AI Native Daily Paper Digest – 20250711

1. Scaling RL to Long Videos
🔑 Keywords: Vision-Language Models, Reinforcement Learning, Long Video QA, Multi-modal Reinforcement Sequence Parallelism, LongVideo-Reason
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a framework that enhances the reasoning capabilities of vision-language models for long videos using reinforcement learning.
🛠️ Research Methods:
– Utilization of a large-scale dataset (LongVideo-Reason) with extensive reasoning annotations.
– Implementation of a two-stage training pipeline involving Chain-of-Thought Supervised Fine-Tuning and Reinforcement Learning.
– Introduction of the Multi-modal Reinforcement Sequence Parallelism infrastructure for efficient long video training.
💬 Research Conclusions:
– The LongVILA-R1-7B model shows strong performance on long video reasoning benchmarks, outperforming certain baselines.
– The framework demonstrates scalable performance improvements with increased video frame inputs and achieves significant training speedups.
– The training system is publicly released, supporting reinforcement learning on varied modalities, enhancing access and utility in the AI community.
👉 Paper link: https://huggingface.co/papers/2507.07966
2. T-LoRA: Single Image Diffusion Model Customization Without Overfitting
🔑 Keywords: T-LoRA, diffusion model fine-tuning, overfitting, single-image customization, dynamic fine-tuning strategy
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces T-LoRA, a Timestep-Dependent Low-Rank Adaptation framework designed for enhanced diffusion model personalization, particularly in single-image customization scenarios.
🛠️ Research Methods:
– T-LoRA employs a dynamic fine-tuning strategy and an orthogonal initialization technique to mitigate overfitting, especially at higher diffusion timesteps.
💬 Research Conclusions:
– T-LoRA, along with its components, outperforms standard LoRA and other techniques, providing a better balance of concept fidelity and text alignment in data-limited environments.
👉 Paper link: https://huggingface.co/papers/2507.05964

3. Traceable Evidence Enhanced Visual Grounded Reasoning: Evaluation and Methodology
🔑 Keywords: TreeBench, TreeVGR, Visual Grounded Reasoning, Reinforcement Learning, Traceable Evidence
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to evaluate visual grounded reasoning through the introduction of TreeBench, a comprehensive benchmark, focusing on subtle target detection and second-order reasoning.
🛠️ Research Methods:
– TreeBench was developed with principles like traceable evidence via bounding box evaluation and involved sampling high-quality images for challenging visual question-answering pairs.
– TreeVGR is introduced as a training paradigm that uses reinforcement learning to enhance joint localization and reasoning.
💬 Research Conclusions:
– The study demonstrates that even advanced models like OpenAI-o3 struggle with TreeBench, highlighting the complexity of the benchmark.
– TreeVGR effectively improves performance on various benchmarks, showing that traceability is crucial for advancing vision-grounded reasoning.
👉 Paper link: https://huggingface.co/papers/2507.07999

4. OST-Bench: Evaluating the Capabilities of MLLMs in Online Spatio-temporal Scene Understanding
🔑 Keywords: OST-Bench, multimodal large language models, Online Spatio-Temporal understanding, spatio-temporal reasoning, long-term memory retrieval
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce OST-Bench, a benchmark designed to evaluate multimodal large language models on online spatio-temporal reasoning tasks in real-world scenarios.
🛠️ Research Methods:
– Evaluated several leading MLLMs using OST-Bench, which consists of 1.4k scenes and 10k question-answer pairs from multiple datasets, under online settings.
💬 Research Conclusions:
– Identified challenges in complex spatio-temporal reasoning and long-term memory retrieval that negatively impact model performance. Noted the decline in accuracy with extended exploration horizon and growing memory.
👉 Paper link: https://huggingface.co/papers/2507.07984
5. Multi-Granular Spatio-Temporal Token Merging for Training-Free Acceleration of Video LLMs
🔑 Keywords: Spatio-temporal token merging, Video LLM, Computational scaling, STTM, Token budget
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to enhance the efficiency of video large language models (LLMs) by reducing computational complexity through a novel spatio-temporal token merging method.
🛠️ Research Methods:
– The proposed method, STTM, involves a training-free approach that leverages local spatial and temporal redundancy. It transforms each video frame into multi-granular spatial tokens and performs directed pairwise merging across the temporal dimension.
💬 Research Conclusions:
– STTM outperforms existing token reduction methods across six video QA benchmarks, achieving significant computational speed-ups with minimal accuracy loss. It offers a 2x speed-up with a 0.5% accuracy drop under a 50% token budget and a 3x speed-up with a 2% drop under a 30% budget. The method is also query-agnostic, allowing KV cache reuse across different questions for the same video.
👉 Paper link: https://huggingface.co/papers/2507.07990

6. PyVision: Agentic Vision with Dynamic Tooling
🔑 Keywords: PyVision, LLMs, Python-based tools, agentic visual reasoning, dynamic tooling
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Present PyVision, an interactive framework enabling LLMs to autonomously create and refine Python tools for visual reasoning, enhancing flexibility and interpretability.
🛠️ Research Methods:
– PyVision develops a taxonomy of Python-based tools and evaluates their performance across varied benchmarks, demonstrating significant improvements.
💬 Research Conclusions:
– PyVision achieves consistent performance gains, with notable improvements in benchmarks such as +7.8% on GPT-4.1 and +31.1% on Claude-4.0-Sonnet models, highlighting dynamic tooling as a means for models to invent tools, not just use them.
👉 Paper link: https://huggingface.co/papers/2507.07998

7. Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
🔑 Keywords: video diffusion models, 3D representations, geometry-aware structure, Angular Alignment, Scale Alignment
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to enhance the geometric-awareness of video diffusion models by introducing Geometry Forcing to internalize latent 3D structures.
🛠️ Research Methods:
– Proposed two alignment objectives, Angular Alignment and Scale Alignment, to guide model representations toward geometric structure by aligning with a pretrained geometric model.
💬 Research Conclusions:
– The proposed Geometry Forcing method significantly improves the visual quality and 3D consistency in video generation tasks compared to baseline methods.
👉 Paper link: https://huggingface.co/papers/2507.07982

8. LangSplatV2: High-dimensional 3D Language Gaussian Splatting with 450+ FPS
🔑 Keywords: LangSplatV2, 3D language field, sparse coefficient field, CUDA optimization, Gaussian Splatting
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to enhance 3D text querying speed and accuracy by optimizing LangSplatV2.
🛠️ Research Methods:
– LangSplatV2 replaces a heavyweight decoder with a sparse coefficient field and utilizes CUDA optimization to improve efficiency.
💬 Research Conclusions:
– LangSplatV2 significantly enhances speed and accuracy compared to its predecessor, achieving 476.2 FPS for feature splatting and 384.6 FPS for 3D text querying, despite limitations in real-time inference.
👉 Paper link: https://huggingface.co/papers/2507.07136
9. A Survey on Long-Video Storytelling Generation: Architectures, Consistency, and Cinematic Quality
🔑 Keywords: Video Generative Models, Long-form Videos, Character Consistency, Frame Redundancy
💡 Category: Generative Models
🌟 Research Objective:
– To identify key architectural components and training strategies for improving video generative models, enabling the production of long-form videos with consistent character appearances and narrative coherence.
🛠️ Research Methods:
– Comprehensive study and analysis of 32 papers on video generation, leading to the identification of effective architectural designs and performance characteristics. Includes constructing a novel taxonomy and comparative tables.
💬 Research Conclusions:
– Existing state-of-the-art video generative methods face limitations in maintaining character consistency and temporal diversity in long-form videos. While some progress exists, much work remains to enhance narrative cohesion and high-fidelity detail for multi-subject videos lasting over 150 seconds.
👉 Paper link: https://huggingface.co/papers/2507.07202

10. Skip a Layer or Loop it? Test-Time Depth Adaptation of Pretrained LLMs
🔑 Keywords: Chain-of-Layers (CoLa), Pretrained Large Language Model, Monte Carlo Tree Search, Layer Pruning
💡 Category: Natural Language Processing
🌟 Research Objective:
– Examine if pretrained neural networks can dynamically adapt architectural structure for different inputs without needing finetuning.
🛠️ Research Methods:
– Utilize selective layer manipulation and Monte Carlo Tree Search optimization to construct a Chain-of-Layers (CoLa) for individual test samples.
💬 Research Conclusions:
– Over 75% of samples with correct predictions by the original model could be optimized with shorter CoLa, enhancing inference efficiency.
– For over 60% of samples initially predicted incorrectly, optimized CoLa could rectify predictions, indicating performance enhancement potential.
👉 Paper link: https://huggingface.co/papers/2507.07996

11. Token Bottleneck: One Token to Remember Dynamics
🔑 Keywords: self-supervised learning, Token Bottleneck, sequential scene understanding, visual representations, robot manipulation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce Token Bottleneck (ToBo) to create compact, temporally aware visual representations for sequential scene understanding.
🛠️ Research Methods:
– Employ a self-supervised learning pipeline to encode and predict scenes using a bottleneck token, enabling temporal dynamics capture across scenes.
💬 Research Conclusions:
– ToBo outperforms baselines in simulated and real-world environments, demonstrating robustness and effectiveness in tasks like video label propagation and robot manipulation.
👉 Paper link: https://huggingface.co/papers/2507.06543

12. Machine Bullshit: Characterizing the Emergent Disregard for Truth in Large Language Models
🔑 Keywords: Machine Bullshit, AI-generated summary, Bullshit Index, RLHF, Chain-of-Thought Prompting, AI Alignment
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to introduce and analyze the broad concept of machine bullshit in LLMs to understand mechanisms underlying the loss of truthfulness.
🛠️ Research Methods:
– The researchers developed the Bullshit Index as a metric and a taxonomy of four qualitative bullshit forms. They conducted empirical evaluations using various datasets, including a new benchmark called BullshitEval.
💬 Research Conclusions:
– Findings highlight that RLHF and CoT prompting exacerbate forms of machine bullshit, revealing challenges in AI alignment and offering insights for improving truthfulness in LLMs.
👉 Paper link: https://huggingface.co/papers/2507.07484

13. Beyond the Linear Separability Ceiling
🔑 Keywords: Visual-Language Models, Linear Reasoning Bottleneck, Linear Separability Ceiling, Reasoning Pathways, Representation Quality
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to address the linear reasoning bottleneck in Visual-Language Models by proposing the Linear Separability Ceiling as a metric for evaluation. It suggests that targeted alignment is a more effective solution than simply enhancing representation learning.
🛠️ Research Methods:
– The research investigates the bottleneck using the Linear Separability Ceiling, a measure of a simple linear classifier’s performance on a model’s visual embeddings. Postfix tuning is used as a methodological control to explore reasoning pathways.
💬 Research Conclusions:
– The bottleneck is widespread due to failures in language model reasoning pathways, not poor visual perception. Addressing this requires task-dependent interventions, activating existing pathways for semantic tasks and adapting core model weights for complex reasoning. The study concludes that robust reasoning relies on targeted alignment, rather than merely improving representation quality.
👉 Paper link: https://huggingface.co/papers/2507.07574

14. Dynamic Chunking for End-to-End Hierarchical Sequence Modeling
🔑 Keywords: Hierarchical networks, dynamic chunking, AI Native, character-level robustness, data-dependent chunking strategies
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to develop a dynamic chunking mechanism that replaces traditional tokenization pipelines, enhancing performance and scalability across various languages and modalities.
🛠️ Research Methods:
– The introduction of hierarchical networks (H-Net) that learn segmentation strategies dynamically and jointly with the rest of the model, achieving end-to-end learning over byte-level data.
💬 Research Conclusions:
– H-Nets outperform traditional models by offering improved scalability, character-level robustness, and significantly better data efficiency, particularly in languages and modalities with weaker tokenization heuristics.
👉 Paper link: https://huggingface.co/papers/2507.07955

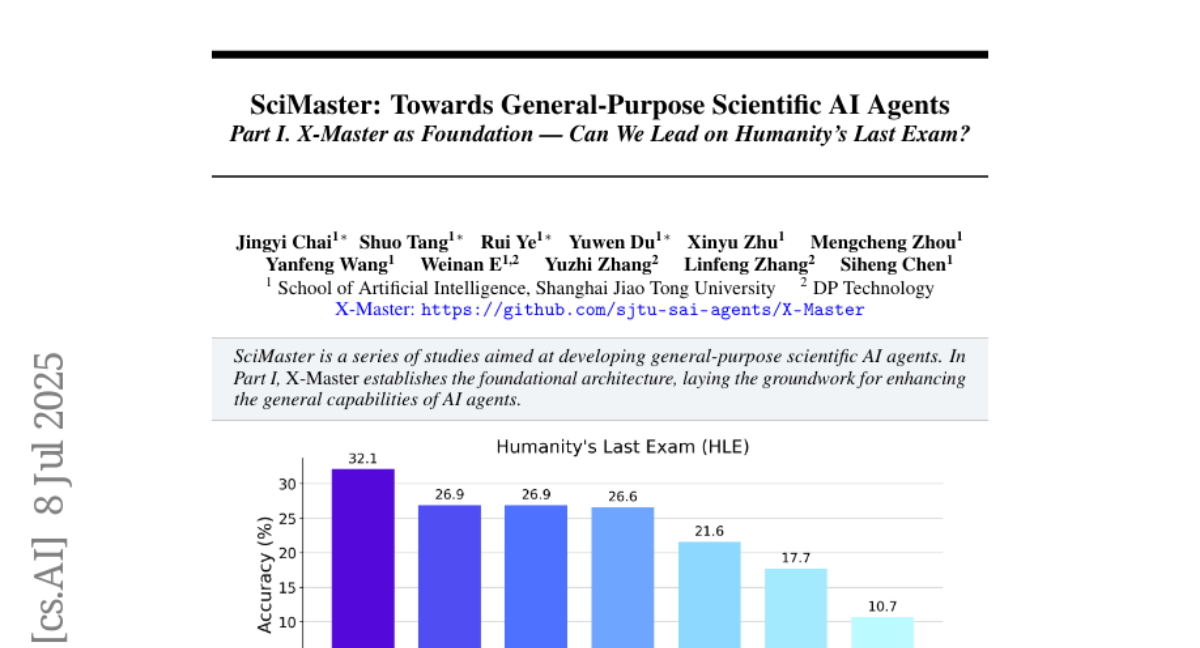
15. SciMaster: Towards General-Purpose Scientific AI Agents, Part I. X-Master as Foundation: Can We Lead on Humanity’s Last Exam?
🔑 Keywords: AI agents, Humanity’s Last Exam, X-Master, reasoning, code as interaction language
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To construct a foundational architecture for general-purpose AI agents and validate their capabilities through performance on Humanity’s Last Exam (HLE).
🛠️ Research Methods:
– Introduction of X-Master, a tool-augmented reasoning agent using built-in Python libraries and customized tools for enhanced reasoning.
– Development of X-Masters, a scattered-and-stacked agentic workflow to systematically enhance reasoning capabilities.
💬 Research Conclusions:
– X-Masters set a new state-of-the-art record on HLE with a score of 32.1%, surpassing previous scores by major entities like OpenAI and Google’s Deep Research.
– The findings provide insights into complex task-solving and future model training advancements.
👉 Paper link: https://huggingface.co/papers/2507.05241
16. Growing Transformers: Modular Composition and Layer-wise Expansion on a Frozen Substrate
🔑 Keywords: Large Language Models, Modular Composition, Mixture-of-Experts, AI Native, Continual Learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore a novel approach to developing large language models using fixed embeddings, emphasizing modular composition and layer-wise growth for enhanced performance and flexibility.
🛠️ Research Methods:
– Utilization of non-trainable, deterministic input embeddings as a universal substrate for “docking” two paradigms: merging specialist models into a Mixture-of-Experts model and a layer-wise constructive training methodology.
💬 Research Conclusions:
– The proposed method allows for seamless integration and performance enhancement of language models without catastrophic forgetting, and advocates for a shift from monolithic optimization to a more incremental, resource-efficient model development.
👉 Paper link: https://huggingface.co/papers/2507.07129

17. Re-Bottleneck: Latent Re-Structuring for Neural Audio Autoencoders
🔑 Keywords: Re-Bottleneck, Autoencoders, Latent Structure, Audio Compression, Semantic Embeddings
💡 Category: Generative Models
🌟 Research Objective:
– Modify pre-trained autoencoders to impose specific latent structures, enhancing performance in various downstream applications.
🛠️ Research Methods:
– Introduce a “Re-Bottleneck” framework to adjust the bottleneck layer of autoencoders with latent space losses to define user-specific structures, demonstrated through experiments involving latent channel ordering, semantic embedding alignment, and equivariance introduction.
💬 Research Conclusions:
– The Re-Bottleneck framework flexibly and efficiently adapts neural audio model representations to meet diverse application requirements with minimal extra training, maintaining reconstruction quality while aligning with semantic embeddings and introducing transformation equivariance.
👉 Paper link: https://huggingface.co/papers/2507.07867

18. Emergent Semantics Beyond Token Embeddings: Transformer LMs with Frozen Visual Unicode Representations
🔑 Keywords: Transformer models, visual embeddings, MMLU reasoning benchmark, representational interference, compositional architecture
💡 Category: Natural Language Processing
🌟 Research Objective:
– Explore the efficacy of fixed, visually derived embeddings in Transformer models, challenging the conventional role of trainable embeddings.
🛠️ Research Methods:
– Utilize non-semantic, precomputed visual embeddings from Unicode glyphs and introduce a Unicode-centric tokenizer for universal text coverage.
💬 Research Conclusions:
– Models with fixed visual embeddings outperformed those with trainable embeddings on reasoning benchmarks, suggesting that high-level semantics emerge from the model architecture and data scale rather than input embeddings.
👉 Paper link: https://huggingface.co/papers/2507.04886

19.
