AI Native Daily Paper Digest – 20250909
1. Reverse-Engineered Reasoning for Open-Ended Generation
🔑 Keywords: REER, deep reasoning, reverse engineering, gradient-free, DeepWriting-20K
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce REverse-Engineered Reasoning (REER) as a new paradigm for deep reasoning, aiming to enhance performance on open-ended tasks.
🛠️ Research Methods:
– Utilize reverse engineering to work backwards from known-good solutions, utilizing a scalable, gradient-free approach to uncover step-by-step reasoning processes.
💬 Research Conclusions:
– Created and open-sourced DeepWriting-20K, a dataset that supports the training of models like DeepWriter-8B, which outperforms existing open-source baselines and rivals proprietary models like GPT-4o and Claude 3.5.
👉 Paper link: https://huggingface.co/papers/2509.06160

2. WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents
🔑 Keywords: AI Native, web browsing capabilities, model-based exploration, reinforcement learning, multi-step reasoning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To develop advanced web agents with state-of-the-art information-seeking capabilities using data-driven techniques and reinforcement learning.
🛠️ Research Methods:
– Utilization of systematic data generation with model-based exploration and iterative query evolution, followed by supervised fine-tuning and reinforcement learning to train WebExplorer-8B.
💬 Research Conclusions:
– WebExplorer-8B achieves superior performance on complex information-seeking tasks across diverse benchmarks, outperforming larger models, and demonstrates strong generalization despite limited training data.
👉 Paper link: https://huggingface.co/papers/2509.06501

3. Revolutionizing Reinforcement Learning Framework for Diffusion Large Language Models
🔑 Keywords: TraceRL, Diffusion Language Models, Reinforcement Learning, Curriculum Learning, Sampling Flexibility
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to enhance diffusion language models (DLMs) with trajectory-aware reinforcement learning to improve reasoning performance on complex tasks and enable flexible sampling.
🛠️ Research Methods:
– The research applies a trajectory-aware reinforcement learning framework called TraceRL, incorporating a diffusion-based value model for training stability, and uses curriculum learning to develop advanced models.
💬 Research Conclusions:
– TraceRL leads to state-of-the-art diffusion language models like TraDo, with TraDo-4B-Instruct outperforming larger AR models in math reasoning and TraDo-8B-Instruct achieving significant accuracy improvements. The study releases an open-source framework with accelerated techniques for reproducible research.
👉 Paper link: https://huggingface.co/papers/2509.06949

4. Does DINOv3 Set a New Medical Vision Standard?
🔑 Keywords: DINOv3, Vision Transformer, Medical Vision Tasks, Self-Supervised Learning, Scalability
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study investigates whether DINOv3, a self-supervised vision transformer, can be effectively used as a unified encoder for medical vision tasks without domain-specific pre-training.
🛠️ Research Methods:
– DINOv3 was benchmarked across a variety of common medical vision tasks, including 2D/3D classification and segmentation, while systematically analyzing its scalability through varying model sizes and input image resolutions.
💬 Research Conclusions:
– DINOv3 showed impressive performance, outperforming medical-specific models like BiomedCLIP and CT-Net in several tasks. However, its effectiveness decreased in heavily specialized domains and did not consistently follow scaling laws in the medical domain, indicating room for improvement.
👉 Paper link: https://huggingface.co/papers/2509.06467

5. Reinforced Visual Perception with Tools
🔑 Keywords: Visual reasoning, Reinforcement learning, Multi-modal LLMs, Visual tools, AI-generated summary
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Enhance the visual reasoning capabilities of multi-modal LLMs using reinforcement learning to achieve state-of-the-art performance on visual benchmarks.
🛠️ Research Methods:
– Introduced a novel RL algorithm based on GRPO to train models for reasoning with a suite of four visual tools through reinforcement learning.
– Conducted extensive experiments across several perception-heavy benchmarks.
💬 Research Conclusions:
– Achieved significant performance improvements on visual benchmarks like SAT, CV-Bench, BLINK, and MMStar, outperforming previous supervised and text-based RL finetuning methods.
– ReVPT-3B and ReVPT-7B models outperformed instruct models by 9.03% and 9.44% on CV-Bench.
– Provided new insights into RL-based visual tool usage.
👉 Paper link: https://huggingface.co/papers/2509.01656

6. Reinforcement Learning Foundations for Deep Research Systems: A Survey
🔑 Keywords: Reinforcement Learning, deep research systems, tool interaction, credit assignment, exploration
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To explore and establish Reinforcement Learning as a foundational approach for training deep research systems, addressing limitations in current supervised and preference alignment methods.
🛠️ Research Methods:
– The study systematizes work through data synthesis and curation, Reinforcement Learning methods focusing on stability, sample efficiency, long context handling, reward and credit design, multi-objective optimization, and multimodal integration.
💬 Research Conclusions:
– Reinforcement Learning reduces reliance on human-defined decision points and biases, aligning with closed-loop, tool-interaction research by optimizing trajectory-level policies and enabling exploration and recovery behaviors.
– The survey identifies infrastructure bottlenecks and offers practical guidance for training robust, transparent deep research agents.
👉 Paper link: https://huggingface.co/papers/2509.06733

7. UniVerse-1: Unified Audio-Video Generation via Stitching of Experts
🔑 Keywords: AI-generated summary, stitching of experts, audio-video generation, ambient sounds, Verse-Bench
💡 Category: Generative Models
🌟 Research Objective:
– The aim is to develop UniVerse-1, a unified model for synchronized audio and video generation, leveraging pre-trained models through the stitching of experts technique.
🛠️ Research Methods:
– Utilizes pre-trained video and music models without training from scratch, employing a stitching of experts approach to fuse these models, accompanied by an online annotation pipeline for precise temporal alignment.
💬 Research Conclusions:
– UniVerse-1, fine-tuned on 7,600 hours of data, achieves well-coordinated audio-visual outputs and robust speech alignment, offering a new benchmark dataset, Verse-Bench, to advance research in the field.
👉 Paper link: https://huggingface.co/papers/2509.06155

8. Focusing by Contrastive Attention: Enhancing VLMs’ Visual Reasoning
🔑 Keywords: Vision-Language Models, visual complexity, attention entropy, CARVE, Visual Enhancement
💡 Category: Computer Vision
🌟 Research Objective:
– To investigate attention patterns within Vision-Language Models (VLMs) and propose a method to enhance their performance in complex visual environments.
🛠️ Research Methods:
– A novel, training-free method called Contrastive Attention Refinement for Visual Enhancement (CARVE) is proposed to extract task-relevant visual signals through attention contrasting at the pixel level.
💬 Research Conclusions:
– CARVE significantly improves VLM performance, enhancing reasoning by up to 75% on open-source models, and offers insights into the impact of visual complexity and attention mechanisms on visual reasoning.
👉 Paper link: https://huggingface.co/papers/2509.06461

9. DivMerge: A divergence-based model merging method for multi-tasking
🔑 Keywords: Multi-task learning, Model merging, Task arithmetic, Jensen-Shannon divergence
💡 Category: Machine Learning
🌟 Research Objective:
– The objective is to merge models trained on different tasks into a single model that maintains strong performance across all tasks, addressing the challenge of task interference.
🛠️ Research Methods:
– The method involves leveraging Jensen-Shannon divergence to guide the merging process without needing additional labeled data and automatically balancing task importance.
💬 Research Conclusions:
– The proposed method is robust as the number of tasks increases and consistently outperforms previous approaches.
👉 Paper link: https://huggingface.co/papers/2509.02108

10. Paper2Agent: Reimagining Research Papers As Interactive and Reliable AI Agents
🔑 Keywords: Paper2Agent, AI agents, Natural Language, Knowledge Dissemination, Interactive AI
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce Paper2Agent to convert research papers into interactive AI agents, facilitating knowledge dissemination and complex scientific queries through natural language.
🛠️ Research Methods:
– Systematic analysis of research papers and associated codebases to construct Model Context Protocol (MCP) servers, which are iteratively refined and linked to chat agents for executing scientific inquiries.
💬 Research Conclusions:
– Paper2Agent successfully transforms static research papers into dynamic AI agents capable of reproducing original results and handling new queries, exemplified through case studies leveraging AlphaGenome, ScanPy, and TISSUE.
👉 Paper link: https://huggingface.co/papers/2509.06917

11. Easier Painting Than Thinking: Can Text-to-Image Models Set the Stage, but Not Direct the Play?
🔑 Keywords: Text-to-Image (T2I) Generation, Composition, Reasoning, Evaluation Taxonomy, Multi-Modal Learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– T2I-CoReBench is designed to evaluate the composition and reasoning capabilities of T2I models, addressing limitations in current benchmarks by providing a comprehensive and complex assessment.
🛠️ Research Methods:
– The benchmark employs a structured approach based on scene graph elements and a philosophical framework of inference, forming a 12-dimensional evaluation taxonomy with high compositional density and multi-step inference.
💬 Research Conclusions:
– Experiments on 27 T2I models indicate limited capabilities in handling complex scenarios, particularly with reasoning tasks, which remain a bottleneck in model performance.
👉 Paper link: https://huggingface.co/papers/2509.03516

12. Interleaving Reasoning for Better Text-to-Image Generation
🔑 Keywords: Interleaving Reasoning Generation (IRG), Text-to-Image (T2I) generation, text-based thinking, image synthesis, state-of-the-art performance
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to investigate the potential of Interleaving Reasoning Generation (IRG) to enhance Text-to-Image generation by combining text-based thinking with image synthesis.
🛠️ Research Methods:
– Introduction of IRG framework that alternates between text-based thinking and image synthesis, coupled with Interleaving Reasoning Generation Learning (IRGL) for effective training.
– Development of a robust dataset IRGL-300K, organized into six decomposed learning modes to enhance text-based thinking and image generation.
💬 Research Conclusions:
– The IRG framework achieves state-of-the-art performance with substantial improvements in visual quality and detail fidelity, as evidenced by gains in various benchmarks.
👉 Paper link: https://huggingface.co/papers/2509.06945

13. Scaling up Multi-Turn Off-Policy RL and Multi-Agent Tree Search for LLM Step-Provers
🔑 Keywords: BFS-Prover-V2, Large Language Models, Reinforcement Learning, AlphaZero, multi-agent search architecture
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Address scaling challenges in automated theorem proving with integration of multi-turn off-policy RL framework and planner-enhanced multi-agent search architecture.
🛠️ Research Methods:
– Introduced a novel multi-turn off-policy RL framework for performance improvement of LLM step-prover, inspired by AlphaZero principles.
– Implemented a planner-enhanced multi-agent search architecture scaling reasoning capabilities at inference time through subgoal decomposition and shared proof cache.
💬 Research Conclusions:
– BFS-Prover-V2 achieves state-of-the-art results on formal mathematics benchmarks, demonstrating significant improvements on MiniF2F and ProofNet test sets. Framework and techniques hold potential applicability in other domains requiring complex reasoning and search.
👉 Paper link: https://huggingface.co/papers/2509.06493

14. Guided Decoding and Its Critical Role in Retrieval-Augmented Generation
🔑 Keywords: Retrieval-Augmented Generation, Large Language Models, guided decoding, multi-turn prompting, structured output generation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the performance variations of guided decoding methods in structured output generation within Retrieval-Augmented Generation (RAG) systems.
🛠️ Research Methods:
– Comparison of three guided decoding methods: Outlines, XGrammar, and LM Format Enforcer across 0-turn, 1-turn, and 2-turn multi-turn prompting setups, focusing on success rates, hallucination rates, and output quality.
💬 Research Conclusions:
– The study reveals how multi-turn interactions impact guided decoding, showing unexpected performance variations and informing method selection for specific use cases, advancing knowledge in structured output generation in RAG systems.
👉 Paper link: https://huggingface.co/papers/2509.06631

15. Test-Time Scaling in Reasoning Models Is Not Effective for Knowledge-Intensive Tasks Yet
🔑 Keywords: Test-time scaling, Knowledge-intensive tasks, Factual accuracy, Hallucination rates, AI-generated summary
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To evaluate the efficacy of test-time scaling in enhancing accuracy and reducing hallucinations in knowledge-intensive tasks.
🛠️ Research Methods:
– Comprehensive evaluation using 12 reasoning models on two knowledge-intensive benchmarks to analyze test-time scaling effects.
💬 Research Conclusions:
– Test-time scaling does not consistently improve accuracy and may increase hallucinations; longer reasoning can lead to overconfident errors and confirmation bias.
👉 Paper link: https://huggingface.co/papers/2509.06861

16. Llama-GENBA-10B: A Trilingual Large Language Model for German, English and Bavarian
🔑 Keywords: Trilingual foundation model, English-centric bias, cross-lingual transfer, multilingual corpus, unified tokenizer
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study addresses English-centric bias in large language models by introducing Llama-GENBA-10B, a trilingual foundation model balanced across English, German, and Bavarian.
🛠️ Research Methods:
– Developed a multilingual corpus despite Bavarian scarcity and created a unified tokenizer for English, German, and Bavarian.
– Optimized architecture and language-ratio hyperparameters for effective cross-lingual transfer.
– Established a standardized trilingual evaluation suite by translating German benchmarks into Bavarian.
💬 Research Conclusions:
– Llama-GENBA-10B achieves strong cross-lingual performance, surpassing other models in Bavarian and showing competitive results in English and German.
– Demonstrates efficient large-scale multilingual pretraining on the Cerebras CS-2, providing a blueprint for inclusive foundation models integrating low-resource languages.
👉 Paper link: https://huggingface.co/papers/2509.05668

17. R^textbf{2AI}: Towards Resistant and Resilient AI in an Evolving World
🔑 Keywords: AI safety, R²AI, coevolution, AI Native, resilience
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– The paper introduces R²AI, a new framework aiming to bridge the gap between rapidly advancing AI capabilities and safety progress by enhancing AI safety through coevolution.
🛠️ Research Methods:
– The framework utilizes fast and slow safe models, adversarial simulation, and a safety wind tunnel to integrate resistance and resilience against known and unforeseen risks, with continual feedback loops for dynamic learning.
💬 Research Conclusions:
– R²AI provides a scalable, proactive pathway to maintain continual safety in dynamic environments, crucial for addressing near-term vulnerabilities and long-term risks as AI evolves towards AGI and ASI.
👉 Paper link: https://huggingface.co/papers/2509.06786

18. MAS-Bench: A Unified Benchmark for Shortcut-Augmented Hybrid Mobile GUI Agents
🔑 Keywords: MAS-Bench, GUI agents, hybrid paradigm, efficient shortcuts, mobile domain
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce MAS-Bench as a benchmark framework for evaluating the performance and efficiency of GUI-shortcut hybrid agents on mobile devices.
🛠️ Research Methods:
– Development of MAS-Bench featuring 139 complex tasks, 88 predefined shortcuts, and 7 evaluation metrics to assess agents’ shortcut generation capability.
💬 Research Conclusions:
– Hybrid agents outperform GUI-only agents in success rates and efficiency, showcasing the effectiveness of MAS-Bench in evaluating agents’ shortcut generation capabilities.
👉 Paper link: https://huggingface.co/papers/2509.06477

19. D-HUMOR: Dark Humor Understanding via Multimodal Open-ended Reasoning
🔑 Keywords: Large Vision-Language Model, Tri-stream Cross-Reasoning Network, dark humor detection, multimodal memes, AI-generated summary
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Develop a framework to effectively detect dark humor, identify targets, and predict intensity in multimodal memes using advanced reasoning techniques.
🛠️ Research Methods:
– Utilized a Large Vision-Language Model and a Tri-stream Cross-Reasoning Network, incorporating a Role-Reversal Self-Loop and pairwise attention mechanisms to process text, images, and reasoning for classification.
💬 Research Conclusions:
– The proposed approach demonstrates superior performance over existing baselines across tasks of dark humor detection, target identification, and intensity prediction, with resources made available to support further research in the field.
👉 Paper link: https://huggingface.co/papers/2509.06771

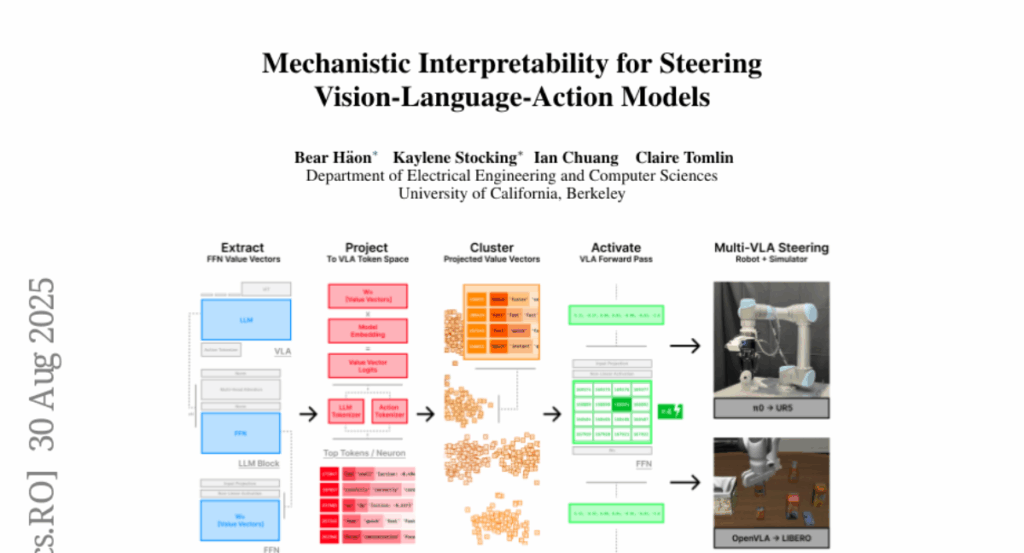
20. Mechanistic interpretability for steering vision-language-action models
🔑 Keywords: Vision-Language-Action models, Mechanistic Interpretability, Activation Steering, Robotics, Zero-Shot Control
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper aims to introduce a framework for interpreting and steering Vision-Language-Action models by accessing their internal representations to enable real-time behavioral control without the need for fine-tuning or environment interaction.
🛠️ Research Methods:
– Projection of feedforward activations within transformer layers onto the token embedding basis to identify sparse semantic directions linked to action selection.
– Development of a general-purpose activation steering method to modulate behavior in real-time.
💬 Research Conclusions:
– The implementation of interpretable components of embodied VLAs for control establishes a new paradigm for transparent and steerable foundation models in robotics, demonstrating effectiveness in zero-shot behavioral control in both simulations and on a physical robot.
👉 Paper link: https://huggingface.co/papers/2509.00328
21. Singular Value Few-shot Adaptation of Vision-Language Models
🔑 Keywords: Vision-language models, CLIP, Singular Value Decomposition, Few-shot learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces CLIP-SVD, a novel adaptation technique for vision-language models that enhances domain adaptation without compromising the model’s pretrained knowledge.
🛠️ Research Methods:
– Utilizes Singular Value Decomposition (SVD) to fine-tune the singular values of parameter matrices in CLIP, allowing efficient domain adaptation while preserving the generalization ability of the model.
💬 Research Conclusions:
– CLIP-SVD achieves state-of-the-art classification results on both natural and biomedical datasets, outperforming previous methods in accuracy and few-shot generalization. The approach requires only 0.04% of the model’s total parameters, ensuring parameter efficiency and enhanced performance.
👉 Paper link: https://huggingface.co/papers/2509.03740

22. Inpaint4Drag: Repurposing Inpainting Models for Drag-Based Image Editing via Bidirectional Warping
🔑 Keywords: Drag-based editing, Pixel-space warping, Real-time warping, Image inpainting, Generative models
💡 Category: Computer Vision
🌟 Research Objective:
– To improve drag-based image editing by decomposing it into pixel-space warping and inpainting, offering real-time performance and superior visual quality.
🛠️ Research Methods:
– Decomposition of drag-based editing into pixel-space bidirectional warping and image inpainting, allowing for real-time interaction and precise control.
– Utilization of 512×512 resolution for quick warping previews (0.01s) and efficient inpainting (0.3s).
💬 Research Conclusions:
– Inpaint4Drag enhances interaction experience with significantly faster and more precise image edits compared to existing methods.
– Acts as a universal adapter for inpainting models, automatically benefitting from future inpainting technology advancements.
👉 Paper link: https://huggingface.co/papers/2509.04582

23. DCReg: Decoupled Characterization for Efficient Degenerate LiDAR Registration
🔑 Keywords: LiDAR point cloud registration, Schur complement decomposition, ill-conditioned, novel preconditioner, Preconditioned Conjugate Gradient method
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Address ill-conditioned LiDAR point cloud registration by detecting, characterizing, and mitigating degeneracies.
🛠️ Research Methods:
– Utilizes Schur complement decomposition to decouple registration problems into rotational and translational subspaces, and develops a quantitative characterization technique.
– Designs a novel preconditioner to selectively stabilize identified ill-conditioned directions.
💬 Research Conclusions:
– DCReg achieves 20%-50% improvement in localization accuracy and a 5-100 times speedup over existing methods.
👉 Paper link: https://huggingface.co/papers/2509.06285

24. Saturation-Driven Dataset Generation for LLM Mathematical Reasoning in the TPTP Ecosystem
🔑 Keywords: Large Language Models, automated theorem proving, E-prover, logical soundness, zero-shot experiments
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Develop a scalable framework to generate high-quality, logically sound symbolic training data for enhancing the mathematical reasoning capabilities of Large Language Models (LLMs).
🛠️ Research Methods:
– Utilize E-prover’s saturation capabilities on the TPTP axiom library to create a massive corpus of valid theorems.
– Transform the symbolic data into tasks like entailment verification, premise selection, and proof reconstruction without involving LLMs.
💬 Research Conclusions:
– Identified a weakness in frontier models regarding their performance on tasks requiring deep, structural reasoning.
– Proposed framework as both a diagnostic tool for measuring reasoning gaps and a source of symbolic training data to address these gaps.
– Provided access to the code and data for community use.
👉 Paper link: https://huggingface.co/papers/2509.06809

25. SFR-DeepResearch: Towards Effective Reinforcement Learning for Autonomously Reasoning Single Agents
🔑 Keywords: AI Native, Autonomous Single-Agent models, Continual Reinforcement Learning, Reasoning-Optimized models, Deep Research
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance autonomous single-agent models for Deep Research tasks using continual reinforcement learning to improve agentic skills and reasoning abilities
🛠️ Research Methods:
– Developing a simple RL recipe with synthetic data applied to open-source large language models to optimize reasoning capabilities
💬 Research Conclusions:
– The proposed model SFR-DR-20B achieves significant performance, reaching up to 28.7% on Humanity’s Last Exam benchmark, providing valuable insights into agentic AI development methodologies
👉 Paper link: https://huggingface.co/papers/2509.06283

26.
