AI Native Daily Paper Digest – 20250401

1. TextCrafter: Accurately Rendering Multiple Texts in Complex Visual Scenes
🔑 Keywords: Complex Visual Text Generation, TextCrafter, Multi-Visual Text Rendering, Generative Models, CVTG-2K
💡 Category: Generative Models
🌟 Research Objective:
– To address challenges in Complex Visual Text Generation (CVTG) by developing a method to improve text clarity and reduce distortions and omissions in visual text.
🛠️ Research Methods:
– Introduction of TextCrafter, employing a progressive strategy and token focus enhancement mechanism to improve alignment and text prominence.
– Development and presentation of a benchmark dataset, CVTG-2K, for evaluating generative model performance in CVTG tasks.
💬 Research Conclusions:
– Extensive experiments indicated that TextCrafter outperforms state-of-the-art methods in generating clearer and more accurate visual text.
👉 Paper link: https://huggingface.co/papers/2503.23461

2. MoCha: Towards Movie-Grade Talking Character Synthesis
🔑 Keywords: Talking Characters, MoCha, speech-video window attention, multi-character conversation, cinematic storytelling
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to advance character-driven storytelling in video generation by creating talking character animations directly from speech and text.
🛠️ Research Methods:
– The study introduces MoCha, a novel framework to generate full-body talking characters. It employs a speech-video window attention mechanism for precise synchronization between speech and video and utilizes a joint training strategy with both speech-labeled and text-labeled video data to improve generalization.
💬 Research Conclusions:
– Evaluations indicate that MoCha sets a new benchmark in AI-generated cinematic storytelling, excelling in realism, expressiveness, controllability, and generalization across diverse character actions.
👉 Paper link: https://huggingface.co/papers/2503.23307

3. What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models
🔑 Keywords: Test-Time Scaling, Large Language Models, Multidimensional Framework, Practical Deployment, Open Challenges
💡 Category: Natural Language Processing
🌟 Research Objective:
– To provide a comprehensive survey and a unified framework for understanding Test-Time Scaling (TTS) in language models, highlighting its significance in both specialized and general tasks.
🛠️ Research Methods:
– A proposal of a multidimensional framework for TTS research structured along four dimensions: what, how, where, and how well to scale; conducting an extensive review of methods, applications, and assessments.
💬 Research Conclusions:
– Identification and decomposition of TTS techniques, providing guidelines for practical deployment and highlighting developmental trajectories, while identifying open challenges and future directions for TTS research.
👉 Paper link: https://huggingface.co/papers/2503.24235

4. Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
🔑 Keywords: Open-Reasoner-Zero, scalability, reinforcement learning, vanilla PPO, performance
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce Open-Reasoner-Zero, focusing on scalability, simplicity, and accessibility for large-scale reasoning-oriented reinforcement learning.
🛠️ Research Methods:
– Utilize a minimalist approach with vanilla PPO and GAE, avoiding KL regularization, along with rule-based rewards to scale response length and benchmark performance.
💬 Research Conclusions:
– Achieved superior performance on various benchmarks like AIME2024, MATH500, and GPQA Diamond with remarkable efficiency, requiring a tenth of the training steps compared to the DeepSeek-R1-Zero pipeline.
👉 Paper link: https://huggingface.co/papers/2503.24290

5. RIG: Synergizing Reasoning and Imagination in End-to-End Generalist Policy
🔑 Keywords: Reasoning, Imagination, Generalist Policy, Reinforcement Learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to synergize reasoning and imagination in an end-to-end Generalist policy model, named RIG, to improve learning efficiency and policy generalization for embodied agents.
🛠️ Research Methods:
– Developed a data pipeline to progressively integrate reasoning and imagination into trajectories, enabling joint learning of reasoning and next image generation.
💬 Research Conclusions:
– The synergy of reasoning and imagination in RIG enhances robustness, generalization, and interoperability, showing a 17-fold improvement in sample efficiency compared to prior work.
– RIG allows agents to predict action outcomes and self-correct during inference, leading to performance enhancements.
👉 Paper link: https://huggingface.co/papers/2503.24388

6. Efficient Inference for Large Reasoning Models: A Survey
🔑 Keywords: Large Reasoning Models, Chain-of-Thought, Efficient Inference, Interpretability, Safety
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To review efficient inference methods for Large Reasoning Models (LRMs) aimed at reducing token inefficiency while maintaining reasoning quality.
🛠️ Research Methods:
– Introduce a taxonomy dividing methods into explicit compact Chain-of-Thought (CoT) and implicit latent CoT.
– Conduct empirical analyses on performance and efficiency of existing methods.
💬 Research Conclusions:
– Highlight open challenges such as human-centric controllable reasoning and the trade-off between interpretability and efficiency.
– Provide insights for enhancing inference efficiency through techniques like model merging, new architectures, and agent routers.
👉 Paper link: https://huggingface.co/papers/2503.23077

7. Effectively Controlling Reasoning Models through Thinking Intervention
🔑 Keywords: Reasoning-enhanced large language models, Thinking Intervention, Intermediate reasoning steps, Instruction-following, Safety alignment
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore the potential of a new generation framework for enhanced control over the reasoning processes of large language models (LLMs) using the Thinking Intervention paradigm.
🛠️ Research Methods:
– Comprehensive evaluations across multiple tasks, including instruction following on IFEval, instruction hierarchy on SEP, and safety alignment on XSTest and SORRY-Bench.
💬 Research Conclusions:
– Thinking Intervention paradigm shows significant improvements over baseline approaches, with up to a 6.7% increase in instruction-following accuracy, 15.4% improvement in reasoning about instruction hierarchies, and a 40.0% increase in refusal rates for unsafe prompts using open-source DeepSeek R1 models.
👉 Paper link: https://huggingface.co/papers/2503.24370

8. SketchVideo: Sketch-based Video Generation and Editing
🔑 Keywords: sketch-based control, video generation, memory-efficient control structure, inter-frame attention, SketchVideo
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to achieve sketch-based spatial and motion control for video generation and support fine-grained editing of real or synthetic videos.
🛠️ Research Methods:
– A memory-efficient control structure with sketch control blocks is proposed to predict residual features of skipped DiT blocks, combined with an inter-frame attention mechanism for propagating temporally sparse sketch conditions.
💬 Research Conclusions:
– The SketchVideo method demonstrates superior performance in controllable video generation and editing, ensuring consistency between newly edited content and original spatial and dynamic features.
👉 Paper link: https://huggingface.co/papers/2503.23284

9. Expanding RL with Verifiable Rewards Across Diverse Domains
🔑 Keywords: Reinforcement Learning, Verifiable Rewards, Cross-Domain, Model-Based Soft Scoring, Scalability
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Explore the extension of Reinforcement Learning with Verifiable Rewards (RLVR) to diverse domains like medicine, chemistry, psychology, and economics.
🛠️ Research Methods:
– Implementation of model-based soft scoring to address limitations of binary rewards and improve flexibility across domains without extensive domain-specific annotations.
– Fine-tuning a base 7B model using various RL algorithms for effective cross-domain verification.
💬 Research Conclusions:
– The research demonstrates that distilled generative reward models act as effective cross-domain verifiers, enabling RLVR to outperform state-of-the-art open-source aligned LLMs in free-form answer settings.
– Highlights the robustness and scalability of RLVR, emphasizing its potential for real-world applications with noisy or weak labels.
👉 Paper link: https://huggingface.co/papers/2503.23829

10. TokenHSI: Unified Synthesis of Physical Human-Scene Interactions through Task Tokenization
🔑 Keywords: Human-Scene Interactions, Transformer-based policy, multi-skill unification, masking mechanism, proprioception
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The primary aim is to create a unified transformer-based policy, TokenHSI, to address diverse Human-Scene Interaction tasks by integrating multiple skills.
🛠️ Research Methods:
– The research introduces a masking mechanism that uses a shared token for humanoid proprioception and combines it with distinct task tokens. This allows effective knowledge sharing and multi-task training.
💬 Research Conclusions:
– The study concludes that TokenHSI enhances versatility, adaptability, and extensibility in handling various complex HSI tasks.
👉 Paper link: https://huggingface.co/papers/2503.19901
11. Query and Conquer: Execution-Guided SQL Generation
🔑 Keywords: text-to-SQL, execution results, semantically consistent, SQL generation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to improve the accuracy of text-to-SQL tasks by selecting the most semantically consistent query from multiple candidates.
🛠️ Research Methods:
– The method leverages execution results to choose queries and integrates smoothly with existing models, outperforming computationally heavy reasoning methods while reducing inference costs.
💬 Research Conclusions:
– This approach enhances smaller models, offering a scalable and practical way to achieve state-of-the-art performance in SQL generation, with cost efficiency improved up to 30 times.
👉 Paper link: https://huggingface.co/papers/2503.24364
12. Classical Planning with LLM-Generated Heuristics: Challenging the State of the Art with Python Code
🔑 Keywords: Large Language Models, Planning Capabilities, Heuristic Functions, Python Code
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Enhance the planning capabilities of Large Language Models (LLMs) using domain-dependent heuristic functions.
🛠️ Research Methods:
– Generate heuristic functions in Python using LLMs and evaluate them with a greedy best-first search to identify the strongest heuristic.
💬 Research Conclusions:
– The LLM-generated heuristics solve more unseen test tasks than state-of-the-art domain-independent heuristics and are competitive in domain-dependent planning, showcasing significant improvements even with an unoptimized implementation.
👉 Paper link: https://huggingface.co/papers/2503.18809

13. ActionStudio: A Lightweight Framework for Data and Training of Large Action Models
🔑 Keywords: Action models, Autonomous agents, Agent-specific fine-tuning, ActionStudio, Scalable
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop ActionStudio, a lightweight and extensible data and training framework tailored for large Action models in autonomous agents.
🛠️ Research Methods:
– Utilized a standardized format to unify heterogeneous agent trajectories, supporting LoRA, full fine-tuning, and distributed training paradigms.
💬 Research Conclusions:
– Demonstrated strong performance and practical scalability of ActionStudio across public and industry benchmarks. Open-sourced code and data to promote further research.
👉 Paper link: https://huggingface.co/papers/2503.22673

14. TeleAntiFraud-28k: A Audio-Text Slow-Thinking Dataset for Telecom Fraud Detection
🔑 Keywords: Multimodal Training Data, Telecom Fraud, Large Language Model (LLM), Privacy-preserved, Fraud Detection
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary aim is to create an open-source audio-text dataset, TeleAntiFraud-28k, to enhance automated telecom fraud analysis.
🛠️ Research Methods:
– Developed privacy-preserved text-truth samples using ASR and TTS models.
– Enhanced semantic meaning via LLM-based self-instruction sampling.
– Simulated emerging fraud tactics through multi-agent adversarial synthesis.
💬 Research Conclusions:
– Introduced a new multimodal dataset with over 28,000 samples for telecom fraud detection.
– Established a standardized benchmark, TeleAntiFraud-Bench, for evaluating model performance.
– Provided a supervised fine-tuning model and open-sourced the data processing framework to encourage community contribution.
👉 Paper link: https://huggingface.co/papers/2503.24115

15. Progressive Rendering Distillation: Adapting Stable Diffusion for Instant Text-to-Mesh Generation without 3D Data
🔑 Keywords: 3D Meshes, Progressive Rendering Distillation, Multi-View Diffusion Models, TriplaneTurbo, Text-to-3D Generators
💡 Category: Generative Models
🌟 Research Objective:
– To develop a model capable of generating high-quality 3D meshes from text prompts in just seconds without the need for 3D ground-truths.
🛠️ Research Methods:
– Introduced Progressive Rendering Distillation (PRD), a novel training scheme that leverages multi-view diffusion models and utilizes U-Net to progressively denoise and decode latent space into 3D outputs.
💬 Research Conclusions:
– The proposed TriplaneTurbo, with minimal additional parameters, surpasses previous text-to-3D generators in both efficiency and quality, achieving high-quality mesh generation in 1.2 seconds.
👉 Paper link: https://huggingface.co/papers/2503.21694
16. UPME: An Unsupervised Peer Review Framework for Multimodal Large Language Model Evaluation
🔑 Keywords: Multimodal Large Language Models (MLLMs), Visual Question Answering (VQA), MLLM-as-judge, vision-language scoring system
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This research aims to address the limitations of current evaluation methods for MLLMs in VQA, which require a heavy human workload and are often biased.
🛠️ Research Methods:
– The authors propose an Unsupervised Peer review MLLM Evaluation framework that uses only image data to generate questions and assessments, along with a vision-language scoring system to evaluate response correctness, visual understanding, and image-text correlation.
💬 Research Conclusions:
– The proposed framework achieves high Pearson correlation scores of 0.944 and 0.814 with human evaluations on the MMstar and ScienceQA datasets, respectively, indicating alignment with human-designed benchmarks.
👉 Paper link: https://huggingface.co/papers/2503.14941

17. Bridging Evolutionary Multiobjective Optimization and GPU Acceleration via Tensorization
🔑 Keywords: Evolutionary multiobjective optimization, GPU, Tensorization, Scalability, High-quality solutions
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To bridge the gap between Evolutionary multiobjective optimization algorithms and advanced computing devices like GPUs by parallelizing EMO algorithms through tensorization.
🛠️ Research Methods:
– Employ tensorization methodology to transform data structures and operations of EMO algorithms into tensor representations for GPU utilization.
– Apply the approach to three representative EMO algorithms: NSGA-III, MOEA/D, and HypE.
– Introduce a multiobjective robot control benchmark using a GPU-accelerated physics engine for comprehensive assessment.
💬 Research Conclusions:
– The tensorized EMO algorithms achieve speedups of up to 1113x compared to CPU-based algorithms while maintaining solution quality.
– Effectively scales population sizes to hundreds of thousands.
– Efficiently tackle complex multiobjective robot control tasks, producing high-quality solutions with diverse behaviors.
👉 Paper link: https://huggingface.co/papers/2503.20286

18. KOFFVQA: An Objectively Evaluated Free-form VQA Benchmark for Large Vision-Language Models in the Korean Language
🔑 Keywords: Large Vision-Language Models, VLMs, Korean language, evaluation benchmarks, KOFFVQA
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce KOFFVQA, a Korean language benchmark for evaluating VLMs, addressing the lack of non-English benchmarks and subjective evaluations.
🛠️ Research Methods:
– Developed a benchmark with 275 questions paired with images and objective grading criteria to ensure reliable evaluation of VLMs.
💬 Research Conclusions:
– Demonstrated that the new benchmark KOFFVQA and its grading criteria provide a more reliable evaluation method for VLMs compared to existing methods, with open access to the evaluation code.
👉 Paper link: https://huggingface.co/papers/2503.23730

19. Easi3R: Estimating Disentangled Motion from DUSt3R Without Training
🔑 Keywords: DUSt3R, 4D Model, Easi3R, Attention Adaptation, Camera Pose Estimation
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce Easi3R, a novel training-free method for 4D reconstruction that does not require network pre-training or fine-tuning.
🛠️ Research Methods:
– Utilizes attention adaptation during inference to disentangle attention maps for tasks such as camera pose estimation and 4D dense point map reconstruction.
💬 Research Conclusions:
– Demonstrates that the lightweight attention adaptation method significantly outperforms state-of-the-art methods trained or fine-tuned on large dynamic datasets.
👉 Paper link: https://huggingface.co/papers/2503.24391

20. Unicorn: Text-Only Data Synthesis for Vision Language Model Training
🔑 Keywords: Multimodal Data Synthesis, Large Language Models (LLMs), Instruction-Tuning, Vision-Language Models (VLMs), Synthetic Image Representations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to synthesize high-quality multimodal training data purely from text to train Vision-Language Models (VLMs) in a cost-effective and scalable manner.
🛠️ Research Methods:
– A three-stage multimodal data synthesis framework was developed, involving diverse caption data synthesis using Large Language Models (LLMs), instruction-tuning data generation, and modality representation transfer to create synthetic image representations.
💬 Research Conclusions:
– The framework successfully eliminates dependency on real images by creating datasets Unicorn-1.2M and Unicorn-471K-Instruction, maintaining data quality and diversity while reducing costs for VLM model training.
👉 Paper link: https://huggingface.co/papers/2503.22655

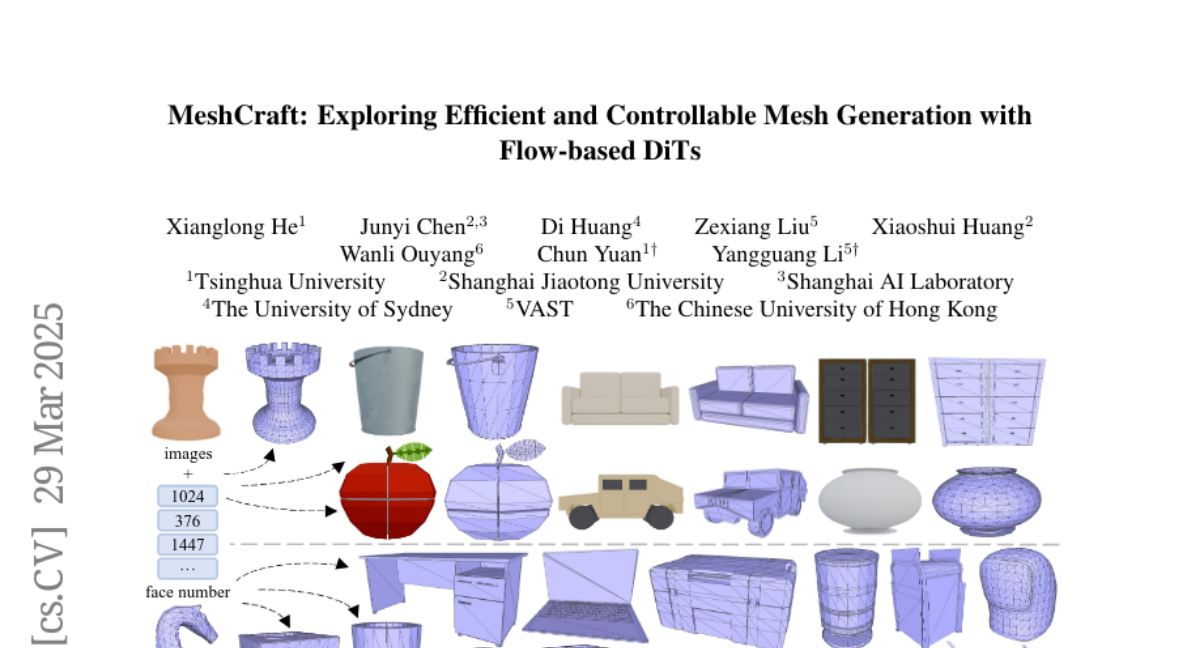
21. MeshCraft: Exploring Efficient and Controllable Mesh Generation with Flow-based DiTs
🔑 Keywords: MeshCraft, 3D content creation, continuous spatial diffusion, transformer-based VAE
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to introduce MeshCraft, a framework that enhances mesh generation in 3D content creation by providing efficiency and control over mesh topology.
🛠️ Research Methods:
– MeshCraft employs a transformer-based VAE to encode and decode meshes, combined with a flow-based diffusion transformer to generate high-quality 3D meshes with a predefined number of faces efficiently.
💬 Research Conclusions:
– MeshCraft achieves faster mesh generation speeds compared to existing methods, significantly outperforming state-of-the-art techniques in both qualitative and quantitative evaluations on datasets like ShapeNet and Objaverse, while also integrating smoothly with conditional guidance strategies to aid artists in reducing manual efforts.
👉 Paper link: https://huggingface.co/papers/2503.23022
22. Decoupling Angles and Strength in Low-rank Adaptation
🔑 Keywords: Parameter-Efficient FineTuning, LoRA, DeLoRA, Robustness, Low-rank Adaptation
💡 Category: Machine Learning
🌟 Research Objective:
– The objective is to propose DeLoRA, a novel finetuning method that enhances robustness without compromising performance by decoupling angular learning from adaptation strength.
🛠️ Research Methods:
– The method involves normalizing and scaling learnable low-rank matrices to bound the distance of the transformation.
💬 Research Conclusions:
– DeLoRA matches or surpasses performance of other PEFT methods and demonstrates stronger robustness in tasks like subject-driven image generation and natural language understanding.
👉 Paper link: https://huggingface.co/papers/2503.18225

23. PAVE: Patching and Adapting Video Large Language Models
🔑 Keywords: Video LLMs, Side-channel signals, Adapters, Multi-task learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to adapt pre-trained Video large language models (Video LLMs) to new tasks involving additional modalities or data types like audio or 3D information using a framework called PAVE.
🛠️ Research Methods:
– This paper introduces lightweight adapters, called “patches,” which add minimal parameters and operations to the base model without altering its architecture or pre-trained weights to support diverse downstream tasks.
💬 Research Conclusions:
– PAVE effectively enhances the performance of the base model across various tasks and surpasses state-of-the-art task-specific models with a minor ~0.1% increase in FLOPs and parameters. It supports multi-task learning and generalizes well across different Video LLMs.
👉 Paper link: https://huggingface.co/papers/2503.19794

24. AvatarArtist: Open-Domain 4D Avatarization
🔑 Keywords: 4D Avatarization, Parametric Triplanes, GANs, Diffusion Models
💡 Category: Generative Models
🌟 Research Objective:
– Develop a method for creating 4D avatars from portrait images in arbitrary styles using open-domain techniques.
🛠️ Research Methods:
– Utilization of parametric triplanes as intermediate 4D representation.
– Implementation of a practical training paradigm combining GANs and diffusion models to handle diverse data distributions.
💬 Research Conclusions:
– AvatarArtist model demonstrated robust capability in generating high-quality 4D avatars across various source image domains, with plans to release code and models for future research.
👉 Paper link: https://huggingface.co/papers/2503.19906
25. Entropy-Based Adaptive Weighting for Self-Training
🔑 Keywords: Entropy-Based Adaptive Weighting, Self-Training, Uncertainty, Reasoning Ability
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study focuses on enhancing the mathematical problem-solving capabilities of large language models by using self-generated reasoning paths.
🛠️ Research Methods:
– The introduction of Entropy-Based Adaptive Weighting for Self-Training (EAST), which prioritizes uncertain data during the training process by using a mapping function with a tunable parameter.
💬 Research Conclusions:
– Empirical evaluations on GSM8K and MATH benchmarks show that EAST achieves up to a 1% improvement on MATH and a 1-2% boost on GSM8K compared to the vanilla method.
👉 Paper link: https://huggingface.co/papers/2503.23913

26. Understanding Co-speech Gestures in-the-wild
🔑 Keywords: Co-speech gestures, Tri-modal embedding space, Weakly supervised, Gesture representation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce a new framework for understanding Co-speech gestures in real-world scenarios, focusing on gesture-text-speech associations.
🛠️ Research Methods:
– Propose three tasks: gesture-based retrieval, gestured word spotting, and active speaker detection using gestures.
– Develop a tri-modal speech-text-video-gesture representation using both global phrase contrastive loss and local gesture-word coupling loss.
💬 Research Conclusions:
– The newly learned representations outperform previous methods, including large vision-language models, across all tasks.
– The study highlights the significance of capturing gesture-related signals through speech and text modalities within a shared tri-modal embedding space.
👉 Paper link: https://huggingface.co/papers/2503.22668

27. DSO: Aligning 3D Generators with Simulation Feedback for Physical Soundness
🔑 Keywords: Self-supporting, Direct Simulation Optimization, Stability Score, Diffusion Models
💡 Category: Generative Models
🌟 Research Objective:
– Develop a method to generate stable 3D objects by using feedback from a non-differentiable physics simulator.
🛠️ Research Methods:
– Introduce Direct Simulation Optimization (DSO) to improve 3D object generation through a feedback-driven approach.
– Use a dataset labeled with stability scores to fine-tune the 3D generator via direct preference optimization (DPO) or direct reward optimization (DRO).
💬 Research Conclusions:
– The DSO framework is faster and more effective than traditional test-time optimization for generating stable 3D objects.
– The method allows for self-improvement without ground-truth 3D objects, through automatic feedback collection from simulations.
👉 Paper link: https://huggingface.co/papers/2503.22677

28.
