AI Native Daily Paper Digest – 20250226

1. OmniAlign-V: Towards Enhanced Alignment of MLLMs with Human Preference
🔑 Keywords: Multi-Modal Large Language Models, Human Preference Alignment, Supervised Fine-Tuning, Direct Preference Optimization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Address the gap in alignment of Multi-Modal Large Language Models (MLLMs) with human preferences by introducing OmniAlign-V, a dataset aimed at improving these models’ alignment with human values.
🛠️ Research Methods:
– Utilize OmniAlign-V dataset for finetuning MLLMs through Supervised Fine-Tuning (SFT) or Direct Preference Optimization (DPO).
💬 Research Conclusions:
– Finetuning MLLMs using OmniAlign-V significantly enhances alignment with human preferences while preserving or improving performance on standard Visual Question Answering (VQA) benchmarks.
👉 Paper link: https://huggingface.co/papers/2502.18411

2. SpargeAttn: Accurate Sparse Attention Accelerating Any Model Inference
🔑 Keywords: Sparse Attention, Quadratic Time Complexity, End-to-End Performance, Quantized Attention, Generative Models
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to develop SpargeAttn, a universal sparse and quantized attention mechanism that can enhance both speed and end-to-end performance across various models without being constrained to specific sparse patterns.
🛠️ Research Methods:
– The method introduces a two-stage online filter. The first stage rapidly predicts the attention map to skip unnecessary matrix multiplications. The second stage includes a softmax-aware filter to further optimize computations without additional overhead.
💬 Research Conclusions:
– SpargeAttn significantly accelerates various models, including language, image, and video generation, proving its efficacy without compromising the models’ end-to-end metrics.
👉 Paper link: https://huggingface.co/papers/2502.18137

3. SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution
🔑 Keywords: Reinforcement Learning, Large Language Models, Software Engineering, Llama3-SWE-RL
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To scale the reasoning capabilities of large language models (LLMs) using reinforcement learning (RL) for real-world software engineering tasks.
🛠️ Research Methods:
– Utilization of a lightweight rule-based reward system to train LLMs on software evolution data, enabling autonomous recovery of developer reasoning and solutions.
💬 Research Conclusions:
– Llama3-SWE-RL-70B achieves a 41.0% solve rate on SWE-bench Verified, showcasing the best performance among medium-sized LLMs, with improved general reasoning skills across five out-of-domain tasks compared to supervised-finetuning.
👉 Paper link: https://huggingface.co/papers/2502.18449

4. KV-Edit: Training-Free Image Editing for Precise Background Preservation
🔑 Keywords: KV-Edit, background consistency, image editing, DiT-based generative model
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to overcome the trade-off between preserving original image similarity and aligning with target content in image editing, specifically focusing on maintaining background consistency.
🛠️ Research Methods:
– Introduced a training-free approach called KV-Edit using KV cache in DiTs, preserving background tokens and ensuring seamless content integration without complex mechanisms or expensive training.
💬 Research Conclusions:
– KV-Edit significantly improves background and image quality over existing methods, even outperforming those that require training.
👉 Paper link: https://huggingface.co/papers/2502.17363

5. ART: Anonymous Region Transformer for Variable Multi-Layer Transparent Image Generation
🔑 Keywords: Multi-layer image generation, Anonymous Region Transformer, generative models, schema theory, layer-wise region crop
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces the Anonymous Region Transformer (ART) to facilitate the direct generation of multi-layer transparent images using a global text prompt and anonymous region layout.
🛠️ Research Methods:
– ART employs a layer-wise region crop mechanism that selects visual tokens for each anonymous region, significantly reducing attention computation costs and allowing efficient multi-layer image generation.
💬 Research Conclusions:
– ART outperforms the full attention approach by being over 12 times faster and results in fewer layer conflicts, setting a new paradigm for scalable and precise interactive content creation.
👉 Paper link: https://huggingface.co/papers/2502.18364

6. Unveiling Downstream Performance Scaling of LLMs: A Clustering-Based Perspective
🔑 Keywords: Large Language Models, Emergence Phenomenon, Performance Prediction, Clustering-On-Difficulty, Resource Allocation
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address challenges in predicting downstream task performance of LLMs to improve resource allocation efficiency.
🛠️ Research Methods:
– Introduce a Clustering-On-Difficulty (COD) framework that uses task difficulty features for predicting performance of LLMs efficiently.
💬 Research Conclusions:
– COD demonstrated high predictive accuracy with a 1.36% mean deviation, providing actionable insights for training resource allocation in 70B LLM with an ensemble of small models.
👉 Paper link: https://huggingface.co/papers/2502.17262

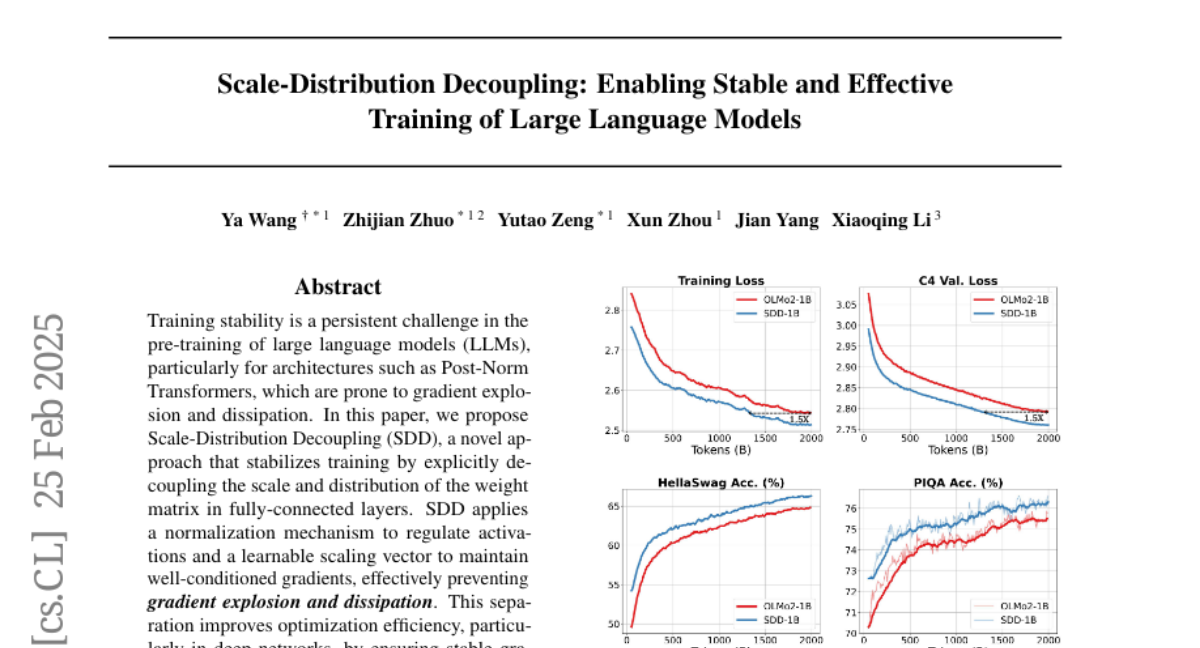
7. Scale-Distribution Decoupling: Enabling Stable and Effective Training of Large Language Models
🔑 Keywords: Training Stability, Large Language Models, Scale-Distribution Decoupling, Gradient Propagation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address training stability issues in the pre-training of large language models, specifically with architectures such as Post-Norm Transformers.
🛠️ Research Methods:
– A novel approach called Scale-Distribution Decoupling (SDD) is proposed, which stabilizes training by decoupling the scale and distribution of weight matrices and applying a normalization mechanism to regulate activations.
💬 Research Conclusions:
– The SDD method improves optimization efficiency in deep networks by ensuring stable gradient propagation and outperforms existing techniques in various normalization configurations, proving to be lightweight and compatible with current frameworks.
👉 Paper link: https://huggingface.co/papers/2502.15499
8. K-LoRA: Unlocking Training-Free Fusion of Any Subject and Style LoRAs
🔑 Keywords: LoRA, K-LoRA, diffusion models, training-free, fusion approach
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to explore a training-free approach for effectively merging learned subject and style using LoRA’s intrinsic properties.
🛠️ Research Methods:
– The proposed method, K-LoRA, uses a Top-K selection mechanism in each attention layer to ensure optimal fusion of LoRAs by retaining representative features of both subject and style.
💬 Research Conclusions:
– K-LoRA successfully integrates subject and style information without additional training, outperforming state-of-the-art methods in both qualitative and quantitative evaluations.
👉 Paper link: https://huggingface.co/papers/2502.18461

9. Curie: Toward Rigorous and Automated Scientific Experimentation with AI Agents
🔑 Keywords: AI Agent, Experimentation Rigor, Interpretability, Large Language Models
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop Curie, an AI agent framework aimed at embedding rigor into the scientific experimentation process via reliability, methodical control, and interpretability.
🛠️ Research Methods:
– Utilized a novel experimental benchmark with 46 questions from four computer science domains, based on influential research papers and open-source projects.
💬 Research Conclusions:
– Curie demonstrates a 3.4 times improvement in correctly answering experimental questions compared to the strongest baseline, showcasing enhanced performance in automating rigorous experimentation.
👉 Paper link: https://huggingface.co/papers/2502.16069

10. WebGames: Challenging General-Purpose Web-Browsing AI Agents
🔑 Keywords: WebGames, AI Systems, Cognitive Tasks, Vision-Language Models, AI Systems and Tools
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The primary goal of the study was to introduce WebGames, a benchmark suite designed to evaluate general-purpose web-browsing AI agents through a series of 50+ interactive challenges that test AI limitations in web interactions.
🛠️ Research Methods:
– The study employed a hermetic testing environment to ensure reproducible evaluation of AI models like GPT-4o and others, comparing their performance to human benchmarks across fundamental browser interactions and cognitive tasks.
💬 Research Conclusions:
– Results indicated a notable capability gap, with the best AI system achieving a 43.1% success rate against human performance at 95.7%, showcasing significant limitations in current AI systems’ abilities to understand intuitive web interaction patterns.
👉 Paper link: https://huggingface.co/papers/2502.18356

11. Introducing Visual Perception Token into Multimodal Large Language Model
🔑 Keywords: Multimodal Large Language Model, Visual Perception Token, Region Selection Token, Vision Re-Encoding Token, Spatial Reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance the control of visual perception processes within Multimodal Large Language Models (MLLM) using Visual Perception Tokens.
🛠️ Research Methods:
– Introduction of two types of Visual Perception Tokens: Region Selection Token and Vision Re-Encoding Token, to enable autonomous generation and control of visual perception.
💬 Research Conclusions:
– The addition of Visual Perception Tokens improved the performance of a multimodal model significantly, increasing spatial reasoning and fine-grained understanding capabilities, outperforming larger models with fewer parameters.
👉 Paper link: https://huggingface.co/papers/2502.17425

12. AAD-LLM: Neural Attention-Driven Auditory Scene Understanding
🔑 Keywords: Auditory Attention-Driven LLM, Intention-Informed Auditory Scene Understanding, brain signals, perception-aligned responses, iEEG recordings
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces Intention-Informed Auditory Scene Understanding (II-ASU) to better align auditory models with human selective perception, proposing a prototype system, the Auditory Attention-Driven LLM, which integrates brain signals to decode listener attention.
🛠️ Research Methods:
– The research extends auditory large language models by incorporating intracranial electroencephalography (iEEG) to infer speaker attention, conditioning response generation based on this attentional state.
💬 Research Conclusions:
– The model shows improved perception-aligned performance in multitalker scenarios across tasks such as speaker description, speech transcription, and question answering, indicating a promising direction for listener-centered auditory systems.
👉 Paper link: https://huggingface.co/papers/2502.16794

13. The Lottery LLM Hypothesis, Rethinking What Abilities Should LLM Compression Preserve?
🔑 Keywords: LLMs, model compression, KV cache compression, computational expressivity, retrieval-augmented generation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore advancements in model and KV cache compression for reducing computational and storage costs of LLMs while maintaining performance.
🛠️ Research Methods:
– Review of recent improvements related to retrieval-augmented generation, multi-step reasoning, and use of external tools in LLMs.
💬 Research Conclusions:
– Proposes a lottery LLM hypothesis indicating smaller LLMs can achieve similar performance as original LLMs using multi-step reasoning and external tools; identifies overlooked capabilities needed in lottery LLM and KV cache compression.
👉 Paper link: https://huggingface.co/papers/2502.17535

14. Finding the Sweet Spot: Preference Data Construction for Scaling Preference Optimization
🔑 Keywords: Iterative data generation, Model retraining, Large Language Models (LLMs), Direct Preference Optimization (DPO), Preference data construction
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance alignment performance of large language models by optimizing preference data construction via iterative data generation and model retraining.
🛠️ Research Methods:
– Employ repeated random sampling to increase on-policy samples and investigate preference data construction using the normal distribution of sample rewards, exploring all 21 pairwise combinations of categorized reward space.
💬 Research Conclusions:
– Optimal performance is achieved by selecting the rejected response at reward position mu – 2sigma rather than the minimum reward, introducing a scalable strategy that enhances model performance as sample scale increases.
👉 Paper link: https://huggingface.co/papers/2502.16825

15. Prompt-to-Leaderboard
🔑 Keywords: Large Language Model, Leaderboard, Prompt-dependent, Unsupervised Evaluation, Chatbot Arena
💡 Category: Natural Language Processing
🌟 Research Objective:
– To address the limitations of averaged metrics in LLM evaluations by introducing a method for prompt-specific evaluations.
🛠️ Research Methods:
– Introducing the Prompt-to-Leaderboard (P2L) method to generate leaderboards for specific prompts using Bradley-Terry coefficients for predicting human preferences.
💬 Research Conclusions:
– P2L effectively captures variations in language model performance specific to prompts and achieves better evaluations than averaged leaderboards. The methodology’s efficacy is demonstrated by achieving the top position in the Chatbot Arena leaderboard in January 2025.
👉 Paper link: https://huggingface.co/papers/2502.14855

16. Shakti-VLMs: Scalable Vision-Language Models for Enterprise AI
🔑 Keywords: Shakti VLM, Multimodal Learning, Vision-Language Models, Data Efficiency, Architectural Innovations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address data efficiency challenges in multimodal learning using vision-language models with 1B and 4B parameters.
🛠️ Research Methods:
– Introduced architectural innovations like QK-Normalization, hybrid normalization techniques, and enhanced positional encoding, along with a three-stage training strategy.
💬 Research Conclusions:
– Shakti VLM models achieve high performance in document understanding, visual reasoning, OCR extraction, and general multimodal reasoning with fewer tokens, offering an efficient solution for large-scale multimodal tasks.
👉 Paper link: https://huggingface.co/papers/2502.17092

17. LaTIM: Measuring Latent Token-to-Token Interactions in Mamba Models
🔑 Keywords: State space models, Mamba, interpretability, LaTIM, token-level decomposition
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce a novel token-level decomposition method (LaTIM) for Mamba models to enhance interpretability.
🛠️ Research Methods:
– Evaluate LaTIM across diverse tasks like machine translation, copying, and retrieval-based generation.
💬 Research Conclusions:
– LaTIM effectively reveals Mamba’s token-to-token interaction patterns, contributing to a better understanding of its processing across layers.
👉 Paper link: https://huggingface.co/papers/2502.15612

18. An Overview of Large Language Models for Statisticians
🔑 Keywords: Large Language Models, AI Native, Uncertainty Quantification, Interpretability, Trustworthiness
💡 Category: Natural Language Processing
🌟 Research Objective:
– The primary aim is to explore how statisticians can enhance the development of Large Language Models (LLMs) with a focus on trustworthiness and transparency.
🛠️ Research Methods:
– The exploration includes bridging AI with statistics by addressing issues such as uncertainty quantification, interpretability, fairness, privacy, and model adaptation.
💬 Research Conclusions:
– By integrating statistical insights, the research seeks to advance both theoretical foundations and practical applications of LLMs, ultimately contributing to their role in tackling complex societal challenges.
👉 Paper link: https://huggingface.co/papers/2502.17814

19. MLLMs Know Where to Look: Training-free Perception of Small Visual Details with Multimodal LLMs
🔑 Keywords: Multimodal Large Language Models, Visual Recognition, Attention Patterns, Visual Question Answering, Visual Intervention
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To investigate the ability of Multimodal Large Language Models (MLLMs) in perceiving small visual details compared to larger ones.
🛠️ Research Methods:
– Conducted an intervention study to assess the performance sensitivity of MLLMs to the size of visual subjects and studied attention patterns during visual question answering.
💬 Research Conclusions:
– Proposed training-free visual intervention methods utilizing attention and gradient maps, significantly enhancing MLLMs’ accuracy on small visual details without additional training.
👉 Paper link: https://huggingface.co/papers/2502.17422

20. Scaling LLM Pre-training with Vocabulary Curriculum
🔑 Keywords: Vocabulary Curriculum Learning, Pretraining Efficiency, Dynamic Tokenization
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to introduce an approach called Vocabulary Curriculum Learning to enhance pretraining efficiency in language models by addressing the limitations of static vocabularies.
🛠️ Research Methods:
– The researchers employ entropy-guided vocabulary expansion in tandem with model optimization, enabling adaptive learning across diverse tokenization granularities.
💬 Research Conclusions:
– The study demonstrates improved scaling efficiency in small-scale GPT models, showcasing the benefits of dynamic tokenization and promising extensions to larger models and various domains.
👉 Paper link: https://huggingface.co/papers/2502.17910

21. WiCkeD: A Simple Method to Make Multiple Choice Benchmarks More Challenging
🔑 Keywords: WiCkeD, Multiple-choice benchmarks, Educational tests, Open-weight LLMs, Chain-of-thought
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to enhance the complexity of existing multiple-choice benchmarks by implementing a method called WiCkeD, which introduces a “None of the above” option similar to educational tests.
🛠️ Research Methods:
– WiCkeD was automatically applied to six popular benchmarks and evaluated across 18 open-weight LLMs. The performance impact was additionally tested using a chain-of-thought approach on MMLU datasets.
💬 Research Conclusions:
– On average, model performance decreased by 12.1 points when WiCkeD was applied, indicating increased difficulty. The method demonstrated that enhanced reasoning abilities are required, thereby exposing models’ sensitivity to additional reasoning demands. The code and data for WiCkeD have been released publicly.
👉 Paper link: https://huggingface.co/papers/2502.18316

22. LDGen: Enhancing Text-to-Image Synthesis via Large Language Model-Driven Language Representation
🔑 Keywords: LDGen, Large Language Models, Multilingual Processing, Zero-shot Multilingual Image Generation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To integrate large language models into existing text-to-image diffusion models while minimizing computational demands and enabling effective multilingual image generation.
🛠️ Research Methods:
– Utilizing a language representation strategy that incorporates hierarchical caption optimization and human instruction techniques. Employing a lightweight adapter and cross-modal refiner for efficient feature alignment between language and image features.
💬 Research Conclusions:
– LDGen surpasses baseline models in terms of prompt adherence and image aesthetic quality, with the added capability of seamless support for multiple languages and reduced training time.
👉 Paper link: https://huggingface.co/papers/2502.18302
