AI Native Daily Paper Digest – 20250812

1. ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability
🔑 Keywords: Large Language Model, listwise ranking, reasoning-intensive reranker, reinforcement learning, ReasonRank
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance passage ranking tasks by developing a reasoning-intensive reranker called ReasonRank, utilizing synthesized training data and a two-stage post-training approach with reinforcement learning.
🛠️ Research Methods:
– An automated framework is proposed for creating reasoning-intensive training data, involving DeepSeek-R1 for label generation and self-consistency data filtering to ensure quality.
– A two-stage post-training approach is implemented with a cold-start supervised fine-tuning stage and a reinforcement learning stage to bolster reasoning ability.
💬 Research Conclusions:
– ReasonRank surpasses existing rerankers significantly, achieving state-of-the-art performance on the BRIGHT leaderboard, with markedly reduced latency compared to pointwise rerankers.
👉 Paper link: https://huggingface.co/papers/2508.07050

2. WideSearch: Benchmarking Agentic Broad Info-Seeking
🔑 Keywords: WideSearch, Large Language Models, benchmark, agentic search systems, quality control pipeline
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce WideSearch, a new benchmark for evaluating the reliability of automated search agents in large-scale information collection tasks, highlighting significant deficiencies in current systems.
🛠️ Research Methods:
– Developed a benchmark with 200 curated questions across 15 domains.
– Established a five-stage quality control pipeline to ensure dataset difficulty, completeness, and verifiability.
– Evaluated over 10 state-of-the-art search systems, including single-agent, multi-agent frameworks, and end-to-end commercial systems.
💬 Research Conclusions:
– Present search agents exhibit critical deficiencies in handling large-scale information seeking, with success rates near 0%, while human testers achieve near 100% success rates with sufficient time and cross-validation.
– The findings indicate urgent areas for future research and development in agentic search systems.
👉 Paper link: https://huggingface.co/papers/2508.07999

3. Omni-Effects: Unified and Spatially-Controllable Visual Effects Generation
🔑 Keywords: Omni-Effects, LoRA, Mixture of Experts, Spatial-Aware Prompt
💡 Category: Generative Models
🌟 Research Objective:
– Develop a unified framework (Omni-Effects) for generating prompt-guided and spatially controllable composite visual effects.
🛠️ Research Methods:
– Utilize LoRA-based Mixture of Experts to integrate diverse effects while mitigating cross-task interference.
– Employ Spatial-Aware Prompt to incorporate spatial control into text tokens, along with Independent-Information Flow to isolate control signals.
💬 Research Conclusions:
– Omni-Effects provides precise spatial control and diverse effect generation, enabling specification of effect category and location.
👉 Paper link: https://huggingface.co/papers/2508.07981

4. A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems
🔑 Keywords: Self-Evolving AI, Agent Systems, Feedback Loop, Ethical AI, Adaptive Systems
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The survey aims to provide a comprehensive review of self-evolving AI agents and their adaptation to dynamic environments through interaction data and feedback.
🛠️ Research Methods:
– A unified conceptual framework is introduced, highlighting key components such as System Inputs, Agent System, Environment, and Optimisers, to review various self-evolving techniques and domain-specific evolution strategies.
💬 Research Conclusions:
– The paper discusses evaluation, safety, and ethical considerations as crucial aspects for the effective and reliable functioning of self-evolving agentic systems, aiming to aid researchers in developing more adaptive, autonomous, and lifelong agentic systems.
👉 Paper link: https://huggingface.co/papers/2508.07407

5. BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent
🔑 Keywords: AI-generated, deep-research agents, large language models, retrieval methods, controlled experimentation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces BrowseComp-Plus, a curated benchmark that allows for controlled evaluation of deep-research agents and retrieval methods to gain insights into their performance and effectiveness.
🛠️ Research Methods:
– BrowseComp-Plus leverages a fixed, carefully curated corpus with human-verified supporting documents and challenging negatives for controlled experimentation. It distinguishes performance differences using various retrieval models.
💬 Research Conclusions:
– The benchmark effectively differentiates deep research system performance, showing significant improvements in accuracy when integrating GPT-5 with Qwen3-Embedding-8B, demonstrating the importance of retrieval effectiveness and citation accuracy.
👉 Paper link: https://huggingface.co/papers/2508.06600

6. Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization
🔑 Keywords: Klear-Reasoner, long reasoning, Chain-of-Thought supervised fine-tuning, reinforcement learning, Gradient-Preserving clipping Policy Optimization
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to enhance long reasoning capabilities in AI models using Klear-Reasoner for superior performance across various benchmarks.
🛠️ Research Methods:
– Implementation of a detailed post-training workflow including long Chain-of-Thought supervised fine-tuning and reinforcement learning with Gradient-Preserving clipping Policy Optimization.
💬 Research Conclusions:
– Klear-Reasoner demonstrates high reasoning capabilities, scoring remarkably in tests like AIME and LiveCodeBench, by efficiently utilizing high-quality data and addressing key issues in current clipping mechanisms in reinforcement learning.
👉 Paper link: https://huggingface.co/papers/2508.07629

7. UserBench: An Interactive Gym Environment for User-Centric Agents
🔑 Keywords: Large Language Models, UserBench, simulated users, task completion, user alignment
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The research aims to address the gap in LLM-based agents’ ability to proactively collaborate with users, especially when users’ goals are vague, evolving, or indirectly expressed.
🛠️ Research Methods:
– Introduction of UserBench, a user-centric benchmark designed for evaluating agents in multi-turn, preference-driven interactions with simulated users who start with underspecified goals.
💬 Research Conclusions:
– Evaluation reveals a significant disconnect between task completion and user alignment, with models aligning fully with user intents only 20% of the time.
– Even advanced models uncover fewer than 30% of all user preferences through active interaction, highlighting the challenges in developing true collaborative partners.
👉 Paper link: https://huggingface.co/papers/2507.22034

8. SONAR-LLM: Autoregressive Transformer that Thinks in Sentence Embeddings and Speaks in Tokens
🔑 Keywords: SONAR-LLM, decoder-only transformer, SONAR embedding space, token-level cross-entropy, AI-generated summary
💡 Category: Generative Models
🌟 Research Objective:
– Develop SONAR-LLM, a decoder-only transformer that enhances text generation quality through token-level cross-entropy in the SONAR embedding space without using diffusion sampling.
🛠️ Research Methods:
– A hybrid training approach combining token-level cross-entropy and supervision via the frozen SONAR decoder to retain semantic abstraction and restore a likelihood-based training signal.
– The model scales across various sizes from 39M to 1.3B parameters, with detailed benchmark results and scaling trends discussed.
💬 Research Conclusions:
– SONAR-LLM achieves competitive text generation quality compared to existing models, and all training code and pretrained checkpoints are made available to support reproducibility and future research.
👉 Paper link: https://huggingface.co/papers/2508.05305

9. MolmoAct: Action Reasoning Models that can Reason in Space
🔑 Keywords: Action Reasoning Models, AI Native, Explainable Robotic Behavior, MolmoAct, Mid-Level Spatial Plans
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce Action Reasoning Models (ARMs) that integrate perception, planning, and control for adaptable and explainable robotic behavior.
🛠️ Research Methods:
– Implement a structured three-stage pipeline model termed MolmoAct that encodes observations into depth-aware perception tokens and generates editable trajectory traces.
💬 Research Conclusions:
– MolmoAct achieves high performance across simulations and real-world tasks, significantly surpassing existing models in generalization and adaptability.
– The release of the MolmoAct Dataset enhances model performance with a 5.5% average improvement.
👉 Paper link: https://huggingface.co/papers/2508.07917

10. OmniEAR: Benchmarking Agent Reasoning in Embodied Tasks
🔑 Keywords: OmniEAR, Embodied Reasoning, Multi-agent Coordination, Tool Usage, Embodied AI Systems
💡 Category: Foundations of AI
🌟 Research Objective:
– To evaluate the reasoning capabilities of language models in physical interactions, tool usage, and multi-agent coordination using the OmniEAR framework.
🛠️ Research Methods:
– OmniEAR requires agents to dynamically acquire capabilities and autonomously determine coordination strategies based on task demands in a text-based environment representation across 1,500 scenarios in household and industrial domains.
💬 Research Conclusions:
– Language models underperform in reasoning from constraints, with severe performance drops in tool reasoning and implicit collaboration.
– Complete environmental information can degrade coordination performance, highlighting architectural limitations.
– Fine-tuning improves single-agent tasks significantly but offers minimal gains for multi-agent tasks, showcasing the need for advancements in embodied AI systems.
👉 Paper link: https://huggingface.co/papers/2508.05614

11. Grove MoE: Towards Efficient and Superior MoE LLMs with Adjugate Experts
🔑 Keywords: Grove MoE, large language models, heterogeneous experts, dynamic activation, computational efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Grove MoE architecture to improve computational efficiency and performance in large language models through dynamic parameter activation based on input complexity.
🛠️ Research Methods:
– Utilize heterogeneous experts of varying sizes inspired by the big.LITTLE CPU architecture and apply an upcycling strategy during mid-training and post-training.
💬 Research Conclusions:
– Grove MoE models activate parameters dynamically, achieving performance comparable to state-of-the-art open-source models while expanding model capacity with manageable computational overhead.
👉 Paper link: https://huggingface.co/papers/2508.07785

12. Temporal Self-Rewarding Language Models: Decoupling Chosen-Rejected via Past-Future
🔑 Keywords: Temporal Self-Rewarding Language Models, Preference Learning, Out-of-Distribution Generalization, Large Language Models(LLMs), Direct Preference Optimization
💡 Category: Generative Models
🌟 Research Objective:
– To improve generative capabilities by strategically using past and future outputs to enhance preference learning and generalization in Self-Rewarding Language Models.
🛠️ Research Methods:
– Introduced a dual-phase framework: (1) Anchored Rejection, (2) Future-Guided Chosen, applied across different model families and sizes such as Llama, Qwen, and Mistral.
💬 Research Conclusions:
– The proposed Temporal Self-Rewarding model yields significant improvements, demonstrating a 29.44 win rate on AlpacaEval 2.0, outperforming the baseline. It also shows superior out-of-distribution generalization in tasks like mathematical reasoning, QA, and code generation.
👉 Paper link: https://huggingface.co/papers/2508.06026

13. Reinforcement Learning in Vision: A Survey
🔑 Keywords: Visual Reinforcement Learning, Policy Optimization, Multi-Modal Large Language Models, Unified Model Frameworks, Visual Generation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The primary goal is to provide a comprehensive synthesis of recent advancements in visual reinforcement learning, emphasizing policy optimization strategies and evaluating protocols, while identifying future challenges and promising research directions.
🛠️ Research Methods:
– The paper formalizes visual reinforcement learning problems, examines various policy optimization strategies, and organizes over 200 studies into four thematic pillars, which include multi-modal large language models, visual generation, unified model frameworks, and vision-language-action models. Key methods involve reviewing algorithmic designs, reward engineering, and various evaluation protocols.
💬 Research Conclusions:
– The survey identifies significant trends such as curriculum-driven training and preference-aligned diffusion, highlighting open challenges like sample efficiency, generalization, and safe deployment. It provides researchers with a coherent map of the landscape and suggestions for future research directions.
👉 Paper link: https://huggingface.co/papers/2508.08189

14. Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning
🔑 Keywords: Reinforcement Learning, LLM reasoning, RL techniques, critic-free policies, vanilla PPO loss
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To systematically review reinforcement learning techniques for large language model reasoning and establish clear guidelines to improve their performance.
🛠️ Research Methods:
– Conducted rigorous reproductions and isolated evaluations of commonly used RL techniques within a unified open-source framework, analyzing internal mechanisms, applicable scenarios, and core principles through fine-grained experiments.
💬 Research Conclusions:
– A minimalist combination of two RL techniques can enhance the learning capabilities of critic-free policies using vanilla PPO loss, showing improved performance over existing methods like GRPO and DAPO.
👉 Paper link: https://huggingface.co/papers/2508.08221

15. Less Is More: Training-Free Sparse Attention with Global Locality for Efficient Reasoning
🔑 Keywords: Sparse attention, LessIsMore, Global attention patterns, Decoding speed-up
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce LessIsMore, a training-free sparse attention mechanism, to improve efficiency and generalization in reasoning tasks.
🛠️ Research Methods:
– Utilize global attention patterns and aggregate token selections from local attention heads for unified cross-head token ranking.
💬 Research Conclusions:
– LessIsMore maintains or improves accuracy while reducing the number of tokens attended to by half, achieving a notable speed-up in decoding and end-to-end processing compared to existing methods.
👉 Paper link: https://huggingface.co/papers/2508.07101

16. Follow-Your-Shape: Shape-Aware Image Editing via Trajectory-Guided Region Control
🔑 Keywords: Follow-Your-Shape, Trajectory Divergence Map, Scheduled KV Injection, shape editing, visual fidelity
💡 Category: Generative Models
🌟 Research Objective:
– To develop the Follow-Your-Shape framework for precise and controllable shape editing in images while preserving non-target content.
🛠️ Research Methods:
– Computing a Trajectory Divergence Map by comparing token-wise velocity differences to enable precise localization of editable regions.
– Introducing a Scheduled KV Injection mechanism to ensure stable and faithful editing.
– Creating ReShapeBench, a benchmark for evaluating the framework.
💬 Research Conclusions:
– The Follow-Your-Shape framework exhibits superior editability and visual fidelity, especially in large-scale shape replacement tasks.
👉 Paper link: https://huggingface.co/papers/2508.08134

17. MoBE: Mixture-of-Basis-Experts for Compressing MoE-based LLMs
🔑 Keywords: Mixture-of-Experts, MoBE, Model Compression, Basis Matrices, Accuracy Drops
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce the Mixture-of-Basis-Experts (MoBE) method to compress large language models with minimal accuracy loss.
🛠️ Research Methods:
– Decompose each up/gate matrix in an expert using rank decomposition, and re-parameterize matrix B as a linear combination of basis matrices shared across all experts within a given MoE layer. The factorization minimizes reconstruction error relative to the original weight matrices.
💬 Research Conclusions:
– MoBE achieves significantly lower accuracy drops compared to previous methods, reducing parameter counts by 24%-30% with only a 1%-2% accuracy decline.
👉 Paper link: https://huggingface.co/papers/2508.05257

18. Compressing Chain-of-Thought in LLMs via Step Entropy
🔑 Keywords: Chain-of-Thought, redundancy, step entropy, inference efficiency, reinforcement learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance LLM inference efficiency using a novel CoT compression framework without significantly reducing accuracy.
🛠️ Research Methods:
– Introduced a CoT compression framework based on step entropy to identify redundant steps.
– Employed a two-stage training strategy combining Supervised Fine-Tuning (SFT) and Group Relative Policy Optimization (GRPO) reinforcement learning.
💬 Research Conclusions:
– Pruning 80% of low-entropy intermediate steps results in minor degradation of accuracy across models including DeepSeek-R1-7B and Qwen3-8B.
– The framework significantly improves inference efficiency while maintaining reasoning performance, with implications for practical LLM deployment and understanding reasoning structures.
👉 Paper link: https://huggingface.co/papers/2508.03346

19. Shortcut Learning in Generalist Robot Policies: The Role of Dataset Diversity and Fragmentation
🔑 Keywords: Generalist robot policies, Shortcut learning, Dataset fragmentation, Robotic data augmentation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study investigates the limited generalization capability of generalist robot policies trained on large-scale datasets and identifies shortcut learning as a key issue.
🛠️ Research Methods:
– Conducted theoretical and empirical analysis to explore contributors to shortcut learning, specifically focusing on limited diversity and distributional disparities across sub-datasets.
💬 Research Conclusions:
– The research identifies dataset collection and robotic data augmentation strategies as solutions to reduce shortcut learning, improving generalization in both simulated and real-world environments.
👉 Paper link: https://huggingface.co/papers/2508.06426
20. VisR-Bench: An Empirical Study on Visual Retrieval-Augmented Generation for Multilingual Long Document Understanding
🔑 Keywords: Multilingual Benchmark, Multimodal Retrieval, Long Documents, MLLMs, Structured Tables
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to introduce VisR-Bench, a multilingual benchmark for evaluating question-driven multimodal retrieval in long documents across sixteen languages and three question types.
🛠️ Research Methods:
– Various models were evaluated, including text-based methods, multimodal encoders, and MLLMs, focusing on their effectiveness in diverse linguistic contexts and question types.
💬 Research Conclusions:
– MLLMs perform better than text-based and multimodal encoder models but face challenges with structured tables and low-resource languages, indicating areas for improvement in multilingual visual retrieval.
👉 Paper link: https://huggingface.co/papers/2508.07493

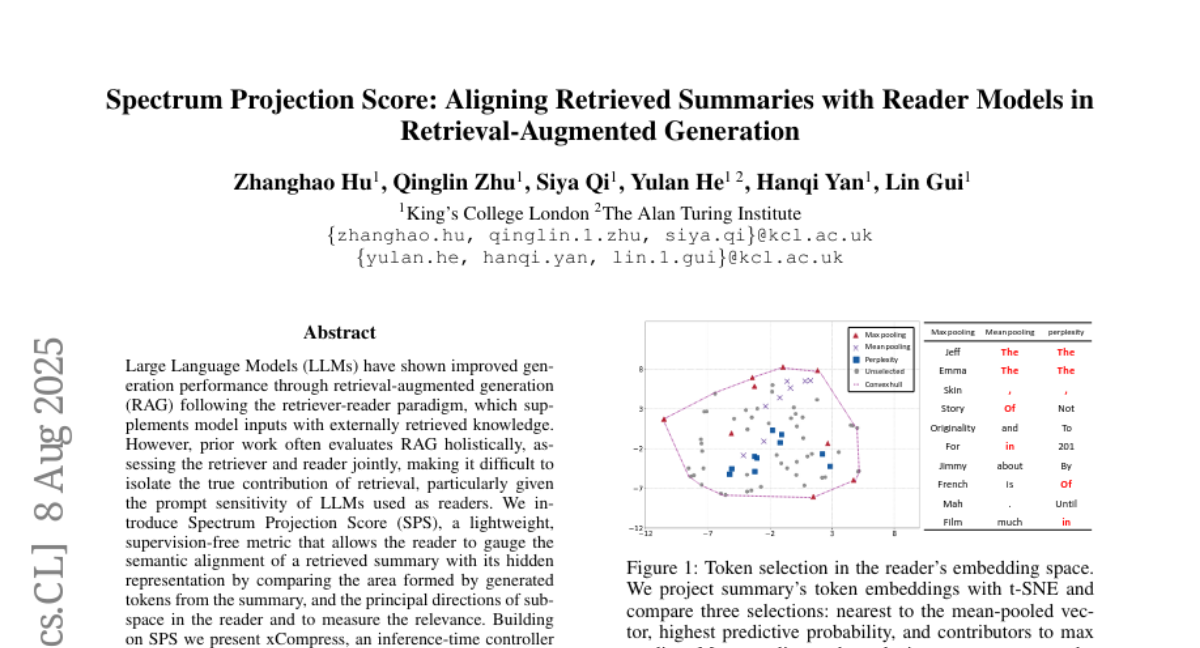
21. Spectrum Projection Score: Aligning Retrieved Summaries with Reader Models in Retrieval-Augmented Generation
🔑 Keywords: Large Language Models, retrieval-augmented generation, Spectrum Projection Score, xCompress
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to develop a new metric, Spectrum Projection Score (SPS), to assess the semantic alignment of retrieved content with language model representations without supervision.
🛠️ Research Methods:
– Introduction of the Spectrum Projection Score (SPS) and development of xCompress, an inference time controller framework that samples, ranks, and compresses retrieval summaries dynamically.
💬 Research Conclusions:
– The experiments demonstrated that SPS enhances performance across various tasks, offering insights into retrieval and generation interactions.
👉 Paper link: https://huggingface.co/papers/2508.05909
22. Bifrost-1: Bridging Multimodal LLMs and Diffusion Models with Patch-level CLIP Latents
🔑 Keywords: multimodal LLMs, diffusion models, patch-level CLIP embeddings, AI Native
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to integrate pretrained multimodal LLMs with diffusion models to enhance high-fidelity image generation without compromising multimodal reasoning capabilities.
🛠️ Research Methods:
– Utilizes patch-level CLIP embeddings as latent variables to bridge the gap between multimodal LLMs and diffusion models, alongside lightweight adaptations of ControlNet.
💬 Research Conclusions:
– Bifrost-1 achieves comparable or better performance in visual fidelity and multimodal understanding with significantly reduced training compute compared to previous methods. Comprehensive ablation studies support the effectiveness of its design.
👉 Paper link: https://huggingface.co/papers/2508.05954

23. Deep Ignorance: Filtering Pretraining Data Builds Tamper-Resistant Safeguards into Open-Weight LLMs
🔑 Keywords: Open-weight AI systems, data filtering, adversarial fine-tuning, pretraining, defense-in-depth
💡 Category: Machine Learning
🌟 Research Objective:
– To explore the efficacy of filtering text about dual-use topics from training data as a defense mechanism against adversarial fine-tuning attacks in open-weight AI systems.
🛠️ Research Methods:
– Introduced a multi-stage pipeline for scalable data filtering to mitigate biothreat proxy knowledge in large language models (LLMs) and pretrained multiple 6.9B-parameter models.
💬 Research Conclusions:
– Data filtering during pretraining significantly enhances resistance to adversarial fine-tuning attacks by outperforming existing post-training baselines and maintaining unrelated capabilities. Although models lack dangerous internalized knowledge, they can utilize such information when contextually provided, indicating the necessity for a defense-in-depth strategy.
👉 Paper link: https://huggingface.co/papers/2508.06601

24. GLiClass: Generalist Lightweight Model for Sequence Classification Tasks
🔑 Keywords: GLiClass, sequence classification, zero-shot learning, few-shot learning, PPO
💡 Category: Natural Language Processing
🌟 Research Objective:
– To achieve efficient and accurate sequence classification with zero-shot and few-shot capabilities using GLiClass.
🛠️ Research Methods:
– Adaptation of the GLiNER architecture for sequence classification with modifications to accommodate zero-shot and few-shot learning.
– Application of proximal policy optimization (PPO) for multi-label text classification in data-sparse conditions.
💬 Research Conclusions:
– GLiClass demonstrates high accuracy and efficiency comparable to embedding-based methods.
– Offers flexibility for dynamic classification requirements and adapts well to zero-shot and few-shot scenarios.
– Demonstrates enhanced performance in training classifiers with limited data availability or from human feedback.
👉 Paper link: https://huggingface.co/papers/2508.07662

25. Speech-to-LaTeX: New Models and Datasets for Converting Spoken Equations and Sentences
🔑 Keywords: LaTeX, Audio language models, Automatic speech recognition, Mathematical content recognition, AI in Education
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve the accuracy of converting spoken mathematical expressions into LaTeX, accommodating multiple languages and sentence structures.
🛠️ Research Methods:
– Presentation of a large-scale open-source dataset with over 66,000 annotated audio samples in English and Russian.
– Application of audio language models and ASR post-correction methods.
💬 Research Conclusions:
– Significant improvement over existing benchmarks, achieving competitive character error rates and surpassing previous models by over 40 percentage points on a new benchmark.
– Establishment of the first benchmark for mathematical sentence recognition, emphasizing the task’s potential in educational and research domains.
👉 Paper link: https://huggingface.co/papers/2508.03542

26. Fact2Fiction: Targeted Poisoning Attack to Agentic Fact-checking System
🔑 Keywords: Fact2Fiction, fact-checking systems, LLM-based agents, security weaknesses, defensive countermeasures
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Fact2Fiction, a poisoning attack framework targeting agentic fact-checking systems to exploit and compromise sub-claim verification.
🛠️ Research Methods:
– Utilize Fact2Fiction to mirror decomposition strategies and utilize system-generated justifications to create malicious evidence in fact-checking systems.
💬 Research Conclusions:
– Extensive experiments reveal Fact2Fiction achieves 8.9%–21.2% higher attack success rates than current methods, underscoring the urgent need for defensive countermeasures to address security weaknesses in fact-checking systems.
👉 Paper link: https://huggingface.co/papers/2508.06059

27. When Good Sounds Go Adversarial: Jailbreaking Audio-Language Models with Benign Inputs
🔑 Keywords: WhisperInject, Reinforcement Learning, Projected Gradient Descent, Audio-Native Threats, Human-AI Interaction
💡 Category: Human-AI Interaction
🌟 Research Objective:
– Introduce an adversarial audio attack framework called WhisperInject to exploit vulnerabilities in audio language models by generating harmful content through imperceptible perturbations.
🛠️ Research Methods:
– Utilizes Reinforcement Learning with Projected Gradient Descent (RL-PGD) and Projected Gradient Descent (PGD) in a two-stage process to manipulate state-of-the-art audio language models and inject payloads into benign audio carriers.
💬 Research Conclusions:
– Demonstrates a high success rate of over 86% in manipulating models such as Qwen2.5-Omni-3B and Phi-4-Multimodal, highlighting a practical and covert method to exploit AI behavior.
👉 Paper link: https://huggingface.co/papers/2508.03365

28. TextQuests: How Good are LLMs at Text-Based Video Games?
🔑 Keywords: TextQuests, intrinsic reasoning, interactive fiction, LLM agent, long-context reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to evaluate AI agents’ intrinsic reasoning and problem-solving capabilities in long, exploratory, text-based interactive fiction environments without external tools.
🛠️ Research Methods:
– Introduction of TextQuests, a benchmark based on the Infocom suite of interactive fiction games, specifically designed to assess an LLM agent’s capacity for self-contained problem-solving through intrinsic reasoning.
💬 Research Conclusions:
– TextQuests serves as an effective proxy for evaluating AI agents on focused, stateful tasks, highlighting their ability for sustained problem-solving and trial-and-error learning within a single interactive session.
👉 Paper link: https://huggingface.co/papers/2507.23701

29. Anatomy of a Machine Learning Ecosystem: 2 Million Models on Hugging Face
🔑 Keywords: Model Family Trees, Fine-Tuning, Model Cards, Licenses
💡 Category: Machine Learning
🌟 Research Objective:
– To examine patterns in model fine-tuning, focusing on model family resemblance, license changes, and model card standardization using an analysis of 1.86 million models on Hugging Face.
🛠️ Research Methods:
– Utilized an evolutionary biology approach to study ML models, analyzing model metadata and model cards to measure genetic similarity and mutation across model families.
💬 Research Conclusions:
– Discoveries showed a family resemblance in models, where sibling models show more genetic similarity than parent-child pairs; licenses tend to drift from restrictive to permissive, often violating upstream terms; models evolve towards English-only compatibility; and model cards become shorter and more standardized.
👉 Paper link: https://huggingface.co/papers/2508.06811
