AI Native Daily Paper Digest – 20250815

1. We-Math 2.0: A Versatile MathBook System for Incentivizing Visual Mathematical Reasoning
🔑 Keywords: MLLMs, mathematical reasoning, reinforcement learning, knowledge system, AI-generated summary
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance the mathematical reasoning capabilities of Multimodal Large Language Models (MLLMs) using a structured knowledge system and model-centric data space modeling.
🛠️ Research Methods:
– Development of a hierarchical MathBook Knowledge System with 491 knowledge points and 1,819 principles.
– Creation of the MathBook-Standard and MathBook-Pro datasets for robust training across varying difficulty levels.
– Implementation of a two-stage reinforcement learning framework for model fine-tuning and alignment.
💬 Research Conclusions:
– We-Math 2.0 demonstrates competitive performance on various benchmarks, showing promising generalization in mathematical reasoning.
👉 Paper link: https://huggingface.co/papers/2508.10433

2. NextStep-1: Toward Autoregressive Image Generation with Continuous Tokens at Scale
🔑 Keywords: NextStep-1, autoregressive model, text-to-image generation, image editing, high-fidelity image synthesis
💡 Category: Generative Models
🌟 Research Objective:
– To advance the autoregressive paradigm for text-to-image generation and image editing with the NextStep-1 model.
🛠️ Research Methods:
– Utilized a 14B autoregressive model paired with a 157M flow matching head to process discrete text tokens and continuous image tokens.
💬 Research Conclusions:
– NextStep-1 achieves state-of-the-art performance in text-to-image generation and exhibits strong capabilities in image editing, emphasizing its power and versatility.
👉 Paper link: https://huggingface.co/papers/2508.10711

3. ToonComposer: Streamlining Cartoon Production with Generative Post-Keyframing
🔑 Keywords: ToonComposer, AI-assisted cartoon production, inbetweening, colorization, generative model
💡 Category: Generative Models
🌟 Research Objective:
– To introduce ToonComposer, a generative model that unifies inbetweening and colorization in cartoon production to enhance visual quality and efficiency.
🛠️ Research Methods:
– ToonComposer leverages sparse sketch injection and cartoon adaptation methods, utilizing a spatial low-rank adapter to adapt a modern video foundation model to cartoons while maintaining temporal consistency.
💬 Research Conclusions:
– ToonComposer significantly outperforms existing methods in visual quality, motion consistency, and production efficiency, providing a superior and flexible solution for AI-assisted cartoon production.
👉 Paper link: https://huggingface.co/papers/2508.10881

4. PRELUDE: A Benchmark Designed to Require Global Comprehension and Reasoning over Long Contexts
🔑 Keywords: PRELUDE, long-context understanding, reasoning accuracy, in-context learning, state-of-the-art LLMs
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce a benchmark named PRELUDE to evaluate the consistency of prequels with original book narratives, demanding global comprehension and deep reasoning.
🛠️ Research Methods:
– Assessment of the ability of models to integrate multi-part narrative information, utilizing in-context learning, RAG, and in-domain training with state-of-the-art LLMs.
💬 Research Conclusions:
– Empirical evidence shows models are >15% less consistent than humans, with a significant 30% gap in reasoning accuracy.
– Highlights the substantial need for improvement in both long-context understanding and reasoning capabilities of AI models.
👉 Paper link: https://huggingface.co/papers/2508.09848

5. UI-Venus Technical Report: Building High-performance UI Agents with RFT
🔑 Keywords: UI-Venus, Multimodal Large Language Model, Reinforcement Finetune, Self-Evolving Framework
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to develop UI-Venus, a UI agent leveraging a multimodal large language model to achieve state-of-the-art performance in UI grounding and navigation tasks.
🛠️ Research Methods:
– The study employs reinforcement fine-tuning, specifically using Qwen2.5-VL. It also introduces carefully designed reward functions and data cleaning strategies. Furthermore, techniques such as Self-Evolving Trajectory History Alignment & Sparse Action Enhancement are proposed to improve navigation performance.
💬 Research Conclusions:
– The UI-Venus model, through its 7B and 72B variants, outperforms previous state-of-the-art models in benchmarks such as Screenspot-V2 and AndroidWorld. It provides a significant improvement in planning and generalization in complex UI tasks, thus encouraging further research in the field.
👉 Paper link: https://huggingface.co/papers/2508.10833

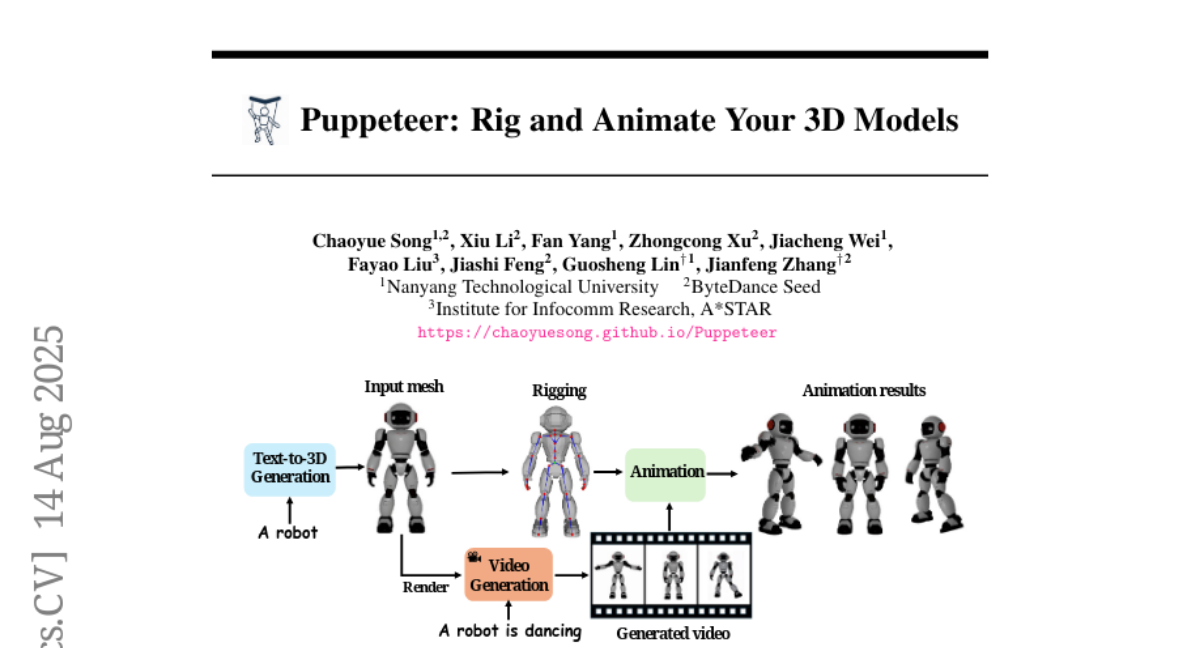
6. Puppeteer: Rig and Animate Your 3D Models
🔑 Keywords: Auto-regressive transformer, Attention-based architecture, Differentiable optimization, Skeletal prediction accuracy, AI-generated
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To automate the rigging and animation of 3D models, making the process more efficient and accurate than current methods.
🛠️ Research Methods:
– Utilizes an auto-regressive transformer with a joint-based tokenization strategy and hierarchical ordering for skeletal structure prediction.
– Employs an attention-based architecture to infer skinning weights by encoding inter-joint relationships through topology-aware joint attention.
– Integrates differentiable optimization for generating stable and high-fidelity animations efficiently.
💬 Research Conclusions:
– Puppeteer framework significantly surpasses existing methods in skeletal prediction accuracy and skinning quality.
– Produces temporally coherent animations, effectively resolving the jittering issues common in current techniques, applicable to various 3D content.
👉 Paper link: https://huggingface.co/papers/2508.10898
7. STream3R: Scalable Sequential 3D Reconstruction with Causal Transformer
🔑 Keywords: 3D reconstruction, Transformer, causal attention, geometric priors, LLM-style training
💡 Category: Computer Vision
🌟 Research Objective:
– The primary objective is to reformulate 3D reconstruction using a decoder-only Transformer framework to improve efficiency and effectiveness in both static and dynamic scenes.
🛠️ Research Methods:
– The approach leverages causal attention to efficiently process image sequences, avoiding expensive global optimization and simplistic memory mechanisms used by current methods.
– It learns geometric priors from large-scale 3D datasets to handle diverse scenarios.
💬 Research Conclusions:
– STream3R consistently outperforms existing methods in 3D scene reconstruction, including dynamic scenes, showing strong generalization capabilities.
– It is compatible with LLM-style training infrastructure, enabling efficient pretraining and fine-tuning for various applications in 3D tasks, promoting real-time 3D understanding in streaming environments.
👉 Paper link: https://huggingface.co/papers/2508.10893

8. Pass@k Training for Adaptively Balancing Exploration and Exploitation of Large Reasoning Models
🔑 Keywords: Reinforcement Learning, Verifiable Rewards, Pass@k, Exploration, Exploitation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To investigate the use of Pass@k as a reward metric in reinforcement learning with verifiable rewards and its impact on exploration abilities.
🛠️ Research Methods:
– Trained a policy model using Pass@k as the reward metric to analyze improvements in exploration capabilities.
– Derived an analytical solution to showcase the advantages of Pass@k Training in the learning process.
💬 Research Conclusions:
– Exploration and exploitation can mutually enhance each other rather than being conflicting objectives.
– Pass@k Training contributes to an efficient learning process by effectively designing the advantage function.
– Highlights potential future directions in advantage design for reinforcement learning with verifiable rewards.
👉 Paper link: https://huggingface.co/papers/2508.10751

9. HumanSense: From Multimodal Perception to Empathetic Context-Aware Responses through Reasoning MLLMs
🔑 Keywords: HumanSense, Multimodal Large Language Models, human-centered perception, reinforcement learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce HumanSense, a comprehensive benchmark for evaluating human-centered perception and interaction in Multimodal Large Language Models (MLLMs).
🛠️ Research Methods:
– Employing a multi-stage, modality-progressive reinforcement learning approach to enhance the reasoning abilities of Omni-modal models.
💬 Research Conclusions:
– Leading MLLMs have room for improvement, particularly in advanced interaction-oriented tasks.
– Supplementing visual input with audio and text information significantly enhances performance.
– Successful reasoning processes are linked to consistent thought patterns, with developed prompts enhancing non-reasoning models without additional training.
👉 Paper link: https://huggingface.co/papers/2508.10576

10. A Survey on Diffusion Language Models
🔑 Keywords: Diffusion Language Models, autoregressive, inference latency, bidirectional context, multimodal extensions
💡 Category: Natural Language Processing
🌟 Research Objective:
– To provide a comprehensive overview of the current state of Diffusion Language Models (DLMs) in contrast to autoregressive models in various NLP tasks.
🛠️ Research Methods:
– Surveying foundational principles, state-of-the-art models, and advanced techniques, including pre-training and post-training methods.
– Reviewing DLM inference strategies and optimizations for decoding parallelism, caching mechanisms, and generation quality.
💬 Research Conclusions:
– DLMs offer reduced inference latency and are effective at capturing bidirectional context, demonstrating potential comparable to autoregressive models across NLP tasks.
– Identification of challenges and future directions for DLMs, particularly in efficiency, handling long sequences, and infrastructure requirements.
– Consideration of multimodal extensions and their practical applications.
👉 Paper link: https://huggingface.co/papers/2508.10875

11. Processing and acquisition traces in visual encoders: What does CLIP know about your camera?
🔑 Keywords: Visual Encoders, Image Acquisition, Semantic Predictions, Distribution Shift
💡 Category: Computer Vision
🌟 Research Objective:
– To analyze the impact of subtle and often imperceptible image acquisition parameters on the robustness of visual encoders and their effect on semantic predictions.
🛠️ Research Methods:
– Evaluating the systematic encoding of image acquisition parameters in learned visual representations and assessing their correlation or anti-correlation with semantic labels.
💬 Research Conclusions:
– Image acquisition parameters, whether subtle or imperceptible, are encoded in visual representations and significantly influence semantic predictions, depending on their correlation with semantic labels.
👉 Paper link: https://huggingface.co/papers/2508.10637

12. From Black Box to Transparency: Enhancing Automated Interpreting Assessment with Explainable AI in College Classrooms
🔑 Keywords: Automated interpreting quality assessment, Feature engineering, Explainable machine learning, Shapley Value (SHAP), BLEURT
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to enhance the quality of automated interpreting assessment by integrating feature engineering, data augmentation, and explainable machine learning, focusing on transparency and detailed diagnostic feedback.
🛠️ Research Methods:
– A multi-dimensional modeling framework is proposed, employing feature engineering, data augmentation, and Shapley Value (SHAP) analysis to prioritize explainability over “black box” predictions.
💬 Research Conclusions:
– The proposed framework demonstrates strong predictive performance on a novel English-Chinese consecutive interpreting dataset, showing the effectiveness of BLEURT and CometKiwi scores for assessing fidelity, pause-related features for fluency, and Chinese-specific phraseological diversity metrics for language use. It provides a reliable and transparent alternative to traditional human evaluation.
👉 Paper link: https://huggingface.co/papers/2508.10860

13. When Explainability Meets Privacy: An Investigation at the Intersection of Post-hoc Explainability and Differential Privacy in the Context of Natural
Language Processing
🔑 Keywords: Differential Privacy, Post-hoc Explainability, NLP, Privacy, Explainability
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the relationship and trade-off between privacy and explainability in NLP using Differential Privacy and Post-hoc Explainability methods.
🛠️ Research Methods:
– Empirical investigation into the privacy-explainability trade-off, considering downstream tasks and choices of text privatization and explainability methods.
💬 Research Conclusions:
– Identified the potential for privacy and explainability to co-exist and provided practical recommendations for future work at this intersection.
👉 Paper link: https://huggingface.co/papers/2508.10482

14.
