AI Native Daily Paper Digest – 20250416
1. xVerify: Efficient Answer Verifier for Reasoning Model Evaluations
🔑 Keywords: reasoning models, complex reasoning, xVerify, equivalence judgment, VAR dataset
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To develop xVerify, an efficient answer verifier, to improve the evaluation of reasoning models incorporating slow thinking strategies.
🛠️ Research Methods:
– Constructed the VAR dataset by collecting question-answer pairs from multiple LLMs and employing a multi-round annotation process for label accuracy.
– Trained multiple xVerify models of varying scales on this dataset.
💬 Research Conclusions:
– xVerify models achieve over 95% in F1 scores and accuracy, with smaller variants outperforming existing methods except GPT-4o.
– The effectiveness and generalizability of xVerify in evaluating reasoning model outputs are validated.
👉 Paper link: https://huggingface.co/papers/2504.10481

2. Genius: A Generalizable and Purely Unsupervised Self-Training Framework For Advanced Reasoning
🔑 Keywords: LLM reasoning, self-training framework, unsupervised learning, stepwise foresight re-sampling
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The aim is to enhance Large Language Models (LLM) reasoning skills without external supervisory signals and overcome challenges such as scalability and high annotation costs.
🛠️ Research Methods:
– Introducing Genius, a generalizable self-training framework that operates unsupervised, employing a stepwise foresight re-sampling strategy and advantage-calibrated optimization loss function to optimize LLM without supervision.
💬 Research Conclusions:
– Genius represents a significant advance in autonomously improving LLM reasoning with general queries, offering a novel approach to scale LLM reasoning capabilities efficiently.
👉 Paper link: https://huggingface.co/papers/2504.08672

3. How Instruction and Reasoning Data shape Post-Training: Data Quality through the Lens of Layer-wise Gradients
🔑 Keywords: Large Language Models (LLMs), Finetuning Dynamics, Spectral Analysis, Effective Ranks
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to understand how different data qualities affect finetuning dynamics in post-training of large language models (LLMs).
🛠️ Research Methods:
– The research employs spectral analysis using singular value decomposition (SVD) of layer-wise gradients to evaluate data quality metrics, specifically focusing on nuclear norms and effective ranks.
💬 Research Conclusions:
– The findings reveal that higher-quality data correlates with lower nuclear norms and higher effective ranks, with the latter being more robust in identifying subtle quality differences. The study highlights shared gradient patterns within the same model family and divergence across different families, providing insights into data quality’s impact on training stability.
👉 Paper link: https://huggingface.co/papers/2504.10766

4. Heimdall: test-time scaling on the generative verification
🔑 Keywords: Chain-of-Thought reasoning, Heimdall, Pessimistic Verification, reinforcement learning, solution accuracy
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve verification capabilities of LLMs in solving competitive math problems and extend functionality for problem-solving.
🛠️ Research Methods:
– Utilizes reinforcement learning to enhance verification accuracy, and employs a method called Pessimistic Verification to select the most likely correct solutions.
💬 Research Conclusions:
– Achieves high verification accuracy of solutions, successfully generalizing to detect issues in math problems not included in training. By scaling compute resources, the solution accuracy on various models increased significantly.
👉 Paper link: https://huggingface.co/papers/2504.10337

5. Seedream 3.0 Technical Report
🔑 Keywords: Seedream 3.0, bilingual image generation, typography, resolution, acceleration
💡 Category: Generative Models
🌟 Research Objective:
– To develop Seedream 3.0, a high-performance Chinese-English bilingual image generation model with improved capabilities and image quality.
🛠️ Research Methods:
– Enhanced the dataset with a defect-aware training paradigm and dual-axis collaborative data-sampling.
– Adopted techniques like mixed-resolution training, cross-modality RoPE, and representation alignment loss in pre-training.
💬 Research Conclusions:
– Seedream 3.0 enhances visual aesthetics, text-rendering in complicated Chinese characters, and provides high-resolution outputs, achieving a 4 to 8 times speedup while maintaining quality.
👉 Paper link: https://huggingface.co/papers/2504.11346

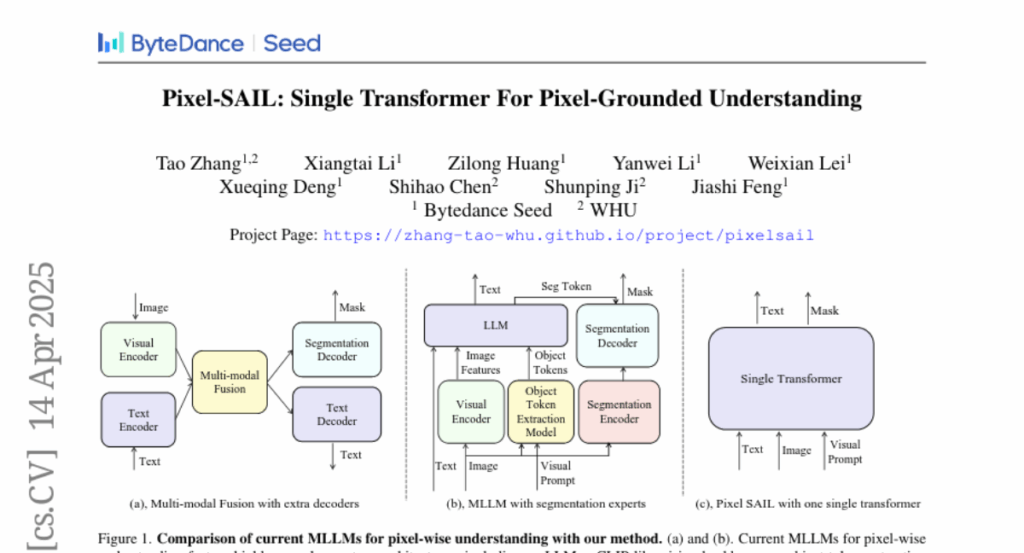
6. Pixel-SAIL: Single Transformer For Pixel-Grounded Understanding
🔑 Keywords: Multimodal Large Language Models, Vision Encoder, Unified Vision-Language Model, Visual Prompt Injection, Pixel Understanding Benchmark
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The aim was to simplify Multimodal Large Language Models (MLLMs) by designing a highly efficient model sans additional components like vision encoders.
🛠️ Research Methods:
– Developed Pixel-SAIL, a single transformer with enhancements such as a learnable upsampling module, a novel visual prompt injection strategy, and vision expert distillation.
– Collected a comprehensive benchmark for pixel understanding, named PerBench, covering tasks like detailed object description and visual-text referring segmentation.
💬 Research Conclusions:
– Pixel-SAIL demonstrated comparable or superior performance to existing methods in pixel-wise MLLM tasks, utilizing a simplified process and reduced system complexity.
– The experiments conducted on various benchmarks, including PerBench, validated the model’s efficacy.
👉 Paper link: https://huggingface.co/papers/2504.10465
7. TextArena
🔑 Keywords: Large Language Models, TrueSkill scores, negotiation, theory of mind, deception
💡 Category: Natural Language Processing
🌟 Research Objective:
– To provide a comprehensive platform for training and evaluating agentic behavior in Large Language Models (LLMs).
🛠️ Research Methods:
– Introduces TextArena, a collection of over 57 unique competitive text-based game environments supporting single-player, two-player, and multi-player setups, that facilitates dynamic social skills assessment and model capability evaluation through an online-play system.
💬 Research Conclusions:
– TextArena fills the gap left by traditional benchmarks by evaluating dynamic social skills like negotiation, theory of mind, and deception, and offers extensive support for adding new games and easily adapting the framework for research and community use.
👉 Paper link: https://huggingface.co/papers/2504.11442

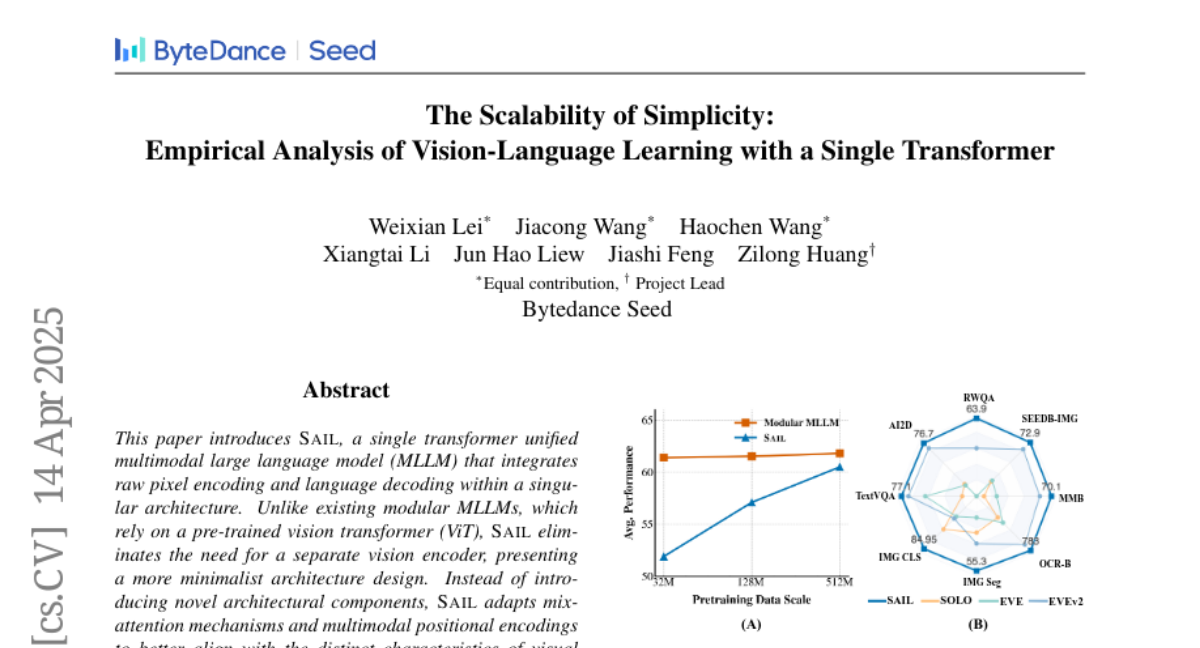
8. The Scalability of Simplicity: Empirical Analysis of Vision-Language Learning with a Single Transformer
🔑 Keywords: SAIL, single transformer, multimodal large language model (MLLM), raw pixel encoding, language decoding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce SAIL, a unified multimodal large language model that simplifies architecture by integrating raw pixel encoding and language decoding without the need for a pre-trained vision transformer (ViT).
🛠️ Research Methods:
– SAIL employs mix-attention mechanisms and multimodal positional encodings to align visual and textual modalities and systematically compares its scalability, information flow, and visual representation capabilities with modular MLLMs.
💬 Research Conclusions:
– SAIL achieves comparable performance to modular MLLMs, with enhanced scalability due to the removal of pretrained ViT components and demonstrates strong visual representation capabilities on par with ViT-22B in vision tasks.
👉 Paper link: https://huggingface.co/papers/2504.10462
9. Efficient Process Reward Model Training via Active Learning
🔑 Keywords: Process Reward Models, ActPRM, Active Learning, Annotation Efficiency, Math Reasoning Trajectories
💡 Category: Natural Language Processing
🌟 Research Objective:
– To scale up the training data annotation for large language models (LLMs) using Process Reward Models (PRMs) efficiently.
🛠️ Research Methods:
– An active learning approach, ActPRM, proactively selects uncertain samples for efficient labeling and uses a reasoning model for labeling after estimating uncertainty via PRM.
💬 Research Conclusions:
– ActPRM reduces annotation costs by 50% while maintaining or improving performance compared to vanilla fine-tuning, advancing state-of-the-art performance on datasets like ProcessBench and PRMBench.
👉 Paper link: https://huggingface.co/papers/2504.10559

10. Efficient Reasoning Models: A Survey
🔑 Keywords: Chain-of-Thoughts, computational overhead, knowledge distillation, efficient decoding strategies
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To provide a comprehensive overview of recent advances in efficient reasoning and address the computational overhead introduced by extensive Chain-of-Thoughts in reasoning models.
🛠️ Research Methods:
– Categorizing existing works into three key directions: compressing lengthy CoTs, developing compact language models with strong reasoning capabilities, and designing efficient decoding strategies.
💬 Research Conclusions:
– A curated collection of papers discussing advances in efficient reasoning is made available in a GitHub repository, highlighting various state-of-the-art techniques for speeding up reasoning processes.
👉 Paper link: https://huggingface.co/papers/2504.10903

11. NormalCrafter: Learning Temporally Consistent Normals from Video Diffusion Priors
🔑 Keywords: Surface normal estimation, Temporal coherence, Video diffusion models, Semantic Feature Regularization, High-fidelity normal estimation
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to improve temporal coherence in video-based surface normal estimation by leveraging temporal priors from video diffusion models.
🛠️ Research Methods:
– Introduced NormalCrafter with Semantic Feature Regularization to align diffusion features with semantic cues.
– Developed a two-stage training protocol focusing on both latent and pixel space learning to maintain spatial accuracy and long temporal context.
💬 Research Conclusions:
– The proposed method significantly enhances the generation of temporally consistent surface normal sequences, achieving superior performance across diverse video inputs.
👉 Paper link: https://huggingface.co/papers/2504.11427
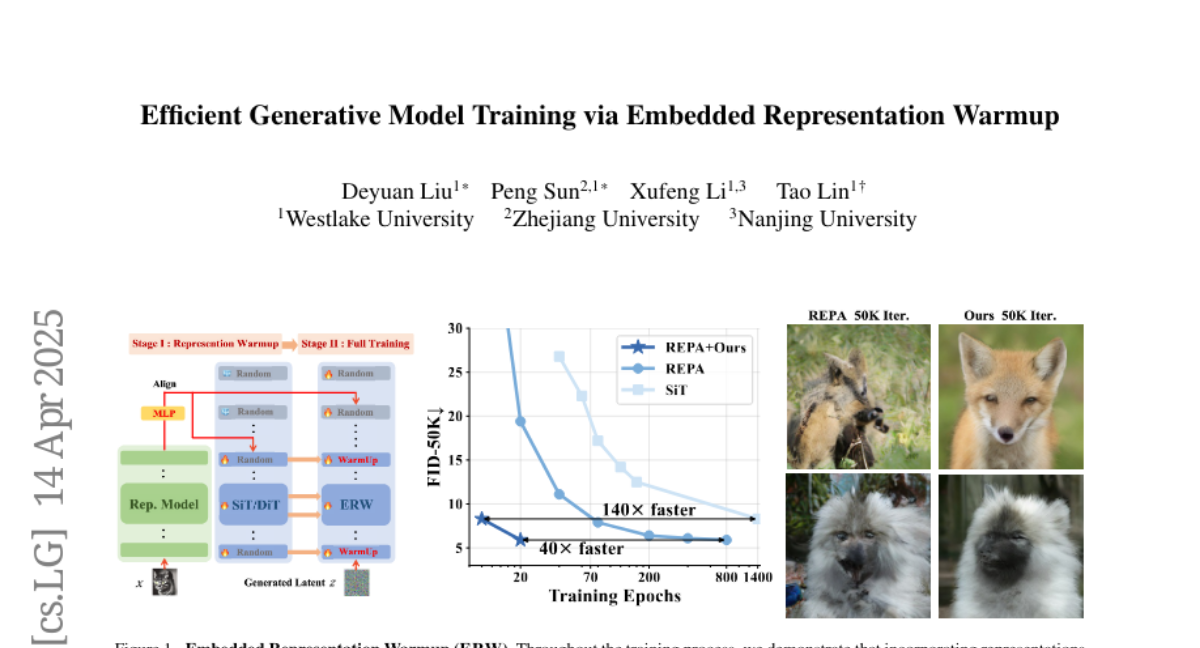
12. Efficient Generative Model Training via Embedded Representation Warmup
🔑 Keywords: Diffusion models, high-dimensional data, representation quality, Embedded Representation Warmup, convergence
💡 Category: Generative Models
🌟 Research Objective:
– To address the inefficiencies in training and representation quality in diffusion models compared to self-supervised methods by utilizing high-quality semantic representations during training.
🛠️ Research Methods:
– Proposed a systematic approach called Embedded Representation Warmup (ERW), which initializes early layers of diffusion models with pretrained representations to accelerate convergence and boost performance.
💬 Research Conclusions:
– The ERW framework significantly accelerates training convergence and enhances representation quality, achieving a 40 times speed increase in training compared to current state-of-the-art methods.
👉 Paper link: https://huggingface.co/papers/2504.10188
13. RealHarm: A Collection of Real-World Language Model Application Failures
🔑 Keywords: Language Models, AI Ethics, RealHarm, Reputational Damage, Misinformation
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– The study introduces RealHarm, a dataset of annotated problematic interactions with AI agents to analyze real-world failure modes of language models in consumer-facing applications.
🛠️ Research Methods:
– Systematic review of publicly reported incidents and empirical evaluation of state-of-the-art guardrails and content moderation systems.
💬 Research Conclusions:
– The research reveals that reputational damage is a predominant harm and misinformation is a common hazard, with a significant gap in current protective measures for AI applications.
👉 Paper link: https://huggingface.co/papers/2504.10277

14. VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge
🔑 Keywords: VisualPuzzles, multimodal benchmarks, reasoning, domain-specific knowledge, multimodal large language models
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce VisualPuzzles to focus on visual reasoning with minimized reliance on specialized knowledge.
🛠️ Research Methods:
– Create a benchmark consisting of diverse reasoning questions from five categories using logical reasoning questions from the Chinese Civil Service Examination.
💬 Research Conclusions:
– Multimodal large language models perform below human levels on VisualPuzzles, and success in knowledge-intensive benchmarks doesn’t guarantee reasoning-focused task performance. No clear correlation exists between model size and performance on reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2504.10342

15. ReZero: Enhancing LLM search ability by trying one-more-time
🔑 Keywords: Retrieval-Augmented Generation, Large Language Model, Reinforcement Learning, persistence, query formulation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to improve Large Language Model (LLM) performance on knowledge-intensive tasks by enhancing search query effectiveness, particularly after an unsuccessful initial attempt.
🛠️ Research Methods:
– The introduction of ReZero, a novel Reinforcement Learning framework, focuses on rewarding the act of retrying search queries to encourage LLMs to explore alternative queries rather than giving up prematurely.
💬 Research Conclusions:
– Implementing ReZero significantly improves performance, with accuracy increasing to 46.88% from a 25% baseline, thereby enhancing the robustness of LLMs in complex information-seeking scenarios.
👉 Paper link: https://huggingface.co/papers/2504.11001
16. DataDecide: How to Predict Best Pretraining Data with Small Experiments
🔑 Keywords: DataDecide, large language models, scaling laws, continuous likelihood metrics
💡 Category: Natural Language Processing
🌟 Research Objective:
– To determine which benchmarks and methods can accurately predict the datasets for optimal large language model performance.
🛠️ Research Methods:
– Conducted controlled pretraining experiments across 25 corpora, analyzing different sources, deduplication, and filtering, with models up to 1B parameters.
💬 Research Conclusions:
– Findings suggest that smaller scale rankings are strong predictors of larger model performance, with a prediction accuracy of ~80%.
– Identified continuous likelihood metrics as effective proxies, enabling >80% predictability at target scale with minimal compute.
👉 Paper link: https://huggingface.co/papers/2504.11393

17. A Minimalist Approach to LLM Reasoning: from Rejection Sampling to Reinforce
🔑 Keywords: Reinforcement learning, Fine-tuning, Large language models, GRPO, RAFT
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To analyze the effectiveness of GRPO in fine-tuning large language models on complex reasoning tasks and propose a more efficient alternative.
🛠️ Research Methods:
– Investigated GRPO from a reinforce-like algorithm perspective and compared it with a baseline, RAFT, through ablation studies.
💬 Research Conclusions:
– Found that RAFT yields competitive performance, and GRPO’s effectiveness is due to discarding prompts with incorrect responses. Proposed Reinforce-Rej for improved efficiency and alternative policy gradient methods.
👉 Paper link: https://huggingface.co/papers/2504.11343

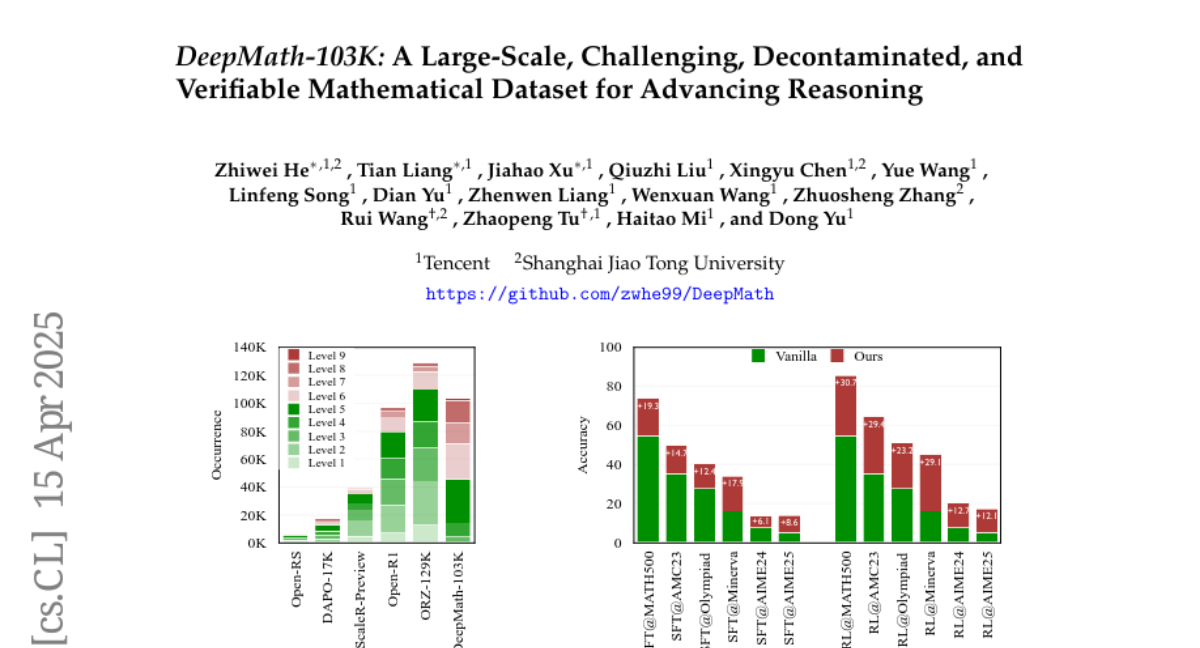
18. DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning
🔑 Keywords: reinforcement learning, training data, large-scale dataset, mathematical problems, AI reasoning systems
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to introduce DeepMath-103K, a comprehensive dataset of approximately 103K mathematical problems, designed for training advanced reasoning models through reinforcement learning.
🛠️ Research Methods:
– DeepMath-103K is curated using a rigorous pipeline of source analysis, decontamination from benchmarks, and filtering for high-difficulty problems. Each problem includes verifiable answers, enabling diverse training paradigms like supervised fine-tuning or distillation.
💬 Research Conclusions:
– Models trained on DeepMath-103K show significant improvements on challenging mathematical benchmarks, supporting its effectiveness in developing more capable AI reasoning systems. The dataset is made publicly available to encourage community advancements.
👉 Paper link: https://huggingface.co/papers/2504.11456
19. AI-University: An LLM-based platform for instructional alignment to scientific classrooms
🔑 Keywords: AI in Education, Large Language Model, Retrieval-Augmented Generation, Low-Rank Adaptation, Traceability
💡 Category: AI in Education
🌟 Research Objective:
– Introduce AI University, a flexible AI-driven framework for delivering course content aligned with instructors’ teaching styles.
🛠️ Research Methods:
– Utilized a scalable pipeline to construct training data and fine-tune an open-source Large Language Model using Low-Rank Adaptation and Retrieval-Augmented Generation.
– Employed assessments like cosine similarity and expert reviews to evaluate model alignment with course materials.
💬 Research Conclusions:
– The developed AI-U framework demonstrated strong alignment with the course materials and outperformed the base Llama 3.2 model in high percentages.
– AI-U is proposed as a scalable approach for AI-assisted education, enabling broader adoption in higher education settings.
👉 Paper link: https://huggingface.co/papers/2504.08846

20. PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
🔑 Keywords: PVUW Challenge, Video Segmentation, MOSE, MeViS, Real-world Scenarios
💡 Category: Computer Vision
🌟 Research Objective:
– To provide an overview of the 4th Pixel-level Video Understanding in the Wild Challenge and summarize its outcomes and future research directions.
🛠️ Research Methods:
– Introduction of two challenge tracks, MOSE and MeViS, each with new datasets for complex and motion-guided video object segmentation.
💬 Research Conclusions:
– Detailed evaluation of the state-of-the-art methods in complex video segmentation and identification of emerging trends.
👉 Paper link: https://huggingface.co/papers/2504.11326

21. Efficient Hybrid Language Model Compression through Group-Aware SSM Pruning
🔑 Keywords: Hybrid LLM architectures, Attention, State Space Models, compression, distillation
💡 Category: Machine Learning
🌟 Research Objective:
– The research explores the effectiveness of compressing Hybrid LLM architectures combining Attention and State Space Models.
🛠️ Research Methods:
– Introduction of a novel group-aware pruning strategy, which preserves the structural integrity of SSM blocks, alongside a combination of SSM, FFN, embedding dimension, and layer pruning followed by knowledge distillation-based retraining.
💬 Research Conclusions:
– The proposed compression strategy successfully reduces the Nemotron-H 8B Hybrid model to 4B parameters, achieving superior accuracy and 2x faster inference, redefining the Pareto frontier.
👉 Paper link: https://huggingface.co/papers/2504.11409

22. Diffusion Distillation With Direct Preference Optimization For Efficient 3D LiDAR Scene Completion
🔑 Keywords: Diffusion Models, LiDAR Scene Completion, Direct Policy Optimization (DPO), Preference Learning
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to propose a novel diffusion distillation framework named Distillation-DPO, aimed at enhancing LiDAR scene completion efficiency and quality through preference alignment.
🛠️ Research Methods:
– Implements a student model to generate paired completion scenes with different initial noises and constructs winning and losing sample pairs using LiDAR scene evaluation metrics. It optimizes the student model using differences in score functions between teacher and student models until convergence.
💬 Research Conclusions:
– Distillation-DPO outperforms existing state-of-the-art LiDAR scene completion models in quality and increases completion speed by over five times. The study pioneers the application of preference learning in distillation, offering new insights into preference-aligned distillation techniques.
👉 Paper link: https://huggingface.co/papers/2504.11447

23. SimpleAR: Pushing the Frontier of Autoregressive Visual Generation through Pretraining, SFT, and RL
🔑 Keywords: Autoregressive Visual Generation, Inference Optimization, Training Optimization, High Fidelity, Supervised Fine-Tuning
💡 Category: Generative Models
🌟 Research Objective:
– To demonstrate the capabilities of SimpleAR, a straightforward autoregressive visual generation framework, in generating high-resolution images with competitive quality using minimal parameters.
🛠️ Research Methods:
– Explored training and inference optimizations, including the use of Supervised Fine-Tuning and Group Relative Policy Optimization for enhancing image aesthetics and prompt alignment.
💬 Research Conclusions:
– SimpleAR can produce 1024×1024 resolution images at high fidelity with only 0.5 billion parameters, achieving impressive benchmarks. Inference acceleration techniques can reduce image generation time significantly, promoting broader participation in autoregressive visual generation research.
👉 Paper link: https://huggingface.co/papers/2504.11455

24. Adaptive Computation Pruning for the Forgetting Transformer
🔑 Keywords: Forgetting Transformer, Forget Gate, Softmax Attention, Pruning Threshold, FLOPs
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to improve computational efficiency in the Forgetting Transformer (FoX) by introducing a method called Adaptive Computation Pruning (ACP).
🛠️ Research Methods:
– Adaptive Computation Pruning is employed, which dynamically prunes computations where input-output dependencies are weakened by the Forget Gate, using a dynamically set pruning threshold.
💬 Research Conclusions:
– ACP reduces FLOPs in softmax attention by approximately 70%, enhancing training throughput by 10% to 35% across various model sizes and context lengths, with no performance degradation.
👉 Paper link: https://huggingface.co/papers/2504.06949

25. D^2iT: Dynamic Diffusion Transformer for Accurate Image Generation
🔑 Keywords: Diffusion models, Dynamic VAE, Dynamic Diffusion Transformer, compression, image regions
💡 Category: Generative Models
🌟 Research Objective:
– To address the limitations of fixed compression in Diffusion Transformer architecture by proposing a dynamic compression strategy that enhances image generation quality.
🛠️ Research Methods:
– Introduced a novel two-stage framework: first, a Dynamic VAE employs a hierarchical encoder to encode image regions at variable downsampling rates; second, a Dynamic Diffusion Transformer predicts multi-grained noise using the Dynamic Grain Transformer and the Dynamic Content Transformer.
💬 Research Conclusions:
– The proposed strategy effectively unifies global consistency and local realism in image generation, validated by comprehensive experiments across various tasks.
👉 Paper link: https://huggingface.co/papers/2504.09454

26. Summarization of Multimodal Presentations with Vision-Language Models: Study of the Effect of Modalities and Structure
🔑 Keywords: Vision-Language Models, automatic summarization, multimodal presentations, structured representation, cross-modal interactions
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To analyze and improve the automatic summarization capabilities of Vision-Language Models using various representations as input in multimodal presentations.
🛠️ Research Methods:
– Fine-grained quantitative and qualitative analyses of VLMs with different input representations, including analysis of text-heavy multimodal documents.
💬 Research Conclusions:
– Utilizing slides extracted from video streams, as opposed to raw video, enhances input effectiveness. Structured representations of interleaved slides and transcripts deliver optimal performance. The study offers insights into cross-modal interactions and suggests improvements for VLM capabilities in understanding diverse documents.
👉 Paper link: https://huggingface.co/papers/2504.10049

27. Multimodal Long Video Modeling Based on Temporal Dynamic Context
🔑 Keywords: Large Language Models, Temporal Dynamic Context, video understanding, token compression, chain-of-thought strategy
💡 Category: Computer Vision
🌟 Research Objective:
– To address challenges in long video processing with context length constraints of Large Language Models (LLMs) by proposing a new method for encoding temporal relationships between video frames.
🛠️ Research Methods:
– Introduced Temporal Dynamic Context (TDC) by segmenting videos into semantically consistent scenes, encoding frames into tokens using visual-audio encoders, and reducing token count with a novel temporal context compressor employing a query-based Transformer.
💬 Research Conclusions:
– The proposed method shows strong performance for general video understanding and audio-video understanding benchmarks, effectively handling long video sequences and demonstrating the utility of a training-free chain-of-thought strategy for extracting answers.
👉 Paper link: https://huggingface.co/papers/2504.10443

28. LazyReview A Dataset for Uncovering Lazy Thinking in NLP Peer Reviews
🔑 Keywords: Peer review, Lazy thinking, Natural Language Processing, Large Language Models, Instruction-based fine-tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce LazyReview, a dataset aimed at improving the detection of lazy thinking heuristics in peer review processes.
🛠️ Research Methods:
– Evaluation of Large Language Models’ performance in detecting lazy thinking within a zero-shot setting.
– Implementation of instruction-based fine-tuning on the LazyReview dataset to enhance detection capabilities.
💬 Research Conclusions:
– Instruction-based fine-tuning on comprehensive datasets significantly improves Large Language Models’ ability to detect lazy thinking by 10-20 performance points.
– Providing feedback on lazy thinking leads to more comprehensive and actionable peer reviews.
👉 Paper link: https://huggingface.co/papers/2504.11042

29. Change State Space Models for Remote Sensing Change Detection
🔑 Keywords: Change State Space Model, Vision Mamba, computational efficiency, detection performance, robustness
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce the Change State Space Model tailored for change detection in bi-temporal images, focusing on relevant changes to reduce network parameters.
🛠️ Research Methods:
– Utilized state space models to filter irrelevant information and enhance computational efficiency while maintaining detection performance and robustness.
💬 Research Conclusions:
– The model outperformed ConvNets and Vision transformers in three benchmark datasets, offering superior performance at reduced computational complexity.
👉 Paper link: https://huggingface.co/papers/2504.11080

30. Aligning Generative Denoising with Discriminative Objectives Unleashes Diffusion for Visual Perception
🔑 Keywords: generative diffusion models, discriminative tasks, perception quality, interactivity
💡 Category: Generative Models
🌟 Research Objective:
– To analyze and enhance the alignment between generative diffusion processes and perception tasks, improving perception quality during denoising.
🛠️ Research Methods:
– Proposed tailored learning objectives reflecting varying timestep contributions.
– Introduced diffusion-tailored data augmentation to address distribution shifts in training-denoising.
💬 Research Conclusions:
– Significantly improved diffusion-based perception models without architectural changes.
– Achieved state-of-the-art performance on tasks such as depth estimation and referring image segmentation.
👉 Paper link: https://huggingface.co/papers/2504.11457

31.
