AI Native Daily Paper Digest – 20250612

1. Confidence Is All You Need: Few-Shot RL Fine-Tuning of Language Models
🔑 Keywords: Reinforcement Learning, Self-Confidence, Large Language Models, AI-generated summary, Post-training
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve the accuracy of large language models using the model’s own confidence as a reward signal, eliminating the need for human labels or reward engineering.
🛠️ Research Methods:
– The method involves using Reinforcement Learning via Self-Confidence (RLSC) applied to the Qwen2.5-Math-7B model with minimal samples and training steps.
💬 Research Conclusions:
– RLSC significantly improves accuracy in various benchmarks, including a +13.4% improvement on AIME2024 and over +20% improvements on other math-related datasets, while being a simple and scalable post-training approach.
👉 Paper link: https://huggingface.co/papers/2506.06395

2. Seedance 1.0: Exploring the Boundaries of Video Generation Models
🔑 Keywords: diffusion modeling, multi-source data curation, text-to-video, fine-grained supervised fine-tuning, model acceleration
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Seedance 1.0, an advanced video generation model focusing on high performance and inference efficiency.
🛠️ Research Methods:
– Utilizing multi-source data curation with video captioning for comprehensive learning.
– Implementing an efficient architecture supporting multi-shot generation for both text-to-video and image-to-video tasks.
– Employing post-training optimization with fine-tuning and video-specific RLHF for enhanced performance.
💬 Research Conclusions:
– Seedance 1.0 achieves significantly faster video generation with superior quality, demonstrating exceptional spatiotemporal fluidity, structural stability, and narrative coherence.
👉 Paper link: https://huggingface.co/papers/2506.09113

3. Autoregressive Adversarial Post-Training for Real-Time Interactive Video Generation
🔑 Keywords: Autoregressive Adversarial Post-Training, Latent Video Diffusion Model, Real-time Video Generation, Interactive Video Generator, Adversarial Training
💡 Category: Generative Models
🌟 Research Objective:
– To transform a pre-trained latent video diffusion model into a real-time, interactive video generator using autoregressive adversarial post-training (AAPT).
🛠️ Research Methods:
– The approach utilizes adversarial training to enhance autoregressive generation efficiency and employs a single neural function evaluation (1NFE) to generate each latent frame in real-time.
💬 Research Conclusions:
– The proposed model achieves real-time streaming video generation at 24fps, supporting resolutions of 736×416 on a single H100 or 1280×720 on 8xH100, demonstrating significant reduction of error accumulation with long video generation.
👉 Paper link: https://huggingface.co/papers/2506.09350

4. Multiverse: Your Language Models Secretly Decide How to Parallelize and Merge Generation
🔑 Keywords: Multiverse, native parallel generation, MapReduce paradigm, Multiverse Attention, efficiency gain
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces Multiverse, a generative model enabling natively parallel text generation, aiming to achieve performance comparable to autoregressive models.
🛠️ Research Methods:
– Utilizes a three-stage MapReduce paradigm: (i) adaptive task decomposition, (ii) parallel subtask execution, and (iii) lossless result synthesis.
– Implements Multiverse Engine featuring a dedicated scheduler for dynamic switching between sequential and parallel generation.
💬 Research Conclusions:
– Multiverse-32B achieves performance on par with leading autoregressive models, with evidence from AIME24 & 25 scores.
– Exhibits superior scaling and efficiency, achieving up to 2x speedup across varying batch sizes, and has been open-sourced with a complete ecosystem.
👉 Paper link: https://huggingface.co/papers/2506.09991

5. ComfyUI-R1: Exploring Reasoning Models for Workflow Generation
🔑 Keywords: ComfyUI-R1, Automated Workflow Generation, Chain-of-Thought (CoT) Reasoning, Reinforcement Learning, AI Art
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop ComfyUI-R1, a large reasoning model aimed at automating workflow generation for AI art through chain-of-thought reasoning and reinforcement learning.
🛠️ Research Methods:
– The model is built using a two-stage framework involving CoT fine-tuning for domain adaptation and reinforcement learning with a fine-grained rule-metric hybrid reward system to enhance reasoning capabilities and ensure format validity.
💬 Research Conclusions:
– ComfyUI-R1 exhibits superior performance, achieving a 97% format validity rate and surpassing previous state-of-the-art models in generating intricate AI art workflows. The reasoning process and code transformation are key to its effectiveness.
👉 Paper link: https://huggingface.co/papers/2506.09790

6. Auto-Regressive vs Flow-Matching: a Comparative Study of Modeling Paradigms for Text-to-Music Generation
🔑 Keywords: Auto-Regressive decoding, Conditional Flow-Matching, text-to-music generation, generation quality, scalability
💡 Category: Generative Models
🌟 Research Objective:
– To systematically compare Auto-Regressive decoding and Conditional Flow-Matching in the domain of text-to-music generation, focusing exclusively on modeling paradigms to understand their specific strengths and limitations.
🛠️ Research Methods:
– Conducted a controlled empirical analysis training models from scratch with identical datasets and configurations to evaluate performance across various dimensions such as generation quality, robustness, scalability, and audio inpainting capabilities.
💬 Research Conclusions:
– The study provides actionable insights into the trade-offs and behaviors of each modeling paradigm, offering guidance for future architectural and training decisions in text-to-music generation systems.
👉 Paper link: https://huggingface.co/papers/2506.08570

7. PlayerOne: Egocentric World Simulator
🔑 Keywords: PlayerOne, egocentric realistic world simulator, coarse-to-fine pipeline, part-disentangled motion injection, joint reconstruction framework
💡 Category: Generative Models
🌟 Research Objective:
– Introduce PlayerOne, an egocentric realistic world simulator, to facilitate immersive exploration in dynamic environments.
🛠️ Research Methods:
– Utilize a coarse-to-fine training pipeline with advanced motion injection and reconstruction frameworks to generate aligned egocentric videos.
– Implement a part-disentangled motion injection scheme for precise control of part-level movements and a joint reconstruction framework for 4D scene modeling.
💬 Research Conclusions:
– Successfully demonstrated great generalization ability in precise control of human movements and consistent world modeling, marking a pioneering initiative in egocentric real-world simulation.
👉 Paper link: https://huggingface.co/papers/2506.09995

8. SeerAttention-R: Sparse Attention Adaptation for Long Reasoning
🔑 Keywords: SeerAttention-R, sparse attention, reasoning models, self-distilled gating mechanism, AIME benchmark
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce SeerAttention-R, a sparse attention framework optimized for reasoning models during long decoding.
🛠️ Research Methods:
– Utilize a self-distilled gating mechanism and a highly optimized sparse decoding kernel for improved performance and integration in existing models.
💬 Research Conclusions:
– Achieves significant speedups while maintaining near-lossless reasoning accuracy, demonstrating 9x speedup over FlashAttention-3 on H100 GPU.
👉 Paper link: https://huggingface.co/papers/2506.08889

9. SWE-Flow: Synthesizing Software Engineering Data in a Test-Driven Manner
🔑 Keywords: SWE-Flow, Test-Driven Development (TDD), unit tests, Runtime Dependency Graph (RDG), fine-tuning
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce SWE-Flow, a framework for improving TDD by automatically inferring development steps from unit tests.
🛠️ Research Methods:
– Utilizes the Runtime Dependency Graph to capture function interactions and generate development schedules.
– Created training and test datasets from GitHub projects to improve open model performance in TDD-based coding.
💬 Research Conclusions:
– SWE-Flow significantly enhances fine-tuning of open models for real-world TDD tasks, as evidenced by improved performance on the SWE-Flow-Eval benchmark.
👉 Paper link: https://huggingface.co/papers/2506.09003

10. InterActHuman: Multi-Concept Human Animation with Layout-Aligned Audio Conditions
🔑 Keywords: End-to-end human animation, multi-modal conditions, region-specific binding, layout information, mask predictor
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce a framework for precise, per-identity control of multi-modal concepts in human animation, addressing limitations of global condition injection in multi-concept scenarios.
🛠️ Research Methods:
– Utilize a mask predictor to match appearance cues, enabling automatic layout information inference and enforce region-specific binding of conditions from multiple modalities.
💬 Research Conclusions:
– The novel design facilitates high-quality, controllable multi-concept human-centric video generation, validated by empirical results and ablation studies against existing methods.
👉 Paper link: https://huggingface.co/papers/2506.09984

11. Time to Talk: LLM Agents for Asynchronous Group Communication in Mafia Games
🔑 Keywords: LLM-agent, asynchronous communication, social dynamics, online Mafia games, AI Native
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To develop an adaptive asynchronous LLM-agent capable of performing on par with human players in environments with complex social dynamics, like online Mafia games.
🛠️ Research Methods:
– The study involved creating a dataset from online Mafia games featuring both human participants and the asynchronous agent to evaluate its performance and integration into group settings.
💬 Research Conclusions:
– The asynchronous LLM-agent was able to mirror human players in both game performance and participation, showing potential for realistic applications in group discussions and environments with complex social interactions.
👉 Paper link: https://huggingface.co/papers/2506.05309

12. Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning
🔑 Keywords: Large Language Models, reproducibility, numerical precision, reasoning models, LayerCast
💡 Category: Natural Language Processing
🌟 Research Objective:
– This study aims to investigate reproducibility issues in Large Language Models (LLMs) caused by hardware and precision variations.
🛠️ Research Methods:
– Through systematic experiments across diverse hardware, software, and precision settings, the researchers quantify the conditions under which model outputs diverge.
💬 Research Conclusions:
– The paper reveals that floating-point precision significantly impacts reproducibility in LLMs, often neglected in evaluation.
– The study introduces a lightweight inference pipeline, LayerCast, which maintains memory efficiency while enhancing numerical stability by storing weights in 16-bit precision and performing computations in FP32.
👉 Paper link: https://huggingface.co/papers/2506.09501

13. SAFE: Multitask Failure Detection for Vision-Language-Action Models
🔑 Keywords: Vision-Language-Action Models, Failure Detector, SAFE, Task Generalization, Conformal Prediction
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper introduces SAFE, a failure detector designed to generalize across unseen tasks by leveraging high-level internal features of vision-language-action models.
🛠️ Research Methods:
– SAFE is trained on both successful and failed task rollouts and is evaluated on unseen tasks, demonstrating compatibility with various policy architectures and environments.
💬 Research Conclusions:
– SAFE achieves state-of-the-art performance in failure detection with an optimal trade-off between accuracy and detection time, validated through extensive testing in both simulated and real-world settings.
👉 Paper link: https://huggingface.co/papers/2506.09937

14. Vision Matters: Simple Visual Perturbations Can Boost Multimodal Math Reasoning
🔑 Keywords: multimodal large language models, visual processing, perceptual robustness, mathematical reasoning, visual perturbation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary aim is to enhance the mathematical reasoning abilities of multimodal large language models (MLLMs) through visual perturbation without algorithmic modifications or additional data.
🛠️ Research Methods:
– The study introduces a visual perturbation framework incorporating three targeted perturbations: distractor concatenation, dominance-preserving mixup, and random rotation, which are integrated into existing post-training pipelines like SFT, DPO, and GRPO.
💬 Research Conclusions:
– The research highlights that visual perturbation plays a crucial role in improving multimodal mathematical reasoning, achieving performance gains comparable to algorithmic changes. It demonstrates that each perturbation type uniquely contributes to visual reasoning, with notable improvements observed in open-source 7B RL-tuned models like Qwen2.5-VL-7B.
👉 Paper link: https://huggingface.co/papers/2506.09736

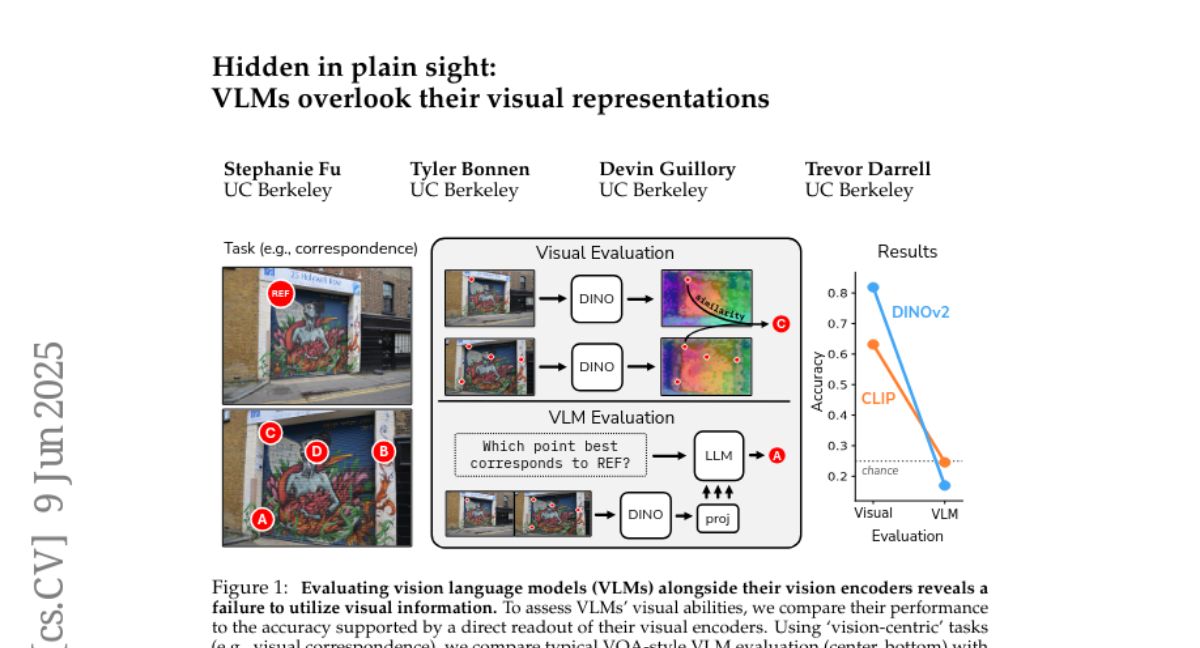
15. Hidden in plain sight: VLMs overlook their visual representations
🔑 Keywords: Vision Language Models, Visual Encoders, Language Priors, Vision Representations, Visual Information
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to compare the performance of Vision Language Models (VLMs) and their visual encoders on vision-centric tasks to understand the integration of visual and linguistic information.
🛠️ Research Methods:
– The study uses a series of vision-centric benchmarks like depth estimation and correspondence to evaluate the performance and investigates the degradation of vision representations, the brittleness to task prompts, and the role of the language model in solving tasks.
💬 Research Conclusions:
– Vision Language Models underperform compared to their visual encoders due to ineffective use of visual information and reliance on language priors, with the bottleneck being the language model’s role in solving vision-centric tasks.
👉 Paper link: https://huggingface.co/papers/2506.08008
16. UFM: A Simple Path towards Unified Dense Correspondence with Flow
🔑 Keywords: Unified Flow & Matching model, Transformer Architecture, Dense Image Correspondence, Optical Flow, Wide-Baseline Scenarios
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a Unified Flow & Matching model (UFM) using a transformer architecture for unified data training to improve dense image correspondence.
🛠️ Research Methods:
– Employ a simple, generic transformer architecture to directly regress the (u, v) flow, simplifying training and enhancing accuracy for large image flows.
💬 Research Conclusions:
– UFM achieves 28% more accuracy than state-of-the-art flow methods and demonstrates 62% less error with 6.7x faster performance compared to dense wide-baseline matchers. It is the first model to outperform specialized approaches in both domains, allowing for fast, general-purpose correspondence and paving the way for multi-modal, long-range, and real-time correspondence tasks.
👉 Paper link: https://huggingface.co/papers/2506.09278
17. Reparameterized LLM Training via Orthogonal Equivalence Transformation
🔑 Keywords: POET, reParameterized training algorithm, Orthogonal Equivalence Transformation, large language models, generalization
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose POET, a reParameterized training algorithm using Orthogonal Equivalence Transformation to optimize neurons in large language models.
🛠️ Research Methods:
– Reparameterization of each neuron with two learnable orthogonal matrices and a fixed random weight matrix to preserve spectral properties and ensure stable optimization.
💬 Research Conclusions:
– POET demonstrates effective and scalable training for large language models, validated by extensive experiments.
👉 Paper link: https://huggingface.co/papers/2506.08001

18. MIRAGE: Multimodal foundation model and benchmark for comprehensive retinal OCT image analysis
🔑 Keywords: MIRAGE, Multimodal FM, OCT, SLO, Segmentation
💡 Category: AI in Healthcare
🌟 Research Objective:
– The objective is to propose MIRAGE, a novel multimodal foundation model that excels in the classification and segmentation of OCT and SLO images, addressing limitations of existing models.
🛠️ Research Methods:
– Development of MIRAGE leveraging multimodal data, alongside a new evaluation benchmark for OCT/SLO classification and segmentation tasks.
💬 Research Conclusions:
– MIRAGE outperforms existing general and specialized models in ophthalmic image classification and segmentation, proving its effectiveness for robust AI systems in retinal analysis.
👉 Paper link: https://huggingface.co/papers/2506.08900

19. Cross-Frame Representation Alignment for Fine-Tuning Video Diffusion Models
🔑 Keywords: Cross-frame Representation Alignment, Video Diffusion Models, Fine-tuning, Semantic Coherence, Visual Fidelity
💡 Category: Generative Models
🌟 Research Objective:
– To enhance video diffusion model fine-tuning by improving visual fidelity and semantic coherence across frames using CREPA.
🛠️ Research Methods:
– Introduction of Cross-frame Representation Alignment (CREPA) as a regularization technique aligning hidden states with external features from neighboring frames.
– Empirical evaluations on large-scale video diffusion models including CogVideoX-5B and Hunyuan Video, using parameter-efficient methods like LoRA.
💬 Research Conclusions:
– CREPA improves both visual fidelity and cross-frame semantic coherence.
– Demonstrated broad applicability across diverse datasets with varying attributes, confirming its effectiveness in video diffusion model fine-tuning.
👉 Paper link: https://huggingface.co/papers/2506.09229

20. When to Trust Context: Self-Reflective Debates for Context Reliability
🔑 Keywords: token-level self-confidence, asymmetric multi-agent debate, contextual inconsistencies, Large Language Models
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose a lightweight framework, Self-Reflective Debate for Contextual Reliability (SR-DCR), that enhances the robustness of large language models against contextual inconsistencies with minimal computational cost.
🛠️ Research Methods:
– Integration of token-level self-confidence with an asymmetric debate between agents; a critic and a defender engage in a debate evaluated by a judge model to determine context reliability.
💬 Research Conclusions:
– SR-DCR consistently outperforms classical debate and confidence-only baselines, enhancing robustness to misleading contexts while maintaining accuracy on trustworthy inputs, all with minimal computational overhead.
👉 Paper link: https://huggingface.co/papers/2506.06020

21. Branched Schrödinger Bridge Matching
🔑 Keywords: BranchSBM, Schrödinger Bridge Matching, Generative Modeling, Multi-path Evolution, Cell Fate Bifurcations
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces BranchSBM, a framework to model branched stochastic paths and multi-path evolution from a single initial distribution to multiple outcomes.
🛠️ Research Methods:
– The framework extends Schrödinger Bridge Matching by parameterizing multiple time-dependent velocity fields and growth processes, addressing limitations of existing unimodal transition methods.
💬 Research Conclusions:
– BranchSBM is more expressive and crucial for tasks like multi-path surface navigation, modeling cell fate bifurcations, and simulating diverging cellular responses to perturbations.
👉 Paper link: https://huggingface.co/papers/2506.09007

22. Query-Level Uncertainty in Large Language Models
🔑 Keywords: Internal Confidence, Large Language Models, AI-generated summary, adaptive inference, RAG
💡 Category: Natural Language Processing
🌟 Research Objective:
– To detect knowledge boundaries in Large Language Models using a method called Internal Confidence.
🛠️ Research Methods:
– Introduction of a novel, training-free method leveraging self-evaluations across layers and tokens called Internal Confidence.
💬 Research Conclusions:
– The Internal Confidence method outperforms several baselines on factual QA and mathematical reasoning tasks, facilitating efficient RAG and model cascading to reduce inference costs while maintaining performance.
👉 Paper link: https://huggingface.co/papers/2506.09669

23. Kvasir-VQA-x1: A Multimodal Dataset for Medical Reasoning and Robust MedVQA in Gastrointestinal Endoscopy
🔑 Keywords: AI Native, MedVQA, multimodal AI systems, large language models, visual augmentations
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study aims to enhance the reliability and effectiveness of multimodal AI systems in clinical settings by developing the Kvasir-VQA-x1 dataset, which incorporates clinical complexity and visual diversity.
🛠️ Research Methods:
– Utilizes large language models to generate 159,549 new question-answer pairs that are stratified by complexity.
– Introduces various visual augmentations to mimic imaging artifacts, ensuring robust evaluation in real-world clinical scenarios.
💬 Research Conclusions:
– Kvasir-VQA-x1 provides a more challenging and clinically relevant benchmark, accelerating the development of reliable multimodal AI systems.
– The dataset, publicly available, adheres to FAIR data principles and supports two evaluation tracks to gauge standard VQA performance and model robustness.
👉 Paper link: https://huggingface.co/papers/2506.09958

24. A Call for Collaborative Intelligence: Why Human-Agent Systems Should Precede AI Autonomy
🔑 Keywords: LLM-based Human-Agent Systems, AI-generated summary, teamwork, transparency, adaptation
💡 Category: Human-AI Interaction
🌟 Research Objective:
– Propose LLM-based Human-Agent Systems (LLM-HAS) over fully autonomous AI agents for improved collaboration and understanding of human needs.
🛠️ Research Methods:
– Analyze examples from healthcare, finance, and software development to demonstrate the effectiveness of human-AI teamwork.
💬 Research Conclusions:
– Advocate for AI systems that enhance human capabilities through collaboration, arguing that the future of AI lies in systems that work with humans rather than replace them.
👉 Paper link: https://huggingface.co/papers/2506.09420

25. TTT-Bench: A Benchmark for Evaluating Reasoning Ability with Simple and Novel Tic-Tac-Toe-style Games
🔑 Keywords: Large reasoning models, reasoning benchmarks, strategic reasoning, spatial reasoning, logical reasoning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To introduce TTT-Bench to evaluate the basic strategic, spatial, and logical reasoning abilities in large reasoning models (LRMs) through simple games.
🛠️ Research Methods:
– Development of a new benchmark consisting of four two-player Tic-Tac-Toe-style games, using a programmatic approach for game generation and evaluation of state-of-the-art LRMs.
💬 Research Conclusions:
– Large reasoning models that perform well in advanced mathematical problems often struggle with these simpler reasoning tasks, scoring significantly lower on TTT-Bench compared to more complex benchmarks.
👉 Paper link: https://huggingface.co/papers/2506.10209

26.
