AI Native Daily Paper Digest – 20250613

1. ReasonMed: A 370K Multi-Agent Generated Dataset for Advancing Medical Reasoning
🔑 Keywords: ReasonMed, LLMs, Error Refiner, Chain-of-Thought, Medical Reasoning
💡 Category: AI in Healthcare
🌟 Research Objective:
– Introduce ReasonMed, a large-scale medical reasoning dataset, to improve the performance of medical question answering models by combining detailed reasoning paths with concise summaries.
🛠️ Research Methods:
– Utilize a multi-agent verification and refinement process along with an Error Refiner to enhance reasoning paths and identify error-prone steps.
– Systematically investigate best practices for training medical reasoning models by leveraging detailed Chain-of-Thought reasoning and concise summaries.
💬 Research Conclusions:
– ReasonMed-7B sets a new performance benchmark for sub-10B models, significantly outperforming previous models and even exceeding larger models on PubMedQA.
👉 Paper link: https://huggingface.co/papers/2506.09513

2. SWE-Factory: Your Automated Factory for Issue Resolution Training Data and Evaluation Benchmarks
🔑 Keywords: Large Language Models, SWE-Factory, SWE-Builder, exit-code-based grading, automated fail2pass validation
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to automate the creation and validation of datasets for GitHub issue resolution tasks to enhance the training and evaluation capabilities of Large Language Models.
🛠️ Research Methods:
– Introduction of SWE-Factory, an automated pipeline integrating SWE-Builder, a multi-agent system for constructing evaluation environments, exit-code-based grading to standardize evaluation, and automated fail2pass validation.
💬 Research Conclusions:
– The automated pipeline, SWE-Factory, demonstrates high efficiency and accuracy, achieving 100% accuracy in grading and high precision in validation, which significantly accelerates dataset construction.
👉 Paper link: https://huggingface.co/papers/2506.10954

3. Text-Aware Image Restoration with Diffusion Models
🔑 Keywords: Text-Aware Image Restoration, text-image hallucination, text-spotting module, AI Native, multi-task diffusion framework
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce Text-Aware Image Restoration (TAIR) to improve both image recovery and textual fidelity in degraded images.
🛠️ Research Methods:
– Develop a multi-task diffusion framework named TeReDiff that integrates features from diffusion models into a text-spotting module for enhanced joint training.
💬 Research Conclusions:
– TAIR approach consistently outperforms existing methods in restoration, achieving significant improvements in text recognition accuracy.
👉 Paper link: https://huggingface.co/papers/2506.09993

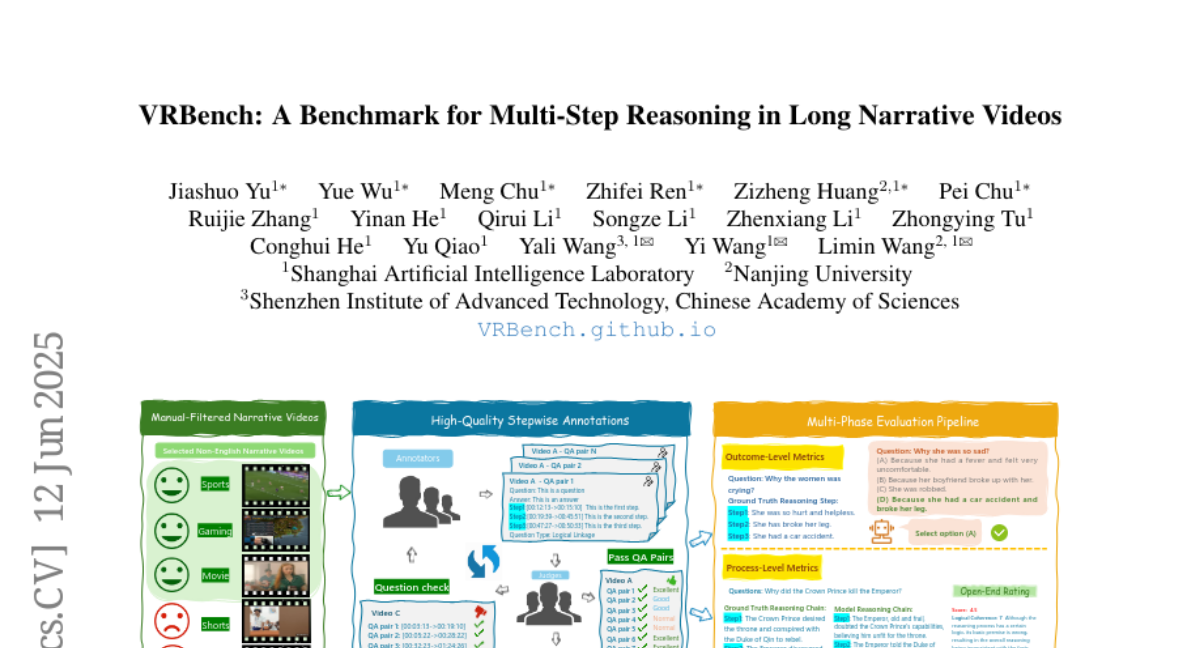
4. VRBench: A Benchmark for Multi-Step Reasoning in Long Narrative Videos
🔑 Keywords: VRBench, multi-step reasoning, procedural validity, human-AI collaborative, coherent reasoning chains
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– VRBench is designed to evaluate models’ multi-step reasoning and procedural validity using long narrative videos and a human-AI collaborative framework.
🛠️ Research Methods:
– The benchmark consists of 1,010 long videos with human-labeled multi-step question-answering pairs and reasoning steps, undergoing expert inter-rater reviewing for plot coherence.
– It employs a multi-phase evaluation pipeline, assessing at both outcome and process levels with a progress-level LLM-guided scoring metric.
💬 Research Conclusions:
– Extensive evaluations on VRBench provide valuable insights advancing the field of multi-step reasoning through thorough analysis of 12 LLMs and 16 VLMs.
👉 Paper link: https://huggingface.co/papers/2506.10857
5. AniMaker: Automated Multi-Agent Animated Storytelling with MCTS-Driven Clip Generation
🔑 Keywords: AniMaker, Multi-Agent Framework, MCTS-Gen, AniEval, AI-Generated Storytelling
💡 Category: Generative Models
🌟 Research Objective:
– The primary goal is to generate coherent storytelling videos from text input using a multi-agent framework that surpasses existing models in quality and efficiency.
🛠️ Research Methods:
– AniMaker employs a specialized multi-agent framework with agents such as the Director Agent, Photography Agent, Reviewer Agent, and Post-Production Agent, integrating technical components like MCTS-Gen and AniEval to optimize video generation and evaluation.
💬 Research Conclusions:
– Experiments validate AniMaker’s superior quality and efficiency, enhancing multi-candidate generation and bringing AI-generated storytelling animations closer to production standards.
👉 Paper link: https://huggingface.co/papers/2506.10540

6. Discrete Audio Tokens: More Than a Survey!
🔑 Keywords: Discrete audio tokens, Perceptual quality, Large language models, Tokenization methods, Encoder-decoder
💡 Category: Natural Language Processing
🌟 Research Objective:
– To perform a systematic review and benchmark of discrete audio tokenizers across speech, music, and general audio domains.
🛠️ Research Methods:
– Developed a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains.
– Evaluated tokenizers on benchmarks for reconstruction, downstream performance, and acoustic language modeling, and conducted controlled ablation studies.
💬 Research Conclusions:
– The study highlights key limitations, practical considerations, and challenges in discrete audio tokenization, providing insights and guidance for future research.
👉 Paper link: https://huggingface.co/papers/2506.10274

7. Magistral
🔑 Keywords: Magistral, Reinforcement Learning, Multimodal Understanding, Instruction Following, AI-generated summary
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce Magistral, a scalable reinforcement learning pipeline to enhance multimodal understanding and instruction following in large language models.
🛠️ Research Methods:
– Develop a reasoning model and an RL pipeline from scratch, relying solely on proprietary models and infrastructure, without using existing RL traces.
💬 Research Conclusions:
– Demonstrate that pure reinforcement learning on text data maintains or improves multimodal understanding, instruction following, and function calling in large language models.
👉 Paper link: https://huggingface.co/papers/2506.10910

8. Domain2Vec: Vectorizing Datasets to Find the Optimal Data Mixture without Training
🔑 Keywords: Domain2Vec, Meta-domains, Domain vector, Language model, Pretraining
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce Domain2Vec, a novel method to decompose datasets into meta-domains for optimizing language model pretraining and performance with lower computational costs.
🛠️ Research Methods:
– Utilized a classifier to map datasets onto domain vectors representing distributions over a vocabulary of meta-domains, leveraging the Distribution Alignment Assumption (DA²) for optimal data mixture identification without additional training.
💬 Research Conclusions:
– Domain2Vec enhances downstream task performance with minimal computational overhead, achieving the same validation loss while using only 51.5% of computation compared to traditional methods, and improves performance by an average of 2.83% under equivalent computational budgets.
👉 Paper link: https://huggingface.co/papers/2506.10952

9. Optimus-3: Towards Generalist Multimodal Minecraft Agents with Scalable Task Experts
🔑 Keywords: Optimus-3, Multimodal Large Language Models, Mixture-of-Experts, Knowledge-enhanced Data Generation, Reinforcement Learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Address challenges in building a generalist agent with perception, planning, action, grounding, and reflection capabilities in open-world environments like Minecraft.
🛠️ Research Methods:
– Introduce a knowledge-enhanced data generation pipeline for scalable and high-quality training data.
– Employ a Mixture-of-Experts architecture with task-level routing to reduce interference among heterogeneous tasks.
– Develop a Multimodal Reasoning-Augmented Reinforcement Learning approach for better handling of visual diversity.
💬 Research Conclusions:
– Optimus-3 surpasses generalist multimodal large language models and state-of-the-art agents across various tasks in the Minecraft setting.
👉 Paper link: https://huggingface.co/papers/2506.10357

10. PosterCraft: Rethinking High-Quality Aesthetic Poster Generation in a Unified Framework
🔑 Keywords: Aesthetic Poster Generation, Text Rendering, Region-Aware Fine-Tuning, Reinforcement Learning, Vision-Language Refinement
💡 Category: Generative Models
🌟 Research Objective:
– Develop PosterCraft, a unified framework for generating visually compelling aesthetic posters without relying on predefined layouts.
🛠️ Research Methods:
– Utilization of a cascaded workflow with large-scale text-rendering optimization, region-aware fine-tuning, aesthetic-text-reinforcement learning, and vision-language refinement.
💬 Research Conclusions:
– PosterCraft significantly outperforms open-source baselines in rendering accuracy, layout coherence, and overall visual appeal.
👉 Paper link: https://huggingface.co/papers/2506.10741

11. Resa: Transparent Reasoning Models via SAEs
🔑 Keywords: SAE-Tuning, reasoning models, sparse autoencoders, AI-generated summary, cost-effective performance
💡 Category: Natural Language Processing
🌟 Research Objective:
– To cost-effectively elicit strong reasoning in language models by leveraging their underlying representations using SAE-Tuning.
🛠️ Research Methods:
– Employed an efficient sparse autoencoder tuning procedure to train a family of reasoning models, and utilized SAE to guide supervised fine-tuning, using verified question-answer data without reasoning traces.
💬 Research Conclusions:
– SAE-Tuning retains >97% of reasoning performance of RL-trained counterparts while significantly reducing training costs and time.
– Demonstrated promising reasoning performance on specific tasks with minimal additional cost.
– Found that the reasoning abilities extracted are potentially both generalizable to larger corpuses and modular, allowing them to be attached to different models at test time with comparable gains.
👉 Paper link: https://huggingface.co/papers/2506.09967

12. Ming-Omni: A Unified Multimodal Model for Perception and Generation
🔑 Keywords: Ming-Omni, multimodal model, modality-specific routers, AI-generated summary, open-source
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video efficiently within a single framework.
🛠️ Research Methods:
– Utilizes dedicated encoders and modality-specific routers in an MoE architecture to process and fuse multimodal inputs.
– Integration of advanced audio decoders and Ming-Lite-Uni for enhanced audio and image generation capabilities.
💬 Research Conclusions:
– Ming-Omni offers a robust solution for unified perception and generation across all modalities, matching existing models in functionality.
– Released as open-source to foster further research and community development.
👉 Paper link: https://huggingface.co/papers/2506.09344

13. VideoDeepResearch: Long Video Understanding With Agentic Tool Using
🔑 Keywords: VideoDeepResearch, Long Video Understanding, Multi-Modal Learning, Text-only Large Reasoning Model, Modular Tools
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To challenge the common belief that Long Video Understanding requires foundation multi-modal large language models with extended context windows and strong visual perception capabilities.
🛠️ Research Methods:
– Introduced VideoDeepResearch, a novel agentic framework using a text-only large reasoning model combined with a modular multi-modal toolkit for problem-solving in LVU tasks.
– Conducted extensive experiments on popular LVU benchmarks such as MLVU, Video-MME, and LVBench.
💬 Research Conclusions:
– VideoDeepResearch significantly improved performance over existing MLLM baselines, surpassing previous state-of-the-art results by up to 9.6% on key benchmarks.
– Highlights the promise of agentic systems in overcoming challenges in Long Video Understanding tasks.
👉 Paper link: https://huggingface.co/papers/2506.10821

14. AutoMind: Adaptive Knowledgeable Agent for Automated Data Science
🔑 Keywords: AutoMind, LLM, data science agents, machine learning pipeline, expert knowledge base
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces AutoMind, a framework to enhance automated data science using expert knowledge, strategic exploration, and adaptive coding.
🛠️ Research Methods:
– AutoMind incorporates a curated expert knowledge base, an agentic knowledgeable tree search algorithm, and a self-adaptive coding strategy to address limitations in traditional LLM-agent frameworks.
💬 Research Conclusions:
– Evaluations demonstrate AutoMind’s superior performance over state-of-the-art baselines, suggesting its potential as a robust solution for fully automated data science.
👉 Paper link: https://huggingface.co/papers/2506.10974

15. CreatiPoster: Towards Editable and Controllable Multi-Layer Graphic Design Generation
🔑 Keywords: AI-assisted graphic design, RGBA large multimodal model, JSON specification, multi-layer designs, automated metrics
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce CreatiPoster, a framework generating high-quality, editable graphic compositions from text or assets.
🛠️ Research Methods:
– Utilize RGBA large multimodal model to produce detailed JSON specifications for each design layer and a conditional background model to synthesize coherent backgrounds.
💬 Research Conclusions:
– CreatiPoster surpasses existing open-source and commercial graphic design tools in performance, supporting diverse applications like canvas editing and multilingual adaptation.
👉 Paper link: https://huggingface.co/papers/2506.10890

16. Build the web for agents, not agents for the web
🔑 Keywords: Agentic Web Interface, web agents, Large Language Models, interface optimization, safety
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To propose a new design paradigm, the Agentic Web Interface, specifically optimized for web agents to navigate and complete tasks efficiently and safely.
🛠️ Research Methods:
– Introduction of six guiding principles for the Agentic Web Interface design, focusing on safety, efficiency, and standardization to address existing interface mismatches.
💬 Research Conclusions:
– Current web interfaces, designed for humans, present mismatch challenges for LLM-based web agents.
– The proposed Agentic Web Interface paradigm aims to create more effective, reliable, and transparent web agent systems by aligning interface design with agentic capabilities.
👉 Paper link: https://huggingface.co/papers/2506.10953

17. ChineseHarm-Bench: A Chinese Harmful Content Detection Benchmark
🔑 Keywords: Large Language Models, Harmful Content Detection, Chinese Datasets, Knowledge-Augmented Model
💡 Category: Natural Language Processing
🌟 Research Objective:
– Develop a comprehensive benchmark for Chinese harmful content detection using real-world data.
🛠️ Research Methods:
– Utilization of human-annotated rules and Large Language Models to augment the knowledge base for improved detection efficiency and accuracy.
💬 Research Conclusions:
– Presented a knowledge-augmented baseline that combines explicit human-annotated rules with implicit knowledge from LLMs, enabling smaller models to perform comparably to state-of-the-art LLMs.
👉 Paper link: https://huggingface.co/papers/2506.10960

18. LaTtE-Flow: Layerwise Timestep-Expert Flow-based Transformer
🔑 Keywords: LaTtE-Flow, Vision-Language Models, Multimodal Model, Image Generation, Flow-based Architecture
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop LaTtE-Flow, an efficient architecture that unifies image understanding and generation within a single multimodal model.
🛠️ Research Methods:
– Use of Layerwise Timestep Experts flow-based Transformer for efficient image generation.
– Incorporation of a Timestep-Conditioned Residual Attention mechanism to enhance information reuse across layers.
💬 Research Conclusions:
– LaTtE-Flow achieves strong multimodal understanding with competitive image generation quality, offering approximately 6x faster inference speed compared to recent unified models.
👉 Paper link: https://huggingface.co/papers/2506.06952

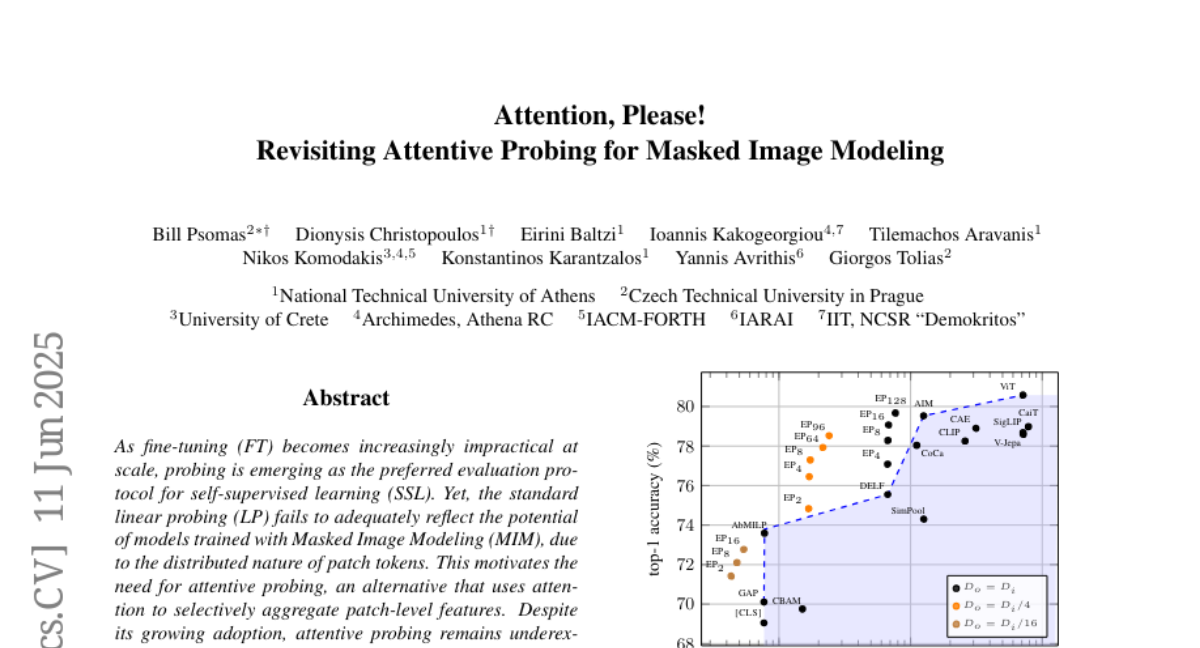
19. Attention, Please! Revisiting Attentive Probing for Masked Image Modeling
🔑 Keywords: Efficient probing, Multi-query cross-attention, Self-supervised learning, Attention maps
💡 Category: Machine Learning
🌟 Research Objective:
– To enhance performance in self-supervised learning by developing a more efficient probing mechanism that reduces parameterization and computational costs compared to traditional methods.
🛠️ Research Methods:
– Systematic study of existing attentive probing methods, introducing a multi-query cross-attention mechanism to analyze mechanisms and benchmark performance.
💬 Research Conclusions:
– The proposed efficient probing method outperforms traditional linear probing and existing attentive probing approaches, demonstrating substantial speed-ups and generalizing well across various pre-training paradigms and settings.
👉 Paper link: https://huggingface.co/papers/2506.10178
20. Comment on The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
🔑 Keywords: Large Reasoning Models, accuracy collapse, token limits
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Investigate why Large Reasoning Models exhibit failures on planning puzzles beyond certain complexity thresholds.
🛠️ Research Methods:
– Analyze the limitations in experimental design, including excess token limits, inadequate classification in evaluation frameworks, and mathematically impossible instances.
💬 Research Conclusions:
– The reported failures of Large Reasoning Models are primarily due to experimental design flaws rather than reasoning capabilities, as evidenced by improved accuracy under controlled conditions.
👉 Paper link: https://huggingface.co/papers/2506.09250

21. VerIF: Verification Engineering for Reinforcement Learning in Instruction Following
🔑 Keywords: VerIF, Reinforcement Learning, Instruction-Following, LLM, Verification
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Explore the verification challenge in reinforcement learning for instruction-following tasks and propose a new method, VerIF, to address it.
🛠️ Research Methods:
– Combines rule-based code verification with LLM-based verification from a large reasoning model. Utilizes a high-quality dataset, VerInstruct, containing about 22,000 instances with verification signals.
💬 Research Conclusions:
– VerIF achieves state-of-the-art performance and significant improvements on instruction-following benchmarks, while the models generalize well to unseen constraints. The trained models’ general capabilities remain unaffected.
👉 Paper link: https://huggingface.co/papers/2506.09942

22. What Makes a Good Natural Language Prompt?
🔑 Keywords: Large Language Models, Natural Language Processing, Prompting, Instruction-tuning, Reasoning Tasks
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose a framework for evaluating and optimizing natural language prompts in large language models, focusing on their impact on reasoning tasks.
🛠️ Research Methods:
– Conducted a meta-analysis of over 150 prompting-related papers, proposing a property- and human-centric framework with 21 properties categorized into six dimensions. Analyzed correlations among properties in high-quality prompts.
💬 Research Conclusions:
– Revealed imbalanced support of prompts across models and tasks, highlighting significant research gaps.
– Established that instruction-tuning on property-enhanced prompts improves reasoning models, thus opening new directions in prompting research.
👉 Paper link: https://huggingface.co/papers/2506.06950

23. Eliciting Fine-Tuned Transformer Capabilities via Inference-Time Techniques
🔑 Keywords: In-Context Learning, AI-Generated Summary, Text Generation, Turing Completeness, Resource-efficient Deployment
💡 Category: Natural Language Processing
🌟 Research Objective:
– To formally prove that supervised fine-tuning capabilities can be approximated by transformers using in-context learning without altering model parameters.
🛠️ Research Methods:
– Utilizes theoretical bounds and practical techniques within inference-time scenarios, focusing on unbounded computational resources and dataset access for text generation and classification tasks.
💬 Research Conclusions:
– Demonstrates that transformers’ Turing completeness provides a theoretical foundation for efficiently deploying large language models. Practical techniques like retrieval-augmented generation bridge the gap between theoretical insights and real-world applications.
👉 Paper link: https://huggingface.co/papers/2506.08060

24. Compound AI Systems Optimization: A Survey of Methods, Challenges, and Future Directions
🔑 Keywords: Compound AI Systems, Natural Language Feedback, Non-Differentiable Systems, Optimizing AI, Large Language Models
💡 Category: AI Systems and Tools
🌟 Research Objective:
– This paper aims to provide a systematic review of recent advancements in optimizing compound AI systems, with a focus on integrating various components and addressing new challenges in their interactions.
🛠️ Research Methods:
– The paper examines both numerical and language-based optimization techniques and classifies existing methods along several key dimensions.
💬 Research Conclusions:
– The study formalizes the notion of compound AI system optimization, highlights open research challenges, and provides future directions for this evolving field. A list of surveyed papers is made publicly available for further reference.
👉 Paper link: https://huggingface.co/papers/2506.08234

25. UniPre3D: Unified Pre-training of 3D Point Cloud Models with Cross-Modal Gaussian Splatting
🔑 Keywords: UniPre3D, 3D vision, Gaussian primitives, representation learning
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a unified pre-training method, UniPre3D, that can be applied to 3D point clouds and models of any scale.
🛠️ Research Methods:
– Utilization of Gaussian primitives and differentiable Gaussian splatting for image rendering, with integration of 2D features from pre-trained image models.
💬 Research Conclusions:
– UniPre3D demonstrates universal effectiveness across object- and scene-level tasks with diverse point cloud models, validated through extensive experiments.
👉 Paper link: https://huggingface.co/papers/2506.09952

26. DreamActor-H1: High-Fidelity Human-Product Demonstration Video Generation via Motion-designed Diffusion Transformers
🔑 Keywords: Diffusion Transformer, human-product demonstration videos, masked cross-attention, 3D body mesh template, structured text encoding
💡 Category: Generative Models
🌟 Research Objective:
– To generate high-fidelity human-product demonstration videos by preserving identities and spatial relationships.
🛠️ Research Methods:
– Utilization of a Diffusion Transformer-based framework with masked cross-attention and structured text encoding to maintain identity integrity and enhance 3D consistency.
– Employment of 3D body mesh templates and product bounding boxes for precise motion guidance in videos.
💬 Research Conclusions:
– The proposed method outperforms state-of-the-art techniques by better maintaining identity integrity and generating realistic demonstration motions for e-commerce and digital marketing.
👉 Paper link: https://huggingface.co/papers/2506.10568

27. LLM Unlearning Should Be Form-Independent
🔑 Keywords: LLM unlearning, Form-Dependent Bias, Rank-one Concept Redirection (ROCR), AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address the limitations of LLM unlearning methods that are dependent on the expression form of knowledge.
🛠️ Research Methods:
– Introduction of Form-Dependent Bias and analysis of its manifestation patterns.
– Proposal of Rank-one Concept Redirection (ROCR), a training-free method targeting invariant concepts.
💬 Research Conclusions:
– ROCR significantly enhances the effectiveness of unlearning processes compared to traditional methods, with fast modification capabilities and natural output generation.
👉 Paper link: https://huggingface.co/papers/2506.07795

28. TeleMath: A Benchmark for Large Language Models in Telecom Mathematical Problem Solving
🔑 Keywords: AI Native, Large Language Models, mathematical reasoning, benchmark dataset, telecommunications
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the performance of Large Language Models in domain-specific mathematical problems within telecommunications using the TeleMath dataset.
🛠️ Research Methods:
– Utilization of a benchmark dataset called TeleMath, consisting of 500 QnA pairs, and a generation pipeline created by Subject Matter Experts to assess the effectiveness of open-source LLMs.
💬 Research Conclusions:
– Models explicitly designed for mathematical reasoning outperform general-purpose large parameter models in telecommunications-related tasks. The dataset and evaluation code have been released to facilitate result reproducibility and support further research.
👉 Paper link: https://huggingface.co/papers/2506.10674

29. Breaking Data Silos: Towards Open and Scalable Mobility Foundation Models via Generative Continual Learning
🔑 Keywords: generative continual learning, privacy-preserving, mobility foundation models, Mixture-of-Experts Transformer, catastrophic forgetting
💡 Category: Generative Models
🌟 Research Objective:
– Develop a scalable and privacy-preserving framework, MoveGCL, for training mobility foundation models without sharing raw data.
🛠️ Research Methods:
– Utilized generative continual learning to replay synthetic trajectories and employed a Mixture-of-Experts Transformer with mobility-aware expert routing to manage heterogeneous mobility patterns.
💬 Research Conclusions:
– MoveGCL achieves performance comparable to joint training, outperforms federated learning baselines, and provides robust privacy protection in real-world urban datasets.
👉 Paper link: https://huggingface.co/papers/2506.06694

30. Draft-based Approximate Inference for LLMs
🔑 Keywords: Large Language Models, Transformers, draft models, SpecKV, SpecPC
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to enhance approximate inference for long-context Large Language Models (LLMs) by predicting token and key-value pair importance more accurately using draft models.
🛠️ Research Methods:
– Introduction of a novel framework utilizing small draft models with two specific implementations: SpecKV and SpecPC, to improve key-value pair importance assessment and prompt token identification, respectively.
💬 Research Conclusions:
– The study demonstrates that the proposed methods consistently achieve higher accuracy and maintain efficiency compared to existing baselines in long-context benchmarks.
👉 Paper link: https://huggingface.co/papers/2506.08373

31. Token Perturbation Guidance for Diffusion Models
🔑 Keywords: Token Perturbation Guidance, Classifier-Free Guidance, Diffusion Models, Perturbation Matrices, Conditional and Unconditional Generation
💡 Category: Generative Models
🌟 Research Objective:
– To propose Token Perturbation Guidance (TPG) as a training-free, condition-agnostic method for improving generation quality in diffusion models.
🛠️ Research Methods:
– TPG involves applying perturbation matrices to intermediate token representations and employing a norm-preserving shuffling operation within the diffusion network.
💬 Research Conclusions:
– TPG achieved nearly a 2x improvement in FID for unconditional generation over the SDXL baseline and closely matched CFG in prompt alignment, establishing it as an effective guidance method for a broader class of diffusion models.
👉 Paper link: https://huggingface.co/papers/2506.10036

32. Beyond True or False: Retrieval-Augmented Hierarchical Analysis of Nuanced Claims
🔑 Keywords: retrieval-augmented generation, hierarchical structure, AI-generated summary, corpus-specific perspectives, nuanced claims
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose ClaimSpect, a framework that constructs hierarchical structures of aspects for claims, enriching them with diverse perspectives from a corpus.
🛠️ Research Methods:
– Utilizes a retrieval-augmented generation-based approach to automatically construct and enrich aspect hierarchies from input corpora.
– Applies the framework to various scientific and political claims to demonstrate its robustness and accuracy.
💬 Research Conclusions:
– ClaimSpect effectively deconstructs nuanced claims and represents perspectives within a corpus.
– Validated through real-world case studies and human evaluation, showcasing its superiority over multiple baselines.
👉 Paper link: https://huggingface.co/papers/2506.10728

33. NoLoCo: No-all-reduce Low Communication Training Method for Large Models
🔑 Keywords: NoLoCo, language models, communication overhead, convergence rate, optimization method
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce a novel optimization method, NoLoCo, to eliminate explicit parameter synchronization and reduce communication overhead during language model training.
🛠️ Research Methods:
– Proposed a novel variant of the Nesterov momentum optimizer.
– Conducted theoretical convergence analysis and empirical testing across various model sizes and accelerator counts.
💬 Research Conclusions:
– NoLoCo achieves faster convergence rates and reduced idling time compared to existing methods like DiLoCo, especially on low-bandwidth networks.
– The method requires less communication overhead and is more efficient in large-scale training scenarios.
👉 Paper link: https://huggingface.co/papers/2506.10911

34. Decomposing MLP Activations into Interpretable Features via Semi-Nonnegative Matrix Factorization
🔑 Keywords: SNMF, Mechanistic Interpretability, LLMs, MLP Activations, Causal Steering
💡 Category: Natural Language Processing
🌟 Research Objective:
– The primary aim is to identify interpretable features in large language models (LLMs) by directly decomposing MLP activations to explain their outputs causally.
🛠️ Research Methods:
– Utilizes semi-nonnegative matrix factorization (SNMF) to decompose MLP activations, offering an alternative to sparse autoencoders (SAEs) for capturing interpretable features in an unsupervised way.
💬 Research Conclusions:
– SNMF-derived features outperform SAEs and supervised methods in causal evaluations, aligning well with human-interpretable concepts and exposing hierarchical structures in activation spaces.
👉 Paper link: https://huggingface.co/papers/2506.10920

35. Fine-Grained Perturbation Guidance via Attention Head Selection
🔑 Keywords: HeadHunter, Diffusion Transformer, attention perturbation, SoftPAG, AI-generated
💡 Category: Generative Models
🌟 Research Objective:
– Develop “HeadHunter,” a framework for selecting attention heads in Diffusion Transformer architectures to enhance image generation quality and style control.
🛠️ Research Methods:
– Investigate attention perturbation granularity and introduce SoftPAG for tuning perturbation strength.
💬 Research Conclusions:
– “HeadHunter” mitigates oversmoothing, allowing fine-grained control and targeted manipulation of visual styles, outperforming existing methods.
👉 Paper link: https://huggingface.co/papers/2506.10978

36. MCA-Bench: A Multimodal Benchmark for Evaluating CAPTCHA Robustness Against VLM-based Attacks
🔑 Keywords: CAPTCHA, benchmark, vision-language model, cracking agents, challenge complexity
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce MCA-Bench as a unified benchmark to evaluate CAPTCHA security across multiple modalities.
🛠️ Research Methods:
– Utilize a shared vision-language model backbone and fine-tune specialized cracking agents to assess different CAPTCHA types consistently.
💬 Research Conclusions:
– MCA-Bench successfully maps vulnerabilities in modern CAPTCHA designs and provides quantitative analysis of challenge complexity, interaction depth, and model solvability. The study proposes design principles for CAPTCHA improvement and highlights open challenges.
👉 Paper link: https://huggingface.co/papers/2506.05982

37. LaMP-Cap: Personalized Figure Caption Generation With Multimodal Figure Profiles
🔑 Keywords: AI-generated captions, LaMP-Cap, personalized figure caption generation, multimodal profiles
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce LaMP-Cap, a dataset for improving AI-generated figure captions through personalized multimodal profiles.
🛠️ Research Methods:
– Experiments conducted using four LLMs to evaluate the effectiveness of profile information in generating personalized captions.
💬 Research Conclusions:
– Multimodal profiles, especially the inclusion of images, significantly enhance the alignment of AI-generated captions with original author-written captions according to ablation studies.
👉 Paper link: https://huggingface.co/papers/2506.06561

38. Discovering Hierarchical Latent Capabilities of Language Models via Causal Representation Learning
🔑 Keywords: causal representation learning, latent capability factors, Open LLM Leaderboard, linear causal structure
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to identify a concise causal structure that explains performance variations in language models by controlling for base model variations.
🛠️ Research Methods:
– The study employs a causal representation learning framework, where observed benchmark performance is modeled as a linear transformation of a few latent capability factors.
💬 Research Conclusions:
– A three-node linear causal structure was identified, revealing scientific insights into the causal direction from general problem-solving capabilities to instruction-following proficiency, and culminating in mathematical reasoning ability. This highlights the importance of controlling for base model variations in evaluating language models.
👉 Paper link: https://huggingface.co/papers/2506.10378

39. TaxoAdapt: Aligning LLM-Based Multidimensional Taxonomy Construction to Evolving Research Corpora
🔑 Keywords: LLM-generated taxonomy, dynamic adaptation, granularity-preserving, computer science conferences
💡 Category: Foundations of AI
🌟 Research Objective:
– The main goal of the study is to propose TaxoAdapt, a framework that dynamically adapts an LLM-generated taxonomy for scientific literature across multiple dimensions to improve the granularity and coherence of taxonomy structures.
🛠️ Research Methods:
– TaxoAdapt utilizes iterative hierarchical classification to expand the taxonomy width and depth based on the topical distribution of a given corpus.
💬 Research Conclusions:
– The TaxoAdapt framework demonstrates state-of-the-art performance, generating taxonomies that are 26.51% more granularity-preserving and 50.41% more coherent than current leading methods, according to evaluations by large language models.
👉 Paper link: https://huggingface.co/papers/2506.10737
40. StreamSplat: Towards Online Dynamic 3D Reconstruction from Uncalibrated Video Streams
🔑 Keywords: 3D scene reconstruction, dynamic scenes, uncalibrated video, probabilistic sampling, bidirectional deformation
💡 Category: Computer Vision
🌟 Research Objective:
– StreamSplat aims to achieve real-time 3D scene reconstruction from uncalibrated video, focusing on accurate dynamics and long-term stability.
🛠️ Research Methods:
– Introduces a fully feed-forward framework that uses dynamic 3D Gaussian Splatting (3DGS).
– Develops a probabilistic sampling mechanism for 3DGS position prediction and a bidirectional deformation field for dynamic modeling.
💬 Research Conclusions:
– StreamSplat consistently surpasses previous methods in reconstruction quality and dynamic scene modeling, supporting the online reconstruction of arbitrarily long video streams.
👉 Paper link: https://huggingface.co/papers/2506.08862

41. EmbodiedGen: Towards a Generative 3D World Engine for Embodied Intelligence
🔑 Keywords: EmbodiedGen, generative AI, 3D assets, embodied intelligence, Unified Robotics Description Format (URDF)
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper aims to develop EmbodiedGen, a platform that efficiently generates high-quality, photorealistic 3D assets for embodied AI research using generative AI techniques.
🛠️ Research Methods:
– EmbodiedGen is a toolkit composed of six key modules: Image-to-3D, Text-to-3D, Texture Generation, Articulated Object Generation, Scene Generation, and Layout Generation. These modules generate diverse and interactive 3D worlds by leveraging generative AI.
💬 Research Conclusions:
– EmbodiedGen addresses challenges in scalability and generalization for embodied intelligence research by providing a cost-efficient, realistic, and scalable solution. It supports various physics simulation engines and facilitates fine-grained physical control in training and evaluation.
👉 Paper link: https://huggingface.co/papers/2506.10600

42.
