AI Native Daily Paper Digest – 20250327

1. Qwen2.5-Omni Technical Report
🔑 Keywords: Multimodal model, End-to-end, Thinker-Talker architecture, TMRoPE, Streaming
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to develop Qwen2.5-Omni, an advanced end-to-end multimodal model capable of perceiving and generating text and speech from various modalities, including text, images, audio, and video.
🛠️ Research Methods:
– Utilizes a block-wise processing approach for audio and visual encoders, an interleaved manner for audio-video synchronization, and introduces the TMRoPE for position embedding.
– Employs the novel Thinker-Talker architecture to concurrently generate text and speech without interference.
– Introduces a sliding-window DiT for streaming audio token decoding to reduce initial package delay.
💬 Research Conclusions:
– Qwen2.5-Omni achieves state-of-the-art performance on multimodal benchmarks like Omni-Bench and excels in end-to-end speech instruction following.
– The model outperforms alternative models in streaming speech generation regarding robustness and naturalness.
👉 Paper link: https://huggingface.co/papers/2503.20215

2. Dita: Scaling Diffusion Transformer for Generalist Vision-Language-Action Policy
🔑 Keywords: Transformer architectures, in-context conditioning, action deltas, long-horizon tasks
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper presents “Dita,” a scalable framework designed to enhance adaptability to heterogeneous action spaces in vision-language-action models.
🛠️ Research Methods:
– Utilizes Transformer architectures to denoise continuous action sequences via a unified multimodal diffusion process.
– Implements in-context conditioning for fine-grained alignment between denoised actions and raw visual tokens.
💬 Research Conclusions:
– Demonstrates state-of-the-art performance on extensive benchmarks, showing robust adaptation to environmental variances and successful execution of complex long-horizon tasks.
– Dita offers a versatile, lightweight, and open-source baseline for generalist robot policy learning.
👉 Paper link: https://huggingface.co/papers/2503.19757
3. Wan: Open and Advanced Large-Scale Video Generative Models
🔑 Keywords: diffusion transformer, VAE, scaling laws, image-to-video, automated evaluation metrics
💡 Category: Generative Models
🌟 Research Objective:
– To develop Wan, a suite of video foundation models to advance video generation capabilities.
🛠️ Research Methods:
– Utilization of mainstream diffusion transformer paradigm, novel VAE, and large-scale data curation for scalable pre-training strategies.
– Implementation of automated evaluation metrics to enhance model performance and versatility.
💬 Research Conclusions:
– Wan exhibits superior performance over existing open-source and commercial models, especially the 14B model trained on billions of images and videos.
– Wan supports various applications like image-to-video transformation and personal video generation, featuring models with 1.3B and 14B parameters.
– The project embraces openness by providing source code and models to the community, aiming to foster video generation innovation.
👉 Paper link: https://huggingface.co/papers/2503.20314

4. LEGO-Puzzles: How Good Are MLLMs at Multi-Step Spatial Reasoning?
🔑 Keywords: Multi-step spatial reasoning, Multimodal Large Language Models (MLLMs), LEGO-Puzzles, spatial understanding, sequential reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to evaluate the spatial understanding and sequential reasoning capabilities of Multimodal Large Language Models (MLLMs) using a benchmark named LEGO-Puzzles.
🛠️ Research Methods:
– LEGO-Puzzles, a scalable benchmark comprising 1,100 visual question-answering samples across 11 tasks, was used to test MLLMs and evaluate their ability to understand and process spatial relationships.
💬 Research Conclusions:
– The study finds significant limitations in the spatial reasoning abilities of current MLLMs, with humans outperforming these models. It also highlights the restricted ability of models like Gemini-2.0-Flash and GPT-4o to generate LEGO images following assembly instructions accurately, underscoring the necessity for advancements in multimodal spatial reasoning.
👉 Paper link: https://huggingface.co/papers/2503.19990

5. Open Deep Search: Democratizing Search with Open-source Reasoning Agents
🔑 Keywords: Open Deep Search, reasoning agents, Open Search Tool, open-source LLMs
💡 Category: Natural Language Processing
🌟 Research Objective:
– To bridge the gap between proprietary search AI solutions and their open-source counterparts by introducing Open Deep Search (ODS), which augments open-source LLMs with reasoning agents.
🛠️ Research Methods:
– The implementation of ODS involves two main components: the Open Reasoning Agent, which orchestrates tasks and actions, and the Open Search Tool, a novel web search tool outperforming proprietary alternatives.
💬 Research Conclusions:
– ODS nearly matches and often surpasses the state-of-the-art baselines in benchmarks, enhancing existing models’ performance, exemplified by a 9.7% accuracy improvement on the FRAMES evaluation benchmark.
👉 Paper link: https://huggingface.co/papers/2503.20201

6. Gemma 3 Technical Report
🔑 Keywords: Gemma 3, multimodal, vision understanding, languages, architecture
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Gemma 3 with enhanced vision understanding and increased language support.
🛠️ Research Methods:
– Implement local and global attention layers to optimize KV-cache memory and employ distillation for training.
💬 Research Conclusions:
– Gemma 3 achieves significant improvements in math, chat, instruction-following, and multilingual tasks, surpassing previous models and performing competitively with larger models.
👉 Paper link: https://huggingface.co/papers/2503.19786

7. Unconditional Priors Matter! Improving Conditional Generation of Fine-Tuned Diffusion Models
🔑 Keywords: Classifier-Free Guidance, conditional diffusion models, noise prediction, unconditional noise, fine-tuning
💡 Category: Generative Models
🌟 Research Objective:
– To investigate the impact of joint learning of conditional and unconditional noise on model performance in conditional diffusion models and propose a method to improve conditional generation quality.
🛠️ Research Methods:
– Replacing unconditional noise in Classifier-Free Guidance with noise predicted by a base model.
– Employing different diffusion models for noise replacement in various CFG-based conditional models.
💬 Research Conclusions:
– Using a base model’s unconditional noise predictions significantly improves the quality of conditional generation.
– The method is validated across multiple CFG-based models, demonstrating its effectiveness in enhancing image and video generation.
👉 Paper link: https://huggingface.co/papers/2503.20240

8. Gemini Robotics: Bringing AI into the Physical World
🔑 Keywords: Gemini Robotics, Vision-Language-Action, Robotics Applications, Multimodal Models, Embodied Reasoning
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce Gemini Robotics, a new family of AI models designed for robotics, built on Gemini 2.0 to control physical agents effectively.
🛠️ Research Methods:
– Develop and fine-tune a Vision-Language-Action generalist model that enables smooth and reactive robot control and adaptation to new tasks and embodiments.
💬 Research Conclusions:
– The Gemini Robotics models exhibit advanced capabilities in handling diverse tasks, environmental variations, and safety considerations, marking progress toward general-purpose robots in the physical world.
👉 Paper link: https://huggingface.co/papers/2503.20020

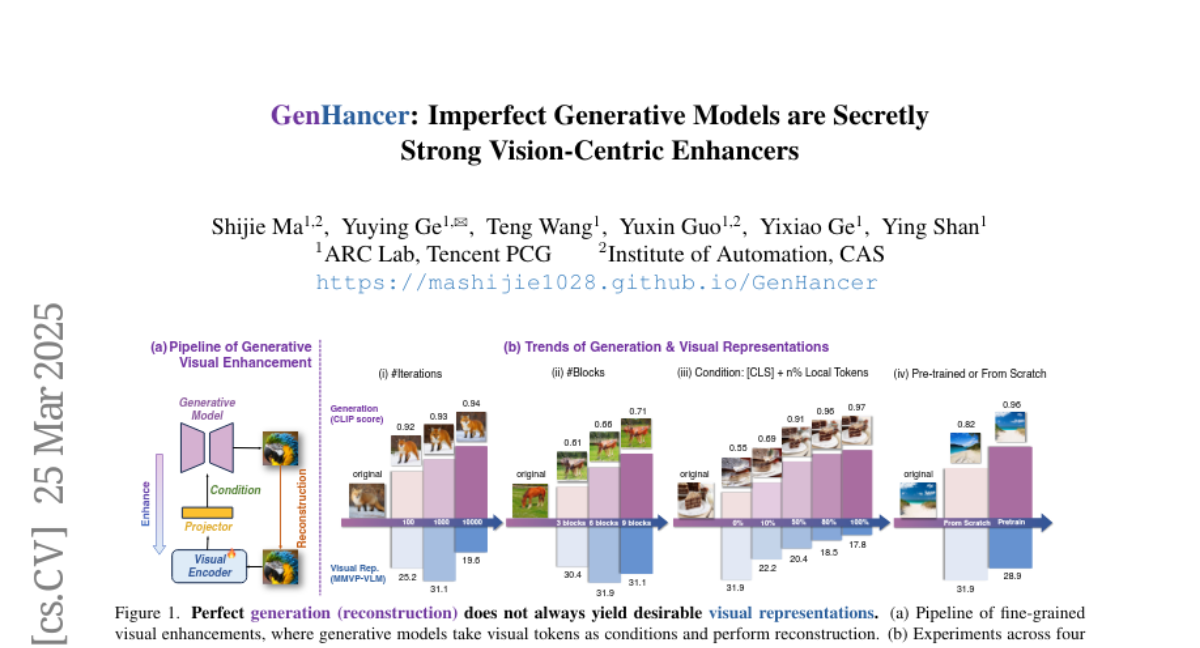
9. GenHancer: Imperfect Generative Models are Secretly Strong Vision-Centric Enhancers
🔑 Keywords: Generative models, Discriminative models, CLIP, GenHancer, Denoising configurations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This study evaluates the synergy between generative and discriminative models, focusing on extracting fine-grained knowledge while reducing irrelevant information for representation enhancement.
🛠️ Research Methods:
– The research examines three factors: conditioning mechanisms, denoising configurations, and generation paradigms. It proposes using global visual tokens to avoid training collapse, a two-stage training strategy with lightweight denoisers, and evaluates continuous and discrete denoisers.
💬 Research Conclusions:
– The study presents GenHancer, a method that outperforms previous models on the MMVP-VLM benchmark with significant improvements. The enhanced CLIP model can be integrated into multimodal large language models to augment vision-centric performance, with models and codes available publicly.
👉 Paper link: https://huggingface.co/papers/2503.19480
10. BizGen: Advancing Article-level Visual Text Rendering for Infographics Generation
🔑 Keywords: text-to-image generation, business content, infographics, ultra-dense layouts
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to advance article-level visual text rendering for generating high-quality business content such as infographics and slides based on descriptive prompts and ultra-dense layouts.
🛠️ Research Methods:
– Development of the Infographics-650K dataset with ultra-dense layouts.
– Implementation of a layout-guided cross attention scheme that manages multiple region-wise prompts for refining sub-regions during inference.
💬 Research Conclusions:
– The proposed system demonstrates superior results over existing models like Flux and SD3 when tested on the BizEval prompt set.
– Ablation experiments confirmed the effectiveness of each component of the system.
👉 Paper link: https://huggingface.co/papers/2503.20672

11. LogQuant: Log-Distributed 2-Bit Quantization of KV Cache with Superior Accuracy Preservation
🔑 Keywords: LogQuant, KV Cache, large language model, quantization, throughput
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce LogQuant, a 2-bit quantization technique for KV Cache to enhance large language model inference by reducing memory usage and maintaining performance.
🛠️ Research Methods:
– Utilizes a novel log-based filtering mechanism to selectively compress the KV Cache, achieving better performance with equal or reduced memory footprint.
💬 Research Conclusions:
– LogQuant increases throughput by 25% and batch size by 60% without additional memory consumption.
– Improves accuracy by 40% to 200% in tasks like Math and Code Completion at the same compression ratio.
– Seamlessly integrates with popular inference frameworks, e.g., Python’s transformers library.
👉 Paper link: https://huggingface.co/papers/2503.19950

12. MCTS-RAG: Enhancing Retrieval-Augmented Generation with Monte Carlo Tree Search
🔑 Keywords: MCTS-RAG, retrieval-augmented generation, Monte Carlo Tree Search, reasoning, factual accuracy
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce MCTS-RAG to enhance reasoning capabilities of small language models on knowledge-intensive tasks.
🛠️ Research Methods:
– Integrate retrieval-augmented generation with Monte Carlo Tree Search for adaptive retrieval and structured reasoning.
💬 Research Conclusions:
– MCTS-RAG improves decision-making, reduces hallucinations, enhances factual accuracy, and ensures response consistency. It shows that small-scale models can achieve performance comparable to advanced models like GPT-4 on reasoning tasks, establishing a new standard for reasoning in small-scale models.
👉 Paper link: https://huggingface.co/papers/2503.20757

13. ViLBench: A Suite for Vision-Language Process Reward Modeling
🔑 Keywords: Process-supervised reward models, Vision large language models, Chain-of-Thought, Vision-language benchmarks
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to evaluate process-supervised reward models (PRMs) specifically in the context of multimodal tasks, addressing the gap in existing evaluations.
🛠️ Research Methods:
– Introduction of ViLBench, a vision-language benchmark, to evaluate model performance requiring detailed process reward signals.
– Collection of 73.6K vision-language process reward data using an enhanced tree-search algorithm to bridge the gap between general VLLMs and reward models.
💬 Research Conclusions:
– Current vision large language models like GPT-4o with Chain-of-Thought struggle on ViLBench, achieving only 27.3% accuracy, highlighting the benchmark’s difficulty.
– The proposed 3B model shows improvement over standard CoT, with an average accuracy increase of 3.3% on ViLBench by effectively leveraging the OpenAI o1 generations.
👉 Paper link: https://huggingface.co/papers/2503.20271
14. AccVideo: Accelerating Video Diffusion Model with Synthetic Dataset
🔑 Keywords: Diffusion models, Iterative denoising, Inference steps, AccVideo, Synthetic dataset
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to address the inefficiencies of existing diffusion models for video generation by reducing the number of inference steps required.
🛠️ Research Methods:
– Proposes AccVideo, a novel method utilizing a synthetic dataset to guide video diffusion models to fewer denoising steps.
– Leverages pretrained video diffusion models and introduces trajectory-based few-step guidance.
– Implements an adversarial training strategy to align output distribution with synthetic dataset.
💬 Research Conclusions:
– The proposed method achieves 8.5x faster video generation speeds compared to traditional models while maintaining high quality and resolution.
– AccVideo outperforms previous acceleration methods, delivering videos with higher quality at 5-seconds, 720×1280, 24fps.
👉 Paper link: https://huggingface.co/papers/2503.19462

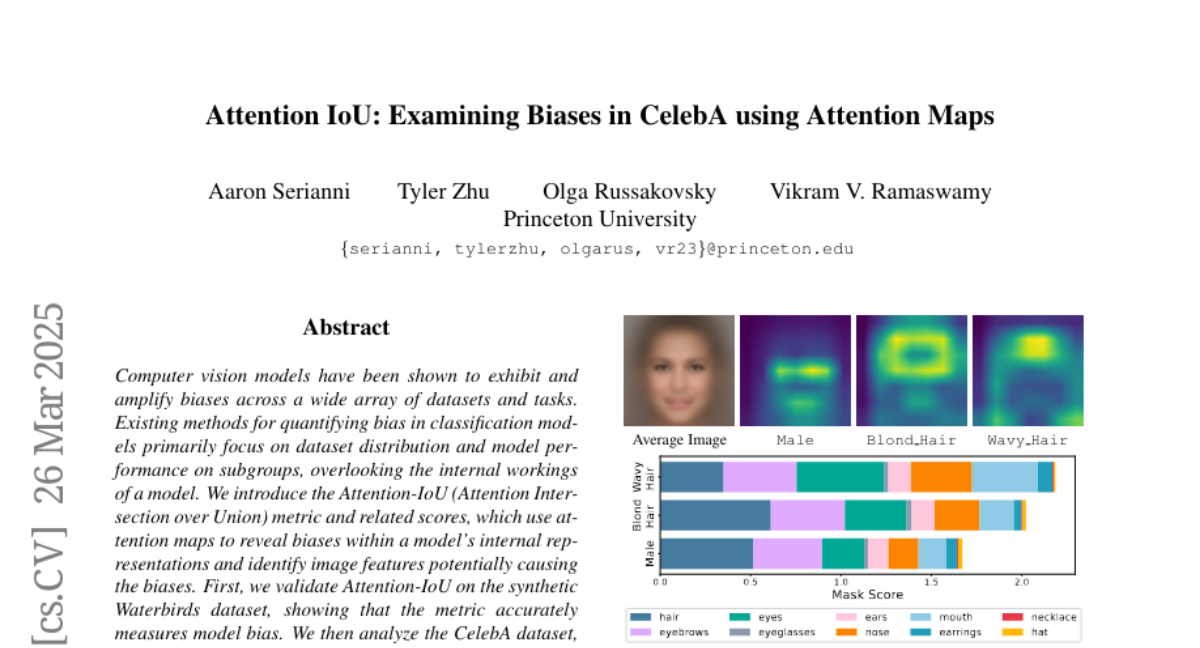
15. Attention IoU: Examining Biases in CelebA using Attention Maps
🔑 Keywords: AI Ethics and Fairness, Attention-IoU, Computer Vision, Bias, Attention Maps
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– Introduce the Attention-IoU metric to reveal and quantify biases in computer vision models.
🛠️ Research Methods:
– Validated the Attention-IoU on the Waterbirds dataset and analyzed the CelebA dataset to uncover hidden biases and attribute correlations.
💬 Research Conclusions:
– The Attention-IoU metric is effective in measuring biases and identifies potential confounding variables not indicated by dataset labels.
👉 Paper link: https://huggingface.co/papers/2503.19846
16. ADS-Edit: A Multimodal Knowledge Editing Dataset for Autonomous Driving Systems
🔑 Keywords: Large Multimodal Models, Autonomous Driving Systems, Knowledge Editing, ADS-Edit
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Explore the use of Knowledge Editing to improve Large Multimodal Models’ application in Autonomous Driving Systems.
🛠️ Research Methods:
– Propose and utilize ADS-Edit, a multimodal knowledge editing dataset, to address challenges in ADS.
💬 Research Conclusions:
– The study provides interesting conclusions and aims to advance knowledge editing applications in autonomous driving.
👉 Paper link: https://huggingface.co/papers/2503.20756

17. Sparse Logit Sampling: Accelerating Knowledge Distillation in LLMs
🔑 Keywords: Knowledge Distillation, Large Language Models, Teacher Output Logits, Importance Sampling, Random Sampling Knowledge Distillation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study investigates applying knowledge distillation to pre-training with a focus on addressing the biases introduced by naive sparse methods.
🛠️ Research Methods:
– The research introduces Random Sampling Knowledge Distillation, which employs importance sampling to provide unbiased estimates and efficient storage of sparser logits.
💬 Research Conclusions:
– The proposed method allows faster training of student models with minimal overhead and achieves competitive performance akin to full distillation across various model sizes.
👉 Paper link: https://huggingface.co/papers/2503.16870

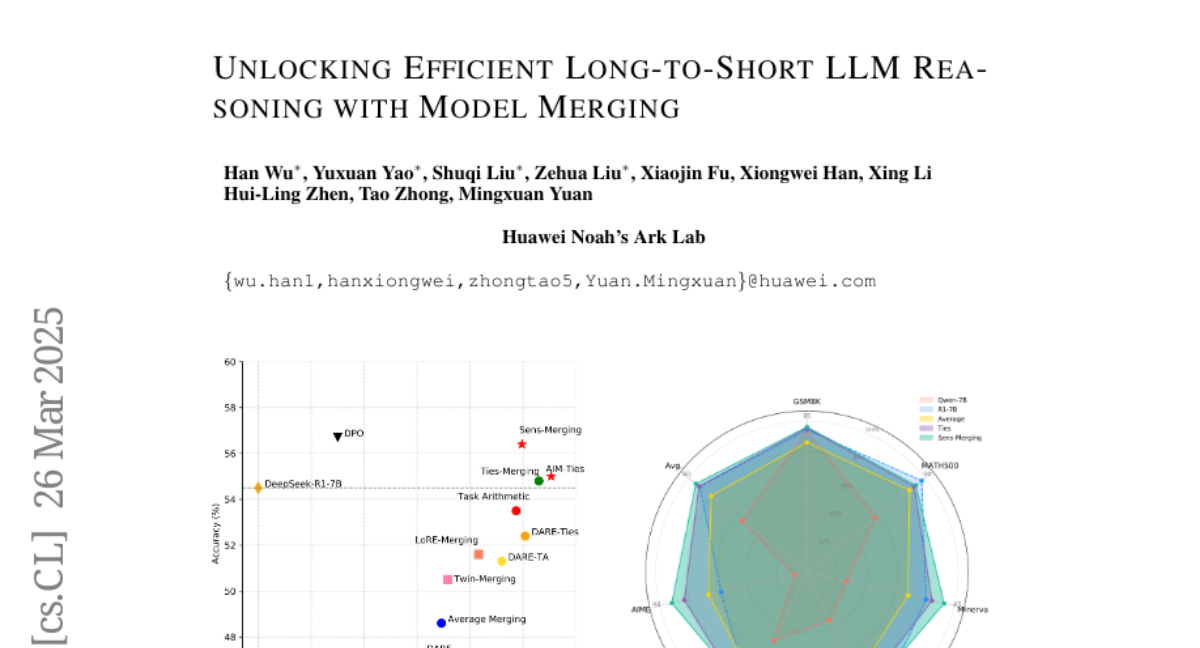
18. Unlocking Efficient Long-to-Short LLM Reasoning with Model Merging
🔑 Keywords: System 1, System 2, Model Merging, L2S Reasoning, Overthinking
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address inefficiencies in large language models by transitioning from System 1 to System 2 reasoning through L2S Reasoning and exploring model merging to enhance efficiency without sacrificing output quality.
🛠️ Research Methods:
– The paper investigates diverse model merging methodologies, including task-vector-based, SVD-based, and activation-informed merging, to integrate reasoning capabilities of different systems.
💬 Research Conclusions:
– Model merging can effectively reduce response length by up to 55%, maintain or improve performance, and offers a solution to the overthinking problem while retaining the robustness of System 2 reasoning.
👉 Paper link: https://huggingface.co/papers/2503.20641
19. Image as an IMU: Estimating Camera Motion from a Single Motion-Blurred Image
🔑 Keywords: motion blur, camera pose estimation, motion flow field, linear least squares problem, real-world benchmarks
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a novel framework that uses motion blur as a cue for improving camera pose estimation.
🛠️ Research Methods:
– Predicts a dense motion flow field and monocular depth map from a single motion-blurred image.
– Utilizes a linear least squares problem under the small motion assumption for recovering instantaneous camera velocity.
💬 Research Conclusions:
– The framework achieves state-of-the-art angular and translational velocity estimates, outperforming methods like MASt3R and COLMAP.
👉 Paper link: https://huggingface.co/papers/2503.17358
20. Beyond Words: Advancing Long-Text Image Generation via Multimodal Autoregressive Models
🔑 Keywords: Autoregressive Models, Diffusion Models, Image Tokenizer, Long Text Image Generation, Multimodal
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to address the challenge in generating coherent long-form text in images, such as paragraphs in slides or documents, which current models struggle with.
🛠️ Research Methods:
– The authors introduced a novel, text-focused binary tokenizer optimized for capturing detailed scene text features, and developed \ModelName, a multimodal autoregressive model designed to generate high-quality long-text images.
💬 Research Conclusions:
– \ModelName significantly outperforms existing models like SD3.5 Large and GPT4o with DALL-E 3 in generating long text accurately and consistently. It opens up new possibilities for innovative applications, including interleaved document and PowerPoint generation.
👉 Paper link: https://huggingface.co/papers/2503.20198

21. DINeMo: Learning Neural Mesh Models with no 3D Annotations
🔑 Keywords: Neural Mesh Models, 3D Pose Estimation, Pseudo-Correspondence, Unlabeled Images, AI Native
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a novel neural mesh model, DINeMo, that performs category-level 3D/6D pose estimation without relying on 3D annotations.
🛠️ Research Methods:
– Utilizes a bidirectional pseudo-correspondence generation method leveraging both local appearance features and global context information from large visual foundation models.
💬 Research Conclusions:
– DINeMo outperforms previous zero- and few-shot 3D pose estimation methods, significantly narrowing the performance gap with fully-supervised methods by 67.3%.
– The model scales effectively and efficiently, especially when incorporating more unlabeled images during training, underscoring its advantages over methods reliant on 3D annotations.
👉 Paper link: https://huggingface.co/papers/2503.20220

22. Trajectory Balance with Asynchrony: Decoupling Exploration and Learning for Fast, Scalable LLM Post-Training
🔑 Keywords: Reinforcement learning, LLM post-training, Trajectory Balance with Asynchrony, off-policy data, central replay buffer
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to address the incompatibility of current on-policy algorithms with experience replay buffers in the context of LLM post-training by proposing a scalable RL system called Trajectory Balance with Asynchrony (TBA).
🛠️ Research Methods:
– Introduces TBA, which utilizes a larger fraction of compute on search and employs a central replay buffer for off-policy data sampling, enhancing the training with Trajectory Balance.
💬 Research Conclusions:
– TBA accelerates training time by decoupling training and search, improves diversity through large-scale sampling, and is effective in sparse reward settings, yielding improvements in speed and performance on tasks like mathematical reasoning, preference-tuning, and automated red-teaming.
👉 Paper link: https://huggingface.co/papers/2503.18929

23. Self-Supervised Learning of Motion Concepts by Optimizing Counterfactuals
🔑 Keywords: Motion Estimation, Self-Supervised Learning, Occlusion Estimation, Next-Frame Prediction Model, AI Native
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a self-supervised technique, Opt-CWM, for flow and occlusion estimation in videos without using labeled data or fixed heuristics.
🛠️ Research Methods:
– Utilization of counterfactual probes to extract motion information from a pre-trained next-frame prediction model, trained on unrestricted video inputs.
💬 Research Conclusions:
– Opt-CWM achieves state-of-the-art performance for motion estimation on real-world videos, enhancing the capabilities of models in real-world contexts.
👉 Paper link: https://huggingface.co/papers/2503.19953

24. RONA: Pragmatically Diverse Image Captioning with Coherence Relations
🔑 Keywords: Writing Assistants, Pragmatic Diversity, Multi-modal Large Language Models, Coherence Relations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Enhance pragmatic diversity in writing assistants by exploring alternative ways to convey central messages alongside visual descriptions.
🛠️ Research Methods:
– Introduce RONA, a novel prompting strategy for Multi-modal Large Language Models utilizing Coherence Relations for varied caption generation.
💬 Research Conclusions:
– RONA significantly improves the diversity and ground-truth alignment of generated captions compared to existing MLLM baselines across multiple domains.
👉 Paper link: https://huggingface.co/papers/2503.10997

25. UniHDSA: A Unified Relation Prediction Approach for Hierarchical Document Structure Analysis
🔑 Keywords: Document Structure Analysis, Hierarchical Document Structure Analysis, Unified Relation Prediction, Transformer Architectures, Multimodal End-to-end System
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study focuses on improving Hierarchical Document Structure Analysis (HDSA) by proposing a unified relation prediction approach named UniHDSA, which aims to treat various HDSA sub-tasks as relation prediction problems in a consolidated label space.
🛠️ Research Methods:
– The researchers developed a multimodal end-to-end system based on Transformer architectures to implement the proposed UniHDSA approach for both page-level and document-level structure analysis.
💬 Research Conclusions:
– Experimental results show that UniHDSA achieves state-of-the-art performance on the hierarchical document structure analysis benchmark, Comp-HRDoc, and competitive results on the document layout analysis dataset, DocLayNet, demonstrating its effectiveness across all sub-tasks.
👉 Paper link: https://huggingface.co/papers/2503.15893

26. PathoHR: Breast Cancer Survival Prediction on High-Resolution Pathological Images
🔑 Keywords: Tumor heterogeneity, Whole slide images (WSIs), Vision Transformer (ViT), Feature learning
💡 Category: AI in Healthcare
🌟 Research Objective:
– To develop a novel pipeline, PathoHR, for improving breast cancer survival prediction by enhancing feature learning from pathological images.
🛠️ Research Methods:
– Utilization of a high-resolution Vision Transformer for detailed feature extraction and evaluation of advanced similarity metrics to optimize representation learning.
💬 Research Conclusions:
– PathoHR enhances the accuracy of survival prediction by integrating improved image resolution with optimized feature learning, providing an efficient approach for computational pathology.
👉 Paper link: https://huggingface.co/papers/2503.17970

27. RecTable: Fast Modeling Tabular Data with Rectified Flow
🔑 Keywords: diffusion models, tabular data, GAN-based, VAE-based, rectified flow modeling
💡 Category: Generative Models
🌟 Research Objective:
– The objective of the study is to develop RecTable, a new approach utilizing rectified flow modeling to efficiently generate high-quality tabular data.
🛠️ Research Methods:
– RecTable consists of a simple architecture with stacked gated linear unit blocks, and employs mixed-type noise distribution and logit-normal timestep distribution for training.
💬 Research Conclusions:
– RecTable demonstrates competitive performance compared to state-of-the-art diffusion and score-based models and significantly reduces the required training time.
👉 Paper link: https://huggingface.co/papers/2503.20731

28.
