AI Native Daily Paper Digest – 20250415

1. InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
🔑 Keywords: InternVL3, multimodal pre-training paradigm, MLLM, V2PE, open-source MLLMs
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce InternVL3, a significant advancement in the InternVL series, featuring a native multimodal pre-training paradigm.
🛠️ Research Methods:
– Utilizes a unified training paradigm with multimodal and linguistic capabilities from diverse multimodal data and pure-text corpora.
– Incorporates variable visual position encoding (V2PE), supervised fine-tuning (SFT), mixed preference optimization (MPO), and test-time scaling strategies.
💬 Research Conclusions:
– InternVL3 delivers superior performance across a wide range of multi-modal tasks and achieves a state-of-the-art score on the MMMU benchmark.
– Achieves high competitiveness with leading proprietary models while maintaining strong pure-language proficiency.
– Training data and model weights will be publicly released to promote further research and development in next-generation MLLMs.
👉 Paper link: https://huggingface.co/papers/2504.10479

2. PRIMA.CPP: Speeding Up 70B-Scale LLM Inference on Low-Resource Everyday Home Clusters
🔑 Keywords: AI Systems and Tools, Distributed Inference System, piped-ring parallelism, model quantization, Halda algorithm
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce prima.cpp, a distributed inference system designed to run 70B-scale language models efficiently on common home devices, addressing the existing limitations of hardware and memory.
🛠️ Research Methods:
– Utilizes mmap to manage model weights and employs piped-ring parallelism with prefetching to optimize performance. Implements an algorithm named Halda to effectively solve the NP-hard assignment problem for CPU/GPU computation distribution.
💬 Research Conclusions:
– Prima.cpp succeeds in outperforming other solutions like llama.cpp and exo while maintaining low memory pressure, making advanced AI models accessible for home assistants and individuals using commonplace hardware setups.
👉 Paper link: https://huggingface.co/papers/2504.08791
3. Have we unified image generation and understanding yet? An empirical study of GPT-4o’s image generation ability
🔑 Keywords: multimodal GPT-4o, semantic synthesis, Global Instruction Adherence, Fine-Grained Editing Precision, context-aware
💡 Category: Generative Models
🌟 Research Objective:
– The study evaluates the capabilities of OpenAI’s multimodal GPT-4o in world knowledge-informed semantic synthesis.
🛠️ Research Methods:
– Systematic evaluation across three dimensions: Global Instruction Adherence, Fine-Grained Editing Precision, and Post-Generation Reasoning.
💬 Research Conclusions:
– Findings reveal limitations in GPT-4o’s ability to integrate dynamic knowledge seamlessly, challenging assumptions about its unified understanding. The study advocates for improved benchmarks and training strategies.
👉 Paper link: https://huggingface.co/papers/2504.08003

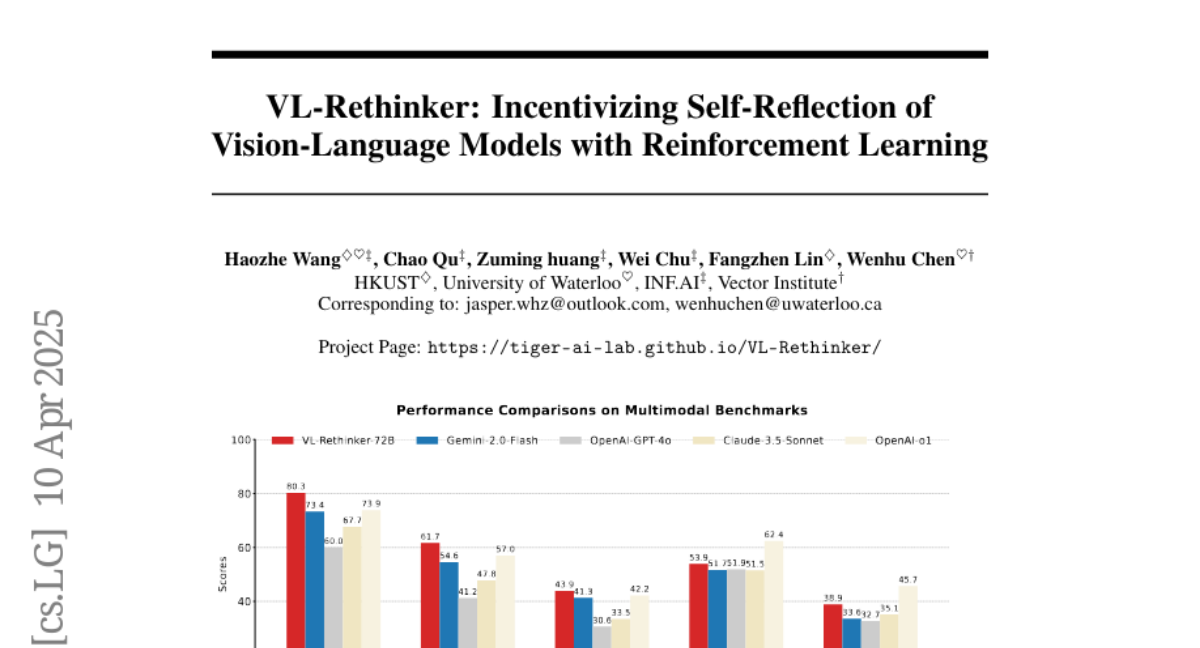
4. VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
🔑 Keywords: Slow-thinking systems, Vision-language models, Reinforcement Learning, Self-reflection, State-of-the-art
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to enhance the slow-thinking capabilities of vision-language models using reinforcement learning without relying on distillation, to advance state of the art in multimodal reasoning.
🛠️ Research Methods:
– Adaptation of the GRPO algorithm with the novel Selective Sample Replay (SSR) technique to address vanishing advantages.
– Introduction of Forced Rethinking to enforce self-reflection reasoning steps.
💬 Research Conclusions:
– The VL-Rethinker model significantly improves state-of-the-art scores on MathVista, MathVerse, and MathVision benchmarks.
– Achieves open-source state-of-the-art on multi-disciplinary benchmarks such as MMMU-Pro, EMMA, and MEGA-Bench, closing the performance gap with GPT-o1.
👉 Paper link: https://huggingface.co/papers/2504.08837
5. FUSION: Fully Integration of Vision-Language Representations for Deep Cross-Modal Understanding
🔑 Keywords: multimodal large language models, vision-language alignment, pixel-level integration, full-modality integration, high-quality QA pairs
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce FUSION, a series of multimodal large language models with complete vision-language alignment and integration.
🛠️ Research Methods:
– Develop Text-Guided Unified Vision Encoding for deep integration and Context-Aware Recursive Alignment Decoding for fine-grained semantic integration.
– Implement Dual-Supervised Semantic Mapping Loss and create a Synthesized Language-Driven Question-Answer dataset to enhance text-guided feature integration.
💬 Research Conclusions:
– FUSION models outperform existing methods, notably exceeding Cambrian-1 8B and Florence-VL 8B in benchmark tests.
– Open-sourced code, model weights, and datasets demonstrate the effectiveness of the approach.
👉 Paper link: https://huggingface.co/papers/2504.09925

6. Iterative Self-Training for Code Generation via Reinforced Re-Ranking
🔑 Keywords: Proximal Policy Optimization, Reranker Model, Iterative Self-Training, Code Generation, GPT-4
💡 Category: Generative Models
🌟 Research Objective:
– To enhance code generation by improving reranking accuracy using an iterative self-training approach with Proximal Policy Optimization.
🛠️ Research Methods:
– Paired a code generation model with a reranker model and utilized iterative self-training to refine the training dataset, focusing on reranking through identifying and incorporating high-scoring negative examples.
💬 Research Conclusions:
– Demonstrated superior performance on the MultiPL-E dataset with a 13.4B parameter model that outperforms a larger 33B model and achieves comparable results to GPT-4, excelling in at least one programming language.
👉 Paper link: https://huggingface.co/papers/2504.09643

7. Mavors: Multi-granularity Video Representation for Multimodal Large Language Model
🔑 Keywords: Multimodal Large Language Models, Long-video Modeling, Vision Transformers, Spatio-temporal Reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a framework, Mavors, for balancing computational efficiency with the retention of fine-grained spatio-temporal patterns in long-context video understanding.
🛠️ Research Methods:
– Introduced Multi-granularity video representation via raw video content encoding using an Intra-chunk Vision Encoder for high-resolution spatial features, and an Inter-chunk Feature Aggregator for temporal coherence across chunks.
💬 Research Conclusions:
– Mavors significantly outperforms existing methods in tasks requiring fine-grained spatio-temporal reasoning, maintaining both spatial fidelity and temporal continuity.
👉 Paper link: https://huggingface.co/papers/2504.10068

8. AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories
🔑 Keywords: Web agents, Evaluation, LLMs, Benchmark, Automatic evaluations
💡 Category: Human-AI Interaction
🌟 Research Objective:
– Introduce AgentRewardBench, the first benchmark to evaluate the effectiveness of LLM judges in assessing web agents.
🛠️ Research Methods:
– Analyze 1302 trajectories across 5 benchmarks and 4 LLMs, with expert reviews assessing success, side effects, and repetitiveness.
💬 Research Conclusions:
– No single LLM excels across all benchmarks; rule-based evaluations underreport web agents’ success, highlighting the need for more flexible automatic evaluations.
👉 Paper link: https://huggingface.co/papers/2504.08942

9. S1-Bench: A Simple Benchmark for Evaluating System 1 Thinking Capability of Large Reasoning Models
🔑 Keywords: S1-Bench, Large Reasoning Models, system 1 thinking, evaluation, reasoning patterns
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To introduce S1-Bench, a new benchmark for evaluating Large Reasoning Models on tasks favoring intuitive system 1 thinking over analytic system 2 reasoning.
🛠️ Research Methods:
– S1-Bench comprises simple, diverse questions across multiple domains and languages, aimed at testing LRMs’ intuitive reasoning abilities.
💬 Research Conclusions:
– LRMs exhibit inefficiencies, producing longer outputs and showing rigid reasoning patterns, with a need for development towards balanced dual-system thinking adaptable to task complexity.
👉 Paper link: https://huggingface.co/papers/2504.10368

10. Breaking the Data Barrier — Building GUI Agents Through Task Generalization
🔑 Keywords: GUI agents, Vision Language Models, Task generalization, Multimodal reasoning, Cross-domain knowledge transfer
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to enhance the performance of GUI agents by addressing the scarcity of high-quality trajectory data through mid-training Vision Language Models on data-rich tasks.
🛠️ Research Methods:
– Utilize a dedicated mid-training stage for Vision Language Models, focusing on tasks like GUI perception, multimodal reasoning, and textual reasoning with available instruction-tuning data.
💬 Research Conclusions:
– Extensive experiments demonstrate substantial task generalization leading to significant improvements in GUI planning scenarios, with notable cross-modal gains from text to visual domains. Surprisingly, GUI perception data impacts performance less than expected. Optimized mid-training tasks result in performance gains of up to 12.2% on specific platforms.
👉 Paper link: https://huggingface.co/papers/2504.10127

11. DUMP: Automated Distribution-Level Curriculum Learning for RL-based LLM Post-training
🔑 Keywords: Reinforcement Learning, Large Language Models, Curriculum Learning, Upper Confidence Bound, Distribution-aware
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance reasoning capabilities of Large Language Models (LLMs) by developing a curriculum learning framework grounded in distribution-level learnability for RL-based post-training.
🛠️ Research Methods:
– Implemented a curriculum learning framework leveraging the Upper Confidence Bound (UCB) principle to dynamically adjust sampling in training based on distribution-level policy advantages.
– Used GRPO as the underlying RL algorithm for validating the framework on diverse logic reasoning datasets.
💬 Research Conclusions:
– The distribution-aware curriculum learning framework significantly improves convergence speed and final performance of LLMs, underscoring the value of adaptive and distribution-sensitive training strategies.
👉 Paper link: https://huggingface.co/papers/2504.09710

12. Executable Functional Abstractions: Inferring Generative Programs for Advanced Math Problems
🔑 Keywords: EFA, EFAGen, program synthesis, advanced math problems, LLM
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The objective is to explore the automatic construction of Executable Functional Abstractions (EFAs) for advanced math problems, moving beyond human-engineered solutions typical in prior work.
🛠️ Research Methods:
– Introduces EFAGen, leveraging program synthesis techniques, where a large language model (LLM) is conditioned on a seed math problem and its solution to generate EFAs.
💬 Research Conclusions:
– EFAs generated by EFAGen are shown to adhere to seed problems faithfully, facilitate learnable variations, and are applicable across diverse problem sources. Additionally, model-generated EFAs aid in finding problem variations that adjust difficulty for learners and contribute to data generation.
👉 Paper link: https://huggingface.co/papers/2504.09763

13. SocioVerse: A World Model for Social Simulation Powered by LLM Agents and A Pool of 10 Million Real-World Users
🔑 Keywords: Social simulation, Large Language Models, SocioVerse, Population Dynamics, Interaction Mechanisms
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to transform traditional social science research by modeling human behavior through a large language model-driven framework, SocioVerse, for social simulation.
🛠️ Research Methods:
– The researchers introduced SocioVerse, featuring four alignment components and a user pool of 10 million real individuals, and conducted large-scale simulation experiments across politics, news, and economics.
💬 Research Conclusions:
– SocioVerse effectively captures large-scale population dynamics ensuring diversity, credibility, and representativeness with standardized procedures and minimal manual adjustments.
👉 Paper link: https://huggingface.co/papers/2504.10157

14. MIEB: Massive Image Embedding Benchmark
🔑 Keywords: Image Embedding Models, Massive Image Embedding Benchmark, Visual Representation, Multimodal Large Language Models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To evaluate the performance of image and image-text embedding models across a broad spectrum using the Massive Image Embedding Benchmark (MIEB) with 130 tasks in 38 languages.
🛠️ Research Methods:
– Introduced and utilized the MIEB, benchmarking 50 models into 8 high-level categories to reveal model capabilities and limitations.
💬 Research Conclusions:
– No single model excels across all categories, but advanced vision models demonstrated accurate visual representation of texts with limitations in interleaved encodings and matching in the presence of confounders.
– Vision encoder performance on MIEB correlates with performance in multimodal large language models.
👉 Paper link: https://huggingface.co/papers/2504.10471

15. TinyLLaVA-Video-R1: Towards Smaller LMMs for Video Reasoning
🔑 Keywords: Reinforcement Learning, Multimodal Models, Video Understanding, Reasoning Capabilities
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance reasoning capabilities of small-scale multimodal models using reinforcement learning on general question-answering datasets.
🛠️ Research Methods:
– Development of TinyLLaVA-Video-R1, a small-scale video reasoning model with traceable training, expanded reasoning using reinforcement learning.
💬 Research Conclusions:
– TinyLLaVA-Video-R1 displays significant improvement in reasoning and thinking abilities, with emergent “aha moments” observed, providing insights for exploring video reasoning in small-scale models.
👉 Paper link: https://huggingface.co/papers/2504.09641

16. The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
🔑 Keywords: AI Science, Peer Review, Vision-Language Model, Autonomous Scientific Discovery, AI Safety
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce The AI Scientist-v2, an autonomous system capable of generating AI-created, peer-reviewed research papers.
🛠️ Research Methods:
– Utilizes a novel progressive agentic tree-search methodology and integrates a Vision-Language Model feedback loop for content refinement.
💬 Research Conclusions:
– Demonstrated capability by successfully submitting an AI-generated manuscript to a peer-reviewed workshop, highlighting AI’s potential in revolutionizing scientific research.
👉 Paper link: https://huggingface.co/papers/2504.08066

17. VisuoThink: Empowering LVLM Reasoning with Multimodal Tree Search
🔑 Keywords: VisuoThink, Large Vision-Language Models, multimodal slow thinking, look-ahead tree search, progressive visual-textual reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to enhance complex reasoning tasks in Large Vision-Language Models by introducing VisuoThink, which integrates visuospatial and linguistic domains to mimic human-like slow thinking.
🛠️ Research Methods:
– The research employs a novel framework that facilitates multimodal slow thinking through progressive visual-textual reasoning and incorporates test-time scaling with look-ahead tree search.
💬 Research Conclusions:
– VisuoThink significantly improves reasoning capabilities in geometric and spatial tasks, achieving state-of-the-art performance without the need for fine-tuning.
👉 Paper link: https://huggingface.co/papers/2504.09130

18. LLM-SRBench: A New Benchmark for Scientific Equation Discovery with Large Language Models
🔑 Keywords: Scientific equation discovery, Large Language Models, LLM-SRBench, symbolic accuracy
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the true discovery capabilities of Large Language Models for scientific equation discovery with a comprehensive benchmark named LLM-SRBench.
🛠️ Research Methods:
– Introduction of LLM-SRBench with 239 challenging problems across four scientific domains, divided into LSR-Transform and LSR-Synth categories, focusing on preventing trivial memorization.
💬 Research Conclusions:
– Extensive evaluation reveals that the best-performing system achieved only 31.5% symbolic accuracy, highlighting the challenges in the current scientific equation discovery methods using LLMs.
👉 Paper link: https://huggingface.co/papers/2504.10415

19. How new data permeates LLM knowledge and how to dilute it
🔑 Keywords: Large Language Models, Gradient-based Updates, Priming Effect, Token Probability, Knowledge Insertion
💡 Category: Natural Language Processing
🌟 Research Objective:
– To understand how new information affects existing knowledge in large language models, leading to either beneficial generalization or problematic hallucination.
🛠️ Research Methods:
– Introduction of a dataset called “Outlandish” with 1320 text samples to study the priming effect.
– Measurement of token probability in different model architectures to predict the degree of priming.
– Development of two novel techniques: stepping-stone text augmentation and ignore-k update pruning.
💬 Research Conclusions:
– The priming effect can be predicted and quantified using token probability.
– Novel methods significantly decrease undesirable priming while preserving the learning ability of models.
– This research provides empirical insights and practical tools for improving knowledge integration in language models.
👉 Paper link: https://huggingface.co/papers/2504.09522

20. EmoAgent: Assessing and Safeguarding Human-AI Interaction for Mental Health Safety
🔑 Keywords: LLM-driven AI characters, EmoAgent, multi-agent AI framework, mental health hazards, human-AI interactions
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To evaluate and mitigate mental health hazards associated with human-AI interactions, especially concerning vulnerable users.
🛠️ Research Methods:
– The proposed EmoAgent comprises EmoEval, which simulates virtual users for mental health assessment using clinically proven tools, and EmoGuard, which monitors, predicts, and mitigates potential harm in interactions.
💬 Research Conclusions:
– Experiments indicate that character-based chatbots can lead to psychological deterioration in users, with EmoGuard significantly reducing the risk of deterioration, highlighting its importance in safer AI-human interactions.
👉 Paper link: https://huggingface.co/papers/2504.09689

21. M1: Towards Scalable Test-Time Compute with Mamba Reasoning Models
🔑 Keywords: LLMs, transformer-based models, hybrid linear RNN reasoning model, Mamba architecture, RL training
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce a novel hybrid linear RNN reasoning model called M1 for efficient memory use and improved reasoning performance.
🛠️ Research Methods:
– Utilized a distillation process from existing models and enhanced with reinforcement learning (RL) training.
– Performance compared using AIME and MATH benchmarks, as well as generation speed comparison with vLLM.
💬 Research Conclusions:
– M1 outperformed previous linear RNN models and matched state-of-the-art models at a similar scale.
– Achieved over 3x generation speedup compared to identical size transformers and superior accuracy under time constraints using self-consistency voting.
👉 Paper link: https://huggingface.co/papers/2504.10449

22. MDK12-Bench: A Multi-Discipline Benchmark for Evaluating Reasoning in Multimodal Large Language Models
🔑 Keywords: Multimodal reasoning, Multimodal Large Language Models, MDK12-Bench, Artificial General Intelligence, data contamination issues
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to evaluate the multimodal reasoning capabilities of Multimodal Large Language Models (MLLMs) using a comprehensive benchmark named MDK12-Bench.
🛠️ Research Methods:
– Introduction of MDK12-Bench, a benchmark consisting of 140K reasoning instances across six disciplines with detailed annotations. It spans difficulty levels and includes a dynamic evaluation framework to address data contamination.
💬 Research Conclusions:
– Current MLLMs show significant limitations in multimodal reasoning, as revealed by experiments on the MDK12-Bench, suggesting areas for development in future models.
👉 Paper link: https://huggingface.co/papers/2504.05782

23. 3D CoCa: Contrastive Learners are 3D Captioners
🔑 Keywords: 3D captioning, contrastive vision-language learning, multi-modal decoder, semantic grounding, shared feature space
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To propose 3D CoCa, a unified framework designed to enhance the description of 3D scenes by integrating contrastive vision-language learning with 3D caption generation.
🛠️ Research Methods:
– Leveraging a frozen CLIP vision-language backbone for semantic priors.
– Employing a spatially-aware 3D scene encoder for geometric context and a multi-modal decoder for descriptive captions.
– Joint optimization of contrastive and captioning objectives in a shared feature space, eliminating the need for external detectors.
💬 Research Conclusions:
– 3D CoCa achieves significant improvements over existing methods, with superior performance on ScanRefer and Nr3D benchmarks, showing 10.2% and 5.76% gains in CIDEr scores at 0.5IoU, respectively.
👉 Paper link: https://huggingface.co/papers/2504.09518

24. Reasoning Models Can Be Effective Without Thinking
🔑 Keywords: NoThinking, Thinking process, low-budget settings, token, parallel scaling
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to evaluate the necessity of the lengthy Thinking process in LLMs by exploring the effectiveness of a simple prompting method called NoThinking.
🛠️ Research Methods:
– Utilized the state-of-the-art DeepSeek-R1-Distill-Qwen model and compared the performance of NoThinking and Thinking processes across seven challenging reasoning datasets.
💬 Research Conclusions:
– NoThinking outperformed the Thinking process in several challenging reasoning scenarios, especially in low-budget settings and with fewer tokens, encouraging a reevaluation of the need for elaborate thinking processes.
👉 Paper link: https://huggingface.co/papers/2504.09858

25. DeepSeek vs. o3-mini: How Well can Reasoning LLMs Evaluate MT and Summarization?
🔑 Keywords: Reasoning-enabled LLMs, Natural Language Generation, Machine Translation, Text Summarization, Reasoning Capabilities
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to evaluate reasoning-enabled large language models (LLMs) in the context of machine translation (MT) and text summarization (TS).
🛠️ Research Methods:
– Systematic comparison of reasoning-based LLMs like DeepSeek-R1 and OpenAI o3 with their non-reasoning counterparts across evaluation tasks.
– Experiments conducted across eight models in three architectural categories on WMT23 and SummEval benchmarks.
💬 Research Conclusions:
– Reasoning capabilities show varying benefits depending on the model and task. OpenAI o3 models generally perform better with increased reasoning intensity, while DeepSeek-R1 performs worse except in specific TS evaluation aspects.
– Correlation analysis indicates a positive relationship between increased reasoning token usage and evaluation quality in certain models.
– Distilled reasoning capabilities maintain performance in medium-sized models but degrade significantly in smaller ones.
👉 Paper link: https://huggingface.co/papers/2504.08120

26. LLM Can be a Dangerous Persuader: Empirical Study of Persuasion Safety in Large Language Models
🔑 Keywords: Large Language Models, persuasion safety, ethical influence, PersuSafety, AI Ethics
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– Investigate the safety risks associated with Large Language Models in performing persuasion tasks, focusing on their ability to reject unethical persuasion and the impact of external factors.
🛠️ Research Methods:
– Introduced a comprehensive framework, PersuSafety, consisting of persuasion scene creation, persuasive conversation simulation, and persuasion safety assessment across 8 widely used LLMs.
💬 Research Conclusions:
– Identified significant safety concerns in LLMs, including failure to detect harmful persuasion tasks and use of unethical strategies, highlighting the need for improved safety alignment in AI-driven persuasive interactions.
👉 Paper link: https://huggingface.co/papers/2504.10430

27. MCP Safety Audit: LLMs with the Model Context Protocol Allow Major Security Exploits
🔑 Keywords: MCP, large language models, security risks, MCPSafetyScanner, automated workflows
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To reduce development overhead and enable seamless integration between potential components of generative AI applications using the Model Context Protocol (MCP).
🛠️ Research Methods:
– Presented the MCPSafetyScanner tool, which utilizes several agents to automatically assess the security of MCP servers by identifying adversarial samples, vulnerabilities, and providing remediations.
💬 Research Conclusions:
– The paper highlights significant security risks associated with the MCP design, showing that leading LLMs can be exploited to compromise AI systems through various attacks. MCPSafetyScanner is introduced as a proactive auditing tool to evaluate and improve MCP server safety, addressing discovered vulnerabilities pre-deployment.
👉 Paper link: https://huggingface.co/papers/2504.03767

28. DiffuMural: Restoring Dunhuang Murals with Multi-scale Diffusion
🔑 Keywords: diffusion models, conditional image generation, mural restoration, Multi-scale convergence, Collaborative Diffusion mechanism
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to address the challenges of restoring ancient murals using diffusion models, focusing on achieving aesthetic standards in style and seam detail.
🛠️ Research Methods:
– The authors propose a model named DiffuMural, which combines Multi-scale convergence and a Collaborative Diffusion mechanism with ControlNet and cyclic consistency loss. This model is trained on data from 23 large-scale Dunhuang murals.
💬 Research Conclusions:
– DiffuMural excels in restoring murals by matching generated images closely with conditional controls, ensuring factual accuracy, textural detail, contextual semantics, and holistic visual coherence in restored murals. The method outperforms existing approaches based on extensive evaluation metrics and humanistic value assessments.
👉 Paper link: https://huggingface.co/papers/2504.09513

29.
