AI Native Daily Paper Digest – 20250331

1. AdaptiVocab: Enhancing LLM Efficiency in Focused Domains through Lightweight Vocabulary Adaptation
🔑 Keywords: Large Language Models, domain adaptation, vocabulary adaptation, AdaptiVocab, efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the efficiency of Large Language Models (LLMs) in domain-specific settings by adapting the vocabulary, thereby reducing computational overhead and latency.
🛠️ Research Methods:
– Introducing AdaptiVocab, an end-to-end approach for vocabulary adaptation. This includes replacing standard tokens with domain-specific n-gram-based tokens and implementing a lightweight fine-tuning phase on a single GPU.
💬 Research Conclusions:
– AdaptiVocab achieves a reduction in token usage by over 25% while maintaining generation quality and end-task performance across evaluated low-resource domains.
👉 Paper link: https://huggingface.co/papers/2503.19693

2. Exploring Data Scaling Trends and Effects in Reinforcement Learning from Human Feedback
🔑 Keywords: Reinforcement Learning from Human Feedback (RLHF), reward hacking, response diversity, reasoning task verifiers (RTV), generative reward model (GenRM)
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to address data-driven bottlenecks in RLHF performance, focusing on mitigating reward hacking and maintaining response diversity.
🛠️ Research Methods:
– Introduces a hybrid reward system using reasoning task verifiers (RTV) and a generative reward model (GenRM).
– Proposes a novel prompt-selection method, Pre-PPO, to enhance learning effectiveness.
💬 Research Conclusions:
– RTV proves most resistant to reward hacking, followed by the GenRM approaches.
– Performance is significantly improved by prioritizing mathematical and coding tasks early in RLHF training.
– The strategies enable rapid capture of subtle task-specific distinctions, improving RLHF performance.
👉 Paper link: https://huggingface.co/papers/2503.22230

3. Think Before Recommend: Unleashing the Latent Reasoning Power for Sequential Recommendation
🔑 Keywords: Sequential Recommendation, ReaRec, Inference-Time Computing, Ensemble Reasoning Learning, Progressive Reasoning Learning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To enhance user representations in recommender systems by using a novel inference-time computing framework called ReaRec.
🛠️ Research Methods:
– Autoregressively feeding the sequence’s last hidden state into the recommender and incorporating reasoning position embeddings. Implementing two reasoning-based learning methods: Ensemble Reasoning Learning and Progressive Reasoning Learning.
💬 Research Conclusions:
– ReaRec significantly improves the performance of sequential recommendation systems by around 30%-50%, proving its generality and effectiveness across various architectures.
👉 Paper link: https://huggingface.co/papers/2503.22675

4. A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond
🔑 Keywords: Large Reasoning Models, Chain-of-Thought reasoning, reasoning efficiency, inference, token economy
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper provides a comprehensive overview of efforts to improve reasoning efficiency in Large Reasoning Models (LRMs), focusing on the unique challenges in this area.
🛠️ Research Methods:
– It examines common inefficiency patterns, reviews methods across the LRM lifecycle from pretraining to inference, and discusses promising future research directions.
💬 Research Conclusions:
– The survey aims to serve as a foundation for further exploration and inspire innovation, maintaining a real-time GitHub repository for tracking recent field advancements.
👉 Paper link: https://huggingface.co/papers/2503.21614

5. OThink-MR1: Stimulating multimodal generalized reasoning capabilities via dynamic reinforcement learning
🔑 Keywords: Multimodal Large Language Models, reinforcement learning, Kullback-Leibler divergence, Group Relative Policy Optimization, cross-task generalization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address limitations in Multimodal Large Language Models (MLLMs) regarding generalized reasoning, enhancing their performance through novel reinforcement learning strategies.
🛠️ Research Methods:
– Introduced OThink-MR1 model with Group Relative Policy Optimization with a dynamic Kullback-Leibler strategy (GRPO-D) to improve reinforcement learning performance.
💬 Research Conclusions:
– GRPO-D showcased significant performance improvements over traditional supervised fine-tuning and standard GRPO, with noteworthy enhancements in cross-task generalization, proving the effectiveness of the OThink-MR1 model.
👉 Paper link: https://huggingface.co/papers/2503.16081

6. ReFeed: Multi-dimensional Summarization Refinement with Reflective Reasoning on Feedback
🔑 Keywords: Summarization refinement, Reflective reasoning, ReFeed, Feedback exposure, SumFeed-CoT
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance summarization across multiple dimensions using a novel pipeline called ReFeed.
🛠️ Research Methods:
– Implementation and experimentation with a dataset named SumFeed-CoT, designed to train models using reflective reasoning on feedback.
💬 Research Conclusions:
– Reflective reasoning is essential for handling multiple feedbacks and mitigating trade-offs, while ReFeed demonstrates robustness to feedback noise and order. Properly guided data creation is fundamental for effective reasoning.
👉 Paper link: https://huggingface.co/papers/2503.21332

7. ORIGEN: Zero-Shot 3D Orientation Grounding in Text-to-Image Generation
🔑 Keywords: ORIGEN, Zero-shot method, 3D orientation grounding, Text-to-image generation, Langevin dynamics
💡 Category: Generative Models
🌟 Research Objective:
– Introduce ORIGEN, a zero-shot method to enhance 3D orientation grounding in text-to-image generation for multiple objects and categories.
🛠️ Research Methods:
– Utilizes a reward-guided sampling approach with a pretrained discriminative model for 3D orientation estimation and a one-step text-to-image generative flow model.
– Implements a sampling-based approach using Langevin dynamics to maintain image realism, including adaptive time rescaling for accelerated convergence.
💬 Research Conclusions:
– ORIGEN excels over traditional 2D spatial grounding by enhancing 3D control and outperforms other training-based and test-time guidance methods in terms of quantitative metrics and user satisfaction.
👉 Paper link: https://huggingface.co/papers/2503.22194

8. PHYSICS: Benchmarking Foundation Models on University-Level Physics Problem Solving
🔑 Keywords: Benchmark, Foundation Models, Evaluation System, Retrieval-Augmented Generation
💡 Category: AI in Education
🌟 Research Objective:
– Developed PHYSICS, a university-level physics problem-solving benchmark to evaluate advanced models.
🛠️ Research Methods:
– Constructed an automated evaluation system and performed error analysis with various prompting strategies and RAG-based knowledge augmentation.
💬 Research Conclusions:
– Leading models exhibit significant limitations in solving complex scientific problems, with the top model achieving only 59.9% accuracy, indicating substantial areas for improvement.
👉 Paper link: https://huggingface.co/papers/2503.21821

9. Perceptually Accurate 3D Talking Head Generation: New Definitions, Speech-Mesh Representation, and Evaluation Metrics
🔑 Keywords: 3D talking head generation, lip synchronization, Temporal Synchronization, Lip Readability, speech-mesh synchronized representation
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to address the shortcomings in capturing perceptual alignment between speech characteristics and lip movements by focusing on three criteria: Temporal Synchronization, Lip Readability, and Expressiveness.
🛠️ Research Methods:
– Introduces a speech-mesh synchronized representation to better align speech signals with 3D face meshes and incorporates it into existing models as a perceptual loss. Utilizes this representation as a perceptual metric along with two other lip synchronization metrics.
💬 Research Conclusions:
– The study finds that employing the speech-mesh synchronized representation as a perceptual loss significantly enhances the perceptual accuracy in lip synchronization across all three targeted criteria. The approach is validated through experiments, and improves the alignment of generated 3D talking heads with speech inputs.
👉 Paper link: https://huggingface.co/papers/2503.20308

10. Free4D: Tuning-free 4D Scene Generation with Spatial-Temporal Consistency
🔑 Keywords: Tuning-Free Framework, 4D Scene Generation, Pre-trained Foundation Models, Adaptive Guidance Mechanism, Modulation-based Refinement
💡 Category: Generative Models
🌟 Research Objective:
– To develop Free4D, a framework for generating 4D scenes from a single image without the need for extensive tuning or large-scale video datasets.
🛠️ Research Methods:
– Utilization of image-to-video diffusion models and the initialization of 4D geometric structures.
– Implementation of an adaptive guidance mechanism combining point-guided denoising for spatial consistency and a latent replacement strategy for temporal coherence.
– Application of modulation-based refinement to enhance consistency in the generated 4D representations.
💬 Research Conclusions:
– Free4D presents a significant advancement in generating real-time, controllable 4D scenes from single images by leveraging existing pre-trained models, enhancing both efficiency and generalization capabilities.
👉 Paper link: https://huggingface.co/papers/2503.20785

11. Your ViT is Secretly an Image Segmentation Model
🔑 Keywords: Vision Transformers (ViTs), image segmentation, Encoder-only Mask Transformer (EoMT), architectural simplicity
💡 Category: Computer Vision
🌟 Research Objective:
– To demonstrate that Vision Transformers (ViTs) can inherently learn inductive biases for image segmentation without task-specific components, given large-scale models and extensive pre-training.
🛠️ Research Methods:
– Introduced the Encoder-only Mask Transformer (EoMT) by repurposing the plain ViT architecture to achieve segmentation using ViTs without additional complexity.
💬 Research Conclusions:
– EoMT achieves similar segmentation accuracy to state-of-the-art models but with significantly faster speeds due to its simple architecture, suggesting that computational resources are better used in scaling the ViT itself.
👉 Paper link: https://huggingface.co/papers/2503.19108

12. Segment Any Motion in Videos
🔑 Keywords: Moving Object Segmentation, Optical Flow, SAM2, Spatio-Temporal Trajectory Attention, Motion-Semantic Decoupled Embedding
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to achieve high-level understanding of visual scenes through enhanced moving object segmentation, addressing challenges like partial motion, complex deformations, motion blur, and background distractions.
🛠️ Research Methods:
– Utilizes a novel approach combining long-range trajectory motion cues with DINO-based semantic features.
– Employs Spatio-Temporal Trajectory Attention and Motion-Semantic Decoupled Embedding for effective segmentation.
– Leverages SAM2 for pixel-level mask densification via an iterative prompting strategy.
💬 Research Conclusions:
– The proposed model demonstrates state-of-the-art performance on diverse datasets, excelling in challenging scenarios with fine-grained segmentation of multiple objects.
– The code is publicly available for further investigation at https://motion-seg.github.io/.
👉 Paper link: https://huggingface.co/papers/2503.22268

13. Hi3DGen: High-fidelity 3D Geometry Generation from Images via Normal Bridging
🔑 Keywords: Hi3DGen, 3D geometry generation, normal maps, image-to-normal estimator, high-fidelity
💡 Category: Computer Vision
🌟 Research Objective:
– To address the challenge of reproducing fine-grained geometric details from 2D images by developing a framework that improves high-fidelity 3D model generation.
🛠️ Research Methods:
– Introduction of Hi3DGen, featuring techniques like image-to-normal estimation, normal-to-geometry learning, and a 3D data synthesis pipeline to enhance the fidelity of 3D geometry generation.
💬 Research Conclusions:
– The Hi3DGen framework effectively generates rich geometric details and outperforms state-of-the-art methods in accuracy and fidelity, providing a novel approach through the use of normal maps as intermediate representations.
👉 Paper link: https://huggingface.co/papers/2503.22236

14. 4D-Bench: Benchmarking Multi-modal Large Language Models for 4D Object Understanding
🔑 Keywords: MLLMs, 4D objects, 4D-Bench, temporal understanding, 4D object QA
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce 4D-Bench, a benchmark for evaluating Multimodal Large Language Models (MLLMs) in understanding 4D objects.
🛠️ Research Methods:
– Evaluate MLLMs through tasks in 4D object Question Answering and 4D object captioning using 4D-Bench.
💬 Research Conclusions:
– MLLMs show weaker performance in temporal understanding compared to appearance understanding, particularly in open-source models.
– The performance gap in 4D object understanding is significant, with even state-of-the-art models like GPT-4o performing poorly in temporal tasks.
👉 Paper link: https://huggingface.co/papers/2503.17827

15. A Refined Analysis of Massive Activations in LLMs
🔑 Keywords: low-precision training, quantization, large language models, massive activations, Attention KV bias
💡 Category: Natural Language Processing
🌟 Research Objective:
– To analyze massive activations across a wide range of large language models and address existing gaps in understanding their effects.
🛠️ Research Methods:
– Conducted analysis of both GLU-based and non-GLU-based architectures and explored hybrid mitigation strategies, such as pairing Target Variance Rescaling with either Attention KV bias or Dynamic Tanh.
💬 Research Conclusions:
– Not all massive activations are detrimental, as suppressing them does not inherently lead to increased perplexity or decreased downstream task performance.
– Proposed model-specific mitigation strategies are often ineffective, prompting the investigation of novel hybrid methods that preserve model performance while mitigating activations.
👉 Paper link: https://huggingface.co/papers/2503.22329

16. SparseFlex: High-Resolution and Arbitrary-Topology 3D Shape Modeling
🔑 Keywords: SparseFlex, isosurface representation, differentiable mesh reconstruction, frustum-aware, Chamfer Distance
💡 Category: Generative Models
🌟 Research Objective:
– To advance high-fidelity 3D mesh creation with arbitrary topology using a novel method called SparseFlex.
🛠️ Research Methods:
– Introduction of a sparse-structured isosurface representation, utilizing a frustum-aware sectional voxel training strategy for efficient memory use and high-resolution training.
– Implementation of a complete shape modeling pipeline with a variational autoencoder and a rectified flow transformer for 3D generation.
💬 Research Conclusions:
– Demonstrated state-of-the-art reconstruction accuracy with a significant reduction in Chamfer Distance and increase in F-score compared to previous methods.
– Enabled reconstruction and generation of high-resolution 3D shapes with arbitrary topology using rendering losses.
👉 Paper link: https://huggingface.co/papers/2503.21732

17. MedAgent-Pro: Towards Multi-modal Evidence-based Medical Diagnosis via Reasoning Agentic Workflow
🔑 Keywords: Multi-modal Large Language Models, Medical Diagnosis, Evidence-based Reasoning, Explainable, Precise
💡 Category: AI in Healthcare
🌟 Research Objective:
– The research aims to develop reliable AI systems to support clinicians in multi-modal medical diagnosis, with a focus on enhancing the use of Multi-modal Large Language Models (MLLMs).
🛠️ Research Methods:
– The study proposes MedAgent-Pro, an agentic system utilizing evidence-based reasoning and a hierarchical workflow to create reliable medical diagnoses, through both task-level knowledge-based reasoning and case-level multi-modal input processing.
💬 Research Conclusions:
– Comprehensive experiments confirm the superiority and effectiveness of MedAgent-Pro in 2D and 3D medical diagnosis tasks, highlighting its reliability and interpretability.
👉 Paper link: https://huggingface.co/papers/2503.18968

18. Reconstructing Humans with a Biomechanically Accurate Skeleton
🔑 Keywords: 3D humans, biomechanically accurate skeleton model, transformer, pseudo ground truth, 3D human mesh recovery
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce a method for reconstructing 3D humans from a single image using a biomechanically accurate skeleton model.
🛠️ Research Methods:
– Train a transformer model to estimate model parameters from an image.
– Develop a pipeline to generate pseudo ground truth data for training.
– Implement an iterative training procedure to refine pseudo labels.
💬 Research Conclusions:
– Achieves competitive performance on standard benchmarks for 3D human mesh recovery.
– Outperforms existing methods in extreme 3D poses and viewpoints.
– Provides realistic joint rotation estimates, addressing joint angle limit violations in previous methods.
– Validated across multiple human pose estimation benchmarks.
👉 Paper link: https://huggingface.co/papers/2503.21751

19. On Large Multimodal Models as Open-World Image Classifiers
🔑 Keywords: Large Multimodal Models, open-world setting, fine-grained capabilities, tailored prompting, evaluation protocol
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to evaluate Large Multimodal Models (LMMs) in an open-world setting for classifying images using natural language prompts.
🛠️ Research Methods:
– Formalization of the task and introduction of an evaluation protocol with metrics, assessing class alignment; evaluation of 13 models across 10 benchmarks including various class granularity levels.
💬 Research Conclusions:
– The analysis uncovers challenges in granularity and fine-grained tasks, identifying the types of errors in LMMs, and suggests that tailored prompting and reasoning can address these issues.
👉 Paper link: https://huggingface.co/papers/2503.21851

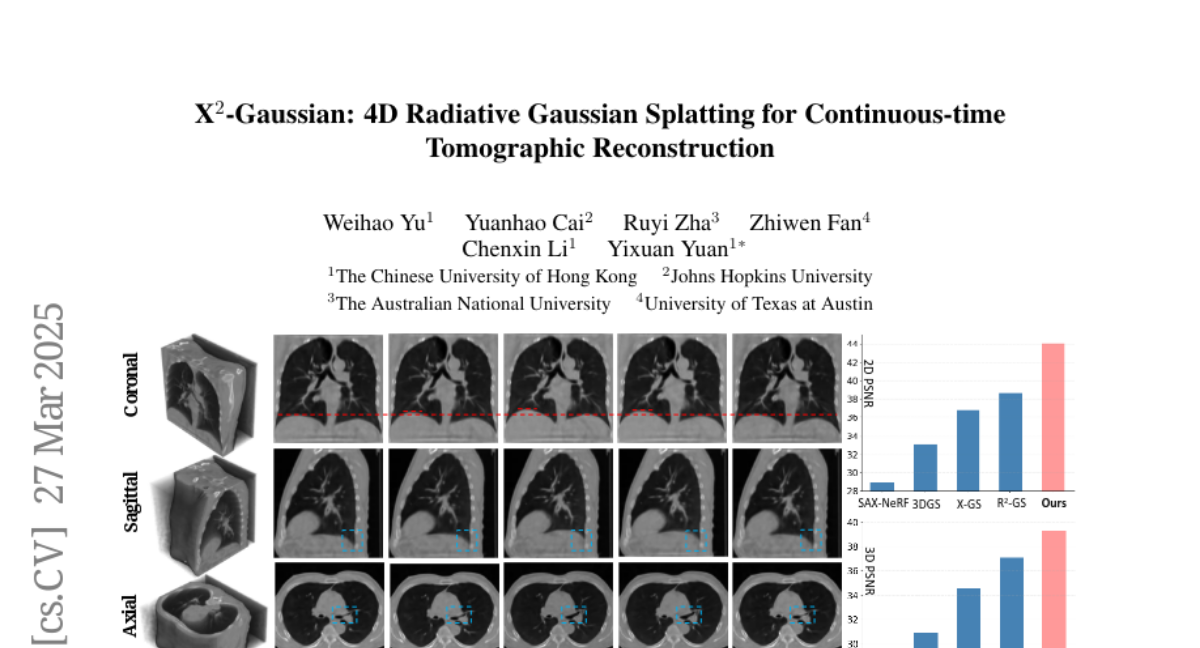
20. X^{2}-Gaussian: 4D Radiative Gaussian Splatting for Continuous-time Tomographic Reconstruction
🔑 Keywords: 4D CT reconstruction, dynamic radiative Gaussian splatting, self-supervised respiratory motion learning, spatiotemporal encoder-decoder architecture, high-fidelity 4D CT reconstruction
💡 Category: AI in Healthcare
🌟 Research Objective:
– Propose a novel framework, X^2-Gaussian, for continuous-time 4D CT reconstruction to improve dynamic clinical imaging without phase discretization.
🛠️ Research Methods:
– Integrate dynamic radiative Gaussian splatting with self-supervised respiratory motion learning using a spatiotemporal encoder-decoder architecture that predicts time-varying Gaussian deformations and a physiology-driven periodic consistency loss.
💬 Research Conclusions:
– X^2-Gaussian achieves a 9.93 dB PSNR improvement over conventional methods and a 2.25 dB gain compared to previous Gaussian splatting techniques, advancing high-fidelity 4D CT reconstruction by modeling continuous motion without reliance on hardware gating devices.
👉 Paper link: https://huggingface.co/papers/2503.21779
21. SWI: Speaking with Intent in Large Language Models
🔑 Keywords: Speaking with Intent, Large Language Models, Cognitive Framework, Reasoning Capabilities, Text Summarization
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces the concept of Speaking with Intent (SWI) in large language models to enhance reasoning and generation quality by using explicitly generated intent to guide analysis and communication.
🛠️ Research Methods:
– Extensive experiments were conducted on mathematical reasoning benchmarks, reasoning-intensive question answering, and text summarization benchmarks to evaluate the performance of SWI compared to existing methods.
💬 Research Conclusions:
– SWI consistently outperforms baseline models and other prompting methods like Chain-of-Thought and Plan-and-Solve, demonstrating superior accuracy, conciseness, and factual correctness in text generation, with fewer hallucinations.
👉 Paper link: https://huggingface.co/papers/2503.21544

22. Challenges and Paths Towards AI for Software Engineering
🔑 Keywords: Generative AI, Automated Software Engineering, Research Directions
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Discuss progress in AI for software engineering, focusing on achieving high levels of automation.
🛠️ Research Methods:
– Provide a structured taxonomy of tasks in AI for software engineering beyond code generation and completion.
– Outline key bottlenecks and propose promising research directions.
💬 Research Conclusions:
– Highlight the need for substantial research and engineering efforts to overcome current limitations and advance the field.
👉 Paper link: https://huggingface.co/papers/2503.22625

23.
