AI Native Daily Paper Digest – 20250908
1. Why Language Models Hallucinate
🔑 Keywords: Language Models, Hallucinations, Benchmark Scoring, Uncertainty, Trustworthy AI Systems
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to address the issue of incorrect statements produced by language models due to training and evaluation practices that favor guessing over uncertainty acknowledgment.
🛠️ Research Methods:
– Analyzing statistical causes and the impact of existing training pipelines on hallucinations, and proposing socio-technical changes in the benchmark scoring to mitigate these issues.
💬 Research Conclusions:
– The study concludes that hallucinations in language models are primarily caused by evaluation procedures rewarding guessing. To improve trust in AI systems, it suggests modifying current benchmarks to better handle uncertainty.
👉 Paper link: https://huggingface.co/papers/2509.04664

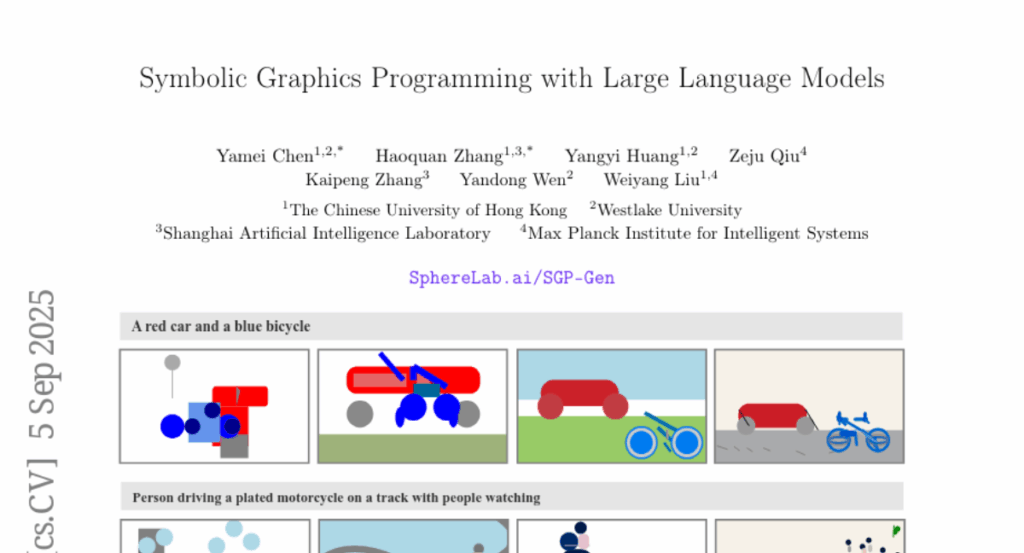
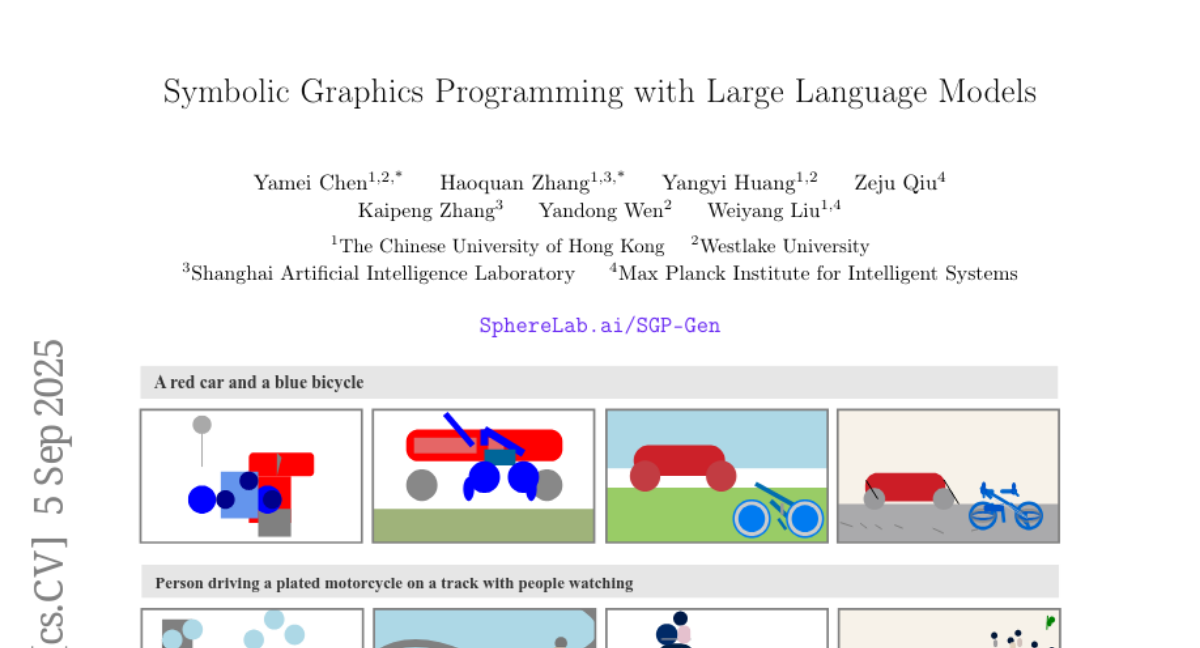
2. Symbolic Graphics Programming with Large Language Models
🔑 Keywords: Large Language Models, Symbolic Graphics Programs, Reinforcement Learning, Scalable Vector Graphics
💡 Category: Generative Models
🌟 Research Objective:
– The study investigates symbolic graphics programming by generating symbolic graphics programs (SGPs) from natural-language descriptions, focusing on producing scalable vector graphics (SVGs).
🛠️ Research Methods:
– The research introduces SGP-GenBench, a benchmark covering several aspects of object and scene fidelity in SGP generation. It employs a reinforcement learning approach with verifiable rewards and cross-modal alignment techniques using strong vision encoders for SVG generation.
💬 Research Conclusions:
– The proposed method significantly improves the quality and semantics of SVG generation, achieving performance comparable to frontier proprietary models. The study highlights the role of symbolic graphics programming as an interpretable means for cross-modal grounding in language models.
👉 Paper link: https://huggingface.co/papers/2509.05208
3. Set Block Decoding is a Language Model Inference Accelerator
🔑 Keywords: Set Block Decoding, Autoregressive Next Token Prediction, Masked Token Prediction, Discrete Diffusion, Llama-3.1 8B
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce Set Block Decoding (SBD) to accelerate language model generation by integrating next token prediction and masked token prediction, improving efficiency in token sampling and reducing computational costs.
🛠️ Research Methods:
– The study implements SBD by fine-tuning existing language models, such as Llama-3.1 8B and Qwen-3 8B, to parallelize token sampling and leverage solvers from discrete diffusion literature without architectural changes.
💬 Research Conclusions:
– SBD significantly reduces the number of forward passes required during generation by 3-5 times, achieving the same performance levels as standard next token prediction models.
👉 Paper link: https://huggingface.co/papers/2509.04185
4. WildScore: Benchmarking MLLMs in-the-Wild Symbolic Music Reasoning
🔑 Keywords: Multimodal Large Language Models, WildScore, symbolic music reasoning, musicological queries, visual-symbolic reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces WildScore, a benchmark for evaluating MLLMs’ abilities to interpret real-world music scores and address complex musicological queries.
🛠️ Research Methods:
– Systematic taxonomy and multiple-choice question answering are used to assess MLLMs’ symbolic music understanding in a controlled and scalable manner.
💬 Research Conclusions:
– Benchmarking reveals both the strengths and ongoing challenges in MLLMs’ visual-symbolic reasoning, suggesting promising areas for further development.
👉 Paper link: https://huggingface.co/papers/2509.04744

5. LuxDiT: Lighting Estimation with Video Diffusion Transformer
🔑 Keywords: HDR environment maps, video diffusion transformer, indirect visual cues, low-rank adaptation, synthetic dataset
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to generate accurate HDR environment maps from visual input, which is a complex problem in computer vision and graphics due to the lack of diverse and accessible ground-truth data.
🛠️ Research Methods:
– Introduction of LuxDiT, a novel approach using a video diffusion transformer fine-tuned with low-rank adaptation on a synthetic dataset featuring diverse lighting conditions.
💬 Research Conclusions:
– LuxDiT outperforms existing methods in generating realistic and accurate lighting predictions, effectively generalizing from synthetic datasets to real-world scenes and providing superior results in both quantitative and qualitative evaluations.
👉 Paper link: https://huggingface.co/papers/2509.03680
6. LatticeWorld: A Multimodal Large Language Model-Empowered Framework for Interactive Complex World Generation
🔑 Keywords: LatticeWorld, Lightweight LLMs, Unreal Engine 5, Multi-Agent Interaction, Real-Time Rendering
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective of LatticeWorld is to create a 3D world generation framework that uses lightweight LLMs and Unreal Engine 5 to produce dynamic, interactive environments based on textual and visual inputs.
🛠️ Research Methods:
– The framework leverages lightweight LLMs and an industry-grade rendering engine to generate environments. Multimodal inputs, including textual descriptions and visual instructions, are used to create large-scale interactive worlds with dynamic agents.
💬 Research Conclusions:
– LatticeWorld demonstrates superior accuracy in scene layout generation and visual fidelity while achieving over 90 times increase in industrial production efficiency compared to traditional methods, maintaining high creative quality.
👉 Paper link: https://huggingface.co/papers/2509.05263

7. MedVista3D: Vision-Language Modeling for Reducing Diagnostic Errors in 3D CT Disease Detection, Understanding and Reporting
🔑 Keywords: MedVista3D, vision-language pretraining, 3D CT analysis, local-global understanding, medical visual question answering
💡 Category: AI in Healthcare
🌟 Research Objective:
– MedVista3D aims to address the challenges in 3D CT analysis by improving local-global understanding in disease classification, report retrieval, and medical visual question answering.
🛠️ Research Methods:
– Introduces a multi-scale semantic-enriched framework that aligns local and global image-text data to enhance representation learning. Utilizes language model rewrites and a Radiology Semantic Matching Bank for semantically consistent reporting.
💬 Research Conclusions:
– MedVista3D achieves state-of-the-art performance in zero-shot disease classification, report retrieval, and visual question answering, and further demonstrates transferability in organ segmentation and prognosis prediction.
👉 Paper link: https://huggingface.co/papers/2509.03800

8. WinT3R: Window-Based Streaming Reconstruction with Camera Token Pool
🔑 Keywords: WinT3R, feed-forward reconstruction model, camera pose estimation, sliding window mechanism, global camera token pool
💡 Category: Computer Vision
🌟 Research Objective:
– The paper introduces WinT3R, a model designed to provide high-quality camera pose estimation and real-time performance.
🛠️ Research Methods:
– Utilizes a sliding window mechanism for optimal information exchange among frames.
– Implements a compact representation of cameras with a global camera token pool to enhance reliability without losing efficiency.
💬 Research Conclusions:
– WinT3R achieves state-of-the-art performance in online reconstruction quality, camera pose estimation, and reconstruction speed, as demonstrated by extensive experiments on varied datasets.
👉 Paper link: https://huggingface.co/papers/2509.05296
9. Behavioral Fingerprinting of Large Language Models
🔑 Keywords: Behavioral Fingerprinting, Diagnostic Prompt Suite, automated evaluation pipeline, sycophancy, semantic robustness
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce the Behavioral Fingerprinting framework to evaluate Large Language Models beyond traditional performance metrics by focusing on intrinsic cognitive and interactive styles.
🛠️ Research Methods:
– Utilize a curated Diagnostic Prompt Suite and an innovative, automated evaluation pipeline to analyze eighteen LLMs across capability tiers with a focus on alignment-related behaviors.
💬 Research Conclusions:
– Identify critical divergences in LLM alignment behaviors, with core reasoning capabilities converging but behaviors like sycophancy and semantic robustness varying widely, reflecting variable developer alignment strategies.
👉 Paper link: https://huggingface.co/papers/2509.04504

10. On Robustness and Reliability of Benchmark-Based Evaluation of LLMs
🔑 Keywords: Large Language Models, linguistic variability, generalization abilities, robustness-aware benchmarks
💡 Category: Natural Language Processing
🌟 Research Objective:
– To assess the robustness of Large Language Models (LLMs) to paraphrased benchmark questions and investigate the reliability of benchmark-based evaluations for model capabilities.
🛠️ Research Methods:
– Systematic generation of various paraphrases for questions across six different benchmarks to measure the variations in effectiveness of 34 different LLMs.
💬 Research Conclusions:
– While LLM rankings remain stable, their effectiveness declines significantly with linguistic variability, challenging their generalization abilities and the reliability of benchmark-based evaluations.
– The study highlights the need for robustness-aware benchmarks that better reflect practical deployment scenarios.
👉 Paper link: https://huggingface.co/papers/2509.04013

11. U-ARM : Ultra low-cost general teleoperation interface for robot manipulation
🔑 Keywords: Low-cost, Adaptable, AI-generated, Teleoperation, Robotics
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce U-Arm, a low-cost and adaptable teleoperation framework optimized for robotic arms.
🛠️ Research Methods:
– Utilize AI-generated optimizations in mechanical design and control logic, supporting teleoperation through 3D-printed leader arms.
💬 Research Conclusions:
– U-Arm achieves 39% higher data collection efficiency and comparable task success rates compared to Joycon, an existing low-cost teleoperation interface.
👉 Paper link: https://huggingface.co/papers/2509.02437

12. Bootstrapping Task Spaces for Self-Improvement
🔑 Keywords: Exploratory Iteration, auto-curriculum RL, LLMs, self-improvement, inference-time
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper introduces Exploratory Iteration (ExIt), a method to enable large language models (LLMs) to perform multi-step self-improvement at inference-time by sampling informative intermediate histories.
🛠️ Research Methods:
– ExIt utilizes an auto-curriculum approach to selectively sample and iterate on the most informative single-step iterations, creating new self-iteration task instances, which are supported by explicit exploration mechanisms.
💬 Research Conclusions:
– ExIt strategies effectively realize inference-time self-improvement across domains such as competition math, multi-turn tool-use, and machine learning engineering, facilitating policies with high performance beyond the average training iteration depth.
👉 Paper link: https://huggingface.co/papers/2509.04575

13.
