AI Native Daily Paper Digest – 20250425

1. Step1X-Edit: A Practical Framework for General Image Editing
🔑 Keywords: Image Editing, Multimodal Models, Step1X-Edit, GPT-4o, Gemini2 Flash
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To release a state-of-the-art image editing model, Step1X-Edit, that rivals proprietary models like GPT-4o and Gemini2 Flash in performance.
🛠️ Research Methods:
– Utilization of Multimodal LLM to process reference images and user instructions.
– Integration of latent embeddings with a diffusion image decoder.
– Development of a data generation pipeline to create a high-quality dataset.
– Creation of GEdit-Bench, a benchmark rooted in real-world user instructions.
💬 Research Conclusions:
– Step1X-Edit outperforms existing open-source baselines and approaches the performance of leading proprietary models, making significant contributions to image editing.
👉 Paper link: https://huggingface.co/papers/2504.17761
2. Paper2Code: Automating Code Generation from Scientific Papers in Machine Learning
🔑 Keywords: Large Language Models, PaperCoder, Machine Learning, Code Implementation
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce PaperCoder, a multi-agent LLM framework designed to convert machine learning papers into functional code repositories.
🛠️ Research Methods:
– PaperCoder operates in three stages: planning, analysis, and generation, each facilitated by specialized agents collaborating effectively across the pipeline.
– Evaluations conducted based on model-based and human assessments, including feedback from original paper authors.
💬 Research Conclusions:
– PaperCoder efficiently produces high-quality, faithful code implementations from machine learning papers.
– Demonstrates significant performance advantages over strong baselines in the PaperBench benchmark.
👉 Paper link: https://huggingface.co/papers/2504.17192

3. RefVNLI: Towards Scalable Evaluation of Subject-driven Text-to-image Generation
🔑 Keywords: Subject-driven T2I generation, Textual alignment, Subject preservation, RefVNLI, Automatic evaluation
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to produce images that align with a given textual description while preserving visual identity from a referenced subject image.
🛠️ Research Methods:
– Introduction of RefVNLI, a cost-effective evaluation metric trained on a large-scale dataset from video-reasoning benchmarks and image perturbations.
💬 Research Conclusions:
– RefVNLI surpasses existing methods in evaluating textual alignment and subject preservation, achieving significant gains and aligning with human preferences at over 87% accuracy in lesser-known concepts.
👉 Paper link: https://huggingface.co/papers/2504.17502

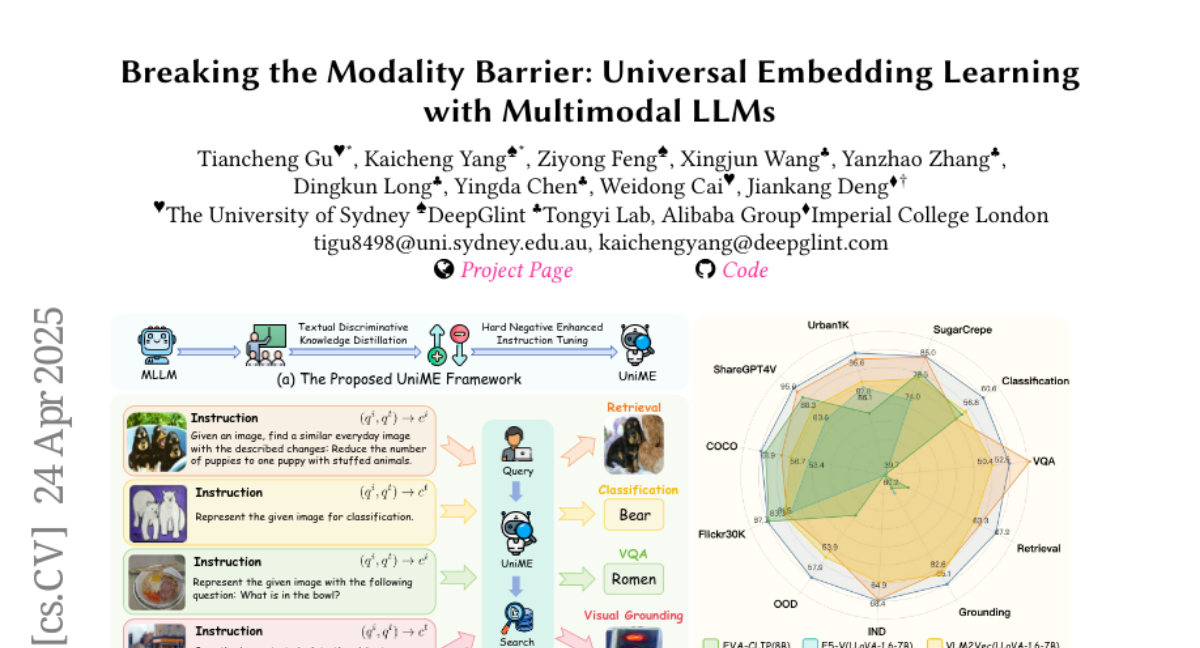
4. Breaking the Modality Barrier: Universal Embedding Learning with Multimodal LLMs
🔑 Keywords: CLIP, Multimodal Large Language Models, UniME, discriminative representation, compositional capabilities
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces UniME, a framework that aims to enhance multimodal representation learning by addressing existing limitations in CLIP and exploring the potential of Multimodal Large Language Models.
🛠️ Research Methods:
– The research utilizes a two-stage approach in UniME, involving textual discriminative knowledge distillation and hard negative enhanced instruction tuning to improve discriminative power and instruction-following ability.
💬 Research Conclusions:
– Experimental results on the MMEB benchmark and various retrieval tasks demonstrate that UniME consistently improves performance, showing superior discriminative and compositional capabilities.
👉 Paper link: https://huggingface.co/papers/2504.17432
5. Perspective-Aware Reasoning in Vision-Language Models via Mental Imagery Simulation
🔑 Keywords: Vision-Language Models, Perspective-taking, Mental Imagery, Perspective-aware Reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to bridge the gap between vision-language models (VLMs) and human perception by developing a framework for perspective-aware reasoning.
🛠️ Research Methods:
– The framework, named Abstract Perspective Change (APC), leverages vision foundation models, such as object detection, segmentation, and orientation estimation, to create scene abstractions that facilitate perspective transformations.
💬 Research Conclusions:
– Experiments on both synthetic and real-image benchmarks demonstrate significant improvements in perspective-aware reasoning with the APC framework, outperforming existing fine-tuned spatial reasoning models and novel-view-synthesis-based methods.
👉 Paper link: https://huggingface.co/papers/2504.17207

6. QuaDMix: Quality-Diversity Balanced Data Selection for Efficient LLM Pretraining
🔑 Keywords: Quality, Diversity, LLM, QuaDMix, LightGBM
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce QuaDMix, a unified data selection framework to optimize data distribution for LLM pretraining by balancing quality and diversity.
🛠️ Research Methods:
– Proposed criteria for measuring data quality and used domain classification for measuring diversity. Utilized a parameterized data sampling function and conducted simulated experiments with smaller models using LightGBM for parameter searching.
💬 Research Conclusions:
– QuaDMix achieved an average performance improvement of 7.2% across multiple benchmarks, outperforming independent quality and diversity strategies, demonstrating the necessity and capability of balancing data quality and diversity.
👉 Paper link: https://huggingface.co/papers/2504.16511

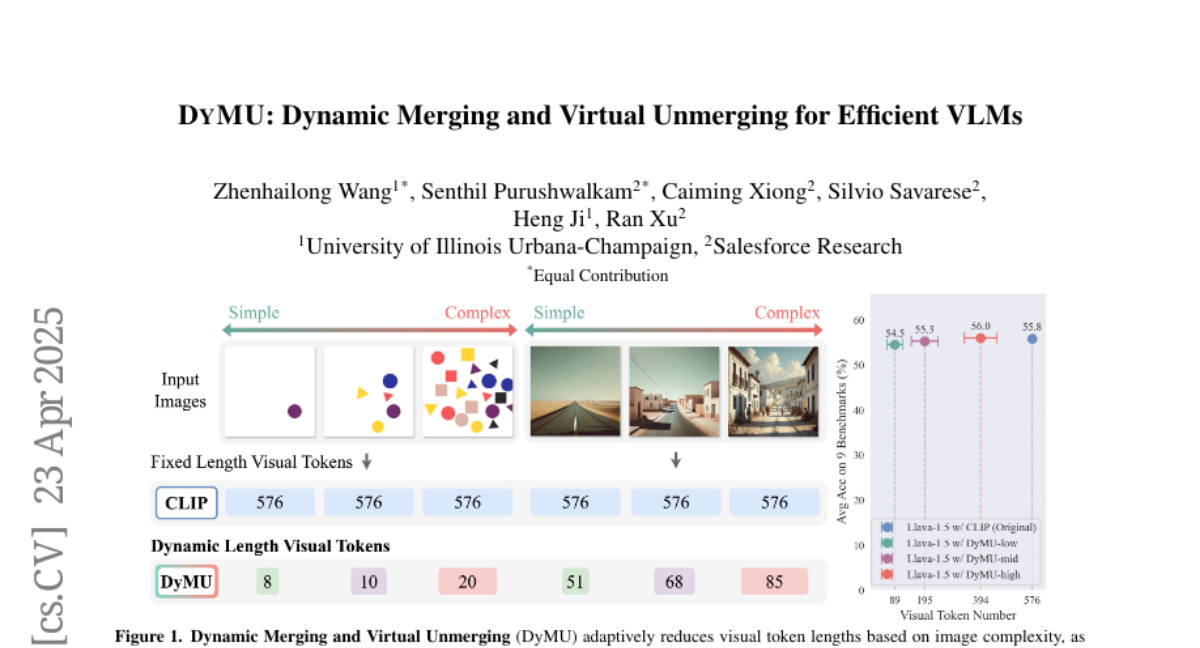
7. DyMU: Dynamic Merging and Virtual Unmerging for Efficient VLMs
🔑 Keywords: DyMU, Dynamic Token Merging (DToMe), Vision-Language Models (VLMs), Virtual Token Unmerging (VTU), Computational Costs
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce DyMU, a training-free framework aiming to dynamically reduce the computational load of vision-language models while retaining high task performance.
🛠️ Research Methods:
– Use Dynamic Token Merging (DToMe) to merge visual token embeddings based on image complexity, optimizing the inefficiency of fixed-length outputs in vision transformers.
– Implement Virtual Token Unmerging (VTU) to simulate expected token sequences for large language models by reconstructing attention dynamics efficiently, avoiding the need for additional fine-tuning.
💬 Research Conclusions:
– DyMU successfully reduces the average visual token count by 32%-85% in image and video understanding tasks, maintaining similar performance to full-length models across multiple VLM architectures and offering control over computational costs.
👉 Paper link: https://huggingface.co/papers/2504.17040
8. Token-Shuffle: Towards High-Resolution Image Generation with Autoregressive Models
🔑 Keywords: Autoregressive models, image synthesis, Token-Shuffle, text-to-image generation, Multimodal Large Language Models
💡 Category: Generative Models
🌟 Research Objective:
– To enhance the efficiency and resolution capabilities of Autoregressive models in image synthesis by introducing a novel method called Token-Shuffle.
🛠️ Research Methods:
– Introduced Token-Shuffle to reduce image token numbers, utilizing dimensional redundancies in Multimodal Large Language Models and employing token-shuffle and token-unshuffle operations.
💬 Research Conclusions:
– The Token-Shuffle approach enables Autoregressive models to achieve high-resolution image synthesis up to 2048×2048 while maintaining efficient training and inference. It demonstrated superior performance on GenAI-benchmark, outperforming existing AR and diffusion models.
👉 Paper link: https://huggingface.co/papers/2504.17789

9. Process Reward Models That Think
🔑 Keywords: Step-by-step verifiers, Process reward models, Verification chain-of-thought, ThinkPRM, Generative long CoT PRMs
💡 Category: Generative Models
🌟 Research Objective:
– Develop data-efficient process reward models (PRMs) that can verify every step in a solution through a verification chain-of-thought (CoT).
🛠️ Research Methods:
– Introduced ThinkPRM, a verifier fine-tuned on significantly fewer process labels, using inherent reasoning abilities of long CoT models.
💬 Research Conclusions:
– ThinkPRM outperforms both LLM-as-a-Judge and discriminative verifiers with just 1% of the process labels required by traditional models, showing superior performance across multiple benchmarks.
– Demonstrated effectiveness in scaling verification compute more efficiently compared to existing methods while maintaining minimal training supervision requirements.
👉 Paper link: https://huggingface.co/papers/2504.16828

10. Boosting Generative Image Modeling via Joint Image-Feature Synthesis
🔑 Keywords: Latent diffusion models, generative image modeling, Representation Guidance, training efficiency, image quality
💡 Category: Generative Models
🌟 Research Objective:
– To introduce a novel generative image modeling framework that integrates representation learning with generative modeling using latent-semantic diffusion.
🛠️ Research Methods:
– Utilized a diffusion model to jointly model low-level image latents and high-level semantic features, significantly enhancing generative quality and training efficiency.
💬 Research Conclusions:
– The proposed method simplifies training by removing complex distillation objectives and improves image quality and training convergence speed, establishing a new direction for representation-aware generative modeling.
👉 Paper link: https://huggingface.co/papers/2504.16064

11. IberBench: LLM Evaluation on Iberian Languages
🔑 Keywords: Large Language Models, IberBench, Natural Language Processing, multilingual evaluation, leaderboard
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces IberBench, a comprehensive and extensible benchmark to evaluate Large Language Models (LLMs) in multiple languages spoken across the Iberian Peninsula and Ibero-America.
🛠️ Research Methods:
– IberBench integrates 101 datasets covering 22 task categories and allows for community-driven updates. It evaluates 23 LLMs, varying from 100 million to 14 billion parameters, on both fundamental and industry-relevant tasks.
💬 Research Conclusions:
– LLMs generally perform worse on industry-relevant tasks compared to fundamental tasks. Performance is lower on average for languages such as Galician and Basque. For certain tasks, results approach random levels, whereas, in others, they exceed random but fall short of shared task systems. IberBench provides open-source implementation for the entire evaluation process.
👉 Paper link: https://huggingface.co/papers/2504.16921

12. ViSMaP: Unsupervised Hour-long Video Summarisation by Meta-Prompting
🔑 Keywords: ViSMaP, Unsupervised Video Summarisation, Meta Prompting, LLMs, pseudo-summaries
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a system, ViSMaP, to summarise long-form videos without supervision, addressing the challenges of sparse and non-pre-segmented events.
🛠️ Research Methods:
– Utilise a meta-prompting strategy with LLMs to iteratively generate and refine pseudo-summaries using segment descriptions from short videos, eliminating the need for costly manual annotations.
💬 Research Conclusions:
– ViSMaP achieves performance comparable to fully supervised models and successfully generalises across different domains without sacrificing efficiency. Code to be released upon publication.
👉 Paper link: https://huggingface.co/papers/2504.15921
13. Distilling semantically aware orders for autoregressive image generation
🔑 Keywords: Autoregressive Models, Patch-based Image Generation, Vision-Language Models, Raster-scan Order, Causality
💡 Category: Generative Models
🌟 Research Objective:
– To improve the order of patch generation in autoregressive models for better image quality, challenging the traditional raster-scan approach.
🛠️ Research Methods:
– Training a model to generate image patches in any-given-order to respect image content causality and fine-tuning it based on inferred generation orders.
💬 Research Conclusions:
– The new method outperforms the raster-scan approach in image generation quality, maintaining similar training costs and requiring no additional annotations.
👉 Paper link: https://huggingface.co/papers/2504.17069

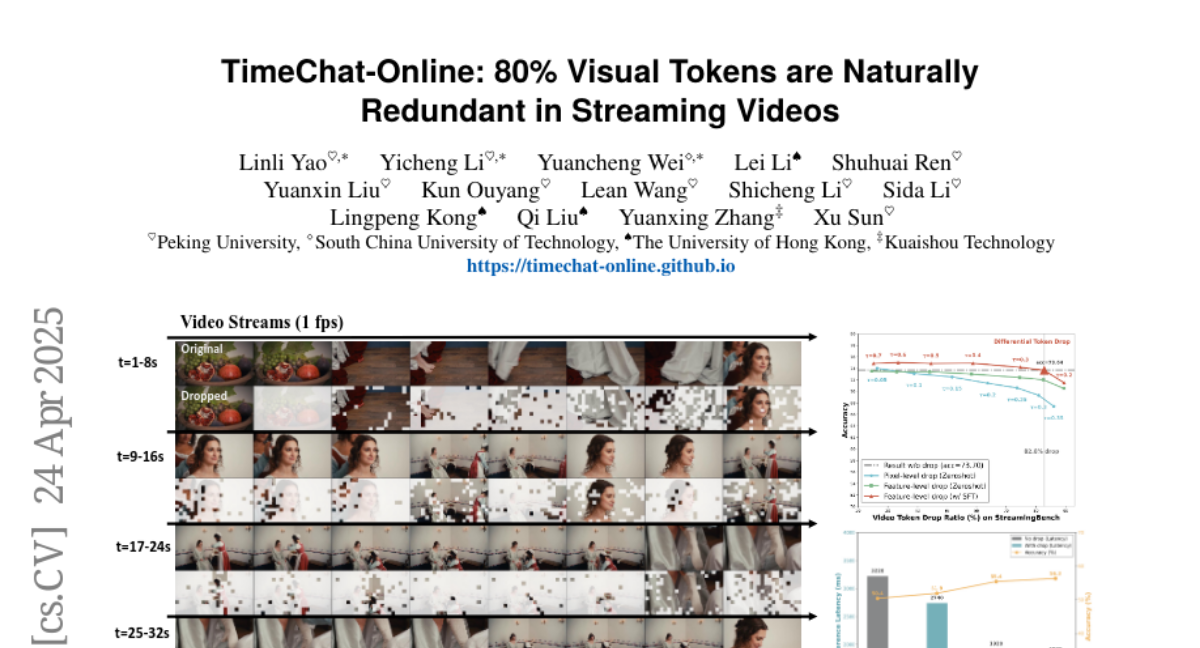
14. TimeChat-Online: 80% Visual Tokens are Naturally Redundant in Streaming Videos
🔑 Keywords: TimeChat-Online, Differential Token Drop (DTD), StreamingBench, real-time video interaction
💡 Category: Computer Vision
🌟 Research Objective:
– To address the limitations of current Video Large Language Models (VideoLLMs) in streaming scenarios by introducing TimeChat-Online, which focuses on real-time video interaction.
🛠️ Research Methods:
– Introduced an innovative Differential Token Drop (DTD) module to handle visual redundancy effectively by preserving meaningful temporal changes and filtering out static content.
💬 Research Conclusions:
– TimeChat-Online demonstrates superior performance on streaming benchmarks like StreamingBench and OvOBench, maintaining competitive results on long-form video tasks, and achieves an 82.8% reduction in video tokens while maintaining 98% performance.
👉 Paper link: https://huggingface.co/papers/2504.17343
15. 3DV-TON: Textured 3D-Guided Consistent Video Try-on via Diffusion Models
🔑 Keywords: video try-on, diffusion-based framework, animatable textured 3D meshes, adaptive pipeline, HR-VVT
💡 Category: Computer Vision
🌟 Research Objective:
– The primary goal is to improve video try-on quality, achieving high-fidelity and temporally consistent results when dealing with complex clothing patterns and diverse body poses.
🛠️ Research Methods:
– The method uses a novel diffusion-based framework employing animatable textured 3D meshes as frame-level guidance. This involves an adaptive pipeline selecting keyframes for initial 2D image try-on, followed by reconstruction and animation of textured 3D meshes synchronized with the original video poses.
💬 Research Conclusions:
– The proposed 3DV-TON framework significantly outperforms existing methods by delivering superior video try-on results. The introduction of the HR-VVT benchmark dataset aids future research and provides diverse scenarios for testing effectiveness.
👉 Paper link: https://huggingface.co/papers/2504.17414

16. Interpretable non-linear dimensionality reduction using gaussian weighted linear transformation
🔑 Keywords: Dimensionality reduction, interpretability, non-linear transformations, Gaussian functions, geometric relationships
💡 Category: Machine Learning
🌟 Research Objective:
– The research introduces a novel approach to dimensionality reduction that integrates the interpretability of linear methods with the expressiveness of non-linear transformations.
🛠️ Research Methods:
– The proposed algorithm constructs a non-linear mapping between high-dimensional and low-dimensional spaces using linear transformations weighted by Gaussian functions.
💬 Research Conclusions:
– The model provides a powerful and interpretable dimensionality reduction tool, offering insights into how geometric relationships are preserved and modified. Techniques are presented for understanding transformations and creating user-friendly software for practical adoption.
👉 Paper link: https://huggingface.co/papers/2504.17601

17. DiMeR: Disentangled Mesh Reconstruction Model
🔑 Keywords: Large Reconstruction Model, DiMeR, mesh reconstruction, normal maps
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to improve 3D generative models by addressing issues in RGB image-based geometry reconstruction and introducing a novel dual-stream model, DiMeR.
🛠️ Research Methods:
– The authors propose disentangling geometry and texture to reduce training difficulty and use normal maps for geometry input to decrease network complexity.
💬 Research Conclusions:
– DiMeR outperforms existing methods with significant improvements, demonstrating a robust performance in tasks like sparse-view reconstruction and achieving over 30% enhancement in Chamfer Distance on benchmark datasets.
👉 Paper link: https://huggingface.co/papers/2504.17670

18. Dynamic Camera Poses and Where to Find Them
🔑 Keywords: DynPose-100K, Camera Poses, Pose Estimation, Dynamic Internet Videos, Structure-from-Motion
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to annotate camera poses on dynamic Internet videos at scale to advance realistic video generation and simulation.
🛠️ Research Methods:
– The paper presents a collection pipeline using task-specific and generalist models for filtering, along with point tracking, dynamic masking, and structure-from-motion techniques for pose estimation.
💬 Research Conclusions:
– The DynPose-100K dataset is defined as large-scale and diverse, contributing to advancements in various downstream applications.
👉 Paper link: https://huggingface.co/papers/2504.17788
