AI Native Daily Paper Digest – 20250408

1. SmolVLM: Redefining small and efficient multimodal models
🔑 Keywords: Vision-Language Models, Resource-Efficient, On-Device Applications, Tokenization, Multimodal Performance
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to develop compact and resource-efficient Vision-Language Models (VLMs) suitable for mobile and edge devices without sacrificing performance.
🛠️ Research Methods:
– Exploration of architectural configurations and tokenization strategies to minimize computational overhead and optimize multimodal performance.
💬 Research Conclusions:
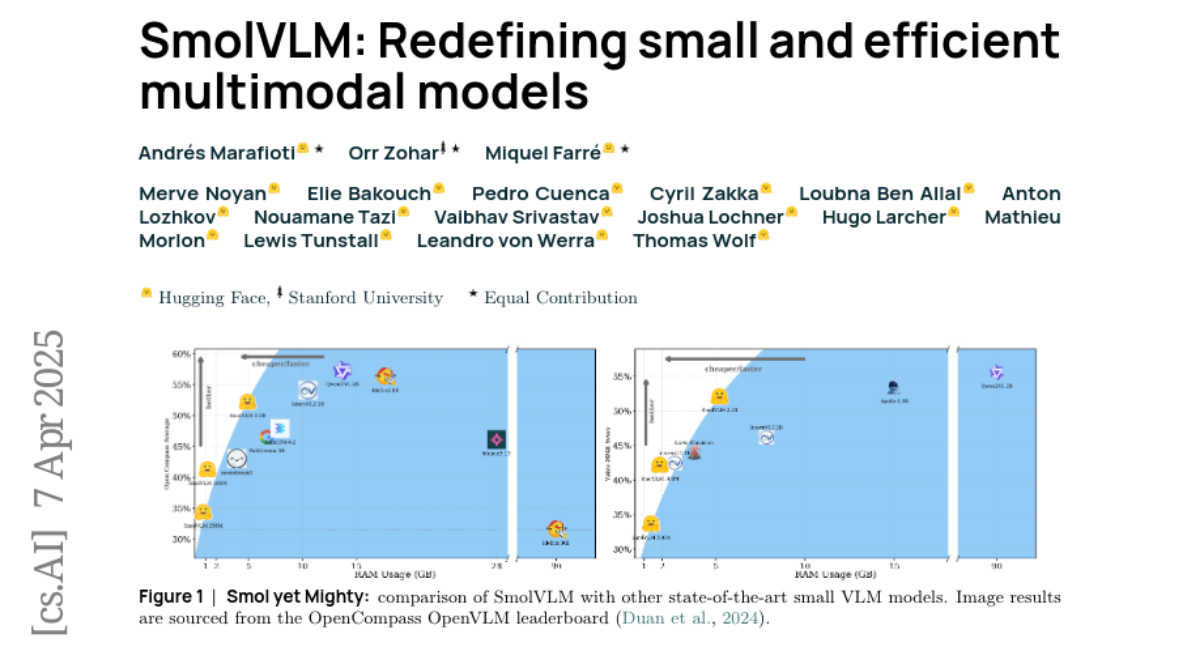
– SmolVLM series achieves significant performance improvements on image and video tasks with minimal memory usage, demonstrating effective video comprehension and practical deployment capabilities at reduced model sizes.
👉 Paper link: https://huggingface.co/papers/2504.05299
2. One-Minute Video Generation with Test-Time Training
🔑 Keywords: Transformers, Test-Time Training, Video Generation, AI Native, Generative Models
💡 Category: Generative Models
🌟 Research Objective:
– Explore the integration of Test-Time Training (TTT) layers into Transformers to enable generation of one-minute videos from text storyboards.
🛠️ Research Methods:
– Implement TTT layers whose hidden states can be neural networks, incorporated into pre-trained Transformers.
– Use a dataset based on Tom and Jerry cartoons for proof of concept.
– Compare results against baselines like Mamba~2, Gated DeltaNet, and sliding-window attention layers.
💬 Research Conclusions:
– TTT layers yield more coherent video generation, outperforming other methods in human evaluations by 34 Elo points.
– Results contain artifacts and issues exist with the efficiency and capacity of the pre-trained 5B model; potential for extending to longer videos and complex stories exists.
👉 Paper link: https://huggingface.co/papers/2504.05298
3. Rethinking Reflection in Pre-Training
🔑 Keywords: language model, self-reflection, pre-training, complex problems, self-correcting
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the emergence of self-reflective reasoning abilities in language models during pre-training rather than reinforcement learning.
🛠️ Research Methods:
– Introduced deliberate errors in chains-of-thought to see if the model can identify and correct these mistakes, tracking this ability during different pre-training stages.
💬 Research Conclusions:
– Demonstrated that the ability of a model to self-correct emerges early during pre-training and improves over time, as shown by the OLMo2-7B model on six self-reflection tasks.
👉 Paper link: https://huggingface.co/papers/2504.04022

4. URECA: Unique Region Caption Anything
🔑 Keywords: Multi-granularity, Region-level captioning, URECA, Multimodal Large Language Models, High-resolution mask encoder
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce the URECA dataset designed for detailed multi-granularity region-level captioning.
🛠️ Research Methods:
– Utilize a stage-wise data curation pipeline with Multimodal Large Language Models to ensure unique and contextually accurate captions.
💬 Research Conclusions:
– URECA model achieves state-of-the-art performance on the URECA dataset, also effectively generalizing to existing region-level captioning benchmarks.
👉 Paper link: https://huggingface.co/papers/2504.05305

5. T1: Tool-integrated Self-verification for Test-time Compute Scaling in Small Language Models
🔑 Keywords: Test-time compute scaling, small language models (sLMs), self-verification, tool integration
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate whether small language models (sLMs) can reliably self-verify their outputs under test-time compute scaling.
🛠️ Research Methods:
– Proposed Tool-integrated self-verification (T1), which utilizes external tools for memorization-heavy verification tasks, like a code interpreter.
💬 Research Conclusions:
– Tool integration reduces memorization demands and improves test-time scaling performance, allowing a Llama-3.2 1B model to outperform a larger Llama-3.1 8B model in the MATH benchmark. It generalizes well to mathematical and multi-domain knowledge-intensive tasks, demonstrating significant improvements in self-verification capabilities of sLMs.
👉 Paper link: https://huggingface.co/papers/2504.04718

6. Concept Lancet: Image Editing with Compositional Representation Transplant
🔑 Keywords: Diffusion models, Image editing, Text embedding, Score space, CoLan
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to address the challenge of overestimating or underestimating edit strength in diffusion-based image editing tasks by introducing a more precise representation manipulation framework.
🛠️ Research Methods:
– The proposed method, Concept Lancet (CoLan), is a zero-shot plug-and-play framework that uses sparse linear combinations of representations from visual concepts for accurate concept estimation and editing direction.
💬 Research Conclusions:
– CoLan-equipped methods achieve state-of-the-art performance in editing effectiveness and consistency preservation, validated through experiments on various diffusion-based image editing baselines.
👉 Paper link: https://huggingface.co/papers/2504.02828

7. Quantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models
🔑 Keywords: Quantization, Reasoning Models, Inference Overhead, State-of-the-Art Algorithms, Mathematical Reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study systematically examines the application of quantization on reasoning language models to mitigate inference overhead.
🛠️ Research Methods:
– Evaluation of quantized models including DeepSeek-R1-Distilled Qwen and LLaMA across parameters ranging from 1.5B to 70B using state-of-the-art algorithms at different bit-widths on reasoning benchmarks.
💬 Research Conclusions:
– Lossless quantization with W8A8 or W4A16 is achievable, but lower bit-widths can significantly risk accuracy. Model size, origin, and task difficulty are crucial for performance, and model size or reasoning steps can be strategically scaled to enhance performance.
👉 Paper link: https://huggingface.co/papers/2504.04823

8. VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
🔑 Keywords: Value-based Reinforcement Learning, Proximal Policy Optimization, Long Chain-of-Thought Reasoning, AI Native
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce VAPO, a novel framework for reasoning models within the value-based paradigm, enhancing performance in long-CoT reasoning tasks.
🛠️ Research Methods:
– Utilize the Qwen 32B pre-trained model and benchmark against the AIME 2024 dataset, achieving state-of-the-art results with an efficient and stable training process.
💬 Research Conclusions:
– VAPO successfully addresses key challenges in value-based methods, surpassing previous models in performance by over 10 points, demonstrating reliability with no training crashes across independent runs.
👉 Paper link: https://huggingface.co/papers/2504.05118

9. LiveVQA: Live Visual Knowledge Seeking
🔑 Keywords: LiveVQA, Visual Reasoning, Multi-Hop Questions, Latest Visual Knowledge
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce LiveVQA, a dataset for visual question answering sourced automatically from the Internet, focusing on visual knowledge and question synthesis.
🛠️ Research Methods:
– Evaluation of 15 different multi-modal language models including GPT-4o and others to assess visual reasoning capabilities, particularly in addressing complex multi-hop visual questions.
💬 Research Conclusions:
– Stronger models excel in handling visual questions, yet there’s a notable performance gap in models using tools like search engines, underlining a need for future research in integrating current visual knowledge for enhanced performance.
👉 Paper link: https://huggingface.co/papers/2504.05288

10. Why Reasoning Matters? A Survey of Advancements in Multimodal Reasoning (v1)
🔑 Keywords: Reasoning, Large Language Models, Multimodal, Textual and Visual Integration, Post-Training Optimization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This paper aims to provide an overview of reasoning techniques within textual and multimodal large language models, highlighting the core challenges in integrating visual and textual inputs.
🛠️ Research Methods:
– The study involves a thorough comparison of recent advances, offering practical methods for post-training optimization and test-time inference.
💬 Research Conclusions:
– The research underscores significant challenges in multimodal reasoning, pointing out opportunities for improvement and providing guidance for future work in bridging theoretical and practical implementations.
👉 Paper link: https://huggingface.co/papers/2504.03151

11. Are You Getting What You Pay For? Auditing Model Substitution in LLM APIs
🔑 Keywords: Large Language Models, Model Substitution Detection, API, Trust, Benchmarking
💡 Category: Natural Language Processing
🌟 Research Objective:
– To address the trust challenge in accessing Large Language Models (LLMs) via black-box APIs by formalizing and systematically evaluating model substitution detection.
🛠️ Research Methods:
– Evaluation of existing verification techniques such as output-based statistical tests, benchmark evaluations, and log probability analysis under attack scenarios like model quantization and randomized substitution.
💬 Research Conclusions:
– Current methods relying solely on text outputs show limitations against subtle attacks; log probability analysis is more reliable but less accessible. Hardware-based solutions like Trusted Execution Environments (TEEs) are proposed to ensure model integrity, considering trade-offs between security and performance.
👉 Paper link: https://huggingface.co/papers/2504.04715

12. Gaussian Mixture Flow Matching Models
🔑 Keywords: Diffusion Models, Gaussian Mixture, Flow Matching, Image Generation
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces a novel Gaussian mixture flow matching (GMFlow) model to address limitations in existing diffusion and flow matching models related to sampling errors and color saturation.
🛠️ Research Methods:
– GMFlow predicts dynamic Gaussian mixture parameters instead of a single mean, and it employs KL divergence loss to capture a multi-modal flow velocity distribution.
– GM-SDE/ODE solvers are derived for precise few-step sampling.
– A novel probabilistic guidance scheme is implemented to reduce over-saturation and enhance image quality.
💬 Research Conclusions:
– GMFlow significantly improves the generation quality over baseline flow matching models, achieving a high precision with minimal sampling steps, as demonstrated on ImageNet 256×256.
👉 Paper link: https://huggingface.co/papers/2504.05304

13. DiaTool-DPO: Multi-Turn Direct Preference Optimization for Tool-Augmented Large Language Models
🔑 Keywords: Tool-Augmented Large Language Models, Dialogue Capabilities, Markov Decision Process, Direct Preference Optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce DiaTool-DPO to enhance dialogue capabilities of Tool-Augmented Large Language Models (TA-LLMs) through Direct Preference Optimization.
🛠️ Research Methods:
– Model TA-LLM interactions as a Markov Decision Process with distinct dialogue states and categorize user queries based on state transition trajectories.
– Automatically construct paired trajectory datasets of correct and incorrect dialogue flows with a specialized objective loss for dialogue control.
💬 Research Conclusions:
– DiaTool-DPO approaches GPT-4o’s performance in information gathering (94.8%) and tool call rejection (91%), significantly surpassing baseline results (44% and 9.6% respectively), all while preserving core functionality.
👉 Paper link: https://huggingface.co/papers/2504.02882

14. BOP Challenge 2024 on Model-Based and Model-Free 6D Object Pose Estimation
🔑 Keywords: 6D object pose estimation, model-free tasks, BOP-H3 datasets, model-based detection, real-world scenarios
💡 Category: Computer Vision
🌟 Research Objective:
– Transition the BOP Challenge from lab conditions to real-world scenarios, introducing new model-free tasks and practical 6D object detection.
🛠️ Research Methods:
– Evaluation conducted on seven challenge tracks, with new BOP-H3 datasets featuring high-resolution sensors and AR/VR headsets.
💬 Research Conclusions:
– Significant advancements were made with methods such as FreeZeV2.1 achieving notably higher accuracy and Co-op showing enhanced speed and practicality. Despite improvements, challenges remain in 2D detection accuracy for unseen objects.
👉 Paper link: https://huggingface.co/papers/2504.02812

15. Mamba as a Bridge: Where Vision Foundation Models Meet Vision Language Models for Domain-Generalized Semantic Segmentation
🔑 Keywords: Vision Foundation Models, Vision-Language Models, Domain Generalized Semantic Segmentation, MFuser, Attention Mechanisms
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The aim is to effectively integrate Vision Foundation Models (VFMs) and Vision-Language Models (VLMs) to enhance Domain Generalized Semantic Segmentation (DGSS).
🛠️ Research Methods:
– Introduction of a novel Mamba-based framework, MFuser, which combines VFMs and VLMs strengths using MVFuser for joint model fine-tuning and MTEnhancer for optimizing text embeddings with image priors.
💬 Research Conclusions:
– The proposed MFuser framework significantly surpasses existing DGSS methods, demonstrating high performance in synthetic-to-real and real-to-real benchmarks, achieving 68.20 mIoU and 71.87 mIoU respectively.
👉 Paper link: https://huggingface.co/papers/2504.03193

16. Clinical ModernBERT: An efficient and long context encoder for biomedical text
🔑 Keywords: Clinical ModernBERT, Biomedical Literature, Natural Language Processing, Flash Attention, Extended Context
💡 Category: AI in Healthcare
🌟 Research Objective:
– The objective is to develop Clinical ModernBERT, an advanced text encoder tailored for biomedical and clinical applications.
🛠️ Research Methods:
– Utilizes transformer-based encoder pretrained on extensive biomedical literature, clinical notes, and medical ontologies, with enhancements like rotary positional embeddings and Flash Attention.
💬 Research Conclusions:
– Clinical ModernBERT delivers semantically rich representations for long context tasks and demonstrates superior performance on clinical NLP benchmarks.
👉 Paper link: https://huggingface.co/papers/2504.03964

17. JailDAM: Jailbreak Detection with Adaptive Memory for Vision-Language Model
🔑 Keywords: Multimodal Large Language Models, Jailbreak Attacks, Harmful Content Detection, Memory-based Approach, Safety Mechanisms
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– The study aims to address the risks of harmful content generation in Multimodal Large Language Models (MLLMs) due to jailbreak attacks by developing a more effective detection framework.
🛠️ Research Methods:
– The introduction of JAILDAM, a test-time adaptive framework that uses a memory-based approach and policy-driven unsafe knowledge representations to detect jailbreak attacks without needing explicit harmful data exposure.
💬 Research Conclusions:
– The novel framework JAILDAM delivers state-of-the-art performance in detecting harmful content, showcasing improvements in both the accuracy and speed of detection compared to existing methods.
👉 Paper link: https://huggingface.co/papers/2504.03770

18. Distillation and Refinement of Reasoning in Small Language Models for Document Re-ranking
🔑 Keywords: Language Models, Reinforcement Learning, Reasoning-Intensive, Knowledge Distillation, Information Retrieval
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces a new method for training small language models focused on reasoning-intensive document ranking.
🛠️ Research Methods:
– Combines knowledge distillation and reinforcement learning optimization, using web data and a teacher LLM to generate training examples with relevance explanations.
💬 Research Conclusions:
– The proposed 3B parameter model achieves state-of-the-art results on the BRIGHT benchmark, outperforming larger models, and highlights the advantages of generating explanations during inference for reasoning effectiveness.
👉 Paper link: https://huggingface.co/papers/2504.03947

19. Sample, Don’t Search: Rethinking Test-Time Alignment for Language Models
🔑 Keywords: Test-Time Computation, QAlign, Reward Model, Markov Chain Monte Carlo, Mathematical Reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve language model performance at test time without needing model finetuning by introducing QAlign, an alignment approach that scales compute effectively.
🛠️ Research Methods:
– Implementing QAlign using Markov chain Monte Carlo for better alignment in text generation, achieving optimal distribution sampling for prompts without altering the base model or needing logit access.
💬 Research Conclusions:
– QAlign shows improvement in mathematical reasoning benchmarks and outperforms other compute methods on varied datasets, suggesting enhanced capabilities from existing language models without further training.
👉 Paper link: https://huggingface.co/papers/2504.03790

20. 3D Scene Understanding Through Local Random Access Sequence Modeling
🔑 Keywords: 3D scene understanding, computer vision, autoregressive generative approach, novel view synthesis, self-supervised depth estimation
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to advance 3D scene understanding from single images, which is crucial for applications in graphics, augmented reality, and robotics.
🛠️ Research Methods:
– Introduces a Local Random Access Sequence (LRAS) modeling approach, using local patch quantization and randomly ordered sequence generation with optical flow as an intermediate representation.
💬 Research Conclusions:
– Demonstrates state-of-the-art results in novel view synthesis and 3D object manipulation, and extends to effective self-supervised depth estimation.
👉 Paper link: https://huggingface.co/papers/2504.03875

21. Rethinking Multilingual Continual Pretraining: Data Mixing for Adapting LLMs Across Languages and Resources
🔑 Keywords: Large Language Models, Continual Pretraining, Multilingual, Low-resource Languages, Cross-lingual Transfer
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address performance disparities in Large Language Models across different language resources by evaluating the effectiveness of Continual Pretraining strategies.
🛠️ Research Methods:
– 36 Continual Pretraining configurations were systematically evaluated using three multilingual base models across over 30 languages categorized into altruistic, selfish, and stagnant types.
💬 Research Conclusions:
– Bilingual Continual Pretraining improves multilingual classification but can lead to language mixing issues during generation.
– Including programming code data enhances classification accuracy for low-resource languages but may slightly reduce generation quality.
– Significant deviations exist from previous language classifications, with nuanced impacts on cross-lingual transfer among different language types.
👉 Paper link: https://huggingface.co/papers/2504.04152

22. GlotEval: A Test Suite for Massively Multilingual Evaluation of Large Language Models
🔑 Keywords: Large Language Models (LLMs), multilingual evaluation, low-resource languages, GlotEval
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to address the lack of multilingual and low-resource language evaluations in large language models, which are predominantly English-focused.
🛠️ Research Methods:
– Introduction of GlotEval, a lightweight framework supporting seven key tasks for massively multilingual evaluation across dozens to hundreds of languages, with a focus on consistent benchmarking and language-specific prompts.
💬 Research Conclusions:
– GlotEval enables precise diagnosis of language model strengths and weaknesses, exemplified by a multilingual translation case study showcasing its applicability for both multilingual and language-specific evaluations.
👉 Paper link: https://huggingface.co/papers/2504.04155

23.
