AI Native Daily Paper Digest – 20250519

1. Qwen3 Technical Report
🔑 Keywords: Qwen3, large language models, multilingual capabilities, Mixture-of-Expert architectures, thinking mode
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to enhance performance, efficiency, and multilingual capabilities in large language models through the introduction of Qwen3, which integrates thinking and non-thinking modes in a unified framework.
🛠️ Research Methods:
– Qwen3 uses both dense and Mixture-of-Expert architectures with parameter scales from 0.6 to 235 billion. It also introduces a thinking budget mechanism for adaptive computational resource allocation.
💬 Research Conclusions:
– Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art performance across various benchmarks. It significantly reduces computational resources needed for smaller-scale models while expanding multilingual support from 29 to 119 languages and ensuring competitive performance.
👉 Paper link: https://huggingface.co/papers/2505.09388

2. MMLongBench: Benchmarking Long-Context Vision-Language Models Effectively and Thoroughly
🔑 Keywords: Long-Context Vision-Language Models, MMLongBench, Cross-Modal Tokenization, Vision Patches, Reasoning Ability
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce MMLongBench, a benchmark for evaluating long-context vision-language models (LCVLMs).
🛠️ Research Methods:
– Evaluation of 46 closed-source and open-source LCVLMs using MMLongBench, with examples across five different downstream task categories and standardized input lengths.
💬 Research Conclusions:
– Single-task performance inadequately indicates overall long-context capability. Both open-source and closed-source models struggle with long-context tasks and can improve. Models with better reasoning ability show improved long-context performance.
👉 Paper link: https://huggingface.co/papers/2505.10610

3. GuardReasoner-VL: Safeguarding VLMs via Reinforced Reasoning
🔑 Keywords: GuardReasoner-VL, Reasoning Corpus, Online RL, Rejection Sampling, Dynamic Clipping Parameter
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The objective is to enhance the safety of Vision-Language Models (VLMs) through a novel reasoning-based guard model called GuardReasoner-VL.
🛠️ Research Methods:
– Constructing a comprehensive reasoning corpus with 123K samples to cold-start the model’s reasoning capability via SFT.
– Employing online reinforcement learning to refine the model’s moderation reasoning.
– Utilizing rejection sampling and data augmentation for increasing diversity and complexity of samples.
– Implementing a dynamic clipping parameter to balance exploration and exploitation phases.
– Designing a length-aware safety reward to maintain a balance between performance and token efficiency.
💬 Research Conclusions:
– The model demonstrated superior performance, surpassing the runner-up by 19.27% in F1 score on average.
– Releases of data, code, and models with 3B/7B parameters are made available for public access.
👉 Paper link: https://huggingface.co/papers/2505.11049

4. Visual Planning: Let’s Think Only with Images
🔑 Keywords: Visual Planning, Reinforcement Learning, MLLMs, Step-by-step Inference, Image-based Inference
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to challenge the dominance of text-based reasoning by proposing Visual Planning, a paradigm leveraging visual representations for tasks involving spatial and geometrical information.
🛠️ Research Methods:
– The researchers introduce a reinforcement learning framework called Visual Planning via Reinforcement Learning (VPRL), using GRPO for post-training large vision models to perform planning through sequences of images.
💬 Research Conclusions:
– The Visual Planning paradigm outperforms traditional text-only reasoning approaches in various visual navigation tasks, indicating its potential as a superior alternative for tasks benefiting from intuitive, image-based inference.
👉 Paper link: https://huggingface.co/papers/2505.11409

5. Group Think: Multiple Concurrent Reasoning Agents Collaborating at Token Level Granularity
🔑 Keywords: Large Language Models, Group Think, Concurrent Reasoning Agents, Edge Inference, Token-Level Collaboration
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose Group Think, a new paradigm utilizing a single LLM to act as multiple concurrent reasoning agents with shared visibility for improved reasoning quality and reduced latency.
🛠️ Research Methods:
– Developed a modification for existing LLMs to perform Group Think on local GPUs and established an evaluation strategy to empirically demonstrate latency improvements.
💬 Research Conclusions:
– Group Think enables fine-grained token-level collaboration that enhances reasoning quality, reduces redundancy, and improves computational efficiency, especially for edge inference.
👉 Paper link: https://huggingface.co/papers/2505.11107

6. Simple Semi-supervised Knowledge Distillation from Vision-Language Models via texttt{D}ual-texttt{H}ead texttt{O}ptimization
🔑 Keywords: Vision-language models, Knowledge distillation, Dual prediction heads, Gradient conflicts, State-of-the-art performance
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to address the deployment challenges of Vision-language models (VLMs) in resource-constrained environments and improve the efficiency of Knowledge distillation (KD) methods.
🛠️ Research Methods:
– The introduction of Dual-Head Optimization (DHO), a framework with dual prediction heads, which leverages both labeled data and teacher predictions to mitigate gradient conflicts and optimize feature learning.
💬 Research Conclusions:
– DHO consistently outperforms existing KD baselines and achieves state-of-the-art performance on datasets like ImageNet, enhancing accuracy while using fewer parameters, especially noteworthy with minimal labeled data.
👉 Paper link: https://huggingface.co/papers/2505.07675

7. Mergenetic: a Simple Evolutionary Model Merging Library
🔑 Keywords: Model Merging, Evolutionary Algorithms, Mergenetic, Fitness Estimators, Evaluation Costs
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to develop an open-source library, Mergenetic, to facilitate evolutionary model merging in language models without the need for additional training.
🛠️ Research Methods:
– Utilization of Mergenetic to enable flexible composition of merging methods and evolutionary algorithms, incorporating lightweight fitness estimators for cost-effective evaluation.
💬 Research Conclusions:
– Mergenetic demonstrates competitive results in various tasks and languages using consumer-level hardware.
👉 Paper link: https://huggingface.co/papers/2505.11427

8. Multi-Token Prediction Needs Registers
🔑 Keywords: Multi-token prediction, MuToR, Register tokens, Pretraining, Fine-tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces MuToR, a novel approach to enhance multi-token prediction, aiming to improve language model pretraining and fine-tuning.
🛠️ Research Methods:
– MuToR is implemented by integrating learnable register tokens into the input sequence, predicting future targets without requiring architectural changes, thus ensuring compatibility with existing language models.
💬 Research Conclusions:
– MuToR demonstrates versatility and effectiveness in various applications, including supervised and parameter-efficient fine-tuning across diverse generative tasks in both language and vision domains.
👉 Paper link: https://huggingface.co/papers/2505.10518

9. MPS-Prover: Advancing Stepwise Theorem Proving by Multi-Perspective Search and Data Curation
🔑 Keywords: Automated Theorem Proving, large language models, Multi-Perspective Search Prover, post-training data curation strategy, multi-perspective tree search mechanism
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce the Multi-Perspective Search Prover (MPS-Prover) to tackle the limitations of current Automated Theorem Proving systems using innovative strategies.
🛠️ Research Methods:
– Implement a post-training data curation strategy to eliminate 40% of redundant data.
– Develop a multi-perspective tree search mechanism that integrates a learned critic model with heuristic rules.
💬 Research Conclusions:
– MPS-Prover achieves state-of-the-art performance in formal reasoning, outperforming 7B parameter models, and produces shorter, more diverse proofs compared to existing methods.
👉 Paper link: https://huggingface.co/papers/2505.10962

10. Scaling Reasoning can Improve Factuality in Large Language Models
🔑 Keywords: Large Language Models, Reasoning Traces, Factual Accuracy, Knowledge Graphs, Test-Time Scaling
💡 Category: Natural Language Processing
🌟 Research Objective:
– To examine the reasoning capabilities of large language models in complex open-domain question-answering scenarios and determine if longer reasoning chains improve factual accuracy beyond mathematical contexts.
🛠️ Research Methods:
– Utilizing reasoning traces from large-scale models and fine-tuning various models ranging from smaller instruction-tuned variants to larger architectures like Qwen2.5. Introducing factual information from knowledge graphs to enhance reasoning traces and conducting 168 experimental runs across six datasets.
💬 Research Conclusions:
– Smaller reasoning models show noticeable improvements in factual accuracy compared to original instruction-tuned counterparts. Adding test-time compute and token budgets consistently enhances factual accuracy by 2-8%, supporting the efficacy of test-time scaling for performance enhancement in open-domain QA tasks.
👉 Paper link: https://huggingface.co/papers/2505.11140

11. MatTools: Benchmarking Large Language Models for Materials Science Tools
🔑 Keywords: Large language models, literature comprehension, property prediction, MatTools, functional Python code
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To evaluate the proficiency of large language models (LLMs) in answering materials science questions through generating and safely executing codes using physics-based computational materials science packages.
🛠️ Research Methods:
– Development of a benchmark application, MatTools, comprising a QA benchmark with 69,225 QA pairs derived from the pymatgen codebase, and a real-world tool-usage benchmark with 49 tasks requiring functional Python code generation.
💬 Research Conclusions:
– Generalist LLMs outperform specialists, AI is efficient in interacting with AI tools, and simpler methods yield better results; MatTools offers a standardized framework to enhance LLM capabilities in materials science applications.
👉 Paper link: https://huggingface.co/papers/2505.10852

12. Humans expect rationality and cooperation from LLM opponents in strategic games
🔑 Keywords: Large Language Models, p-beauty contest, Nash-equilibrium, strategic reasoning, reasoning ability
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To understand human behavior against LLMs in strategic multiplayer settings and highlight the differences compared to interactions with other humans.
🛠️ Research Methods:
– Conducted a controlled, monetarily-incentivised laboratory experiment using a within-subject design to compare individual behavior in a multi-player p-beauty contest.
💬 Research Conclusions:
– Humans choose lower numbers when competing with LLMs, driven by the zero Nash-equilibrium strategy, mainly among those with high strategic reasoning abilities. The perception of LLMs’ reasoning ability and unexpected cooperation tendencies influence this behavior. Findings suggest significant implications for mechanism design in mixed human-LLM systems.
👉 Paper link: https://huggingface.co/papers/2505.11011

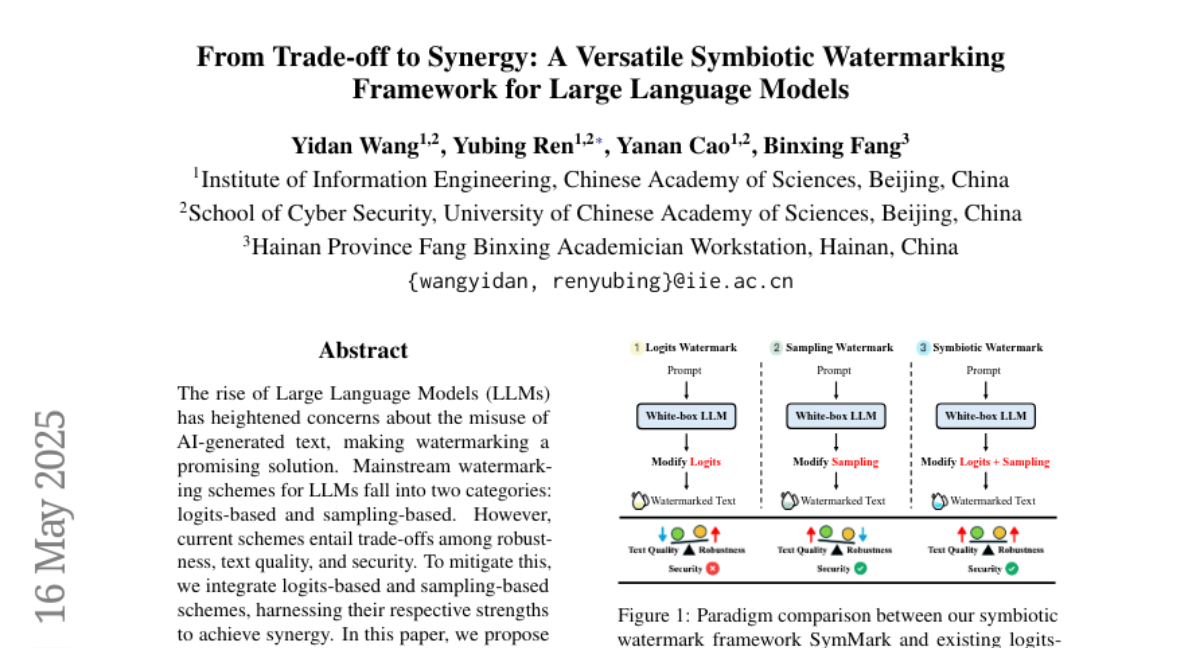
13. From Trade-off to Synergy: A Versatile Symbiotic Watermarking Framework for Large Language Models
🔑 Keywords: Large Language Models, Watermarking, Logits-based, Sampling-based, State-of-the-art
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to develop a versatile symbiotic watermarking framework that integrates logits-based and sampling-based schemes, optimizing the trade-offs between robustness, text quality, and security in AI-generated text.
🛠️ Research Methods:
– The study proposes three strategies (serial, parallel, and hybrid) within the framework and uses token entropy and semantic entropy to embed watermarks adaptively.
💬 Research Conclusions:
– Experiments on various datasets and models demonstrate that the proposed method outperforms existing baselines, achieving state-of-the-art performance. The framework provides new insights into diverse watermarking paradigms.
👉 Paper link: https://huggingface.co/papers/2505.09924
14. CheXGenBench: A Unified Benchmark For Fidelity, Privacy and Utility of Synthetic Chest Radiographs
🔑 Keywords: synthetic chest radiograph generation, privacy risks, clinical utility, generative fidelity, standardised benchmark
💡 Category: AI in Healthcare
🌟 Research Objective:
– To introduce CheXGenBench, a framework for evaluating synthetic chest radiograph generation, focusing on fidelity, privacy risks, and clinical utility.
🛠️ Research Methods:
– Utilized standardised data partitioning and a unified evaluation protocol with over 20 quantitative metrics to assess 11 leading text-to-image architectures.
💬 Research Conclusions:
– Identified critical inefficiencies in current evaluation protocols and established a standardised benchmark for medical AI, releasing SynthCheX-75K dataset to support further research.
👉 Paper link: https://huggingface.co/papers/2505.10496

15. Learning Dense Hand Contact Estimation from Imbalanced Data
🔑 Keywords: hand interaction datasets, dense hand contact estimation, class imbalance issue, balanced contact sampling, vertex-level class-balanced (VCB) loss
💡 Category: Computer Vision
🌟 Research Objective:
– Analyze and address challenges in dense hand contact estimation using imbalanced hand interaction datasets.
🛠️ Research Methods:
– Implement balanced contact sampling to mitigate the class imbalance issue.
– Develop vertex-level class-balanced (VCB) loss to address spatial imbalance by reweighting the contribution based on contact frequency.
💬 Research Conclusions:
– Successfully predicts dense hand contact estimation while overcoming class and spatial imbalance issues.
– Large-scale hand contact data can now be effectively used for this prediction task.
👉 Paper link: https://huggingface.co/papers/2505.11152

16. Unifying Segment Anything in Microscopy with Multimodal Large Language Model
🔑 Keywords: Vision-Language Knowledge (VLK), Multimodal Large Language Models (MLLMs), Segment Anything Model (SAM), Semantic Boundary Regularization (SBR)
💡 Category: AI in Healthcare
🌟 Research Objective:
– To enhance the generalization capabilities of biomedical segmentation models across different domain datasets by leveraging Vision-Language Knowledge.
🛠️ Research Methods:
– Utilized Multimodal Large Language Models to guide SAM in learning from cross-domain microscopy data.
– Introduced the Vision-Language Semantic Alignment module and Semantic Boundary Regularization to improve segmentation accuracy.
💬 Research Conclusions:
– Achieved significant performance improvements with 7.71% increase in Dice and 12.10% increase in SA for in-domain datasets.
– Demonstrated strong generalization and a 6.79% increase in Dice and 10.08% increase in SA across out-of-domain datasets.
👉 Paper link: https://huggingface.co/papers/2505.10769

17. Improving Assembly Code Performance with Large Language Models via Reinforcement Learning
🔑 Keywords: Large Language Models, Code Optimization, Reinforcement Learning, Proximal Policy Optimization, Execution Performance
💡 Category: Reinforcement Learning
🌟 Research Objective:
– This study explores the potential of Large Language Models (LLMs) to optimize assembly code performance, which is traditionally challenging with high-level languages.
🛠️ Research Methods:
– The paper introduces a reinforcement learning framework, using Proximal Policy Optimization (PPO) and a reward function assessing functional correctness and execution performance, compared to gcc -O3.
💬 Research Conclusions:
– The model, Qwen2.5-Coder-7B-PPO, demonstrated high effectiveness with a 96.0% test pass rate and an average speedup of 1.47x over the gcc -O3 baseline, outperforming all evaluated models, showcasing LLMs as proficient optimizers for assembly code.
👉 Paper link: https://huggingface.co/papers/2505.11480

18. InstanceGen: Image Generation with Instance-level Instructions
🔑 Keywords: generative models, text-to-image models, semantics, structural constraints, LLM-based
💡 Category: Generative Models
🌟 Research Objective:
– Enhance text-to-image models by better capturing complex prompts involving multiple objects and attributes through structural guidance.
🛠️ Research Methods:
– Introduce a technique that integrates image-based fine-grained structural guidance with LLM-based instance-level instructions.
💬 Research Conclusions:
– Achieved outputs that adhere closely to the semantics of text prompts, including detailed object counts and spatial relations.
👉 Paper link: https://huggingface.co/papers/2505.05678
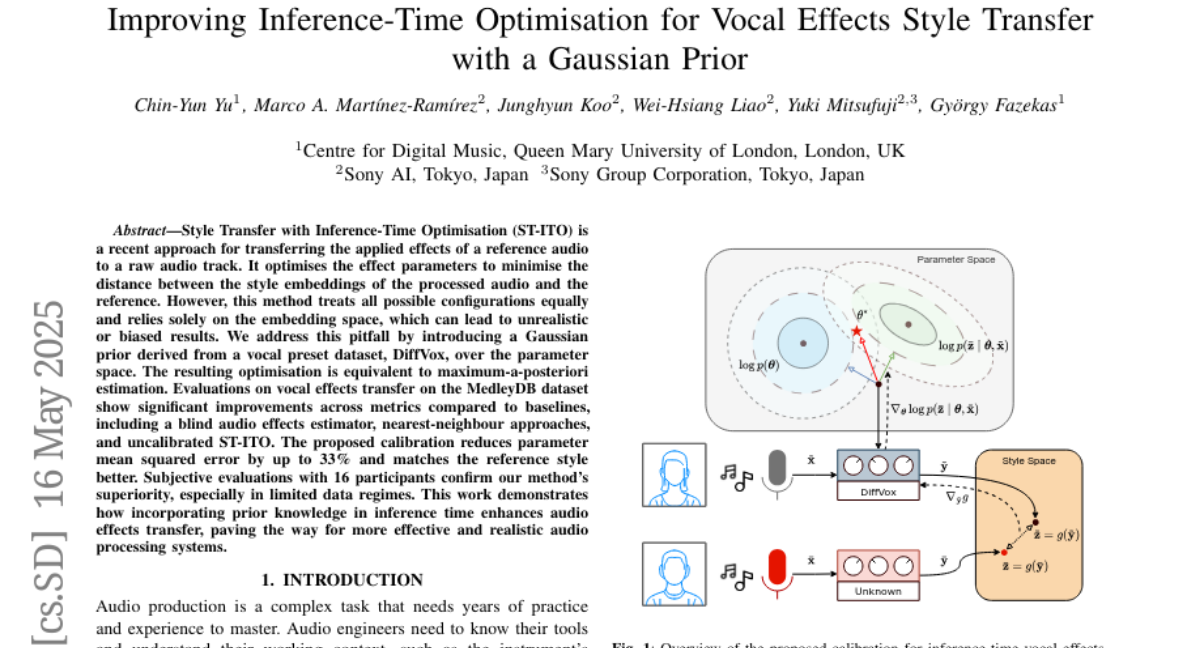
19. Improving Inference-Time Optimisation for Vocal Effects Style Transfer with a Gaussian Prior
🔑 Keywords: Style Transfer, Inference-Time Optimisation, Gaussian Prior, Maximum-a-Posteriori Estimation, Audio Effects Transfer
💡 Category: Machine Learning
🌟 Research Objective:
– To enhance Style Transfer with Inference-Time Optimisation (ST-ITO) for audio by minimizing unrealistic results and achieving better style matching through Gaussian prior from a vocal preset dataset.
🛠️ Research Methods:
– Introduced a Gaussian prior over parameter space leading to maximum-a-posteriori estimation, evaluated against MedleyDB dataset to show improvements over existing methods like blind audio effects estimator and nearest-neighbour approaches.
💬 Research Conclusions:
– Achieved significant reduction in parameter mean squared error by up to 33%, with better style matching. Subjective evaluations confirmed superiority in limited data settings, demonstrating enhanced audio effects transfer through incorporating prior knowledge.
👉 Paper link: https://huggingface.co/papers/2505.11315
20. GIE-Bench: Towards Grounded Evaluation for Text-Guided Image Editing
🔑 Keywords: Text-guided image editing, Functional correctness, Image content preservation, GPT-Image-1, Instruction-following accuracy
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce a new benchmark for evaluating text-guided image editing models along functional correctness and image content preservation.
🛠️ Research Methods:
– Utilize automatically generated multiple-choice questions and object-aware masking techniques to assess model performance.
💬 Research Conclusions:
– GPT-Image-1 excels in instruction-following accuracy but tends to over-modify irrelevant image regions; GIE-Bench offers a scalable evaluation framework.
👉 Paper link: https://huggingface.co/papers/2505.11493

21.
