AI Native Daily Paper Digest – 20251009

1. Cache-to-Cache: Direct Semantic Communication Between Large Language Models
🔑 Keywords: Cache-to-Cache, Large Language Models, neural network, direct semantic communication, latency
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore direct semantic communication between Large Language Models (LLMs) using Cache-to-Cache (C2C), improving performance and efficiency compared to text-based communication.
🛠️ Research Methods:
– The researchers utilized neural network projections to enable direct semantic transfer between LLMs via KV-Cache, employing a learnable gating mechanism to optimize inter-model communication.
💬 Research Conclusions:
– The proposed C2C paradigm enhances accuracy by 8.5-10.5% over individual models and surpasses text communication by 3.0-5.0%, achieving an average 2.0x reduction in latency.
👉 Paper link: https://huggingface.co/papers/2510.03215

2. Ming-UniVision: Joint Image Understanding and Generation with a Unified Continuous Tokenizer
🔑 Keywords: MingTok, continuous latent space, autoregressive framework, visual tokenization, vision-language tasks
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective of the research is to develop MingTok, a continuous latent space visual tokenizer, to unify vision-language understanding and generation within an autoregressive framework, achieving state-of-the-art performance across both domains.
🛠️ Research Methods:
– The paper introduces a three-stage sequential architecture involving low-level encoding, semantic expansion, and visual reconstruction to reconcile the competing demands of vision-language tasks.
💬 Research Conclusions:
– The study concludes that using a unified continuous visual representation in visual tokenization can enhance semantic expressiveness and support a wide range of tasks, leading to state-of-the-art performance in vision-language understanding and generation.
👉 Paper link: https://huggingface.co/papers/2510.06590
3. Lumina-DiMOO: An Omni Diffusion Large Language Model for Multi-Modal Generation and Understanding
🔑 Keywords: Lumina-DiMOO, Open-Source Model, Multi-Modal, Discrete Diffusion
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Lumina-DiMOO is designed to facilitate efficient multi-modal generation and understanding using a fully discrete diffusion modeling approach.
🛠️ Research Methods:
– The model employs fully discrete diffusion modeling which enhances sampling efficiency over traditional autoregressive and hybrid AR-Diffusion models.
💬 Research Conclusions:
– Lumina-DiMOO outperforms existing unified multi-modal models, achieving state-of-the-art results in benchmarks and supports various tasks such as text-to-image and image-to-image generation, as well as image understanding.
– The release of code and checkpoints aims to motivate advancements in multi-modal and discrete diffusion model research.
👉 Paper link: https://huggingface.co/papers/2510.06308

4. SHANKS: Simultaneous Hearing and Thinking for Spoken Language Models
🔑 Keywords: SHANKS, spoken language models, real-time interaction, unspoken reasoning, interruption accuracy
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The research aims to enhance real-time interactions and task completion between users and Spoken Language Models (SLMs) by enabling unspoken reasoning during user input via the SHANKS framework.
🛠️ Research Methods:
– SHANKS streams input speech in fixed-duration chunks, generating unspoken reasoning with each chunk. It uses this reasoning to decide on user interruptions and tool calls, enhancing interaction efficiency.
💬 Research Conclusions:
– SHANKS significantly improves real-time user-SLM interaction, with increased interruption accuracy in math problem-solving and earlier tool call completions in dialogue tasks.
👉 Paper link: https://huggingface.co/papers/2510.06917
5. RLinf-VLA: A Unified and Efficient Framework for VLA+RL Training
🔑 Keywords: RLinf-VLA, Vision-Language-Action, Reinforcement Learning, Embodied Intelligence, GPU-parallelized Simulators
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces RLinf-VLA, a unified framework for scalable reinforcement learning training of vision-language-action models, aiming to improve performance and generalization over traditional supervised fine-tuning methods.
🛠️ Research Methods:
– The framework employs a flexible resource allocation design to integrate rendering, training, and inference. It incorporates a novel hybrid fine-grained pipeline allocation mode for GPU-parallelized simulators, supporting diverse architectures, algorithms, and simulators.
💬 Research Conclusions:
– RLinf-VLA achieves significant training speedup and exhibits strong generalization in simulated tasks and preliminary real-world deployment, highlighting its potential to accelerate research in embodied intelligence.
👉 Paper link: https://huggingface.co/papers/2510.06710

6. MATRIX: Mask Track Alignment for Interaction-aware Video Generation
🔑 Keywords: MATRIX-11K, Video DiTs, semantic alignment, interaction fidelity, MATRIX regularization
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance interaction fidelity and semantic alignment in video DiTs by utilizing the MATRIX-11K dataset and introducing MATRIX regularization.
🛠️ Research Methods:
– Conducts a systematic analysis of video DiTs by curating the MATRIX-11K dataset and examining two perspectives: semantic grounding and semantic propagation.
– Introduces MATRIX regularization that aligns attention layers with multi-instance mask tracks for improved grounding and propagation.
💬 Research Conclusions:
– MATRIX enhances interaction fidelity and semantic alignment in video DiTs, reduces drift and hallucination, with experimental validation supporting these design choices.
👉 Paper link: https://huggingface.co/papers/2510.07310

7. Vibe Checker: Aligning Code Evaluation with Human Preference
🔑 Keywords: Large Language Models, vibe coding, human preference, functional correctness, instruction following
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to evaluate Large Language Models’ (LLMs) ability to align with human coding preferences through a method called Vibe Checker, combining functional correctness and instruction following.
🛠️ Research Methods:
– A taxonomy called VeriCode, consisting of 30 verifiable code instructions and corresponding deterministic verifiers, is developed to assess code instruction following and functional correctness, augmenting existing evaluation suites.
💬 Research Conclusions:
– Despite being strong, current LLMs struggle with following multiple instructions, leading to functional regression. Instruction following, along with functional correctness, best correlates with human preference, offering a path for developing models that align better with user coding preferences.
👉 Paper link: https://huggingface.co/papers/2510.07315

8. Multi-Agent Tool-Integrated Policy Optimization
🔑 Keywords: Multi-Agent Framework, Reinforcement Learning, LLM, Role-Specific Prompts, Robustness
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The primary goal is to optimize tool-integrated multi-agent roles within a single large language model (LLM) to enhance performance and robustness compared to single-agent systems.
🛠️ Research Methods:
– The study introduces Multi-Agent Tool-Integrated Policy Optimization (MATPO) using reinforcement learning to train distinct roles (planner and worker) with role-specific prompts within a single LLM instance, based on a principled credit assignment mechanism.
💬 Research Conclusions:
– Experiments show MATPO leads to an 18.38% relative improvement in performance over single-agent baselines and offers greater robustness against noisy tool outputs, validating the effectiveness of integrating multiple agent roles within a single LLM.
👉 Paper link: https://huggingface.co/papers/2510.04678

9. The African Languages Lab: A Collaborative Approach to Advancing Low-Resource African NLP
🔑 Keywords: African languages, NLP, data collection, fine-tuning, AI-generated
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address the underserved status of African languages in NLP by creating a large, validated multi-modal dataset.
🛠️ Research Methods:
– Developed a quality-controlled data collection pipeline, covering 40 languages with 19 billion text tokens and 12,628 hours of speech data.
– Conducted experimental validations demonstrating improved model performance through fine-tuning.
💬 Research Conclusions:
– The dataset combined with fine-tuning leads to substantial improvements in NLP model performance, with notable increases in ChrF++, COMET, and BLEU scores.
– Comparative evaluation shows competitive performance against Google Translate for several languages, highlighting areas for further development.
👉 Paper link: https://huggingface.co/papers/2510.05644

10. CALM Before the STORM: Unlocking Native Reasoning for Optimization Modeling
🔑 Keywords: CALM, Large Reasoning Models, domain adaptation, corrective adaptation, reasoning trajectories
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The research aims to refine Large Reasoning Models (LRMs) for optimization tasks using the CALM framework, which incorporates expert interventions to achieve higher accuracy with minimal modifications.
🛠️ Research Methods:
– The CALM framework involves expert interventions to identify reasoning flaws and provide corrective hints, which are used by LRMs to improve reasoning trajectories. It applies soft adaptation through supervised fine-tuning followed by reinforcement learning.
💬 Research Conclusions:
– The study concludes that dynamic, hint-based data synthesis effectively leverages the native reasoning abilities of LRMs. The developed STORM model demonstrates state-of-the-art accuracy in optimization modeling, matching the performance of much larger models.
👉 Paper link: https://huggingface.co/papers/2510.04204

11. Why Low-Precision Transformer Training Fails: An Analysis on Flash Attention
🔑 Keywords: Low-precision training, transformer models, flash attention, low-rank representations, biased rounding errors
💡 Category: Machine Learning
🌟 Research Objective:
– This paper aims to provide the first mechanistic explanation for the catastrophic loss explosions in low-precision training of transformer models using flash attention.
🛠️ Research Methods:
– The study conducts an in-depth analysis to identify the intertwined causes of the failure: low-rank representations and biased rounding errors. The researchers then introduce a minimal modification to the flash attention mechanism to address these issues.
💬 Research Conclusions:
– The proposed modification successfully stabilizes the training process by mitigating rounding error bias, confirming the analysis and providing a practical solution to the problem.
👉 Paper link: https://huggingface.co/papers/2510.04212

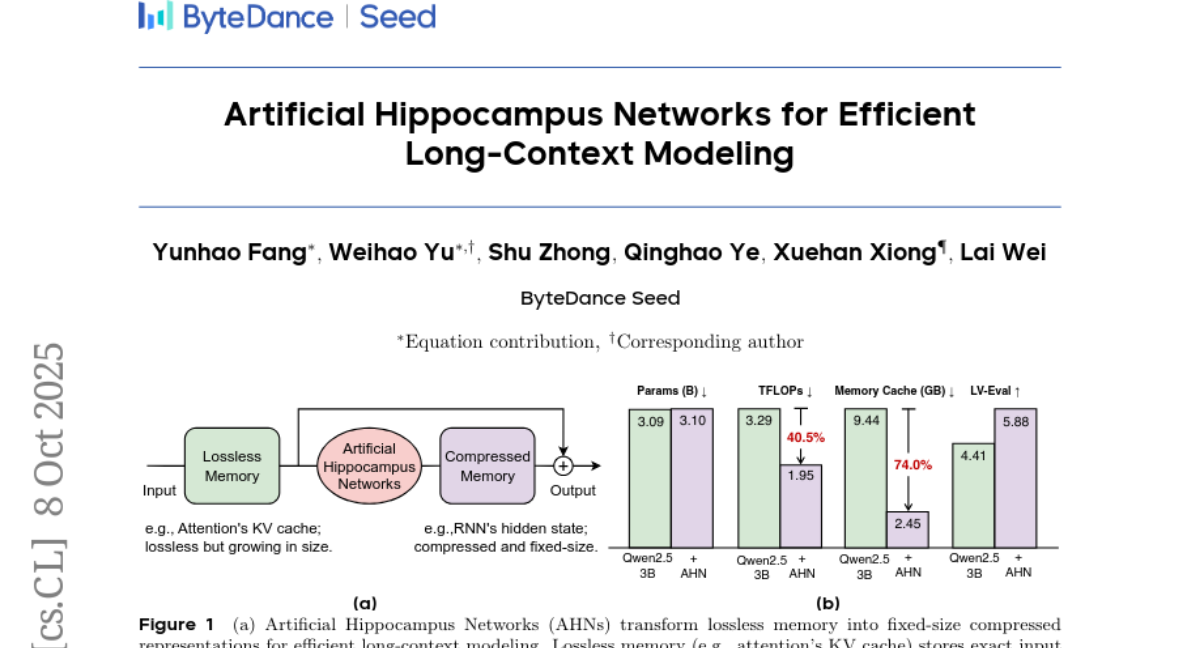
12. Artificial Hippocampus Networks for Efficient Long-Context Modeling
🔑 Keywords: Long-sequence modeling, Neural Networks, Artificial Hippocampus Network, Efficiency, Memory framework
💡 Category: Machine Learning
🌟 Research Objective:
– To improve efficiency and performance in modeling long sequences without sacrificing fidelity by combining short-term and long-term memory in neural networks.
🛠️ Research Methods:
– The introduction of a memory framework inspired by the Multi-Store Model, maintaining a sliding window of Transformer’s KV cache for short-term memory and utilizing the Artificial Hippocampus Network for compressing data into long-term memory.
– Implementation using architectures like Mamba2, DeltaNet, and Gated DeltaNet.
💬 Research Conclusions:
– AHN-augmented models consistently outperform sliding window baselines and show comparable or superior performance to full-attention models with significantly reduced computational and memory requirements.
– Specifically, augmenting Qwen2.5-3B-Instruct with AHNs resulted in a 40.5% reduction in inference FLOPs and a 74.0% reduction in memory cache while increasing performance scores on benchmarks like LV-Eval.
👉 Paper link: https://huggingface.co/papers/2510.07318
13. Pushing on Multilingual Reasoning Models with Language-Mixed Chain-of-Thought
🔑 Keywords: Language-Mixed CoT, Cross-lingual, Multimodal, KO-REAson-35B
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance Korean-specific task performance by employing a language-mixed chain-of-thought reasoning approach, switching between English and Korean.
🛠️ Research Methods:
– Introduces Language-Mixed CoT, utilizing English as an anchor to excel in reasoning and minimize translation artifacts. The study curates a large dataset, trains models across different families and sizes, and evaluates their performance on benchmarks.
💬 Research Conclusions:
– The best model, KO-REAson-35B, achieves state-of-the-art performance with the highest average score, demonstrating significant improvements over monolingual CoT, as well as cross-lingual and multimodal performance gains.
👉 Paper link: https://huggingface.co/papers/2510.04230

14. Native Hybrid Attention for Efficient Sequence Modeling
🔑 Keywords: Native Hybrid Attention, Transformers, linear attention, sliding window, recall-intensive tasks
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Native Hybrid Attention (NHA) to improve efficiency while maintaining long-term context in AI models, outperforming Transformers.
🛠️ Research Methods:
– Developed a novel hybrid architecture combining linear and full attention mechanisms with intra and inter-layer hybridization.
💬 Research Conclusions:
– NHA surpasses Transformers and other baselines in recall-intensive and commonsense reasoning tasks, providing efficiency gains, especially when integrated with pretrained LLMs.
👉 Paper link: https://huggingface.co/papers/2510.07019

15. The Markovian Thinker
🔑 Keywords: Markovian Thinking, Delethink, Reinforcement Learning, LongCoT, Linear Compute
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to improve reinforcement learning’s efficiency and scalability in long-chain-of-thought reasoning for large language models (LLMs) by introducing a new paradigm called Markovian Thinking, which decouples thinking length from context size.
🛠️ Research Methods:
– The researchers implemented Markovian Thinking in an RL environment named Delethink, which structures reasoning into fixed-size chunks, ensuring linear compute and constant memory usage by resetting context and reinitializing prompts with short carryovers at the chunk boundaries.
💬 Research Conclusions:
– The study demonstrates that redesigning the thinking environment using Markovian Thinking allows very long reasoning without quadratic overhead, achieving efficiency and scalability. The Delethink environment proved to be effective, with empirical results showing substantial cost reduction in computational resources compared to traditional LongCoT-RL methods.
👉 Paper link: https://huggingface.co/papers/2510.06557

16. OBS-Diff: Accurate Pruning For Diffusion Models in One-Shot
🔑 Keywords: OBS-Diff, diffusion models, one-shot pruning, Hessian construction, inference acceleration
💡 Category: Generative Models
🌟 Research Objective:
– Introduce OBS-Diff, a one-shot pruning framework aimed at compressing large-scale text-to-image diffusion models with minimal quality loss and significant inference acceleration.
🛠️ Research Methods:
– Adaptation of Optimal Brain Surgeon to modern diffusion models, enabling multiple pruning granularities.
– Development of a timestep-aware Hessian construction with a logarithmic-decrease weighting scheme to address error accumulation in the diffusion process.
– Introduction of a computationally efficient group-wise sequential pruning strategy to optimize the calibration process.
💬 Research Conclusions:
– OBS-Diff demonstrates state-of-the-art performance in one-shot pruning for diffusion models, achieving improved inference speeds while maintaining high visual quality.
👉 Paper link: https://huggingface.co/papers/2510.06751

17. Revisiting Long-context Modeling from Context Denoising Perspective
🔑 Keywords: Context Denoising Training, Long-context models, contextual noise, critical tokens, Integrated Gradient
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to improve long-context models’ performance by reducing contextual noise and enhancing attention to critical tokens using Context Denoising Training (CDT).
🛠️ Research Methods:
– A fine-grained analysis of context noise is performed, and the Integrated Gradient (IG) score is proposed to detect and quantify noise information within the context. Extensive experiments are conducted across four tasks under different settings.
💬 Research Conclusions:
– The study concludes that mitigating detected context noise significantly enhances model attention and predictions. CDT allows an open-source 8B model to achieve near-GPT-4o performance.
👉 Paper link: https://huggingface.co/papers/2510.05862

18. When Benchmarks Age: Temporal Misalignment through Large Language Model Factuality Evaluation
🔑 Keywords: LLM factuality, factuality benchmarks, benchmark aging, AI Native
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study investigates the aging of factuality benchmarks and its impact on evaluating the factuality of large language models (LLMs), revealing significant unreliability due to outdated samples.
🛠️ Research Methods:
– The research conducts a systematic examination of five popular factuality benchmarks and eight LLMs released over different years.
– An updated fact retrieval pipeline and three metrics were developed to quantify benchmark aging and its impact on LLM factuality evaluation.
💬 Research Conclusions:
– The study highlights that a significant portion of samples in widely used factuality benchmarks is outdated, leading to unreliable assessments of LLM factuality.
– The research provides a testbed to assess the reliability of benchmarks for LLM factuality evaluation and encourages further research on the benchmark aging issue.
👉 Paper link: https://huggingface.co/papers/2510.07238

19. StaMo: Unsupervised Learning of Generalizable Robot Motion from Compact State Representation
🔑 Keywords: Unsupervised learning, Diffusion Transformer, State representation, Latent action, Robotic performance
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective is to develop a highly compressed state representation for efficient world modeling and decision-making in robotic systems.
🛠️ Research Methods:
– Utilizes a lightweight encoder paired with a pre-trained Diffusion Transformer decoder to learn a two-token state representation in an unsupervised manner.
💬 Research Conclusions:
– The method, named StaMo, improves LIBERO performance by 14.3% and real-world task success by 30%, revealing the capacity to decode latent actions from static images and enhancing policy co-training by 10.4%.
👉 Paper link: https://huggingface.co/papers/2510.05057

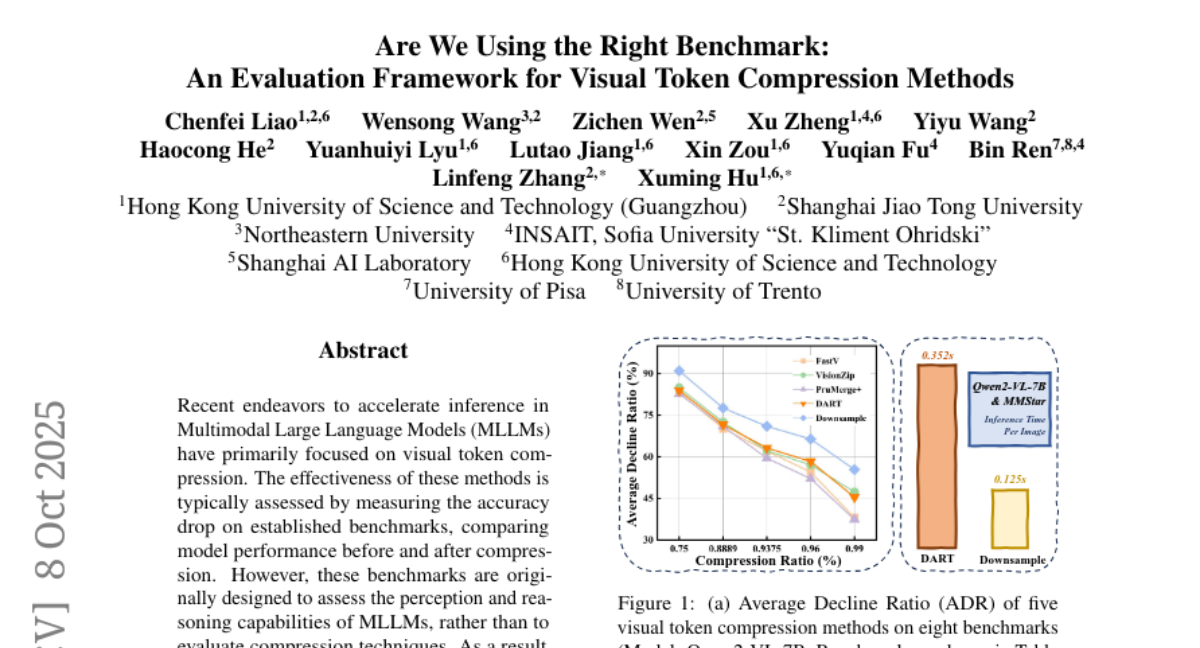
20. Are We Using the Right Benchmark: An Evaluation Framework for Visual Token Compression Methods
🔑 Keywords: Visual Token Compression, VTC-Bench, Data Filtering Mechanism, Multimodal Large Language Models, Image Downsampling
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces VTC-Bench, an evaluation framework designed to provide a fair assessment of visual token compression techniques by incorporating a data filtering mechanism to reduce noise in existing benchmarks.
🛠️ Research Methods:
– The study involves extensive experiments comparing advanced compression methods with simple image downsampling, revealing that many benchmarks are noisy for the visual token compression task, and downsampling can effectively evaluate sample difficulty.
💬 Research Conclusions:
– Current benchmarks are mismatched for evaluating visual token compression, and simple downsampling often outperforms advanced methods. VTC-Bench addresses these issues by providing a denoised evaluation framework, ensuring fairer assessments of visual token compression techniques.
👉 Paper link: https://huggingface.co/papers/2510.07143
21. Patch-as-Decodable-Token: Towards Unified Multi-Modal Vision Tasks in MLLMs
🔑 Keywords: Multimodal Large Language Models, Patch-as-Decodable Token, Visual Reference Tokens, State-of-the-Art Performance, Supervised Fine-Tuning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce the Patch-as-Decodable Token (PaDT) paradigm to enhance multimodal large language models (MLLMs) for direct generation of textual and visual outputs.
🛠️ Research Methods:
– Employ Visual Reference Tokens (VRTs) derived from visual patch embeddings, and transform outputs using a lightweight decoder for detection, segmentation, and grounding predictions.
– Utilize a tailored training strategy with random VRT selection and per-token cross-entropy loss for supervised fine-tuning.
💬 Research Conclusions:
– PaDT achieves state-of-the-art performance in visual perception and understanding tasks, outperforming significantly larger MLLM models.
👉 Paper link: https://huggingface.co/papers/2510.01954

22. TTRV: Test-Time Reinforcement Learning for Vision Language Models
🔑 Keywords: Reinforcement Learning, Vision Language Understanding, Test-Time Reinforcement Learning, Object Recognition, Visual Question Answering
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance vision language understanding by adapting models without labeled data during inference.
🛠️ Research Methods:
– Utilize a modified Group Relative Policy Optimization (GRPO) framework with rewards based on output frequency and entropy management to boost performance during test-time.
💬 Research Conclusions:
– TTRV significantly improves object recognition and VQA performance, surpassing GPT-4o in image recognition, demonstrating the potential of test-time reinforcement learning to compete with advanced proprietary models.
👉 Paper link: https://huggingface.co/papers/2510.06783

23. G^2RPO: Granular GRPO for Precise Reward in Flow Models
🔑 Keywords: Granular-GRPO, reinforcement learning, denoising process, reward assessment, Multi-Granularity Advantage Integration
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Develop a novel Granular-GRPO framework to enhance reinforcement learning in diffusion and flow models, by improving reward assessment and reducing bias in the denoising process.
🛠️ Research Methods:
– Utilize Singular Stochastic Sampling and Multi-Granularity Advantage Integration to optimize reward correlation with noise and provide comprehensive advantage evaluation through multi-scale diffusion.
💬 Research Conclusions:
– The G^2RPO framework significantly outperforms existing GRPO baselines in experiments, demonstrating its effectiveness and robustness in both in-domain and out-of-domain evaluations.
👉 Paper link: https://huggingface.co/papers/2510.01982

24. MLE-Smith: Scaling MLE Tasks with Automated Multi-Agent Pipeline
🔑 Keywords: MLE, multi-agent pipeline, generate-verify-execute, interactive execution, real-world datasets
💡 Category: Machine Learning
🌟 Research Objective:
– To automate the creation of high-quality, diverse machine learning engineering (MLE) tasks from raw datasets, improving scalability and maintaining task quality.
🛠️ Research Methods:
– Introduction of MLE-Smith, a fully automated multi-agent pipeline using a generate-verify-execute paradigm to transform raw datasets into competition-style MLE challenges. It features hybrid verification and interactive execution for validating empirical solvability and real-world fidelity.
💬 Research Conclusions:
– MLE-Smith effectively scales MLE tasks while maintaining quality, demonstrated by generating 606 tasks from 224 real-world datasets. The correlation in performance between MLE-Smith tasks and human-designed tasks for eight language models highlights the system’s effectiveness and reliability.
👉 Paper link: https://huggingface.co/papers/2510.07307

25. WristWorld: Generating Wrist-Views via 4D World Models for Robotic Manipulation
🔑 Keywords: WristWorld, VLA performance, 4D world model, anchor views, wrist-view videos
💡 Category: Computer Vision
🌟 Research Objective:
– The research presents WristWorld, a novel 4D world model designed to generate wrist-view videos solely from anchor views, thus bridging the gap between these two perspectives and enhancing video generation consistency and VLA performance.
🛠️ Research Methods:
– WristWorld operates through two primary stages: (i) Reconstruction, which extends VGGT and introduces Spatial Projection Consistency (SPC) Loss to estimate geometrically consistent wrist-view poses and 4D point clouds; (ii) Generation, using a video generation model to create temporally coherent wrist-view videos from the reconstructed perspectives.
💬 Research Conclusions:
– The experiments conducted on Droid, Calvin, and Franka Panda datasets demonstrate that WristWorld achieves state-of-the-art video generation with enhanced spatial consistency, improving VLA performance. It increases the average task completion length on Calvin by 3.81% and reduces 42.4% of the anchor-wrist view gap.
👉 Paper link: https://huggingface.co/papers/2510.07313

26. Reinforcement Mid-Training
🔑 Keywords: Reinforcement mid-training, Imbalanced token entropy, Dynamic token budget, Curriculum-based adaptive sampling, Dual training strategy
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to introduce a reinforcement mid-training (RMT) framework to enhance large language models by overcoming inefficiencies and underutilization of token information for improved performance.
🛠️ Research Methods:
– The study proposes RMT as a new training stage with innovative components such as a dynamic token budget mechanism, curriculum-based adaptive sampling, and a dual training strategy combining reinforcement learning with next-token prediction.
💬 Research Conclusions:
– RMT shows significant improvements over existing methods, with up to 64.91% performance enhancement using only 21% of the typical reasoning length in language modeling, and further benefits post-training, improving results in the mathematical domain by up to 18.76%.
👉 Paper link: https://huggingface.co/papers/2509.24375

27. Revisiting the Uniform Information Density Hypothesis in LLM Reasoning Traces
🔑 Keywords: Uniform Information Density, large language model, reasoning quality, entropy-based stepwise information density, global uniformity scores
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the impact of step-level uniformity in information density on the reasoning accuracy of large language models.
🛠️ Research Methods:
– Introduce entropy-based stepwise information density metric and propose local and global uniformity scores for evaluating reasoning quality.
💬 Research Conclusions:
– Step-level uniformity in information density improves reasoning accuracy by 10-32% on various benchmarks and serves as a robust predictor of reasoning quality.
– Correct reasoning traces typically avoid sharp information density spikes; incorrect ones display irregular information bursts.
👉 Paper link: https://huggingface.co/papers/2510.06953

28. Heptapod: Language Modeling on Visual Signals
🔑 Keywords: Heptapod, Image Autoregressive Model, Causal Attention, Next 2D Distribution Prediction, ImageNet
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Heptapod, a new image autoregressive model that combines causal attention and next 2D distribution prediction to improve image generation.
🛠️ Research Methods:
– Deploy causal Transformers with a reconstruction-focused visual tokenizer to predict distributions over the entire 2D spatial grid of images, unifying sequential modeling with holistic self-supervised learning.
💬 Research Conclusions:
– Heptapod achieves a notably superior FID score of 2.70 on the ImageNet benchmark, outperforming previous causal autoregressive methods, and motivates rethinking language modeling on visual signals.
👉 Paper link: https://huggingface.co/papers/2510.06673

29. Online Generic Event Boundary Detection
🔑 Keywords: Online Generic Event Boundary Detection, Event Segmentation Theory, prediction error, streaming videos, real-time
💡 Category: Computer Vision
🌟 Research Objective:
– The research introduces Online Generic Event Boundary Detection (On-GEBD) to identify event boundaries instantly in streaming videos based on human perception.
🛠️ Research Methods:
– Utilizes a novel framework, Estimator, inspired by Event Segmentation Theory, integrating Consistent Event Anticipator (CEA) and Online Boundary Discriminator (OBD) to predict future frames and measure prediction errors adaptively.
💬 Research Conclusions:
– Estimator surpasses all baselines from recent models and offers results comparable to existing offline-GEBD methods on Kinetics-GEBD and TAPOS datasets.
👉 Paper link: https://huggingface.co/papers/2510.06855
