AI Native Daily Paper Digest – 20250411

1. Kimi-VL Technical Report
🔑 Keywords: Mixture-of-Experts (MoE), Vision-Language Model (VLM), Multimodal Reasoning, Long Context Understanding, Reinforcement Learning (RL)
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The main objective is to develop Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model that excels in multimodal reasoning and long-context understanding while maintaining efficient agent capabilities.
🛠️ Research Methods:
– The model, Kimi-VL, includes a 128K extended context window for processing long inputs, and utilizes MoonViT for native-resolution vision encoding. It also involves long chain-of-thought supervised fine-tuning and reinforcement learning for the advanced variant Kimi-VL-Thinking.
💬 Research Conclusions:
– Kimi-VL demonstrates competitive performance compared to state-of-the-art efficient VLMs, achieving high scores on various benchmarks and setting a new standard for efficient multimodal thinking models while maintaining a compact 2.8B activated parameters. The model and its code are publicly available for further use.
👉 Paper link: https://huggingface.co/papers/2504.07491

2. VCR-Bench: A Comprehensive Evaluation Framework for Video Chain-of-Thought Reasoning
🔑 Keywords: Chain-of-Thought, LVLMs, Video Reasoning, Benchmark, Perception
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper introduces VCR-Bench, a novel benchmark designed to evaluate the Video Chain-of-Thought (CoT) reasoning capabilities of large vision-language models (LVLMs).
🛠️ Research Methods:
– VCR-Bench includes 859 videos with 1,034 question-answer pairs, each annotated with stepwise CoT rationale to indicate association with perception or reasoning. It also involves the design of seven distinct task dimensions and proposes a CoT score.
💬 Research Conclusions:
– Experiments on VCR-Bench reveal limitations in current LVLMs, highlighting their challenges in temporal-spatial information processing. A robust correlation between CoT scores and accuracy showcases the framework’s validity, with the hope that VCR-Bench will become a standardized evaluation tool in the field.
👉 Paper link: https://huggingface.co/papers/2504.07956

3. VisualCloze: A Universal Image Generation Framework via Visual In-Context Learning
🔑 Keywords: Diffusion Models, Universal Image Generation, Graph-Structured Dataset, Visual In-Context Learning
💡 Category: Generative Models
🌟 Research Objective:
– To develop a universal image generation framework, VisualCloze, that supports a wide range of in-domain and unseen tasks through visual demonstrations.
🛠️ Research Methods:
– Introduced a graph-structured dataset, Graph200K, to improve task density and knowledge transferability.
– Implemented visual in-context learning to allow models to identify tasks through visual demonstrations instead of language-based instructions.
💬 Research Conclusions:
– VisualCloze effectively addresses the limitations of task-specific models by leveraging pre-trained infilling models, ensuring a consistent image generation objective and enhancing generalizability.
👉 Paper link: https://huggingface.co/papers/2504.07960
4. DeepSeek-R1 Thoughtology: Let’s about LLM Reasoning
🔑 Keywords: Large Reasoning Models, DeepSeek-R1, reasoning chains, cognitive phenomena, safety vulnerabilities
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To investigate DeepSeek-R1’s reasoning processes and its implications for cognitive phenomena and safety concerns.
🛠️ Research Methods:
– Analyzed DeepSeek-R1’s basic reasoning structures, impact of thought length, and management of contexts.
💬 Research Conclusions:
– DeepSeek-R1 exhibits a ‘sweet spot’ of reasoning where extra inference time can hinder performance and shows tendencies to ruminate on previous problem formulations. Strong safety vulnerabilities were noted compared to non-reasoning models.
👉 Paper link: https://huggingface.co/papers/2504.07128

5. MM-IFEngine: Towards Multimodal Instruction Following
🔑 Keywords: Multi-modal Large Language Models, Instruction Following, Supervised Fine-Tuning, Direct Preference Optimization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address the scarcity of multimodal instruction following training data, providing a comprehensive pipeline for generating high-quality image-instruction pairs.
🛠️ Research Methods:
– Introduction of MM-IFEngine pipeline to produce a large-scale dataset MM-IFInstruct-23k.
– Development of a benchmark MM-IFEval for evaluating multi-modal instruction following with detailed constraints.
– Conducting experiments using both Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) on newly developed datasets.
💬 Research Conclusions:
– Fine-tuning Multi-modal Large Language Models on MM-IFInstruct-23k and MM-IFDPO-23k significantly improves performance across various benchmarks, showcasing notable gains such as MM-IFEval (+10.2%), MIA (+7.6%), and IFEval (+12.3%).
👉 Paper link: https://huggingface.co/papers/2504.07957

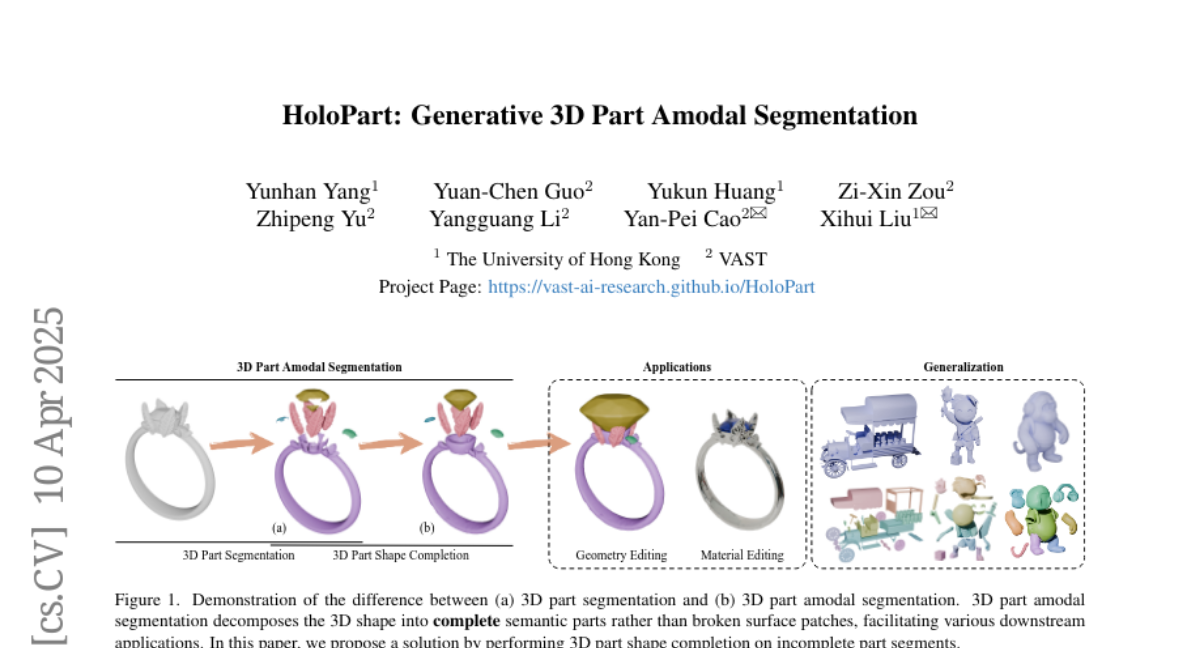
6. HoloPart: Generative 3D Part Amodal Segmentation
🔑 Keywords: 3D part amodal segmentation, HoloPart, shape completion, geometry editing, animation
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce 3D part amodal segmentation to the 3D domain for improved content creation and understanding.
🛠️ Research Methods:
– Develop a two-stage approach with HoloPart, a novel diffusion-based model, to complete 3D segments and ensure shape consistency.
💬 Research Conclusions:
– HoloPart significantly outperforms existing shape completion methods and opens new application avenues in 3D domains.
👉 Paper link: https://huggingface.co/papers/2504.07943
7. C3PO: Critical-Layer, Core-Expert, Collaborative Pathway Optimization for Test-Time Expert Re-Mixing
🔑 Keywords: Mixture-of-Experts, Large Language Models, Test-time Optimization, C3PO, Efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address the sub-optimal expert pathways in Mixture-of-Experts (MoE) Large Language Models by improving accuracy through novel optimization methods.
🛠️ Research Methods:
– It introduces test-time optimization techniques such as re-weighting experts using surrogate objectives based on “successful neighbors” from a reference set and applies mode-finding, kernel regression, and average loss strategies.
– The C3PO method focuses optimization on core experts’ mixing weights in critical layers to boost performance without significant computational costs.
💬 Research Conclusions:
– C3PO significantly enhances accuracy by 7-15% on two MoE LLMs across six benchmarks, outperforming traditional test-time learning methods and enabling smaller parameter models to rival much larger counterparts, thus improving MoE efficiency.
👉 Paper link: https://huggingface.co/papers/2504.07964

8. MOSAIC: Modeling Social AI for Content Dissemination and Regulation in Multi-Agent Simulations
🔑 Keywords: MOSAIC, generative language agents, social network simulation, misinformation, open-source
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To explore how users determine the veracity of online social content through a novel simulation framework that combines generative language agents with social graphs.
🛠️ Research Methods:
– Utilizing multi-agent simulations to model content dissemination and engagement dynamics by creating user representations from diverse personas. The study evaluates three different content moderation strategies within the simulation.
💬 Research Conclusions:
– The evaluated content moderation strategies not only mitigate non-factual content spread but also increase user engagement. Additionally, the analysis explores if the reasoning of simulation agents aligns with their engagement patterns.
👉 Paper link: https://huggingface.co/papers/2504.07830

9. Scaling Laws for Native Multimodal Models Scaling Laws for Native Multimodal Models
🔑 Keywords: Native Multimodal Models, Multi-Modal Learning, Mixture of Experts, Early-Fusion, Late-Fusion
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To investigate the architectural design of native multimodal models and compare early-fusion and late-fusion approaches in terms of efficiency and performance.
🛠️ Research Methods:
– Conducted an extensive scaling laws study on 457 trained models with various architectures and training mixtures.
💬 Research Conclusions:
– Early-fusion architectures outperform late-fusion ones, showcasing better performance with lower parameter counts, and improved training and deployment efficiency.
– Incorporation of Mixture of Experts enhances the modality-specific learning and performance of early-fusion models.
👉 Paper link: https://huggingface.co/papers/2504.07951

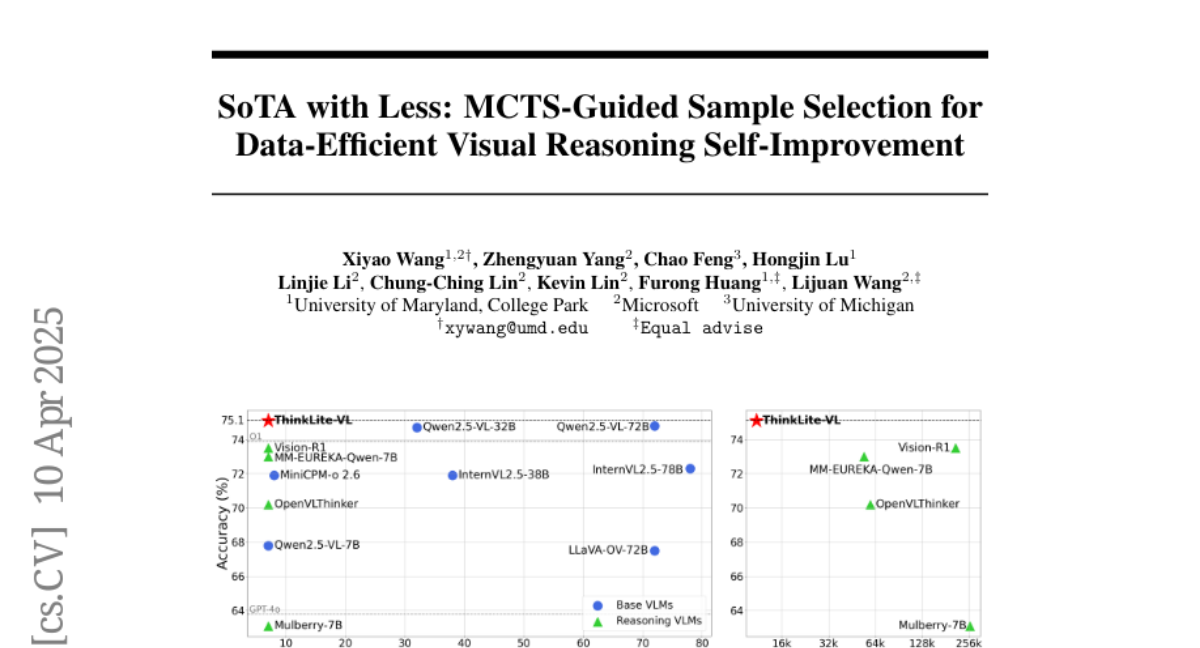
10. SoTA with Less: MCTS-Guided Sample Selection for Data-Efficient Visual Reasoning Self-Improvement
🔑 Keywords: Visual Reasoning, Self-Improvement, Reinforcement Fine-Tuning, Monte Carlo Tree Search, VLMs
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To enhance visual reasoning with fewer training samples through self-improvement without using knowledge distillation.
🛠️ Research Methods:
– Developed a novel Monte Carlo Tree Search-based selection method to quantify the difficulty of training samples, retaining challenging samples for effective reinforcement fine-tuning.
💬 Research Conclusions:
– ThinkLite-VL improves the previous model’s performance by 7% on average with only 11k samples, achieving state-of-the-art accuracy on the MathVista benchmark, outperforming several advanced models.
👉 Paper link: https://huggingface.co/papers/2504.07934
11. Towards Visual Text Grounding of Multimodal Large Language Model
🔑 Keywords: Multimodal Large Language Models, Text-Rich Image Grounding, Document Question-Answering, OCR-LLM-human interaction
💡 Category: Multimodal Learning
🌟 Research Objective:
– The research introduces TRIG, a novel task and dataset to enhance the Text-Rich Image Grounding capabilities in document question-answering by addressing the limitations in current MLLMs.
🛠️ Research Methods:
– Developed an OCR-LLM-human interaction pipeline to generate 800 annotated question-answer pairs and a large-scale synthetic dataset from four diverse datasets.
– Proposed two methods: general instruction tuning and plug-and-play efficient embedding for enhancing MLLMs.
💬 Research Conclusions:
– Evaluation of MLLMs on the TRIG benchmark reveals substantial limitations in grounding capability in text-rich images.
– Fine-tuning with the synthetic dataset improves spatial reasoning and grounding capabilities.
👉 Paper link: https://huggingface.co/papers/2504.04974

12. TAPNext: Tracking Any Point (TAP) as Next Token Prediction
🔑 Keywords: Tracking Any Point, TAPNext, computer vision, AI Native
💡 Category: Computer Vision
🌟 Research Objective:
– The research focuses on redefining Tracking Any Point (TAP) as sequential masked token decoding to enhance scalability and general applicability.
🛠️ Research Methods:
– TAPNext employs a causal model that operates in a purely online fashion, eliminating the need for traditional tracking-specific inductive biases and heuristics.
💬 Research Conclusions:
– TAPNext achieves state-of-the-art performance in both online and offline tracking scenarios, demonstrating superior performance while naturally incorporating widely used tracking heuristics through end-to-end training.
👉 Paper link: https://huggingface.co/papers/2504.05579

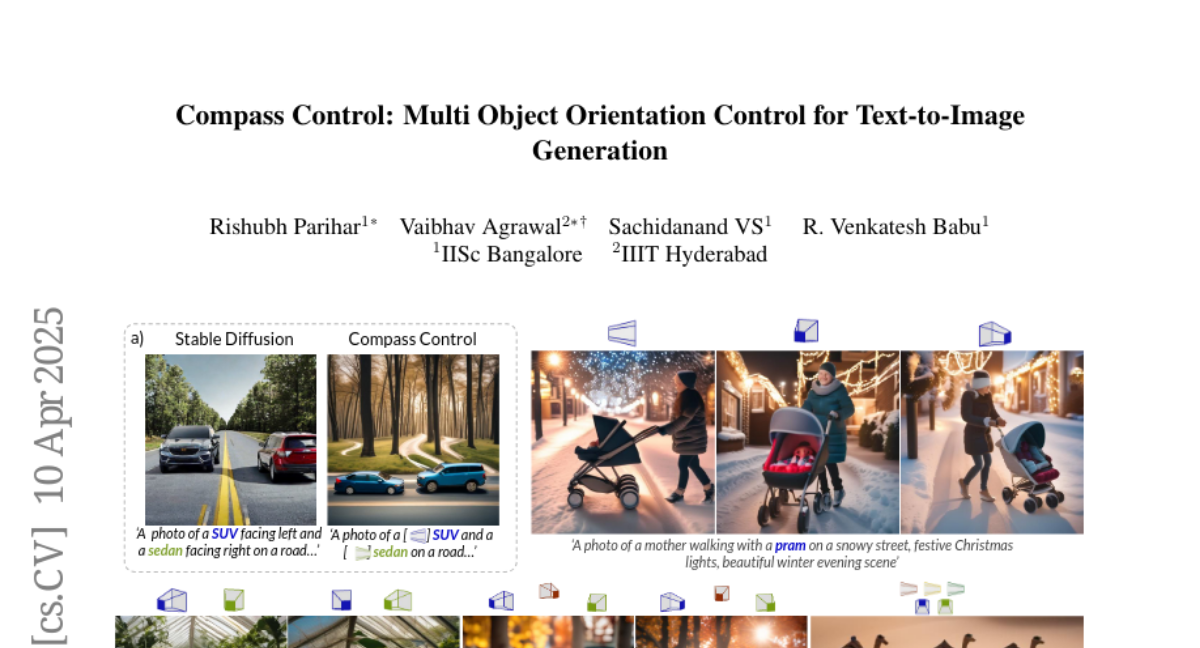
13. Compass Control: Multi Object Orientation Control for Text-to-Image Generation
🔑 Keywords: 3D object-centric control, text-to-image diffusion models, orientation control, compass tokens, generative models
💡 Category: Generative Models
🌟 Research Objective:
– Address the challenge of multi-object orientation control in text-to-image diffusion models to enable diverse scene generation with precise control of each object’s orientation.
🛠️ Research Methods:
– Introduce orientation-aware compass tokens conditioned with a lightweight encoder to manage object orientation in synthetic datasets and apply cross-attention maps for avoiding object entanglement.
💬 Research Conclusions:
– The proposed method demonstrates state-of-the-art orientation control and text alignment with strong generalization, effective on both unseen complex objects and multi-object scenes, enhanced by personalization techniques.
👉 Paper link: https://huggingface.co/papers/2504.06752
14. MonoPlace3D: Learning 3D-Aware Object Placement for 3D Monocular Detection
🔑 Keywords: Monocular 3D Detectors, Synthetic Data Generation, Data Augmentation, MonoPlace3D
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce MonoPlace3D to enhance realism in augmented datasets for monocular 3D detectors by focusing on realistic object placement in outdoor scenes.
🛠️ Research Methods:
– Develop a system that determines realistic object placement parameters including position, dimensions, and alignment by learning a distribution over plausible 3D bounding boxes.
💬 Research Conclusions:
– MonoPlace3D significantly improves the accuracy of multiple existing monocular 3D detectors on datasets like KITTI and NuScenes while using data efficiently.
👉 Paper link: https://huggingface.co/papers/2504.06801

15. Geo4D: Leveraging Video Generators for Geometric 4D Scene Reconstruction
🔑 Keywords: Geo4D, video diffusion models, 3D reconstruction, dynamic scenes, zero-shot
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce Geo4D for monocular 3D reconstruction in dynamic scenes using video diffusion models.
🛠️ Research Methods:
– Utilizes a novel multi-modal alignment algorithm and leverages synthetic data with zero-shot generalization to real data.
💬 Research Conclusions:
– Geo4D outperforms state-of-the-art methods in video depth estimation across multiple benchmarks.
👉 Paper link: https://huggingface.co/papers/2504.07961

16.
