AI Native Daily Paper Digest – 20251003

1. LongCodeZip: Compress Long Context for Code Language Models
🔑 Keywords: LongCodeZip, Large Language Models, code compression, context pruning
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research aims to develop LongCodeZip, a code compression framework specifically designed for code Large Language Models (LLMs) to improve efficiency and performance by reducing context size without compromising on task accuracy.
🛠️ Research Methods:
– LongCodeZip uses a dual-stage strategy: coarse-grained compression to rank function-level chunks using conditional perplexity and fine-grained compression to further segment and optimize the retained functions under an adaptive token budget.
💬 Research Conclusions:
– Evaluations indicate that LongCodeZip significantly outperforms existing methods, achieving up to a 5.6x compression ratio while maintaining task performance, thus enabling better scalability and efficiency in large-scale code intelligence applications.
👉 Paper link: https://huggingface.co/papers/2510.00446

2. Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
🔑 Keywords: video generation, Diffusion models, quality degradation, temporal consistency, position embedding
💡 Category: Generative Models
🌟 Research Objective:
– Enhance long-horizon video generation by improving quality and consistency without additional supervision or retraining.
🛠️ Research Methods:
– Utilize sampled segments from self-generated videos to guide student models, avoiding quality degradation and maintaining temporal consistency.
💬 Research Conclusions:
– The proposed method allows videos to scale up to 20x beyond the teacher’s capability in length, achieving superior performance compared to baseline methods.
👉 Paper link: https://huggingface.co/papers/2510.02283
3. StealthAttack: Robust 3D Gaussian Splatting Poisoning via Density-Guided Illusions
🔑 Keywords: 3D Gaussian Splatting, density-guided poisoning, Kernel Density Estimation, image-level poisoning attacks
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to enhance the attack effectiveness on 3D Gaussian Splatting by strategically injecting Gaussian points and disrupting multi-view consistency.
🛠️ Research Methods:
– The method involves a novel density-guided poisoning approach that injects Gaussian points into low-density regions via Kernel Density Estimation, embedding viewpoint-dependent illusory objects, and employing an adaptive noise strategy to disrupt multi-view consistency.
💬 Research Conclusions:
– The proposed method demonstrated superior performance in attack effectiveness compared to existing techniques, showing promise for systematic assessment and benchmarking in future research.
👉 Paper link: https://huggingface.co/papers/2510.02314
4. ExGRPO: Learning to Reason from Experience
🔑 Keywords: ExGRPO, Reinforcement Learning, Experience Management, Large Language Models, Reasoning Performance
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to enhance and stabilize reinforcement learning from verifiable rewards for large language models by efficiently managing and prioritizing valuable reasoning experiences.
🛠️ Research Methods:
– Introduces ExGRPO, a framework that utilizes rollout correctness and entropy as indicators to identify valuable experiences. It employs a mixed-policy objective to balance exploration with experience exploitation.
💬 Research Conclusions:
– ExGRPO consistently improves reasoning performance across various benchmarks, providing an average score increase and stabilizing training, demonstrating the significance of effective experience management for efficient and scalable reinforcement learning.
👉 Paper link: https://huggingface.co/papers/2510.02245

5. Interactive Training: Feedback-Driven Neural Network Optimization
🔑 Keywords: Interactive Training, AI agents, optimizer hyperparameters, training stability, adaptability
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce Interactive Training, a framework for real-time, feedback-driven intervention during neural network training to improve stability and adaptability.
🛠️ Research Methods:
– Utilization of a control server to allow dynamic adjustments by experts or AI agents on optimizer hyperparameters, training data, and model checkpoints.
💬 Research Conclusions:
– Demonstrated superior training stability, reduced sensitivity to initial hyperparameters, and improved adaptability through three case studies.
👉 Paper link: https://huggingface.co/papers/2510.02297

6. ModernVBERT: Towards Smaller Visual Document Retrievers
🔑 Keywords: ModernVBERT, Vision-Language Encoder, Multimodal Embedding Models, Document Retrieval, Contrastive Objectives
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To demonstrate the effectiveness of ModernVBERT, a compact vision-language encoder, in outperforming larger models in visual document retrieval tasks.
🛠️ Research Methods:
– Conduct controlled experiments to evaluate performance factors such as attention masking, image resolution, modality alignment, and contrastive objectives.
💬 Research Conclusions:
– ModernVBERT, with its 250M parameters, surpasses larger models when fine-tuned for document retrieval, highlighting key performance enhancements through optimized model architecture and contrastive learning.
👉 Paper link: https://huggingface.co/papers/2510.01149

7. StockBench: Can LLM Agents Trade Stocks Profitably In Real-world Markets?
🔑 Keywords: Large language models, financial agents, trading strategies, StockBench, AI Native
💡 Category: AI in Finance
🌟 Research Objective:
– To evaluate large language models (LLMs) in realistic, multi-month stock trading environments and assess their performance as financial agents.
🛠️ Research Methods:
– Introduction of StockBench, a contamination-free benchmark that provides daily market signals including prices, fundamentals, and news for LLM agents to make sequential buy, sell, or hold decisions.
💬 Research Conclusions:
– Most LLM agents struggle to outperform the simple buy-and-hold baseline, but several models show potential for higher returns and better risk management, highlighting both challenges and opportunities in developing LLM-powered financial agents.
👉 Paper link: https://huggingface.co/papers/2510.02209

8. The Rogue Scalpel: Activation Steering Compromises LLM Safety
🔑 Keywords: Activation steering, LLM behavior, Model alignment safeguards, Harmful compliance, Universal attack
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to investigate the effects of Activation steering on controlling LLM behavior and its implications for model alignment safeguards.
🛠️ Research Methods:
– Extensive experiments were conducted on different model families to evaluate the impact of activation steering, including steering in random directions and using features from a sparse autoencoder.
💬 Research Conclusions:
– Activation steering can break model alignment safeguards, increasing harmful compliance from 0% to 2-27%.
– Steering benign features further increases compliance rates by 2-4%.
– Combining vectors that jailbreak a single prompt results in a universal attack, increasing harmful compliance on unseen requests.
– These findings challenge the notion that safety through interpretability ensures control over model behavior.
👉 Paper link: https://huggingface.co/papers/2509.22067

9. VOGUE: Guiding Exploration with Visual Uncertainty Improves Multimodal Reasoning
🔑 Keywords: Visual Uncertainty, Multimodal Reasoning, Reinforcement Learning, Exploration-Exploitation, AI-Generated Summary
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce VOGUE, a method for enhancing exploration in large language models through visual input space analysis to improve multimodal reasoning.
🛠️ Research Methods:
– VOGUE shifts exploration from output to input by considering images as stochastic contexts, using symmetric KL divergence for uncertainty quantification, and implementing uncertainty-aware exploration techniques.
💬 Research Conclusions:
– VOGUE successfully improves pass@1 accuracy on visual and general-domain benchmarks by exploiting visual input uncertainties, balancing exploration and exploitation, and mitigating exploration decay in reinforcement learning fine-tuning.
👉 Paper link: https://huggingface.co/papers/2510.01444

10. CLUE: Non-parametric Verification from Experience via Hidden-State Clustering
🔑 Keywords: Large Language Models, hidden states, CLUE, verification, confidence-based methods
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore the use of hidden states in Large Language Models as a foundation for verification, highlighting their ability to encode correctness as a separable signature surpassing traditional text-level and confidence-based methods.
🛠️ Research Methods:
– Introduces CLUE, a minimalist, non-parametric verifier that utilizes hidden state deltas and nearest-centroid distance for classifying the correctness of outputs without any trainable parameters.
💬 Research Conclusions:
– CLUE outperforms existing LLM-as-a-judge baselines and modern confidence-based methods in reranking and accuracy, improving both top-1 and majority-vote accuracy metrics.
👉 Paper link: https://huggingface.co/papers/2510.01591

11. RLP: Reinforcement as a Pretraining Objective
🔑 Keywords: Reinforcement Learning, Pretraining, Exploration, Chain-of-Thought, Information Gain
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To introduce RLP, an information-driven reinforcement pretraining objective that incorporates exploration into the pretraining phase of reasoning models to enhance performance.
🛠️ Research Methods:
– RLP treats the chain-of-thought as an exploratory action with reward signals based on information gain for predicting future tokens, implemented during the pretraining phase on models like Qwen3-1.7B-Base and Nemotron-Nano-12B-v2.
💬 Research Conclusions:
– Pretraining with RLP significantly lifts performance, improving results across various benchmarks, especially in reasoning-heavy tasks, demonstrating the scalability and efficiency of this approach in enhancing reasoning models.
👉 Paper link: https://huggingface.co/papers/2510.01265

12. The Unreasonable Effectiveness of Scaling Agents for Computer Use
🔑 Keywords: Behavior Best-of-N, computer-use agents, state-of-the-art, rollouts, behavior narratives
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve the reliability and success rates of computer-use agents through the Behavior Best-of-N (bBoN) method by generating and selecting among multiple rollouts using behavior narratives.
🛠️ Research Methods:
– The method involves generating multiple rollouts and employing behavior narratives for selection, leading to wide exploration and structured trajectory selection.
💬 Research Conclusions:
– The bBoN method establishes a new state of the art at 69.9% on OSWorld and demonstrates strong generalization to different operating systems, significantly outperforming prior methods and approaching human performance levels.
👉 Paper link: https://huggingface.co/papers/2510.02250

13. Tree-based Dialogue Reinforced Policy Optimization for Red-Teaming Attacks
🔑 Keywords: Reinforcement Learning, Tree Search, Multi-turn Interaction, Adversarial Attacks
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The aim of the research is to autonomously discover diverse multi-turn attack strategies against large language models using an on-policy reinforcement learning framework with tree search.
🛠️ Research Methods:
– The researchers employed DialTree-RPO, an on-policy reinforcement learning framework integrated with tree search, to systematically explore and discover new multi-turn attack trajectories without the need for human-curated data.
💬 Research Conclusions:
– The approach achieves over 25.9% higher attack success rates compared to previous methods and uncovers novel attack strategies through optimal dialogue policies in multi-turn settings.
👉 Paper link: https://huggingface.co/papers/2510.02286

14. Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation
🔑 Keywords: Audio-video generation, Twin-DiT modules, Blockwise cross-modal fusion, Cinematic storytelling
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Ovi, a unified model for simultaneous audio-video generation that ensures natural synchronization and high-quality outputs.
🛠️ Research Methods:
– Utilizes twin-DiT modules with blockwise cross-modal fusion for seamless integration of audio and video.
– Audio tower is initialized with video model architecture and trained on extensive audio datasets.
💬 Research Conclusions:
– Ovi enhances cinematic storytelling by producing movie-grade video clips with accurate context-matched sound effects and natural speech.
👉 Paper link: https://huggingface.co/papers/2510.01284
15. A Rigorous Benchmark with Multidimensional Evaluation for Deep Research Agents: From Answers to Reports
🔑 Keywords: Deep Research Agents, Benchmark, Task Decomposition, Multi-stage Reasoning, Semantic Quality
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to introduce a comprehensive benchmark and evaluation framework for Deep Research Agents (DRAs) to assess their performance on complex tasks with multidimensional metrics.
🛠️ Research Methods:
– The researchers developed a benchmark consisting of 214 expert-curated challenging queries across 10 thematic domains, with reference bundles for composite evaluation. A multidimensional evaluation framework was tailored to assess the semantic quality, topical focus, and retrieval trustworthiness of long-form reports by DRAs.
💬 Research Conclusions:
– The experiment confirms that mainstream DRAs perform superiorly compared to web-search-tool-augmented reasoning models, although there remains significant room for improvement. The study lays a foundation for assessing capabilities and refining DRA architectures.
👉 Paper link: https://huggingface.co/papers/2510.02190

16. RewardMap: Tackling Sparse Rewards in Fine-grained Visual Reasoning via Multi-Stage Reinforcement Learning
🔑 Keywords: RewardMap, multi-stage RL, dense reward signals, visual understanding, reasoning capabilities
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance the visual understanding and reasoning skills of multimodal large language models (MLLMs) using a novel reinforcement learning framework called RewardMap.
🛠️ Research Methods:
– Developed ReasonMap-Plus, an extended dataset introducing dense reward signals via Visual Question Answering tasks for effective cold-start training.
– Proposed RewardMap, a multi-stage reinforcement learning framework, focusing on difficulty-aware reward design and a multi-stage RL scheme for training progression from simple to complex tasks.
💬 Research Conclusions:
– Experimental results demonstrated consistent performance gains with RewardMap, achieving an average improvement of 3.47% across multiple benchmarks, validating improved visual understanding and reasoning abilities in MLLMs.
👉 Paper link: https://huggingface.co/papers/2510.02240

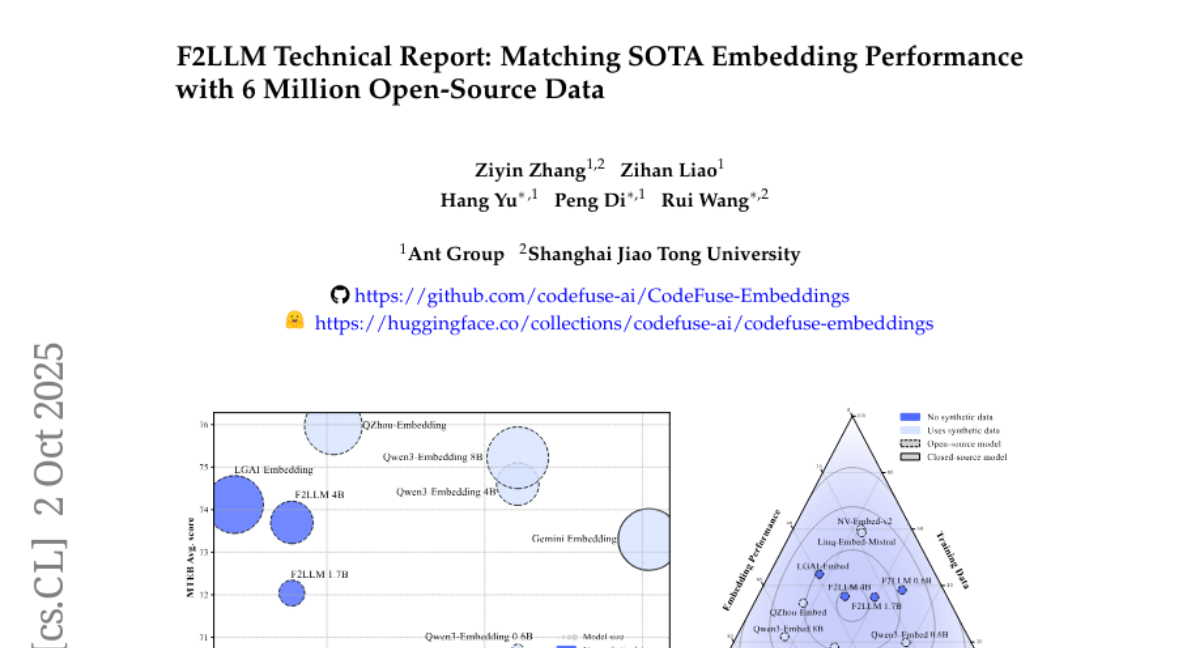
17. F2LLM Technical Report: Matching SOTA Embedding Performance with 6 Million Open-Source Data
🔑 Keywords: F2LLM, embedding models, foundation models, fine-tuning, open-source datasets
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce F2LLM, a suite of large language models designed to achieve high embedding performance with efficient fine-tuning from foundation models.
🛠️ Research Methods:
– F2LLM models are finetuned on 6 million query-document-negative tuples curated from open-source, non-synthetic datasets, avoiding massive pretraining and costly synthetic data.
💬 Research Conclusions:
– F2LLM-4B and F2LLM-1.7B achieve high rankings on the MTEB English leaderboard, demonstrating strong performance and cost-effectiveness as reproducible baselines for future research.
👉 Paper link: https://huggingface.co/papers/2510.02294
18. DragFlow: Unleashing DiT Priors with Region Based Supervision for Drag Editing
🔑 Keywords: DragFlow, FLUX, DiT, drag-based image editing, affine transformations
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to improve drag-based image editing by leveraging FLUX’s strong generative priors and region-based editing using affine transformations.
🛠️ Research Methods:
– Introduces a region-based editing paradigm with affine transformations to enhance feature supervision.
– Integrates pretrained open-domain personalization adapters to improve subject consistency while maintaining background fidelity.
– Employs multimodal large language models to address task ambiguities.
💬 Research Conclusions:
– DragFlow outperforms existing point-based and region-based baselines, achieving state-of-the-art performance in drag-based image editing.
👉 Paper link: https://huggingface.co/papers/2510.02253

19. TOUCAN: Synthesizing 1.5M Tool-Agentic Data from Real-World MCP Environments
🔑 Keywords: Toucan, LLM agents, tool-agentic dataset, BFCL V3 benchmark, multi-turn interactions
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Toucan, the largest publicly available tool-agentic dataset, to enhance the performance of LLM agents with diverse, realistic, and complex multi-tool and multi-turn interactions.
🛠️ Research Methods:
– Utilization of authentic Model Context Protocols (MCPs) to generate diverse tasks, alongside model-based quality filtering and agentic trajectory generation using three teacher models within two frameworks.
💬 Research Conclusions:
– Models fine-tuned on Toucan outperform larger closed-source models on the BFCL V3 benchmark and push the Pareto frontier on the MCP-Universe Bench, showcasing the dataset’s effectiveness in improving LLM applications.
👉 Paper link: https://huggingface.co/papers/2510.01179

20. Aristotle: IMO-level Automated Theorem Proving
🔑 Keywords: Aristotle, AI System, Lean proof search, informal reasoning, geometry solver
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce Aristotle, an AI system that achieves top performance on International Mathematical Olympiad problems by combining formal verification with informal reasoning.
🛠️ Research Methods:
– Integration of a Lean proof search system, an informal reasoning system for lemma generation and formalization, and a dedicated geometry solver.
💬 Research Conclusions:
– Demonstrates state-of-the-art performance with favorable scaling properties for automated theorem proving.
👉 Paper link: https://huggingface.co/papers/2510.01346

21. Learning to Reason for Hallucination Span Detection
🔑 Keywords: hallucination detection, large language models, reinforcement learning, Chain-of-Thought, span-level rewards
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve hallucination span detection in large language models through a reinforcement learning framework with span-level rewards, incentivizing reasoning.
🛠️ Research Methods:
– Evaluated pretrained models with and without Chain-of-Thought reasoning.
– Developed and tested RL4HS framework using Group Relative Policy Optimization and Class-Aware Policy Optimization.
💬 Research Conclusions:
– RL4HS surpasses pretrained models and supervised fine-tuning, demonstrating that reinforcement learning with span-level rewards is crucial for effective hallucination span detection.
👉 Paper link: https://huggingface.co/papers/2510.02173
