tasks such as Visual Place Recognition, Landmark Retrieval, and Visual Localization.
🛠️ Research Methods:
– Combination of various existing methods, training techniques, and datasets to train the MegaLoc retrieval model.
💬 Research Conclusions:
– MegaLoc achieves state-of-the-art results on numerous Visual Place Recognition datasets.
– It delivers impressive results on common Landmark Retrieval datasets.
– MegaLoc sets a new state-of-the-art for Visual Localization on the LaMAR datasets by modifying the retrieval method in the existing localization pipeline.
👉 Paper link: https://huggingface.co/papers/2502.17237

32. Mind the Gap! Static and Interactive Evaluations of Large Audio Models
🔑 Keywords: AI chatbots, Large Audio Models, voice interaction, user preferences
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The study aims to enhance the alignment of Large Audio Models (LAMs) with user goals by understanding user needs and preferences in voice interaction contexts.
🛠️ Research Methods:
– An interactive approach was used to evaluate LAMs, involving 7,500 interactions collected from 484 participants. Topic modeling was applied to user queries to identify primary use cases.
💬 Research Conclusions:
– The study concludes that no single benchmark strongly correlates with interactive performance, emphasizing the need for more effective LAM evaluation methods that align better with user preferences and provide useful predictors of performance.
👉 Paper link: https://huggingface.co/papers/2502.15919

33. MutaGReP: Execution-Free Repository-Grounded Plan Search for Code-Use
🔑 Keywords: LLM, MutaGReP, code repository, neural tree search, LongCodeArena
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to enhance the ability of language models to complete coding tasks by efficiently providing context from large code repositories, using a method inspired by human navigation abilities.
🛠️ Research Methods:
– The proposed method, MutaGReP, utilizes mutation-guided grounded repository plan search, employing neural tree search in plan space and a symbol retriever for grounding.
💬 Research Conclusions:
– MutaGReP allows plans that use less than 5% of the context window while matching the performance of language models using full repo context. It achieves competitive results on the LongCodeArena benchmark, enabling significant progress on challenging tasks.
👉 Paper link: https://huggingface.co/papers/2502.15872