AI Native Daily Paper Digest – 20250507

1. Unified Multimodal Chain-of-Thought Reward Model through Reinforcement Fine-Tuning
🔑 Keywords: multimodal Reward Models, CoT reasoning, UnifiedReward-Think, reinforcement fine-tuning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve the reliability and robustness of multimodal Reward Models by incorporating explicit long chains of thought (CoT) in their reasoning process.
🛠️ Research Methods:
– The introduction of UnifiedReward-Think, a unified multimodal CoT-based reward model, using exploration-driven reinforcement fine-tuning with limited image generation preference data for cold start and large-scale multimodal preference data for reasoning.
– Group Relative Policy Optimization (GRPO) is used for reinforcement fine-tuning, leveraging both correct and incorrect predicted samples for reasoning process optimization.
💬 Research Conclusions:
– The model demonstrates superior performance in visual understanding and reward tasks by exploring diverse reasoning paths and optimizing for robust solutions through extensive experiments.
👉 Paper link: https://huggingface.co/papers/2505.03318

2. Absolute Zero: Reinforced Self-play Reasoning with Zero Data
🔑 Keywords: Reinforcement Learning, Verifiable Rewards, Absolute Zero, Superintelligent System, SOTA Performance
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To propose a new paradigm, Absolute Zero, in reinforcement learning to enhance reasoning capabilities without external data dependency.
🛠️ Research Methods:
– Developing the Absolute Zero Reasoner (AZR) that self-evolves its training curriculum and reasoning ability using a code executor for validating tasks and verifying answers.
💬 Research Conclusions:
– AZR achieves state-of-the-art performance in coding and mathematical reasoning tasks with no reliance on human-curated examples and is effective across different model scales.
👉 Paper link: https://huggingface.co/papers/2505.03335

3. RADLADS: Rapid Attention Distillation to Linear Attention Decoders at Scale
🔑 Keywords: Rapid Attention Distillation, Linear Attention Decoders, RWKV-variant, Qwen2.5, HuggingFace
💡 Category: Natural Language Processing
🌟 Research Objective:
– The primary goal is to present a protocol for converting softmax attention transformers into linear attention decoder models efficiently and cost-effectively.
🛠️ Research Methods:
– Introduces the Rapid Attention Distillation to Linear Attention Decoders at Scale (RADLADS) protocol.
– Utilizes RWKV-variant architectures and models converted from popular Qwen2.5 models, supporting conversions with minimal token usage.
💬 Research Conclusions:
– Achieved state-of-the-art performance in downstream tasks with the linear attention models, preserving quality while significantly reducing cost.
– Models are accessible on HuggingFace under the Apache 2.0 license, with the notable exception of the 72B models which also require adherence to the Qwen License Agreement.
👉 Paper link: https://huggingface.co/papers/2505.03005

4. FlexiAct: Towards Flexible Action Control in Heterogeneous Scenarios
🔑 Keywords: Action customization, FlexiAct, RefAdapter, denoising process, Frequency-aware Action Extraction
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce FlexiAct, a method to transfer actions from a reference video to an arbitrary target image while maintaining identity consistency and allowing spatial structure variations.
🛠️ Research Methods:
– Developed RefAdapter, an image-conditioned adapter for spatial adaptation and consistency preservation.
– Proposed FAE (Frequency-aware Action Extraction) to achieve direct action extraction during the denoising process.
💬 Research Conclusions:
– FlexiAct effectively transfers actions across diverse subjects with different layouts, skeletons, and viewpoints, outperforming existing methods.
👉 Paper link: https://huggingface.co/papers/2505.03730

5. RetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference
🔑 Keywords: Large Language Models, GPU Memory, Key-Value Cache, Attention Sparsity, Wave Index
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To address the challenges of efficient inference in Large Language Models (LLMs) due to constraints in GPU memory and bandwidth.
🛠️ Research Methods:
– Introduction of RetroInfer, a novel system using a wave index (Attention-aWare VEctor index) for efficient critical token retrieval through techniques like tripartite attention approximation and segmented clustering.
– Utilization of the wave buffer to coordinate Key-Value cache placement and manage computation-data transfer across GPU and CPU.
💬 Research Conclusions:
– RetroInfer provides up to 4.5X speedup over full attention within GPU memory constraints and up to 10.5X speedup when extending KV cache to CPU memory, maintaining full-attention-level accuracy.
👉 Paper link: https://huggingface.co/papers/2505.02922

6. Decoding Open-Ended Information Seeking Goals from Eye Movements in Reading
🔑 Keywords: LLMs, eye movements, goal classification, multimodal LLMs, text-specific information seeking
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To investigate if open-ended reading goals can be automatically decoded from eye movements during reading.
🛠️ Research Methods:
– Developed and compared several discriminative and generative multimodal LLMs using large-scale eye tracking data for goal classification and reconstruction tasks in English.
💬 Research Conclusions:
– The experiments demonstrated considerable success, indicating that LLMs can effectively extract valuable information about readers’ text-specific goals from their eye movements.
👉 Paper link: https://huggingface.co/papers/2505.02872

7. An Empirical Study of Qwen3 Quantization
🔑 Keywords: Qwen3, Large Language Models, Quantization, Performance, LLM Compression
💡 Category: Natural Language Processing
🌟 Research Objective:
– To systematically evaluate Qwen3’s robustness under various quantization settings and to uncover opportunities and challenges in compressing this state-of-the-art model.
🛠️ Research Methods:
– Conducted a rigorous assessment of 5 existing classic post-training quantization techniques, evaluating bit-widths from 1 to 8 bits across multiple datasets.
💬 Research Conclusions:
– Qwen3 maintains competitive performance at moderate bit-widths, but experiences notable degradation in linguistic tasks under ultra-low precision. This emphasizes the need for further research to mitigate performance loss in extreme quantization scenarios.
👉 Paper link: https://huggingface.co/papers/2505.02214

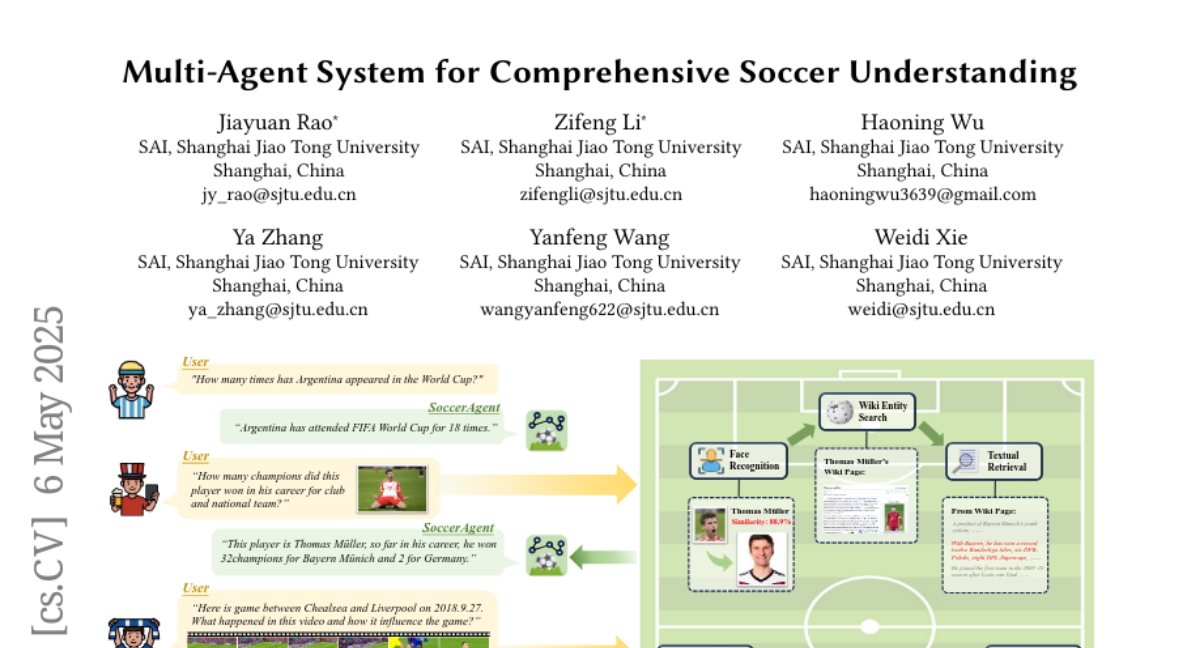
8. Multi-Agent System for Comprehensive Soccer Understanding
🔑 Keywords: AI-driven soccer, multimodal, knowledge base, multi-agent system, domain knowledge
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To propose a comprehensive framework for holistic soccer understanding that addresses the limitations of existing isolated or narrow task research.
🛠️ Research Methods:
– Developed SoccerWiki, a large-scale multimodal soccer knowledge base integrating domain knowledge.
– Introduced SoccerBench, a soccer-specific benchmark with around 10K multimodal multi-choice QA pairs.
– Created SoccerAgent, a novel multi-agent system leveraging collaborative reasoning and domain expertise.
💬 Research Conclusions:
– Extensive evaluations demonstrate the superiority of the proposed agentic system on SoccerBench, with all data and code available publicly.
👉 Paper link: https://huggingface.co/papers/2505.03735
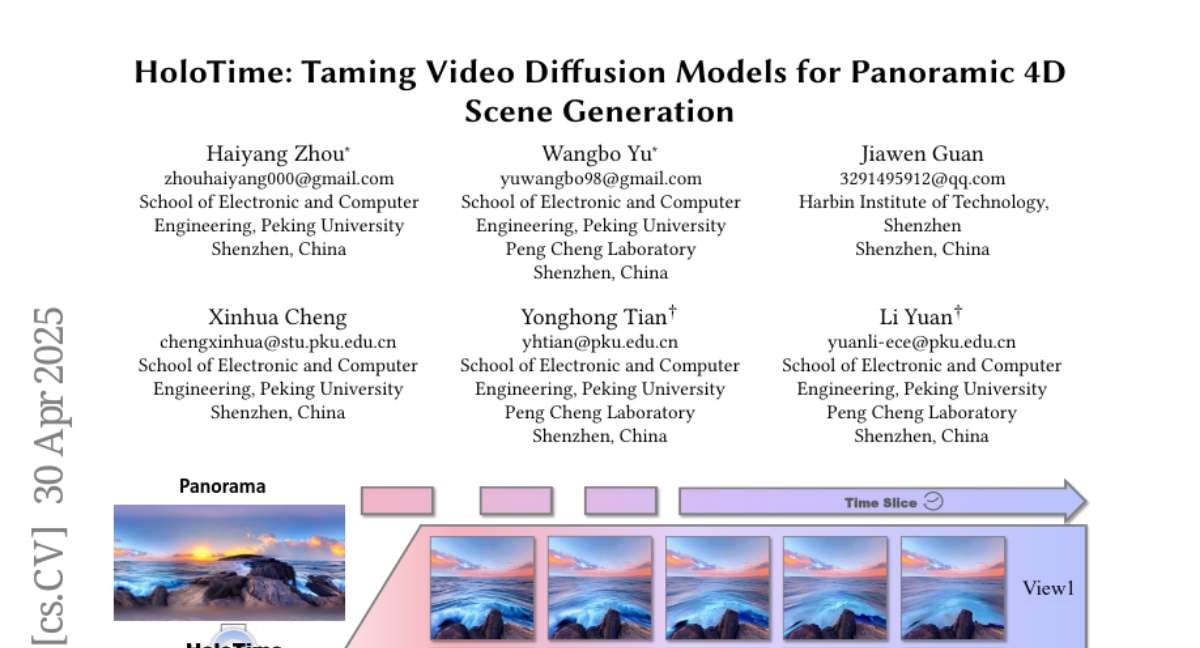
9. HoloTime: Taming Video Diffusion Models for Panoramic 4D Scene Generation
🔑 Keywords: diffusion models, HoloTime, panoramic videos, 4D scene reconstruction, VR and AR
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to revolutionize the VR and AR applications by using diffusion models to generate immersive 4D experiences.
🛠️ Research Methods:
– Introduces HoloTime, which integrates video diffusion models for generating panoramic videos and converting them into 4D assets.
– Presents the 360World dataset and the Panoramic Animator model for high-quality video generation.
💬 Research Conclusions:
– The proposed method effectively creates more engaging and realistic immersive environments, enhancing user experiences in VR and AR applications.
👉 Paper link: https://huggingface.co/papers/2504.21650
10. Geospatial Mechanistic Interpretability of Large Language Models
🔑 Keywords: Large Language Models, mechanistic interpretability, spatial reasoning, probing, sparse autoencoders
💡 Category: Natural Language Processing
🌟 Research Objective:
– To establish a novel framework for studying geospatial mechanistic interpretability to understand how LLMs process geographical information.
🛠️ Research Methods:
– Utilization of probing to reveal internal structures within LLMs and employing spatial autocorrelation to interpret spatial patterns.
💬 Research Conclusions:
– The framework helps in understanding the internal representations of LLMs concerning geographic information, with implications for their use in geography.
👉 Paper link: https://huggingface.co/papers/2505.03368

11. VITA-Audio: Fast Interleaved Cross-Modal Token Generation for Efficient Large Speech-Language Model
🔑 Keywords: Speech-based systems, VITA-Audio, Multiple Cross-modal Token Prediction, inference speedup, real-time conversational capabilities
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to address high latency in existing speech models by introducing VITA-Audio, which enables fast audio-text token generation.
🛠️ Research Methods:
– The researchers propose a lightweight Multiple Cross-modal Token Prediction (MCTP) module and a four-stage progressive training strategy to accelerate model inference with minimal speech quality loss.
💬 Research Conclusions:
– VITA-Audio achieves an inference speedup of 3~5x on the 7B parameter scale, significantly outperforming open-source models of similar size in ASR, TTS, and SQA tasks.
👉 Paper link: https://huggingface.co/papers/2505.03739

12. InfoVids: Reimagining the Viewer Experience with Alternative Visualization-Presenter Relationships
🔑 Keywords: Human-centric, Visualization, InfoVids, Interactive, Presenter
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To establish a more equitable relationship between visualization and presenter through the design of InfoVids, transforming traditional presenter-visualization dynamics.
🛠️ Research Methods:
– Mixed methods analysis with 30 participants, comparing InfoVids to traditional 2D slide presentations on 9 metrics.
💬 Research Conclusions:
– InfoVids reduce viewer attention splitting, enhance focus on the presenter, and facilitate more interactive and engaging data presentations.
👉 Paper link: https://huggingface.co/papers/2505.03164

13. SWE-smith: Scaling Data for Software Engineering Agents
🔑 Keywords: SWE-smith, Language Models, Training Data, Software Engineering, SWE-agent-LM-32B
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce SWE-smith, a new pipeline for generating large-scale software engineering training data.
🛠️ Research Methods:
– Utilize SWE-smith to automatically generate 100s to 1,000s of task instances from Python codebases and create a dataset from 128 GitHub repositories.
💬 Research Conclusions:
– SWE-agent-LM-32B, trained on this dataset, achieves state-of-the-art performance among open-source models with a 40.2% Pass@1 resolve rate on the SWE-bench Verified benchmark. Open sourcing SWE-smith lowers the research entry barrier for automated software engineering.
👉 Paper link: https://huggingface.co/papers/2504.21798

14. Auto-SLURP: A Benchmark Dataset for Evaluating Multi-Agent Frameworks in Smart Personal Assistant
🔑 Keywords: Multi-agent frameworks, Large Language Models (LLMs), Benchmark datasets, Auto-SLURP, Intelligent personal assistants
💡 Category: Natural Language Processing
🌟 Research Objective:
– The primary objective is to introduce Auto-SLURP, a benchmark dataset for evaluating LLM-based multi-agent frameworks, particularly in the context of intelligent personal assistants.
🛠️ Research Methods:
– Auto-SLURP extends the SLURP dataset by relabeling data and integrating simulated servers and external services to create a comprehensive end-to-end evaluation pipeline.
💬 Research Conclusions:
– The dataset presents significant challenges for current state-of-the-art frameworks, emphasizing the ongoing development needed for reliable multi-agent personal assistants.
👉 Paper link: https://huggingface.co/papers/2504.18373

15. Invoke Interfaces Only When Needed: Adaptive Invocation for Large Language Models in Question Answering
🔑 Keywords: Small LMs, AttenHScore, Hallucinations, Reasoning Errors, Knowledge Reorganization
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address the challenge of precisely identifying when to invoke large LMs to improve performance and reduce hallucinations in small LMs.
🛠️ Research Methods:
– Propose the AttenHScore metric to measure and manage hallucinations during the generation process.
– Implement uncertainty-aware knowledge reorganization to enhance small LMs’ understanding of critical information.
💬 Research Conclusions:
– AttenHScore significantly improves real-time hallucination detection across various QA datasets, especially with complex queries.
– The approach is flexible, requiring no additional model training, and adapts to multiple transformer-based LMs.
👉 Paper link: https://huggingface.co/papers/2505.02311

16. Teaching Models to Understand (but not Generate) High-risk Data
🔑 Keywords: Selective Loss, High-Risk Content, Language Models, Toxic Content, Pre-training Paradigm
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce SLUNG, a pre-training paradigm that enables models to understand high-risk data without generating it.
🛠️ Research Methods:
– Uses selective application of next-token prediction loss to prevent models from generating high-risk tokens while retaining context.
💬 Research Conclusions:
– SLUNG enhances models’ understanding of high-risk data, like toxic content, without amplifying the generation of such content.
👉 Paper link: https://huggingface.co/papers/2505.03052

17. Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems
🔑 Keywords: LLM multi-agent systems, automated failure attribution, failure logs, agents, error steps
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper proposes and formulates a new research area focused on automated failure attribution in LLM multi-agent systems to address the labor-intensive task of debugging these systems.
🛠️ Research Methods:
– The Who&When dataset is introduced, containing extensive failure logs with fine-grained annotations, and three automated failure attribution methods are developed and evaluated for their effectiveness.
💬 Research Conclusions:
– The best failure attribution method achieved 53.5% accuracy in identifying responsible agents, but only 14.2% in pinpointing failure steps. Current methods and state-of-the-art reasoning models like OpenAI o1 and DeepSeek R1 struggle to achieve practical usability, underscoring the complexity and need for further research.
👉 Paper link: https://huggingface.co/papers/2505.00212

18.
