AI Native Daily Paper Digest – 20251028

1. Concerto: Joint 2D-3D Self-Supervised Learning Emerges Spatial Representations
🔑 Keywords: Concerto, 3D self-distillation, 2D-3D joint embedding, open-world perception, scene understanding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces Concerto, a minimalist model aiming to simulate human concept learning for spatial cognition by integrating 3D self-distillation with 2D-3D joint embedding.
🛠️ Research Methods:
– The model uses a combination of 3D intra-modal self-distillation and 2D-3D cross-modal joint embedding to achieve superior spatial feature learning.
💬 Research Conclusions:
– Concerto outperforms existing state-of-the-art models in scene understanding and open-world perception, achieving new benchmarks in multiple scene understanding tasks with notable improvements in coherence and fine-grained geometric and semantic consistency.
👉 Paper link: https://huggingface.co/papers/2510.23607

2. ReCode: Unify Plan and Action for Universal Granularity Control
🔑 Keywords: Recursive Code Generation, Decision Granularity, Data Efficiency, LLM-based Agents, High-Level Planning
💡 Category: Foundations of AI
🌟 Research Objective:
– To address the limitation in LLM-based agents by unifying planning and action within a single code representation through a new paradigm called ReCode.
🛠️ Research Methods:
– Proposed a unified representation where high-level plans are abstract placeholder functions decomposed into sub-functions until reaching primitive actions, allowing for dynamic decision granularity.
💬 Research Conclusions:
– ReCode significantly surpasses advanced baselines in inference performance and demonstrates exceptional data efficiency, validating the effectiveness of unifying planning and action for universal granularity control.
👉 Paper link: https://huggingface.co/papers/2510.23564

3. A Survey of Data Agents: Emerging Paradigm or Overstated Hype?
🔑 Keywords: Data Agents, AI Ecosystems, Autonomy Levels, Hierarchical Taxonomy, Generative Data Agents
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study aims to introduce a systematic hierarchical taxonomy for clarifying the autonomy levels and capabilities of data agents, addressing terminological ambiguities and guiding future research.
🛠️ Research Methods:
– The research employs the SAE J3016 standard as inspiration to establish a six-level classification system for data agents, delineating shifts from manual operations to fully autonomous systems.
💬 Research Conclusions:
– The paper provides a structured review of existing research on data agents, identifying critical evolutionary leaps and technical gaps, particularly the transition from procedural execution to autonomous orchestration. It concludes with a roadmap for the development of proactive, generative data agents.
👉 Paper link: https://huggingface.co/papers/2510.23587

4. FARMER: Flow AutoRegressive Transformer over Pixels
🔑 Keywords: FARMER, Normalizing Flows, Autoregressive models, self-supervised dimension reduction, image synthesis
💡 Category: Generative Models
🌟 Research Objective:
– Introduce FARMER, a framework combining Normalizing Flows and Autoregressive models, for effective image synthesis from raw pixels.
🛠️ Research Methods:
– Utilizes an invertible autoregressive flow to transform images into latent sequences.
– Implements a self-supervised dimension reduction scheme to handle redundancy and complexity in pixel-level modeling.
– Develops a one-step distillation scheme and a resampling-based classifier-free guidance algorithm to enhance image generation quality and accelerate inference speed.
💬 Research Conclusions:
– FARMER achieves competitive performance in image synthesis compared to existing pixel-based generative models while maintaining exact likelihoods and scalable training.
👉 Paper link: https://huggingface.co/papers/2510.23588

5. VITA-E: Natural Embodied Interaction with Concurrent Seeing, Hearing, Speaking, and Acting
🔑 Keywords: VITA-E, dual-model architecture, embodied interaction, Vision-Language-Action, emergency stops
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The study introduces VITA-E, a novel embodied interaction framework designed to enhance real-time user interaction and multitasking through a dual-model architecture, mitigating limitations in current Vision-Language-Action (VLA) models.
🛠️ Research Methods:
– Utilization of a dual-model structure with “Active” and “Standby” models for concurrent and interruptible operations, and a “model-as-controller” paradigm to integrate system-level commands with model reasoning.
💬 Research Conclusions:
– Experiments on a physical humanoid platform indicate VITA-E’s efficacy in complex interactive scenarios, achieving high success rates in emergency stops and speech interruptions, advancing the development of more capable embodied assistants.
👉 Paper link: https://huggingface.co/papers/2510.21817

6. Lookahead Anchoring: Preserving Character Identity in Audio-Driven Human Animation
🔑 Keywords: Lookahead Anchoring, audio-driven human animation, keyframes, identity preservation, lip synchronization
💡 Category: Computer Vision
🌟 Research Objective:
– To improve audio-driven human animation by enhancing lip synchronization, identity preservation, and visual quality using Lookahead Anchoring.
🛠️ Research Methods:
– Utilizing future keyframes as dynamic guides to act as directional beacons for continuous identity preservation without needing additional keyframe generation.
💬 Research Conclusions:
– Lookahead Anchoring demonstrates superior animation results, maintaining identity through persistent guidance and achieving greater expressivity with controlled temporal lookahead distances.
👉 Paper link: https://huggingface.co/papers/2510.23581

7. ACG: Action Coherence Guidance for Flow-based VLA models
🔑 Keywords: Action Coherence Guidance, Vision-Language-Action models, Diffusion and flow matching models, Imitation learning, Trajectory drift
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce Action Coherence Guidance (ACG), a test-time algorithm, to enhance action coherence in Vision-Language-Action (VLA) models.
🛠️ Research Methods:
– The paper evaluates ACG on RoboCasa, DexMimicGen, and real-world SO-101 tasks, demonstrating its ability to improve action coherence and task success rates without requiring additional training.
💬 Research Conclusions:
– ACG enhances the performance of VLA models by mitigating instability and reducing trajectory drift, crucial for precision in manipulation tasks.
👉 Paper link: https://huggingface.co/papers/2510.22201
8. Open Multimodal Retrieval-Augmented Factual Image Generation
🔑 Keywords: ORIG, Factual Image Generation, Multimodal Models, retrieval-augmented, factual consistency
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introducing ORIG, an agentic open multimodal retrieval-augmented framework to enhance factual consistency and image quality in factual image generation.
🛠️ Research Methods:
– The framework iteratively retrieves and integrates multimodal evidence from the web into prompts, guided by a newly established benchmark, FIG-Eval.
💬 Research Conclusions:
– ORIG significantly improves factual consistency and image quality, demonstrating potential in open multimodal retrieval for factual image generation.
👉 Paper link: https://huggingface.co/papers/2510.22521

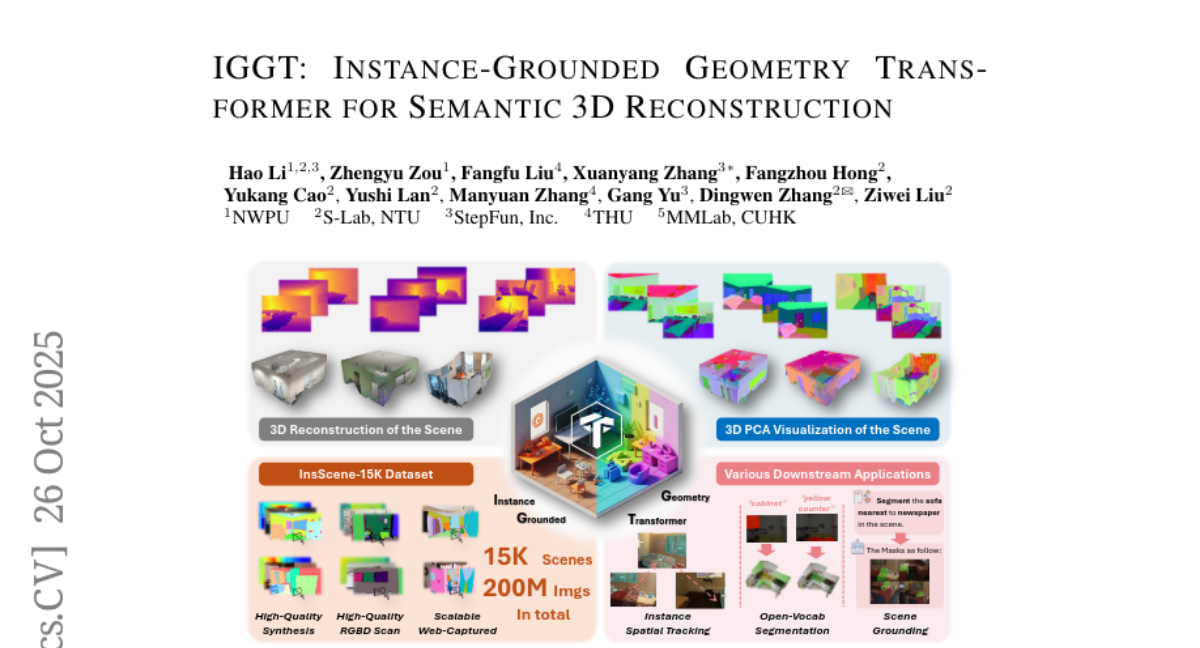
9. IGGT: Instance-Grounded Geometry Transformer for Semantic 3D Reconstruction
🔑 Keywords: InstanceGrounded Geometry Transformer, 3D reconstruction, 3D-Consistent Contrastive Learning, instance-level contextual understanding, InsScene-15K
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to unify 3D reconstruction and instance-level understanding using a novel transformer and contrastive learning approach.
🛠️ Research Methods:
– Introduces a 3D-Consistent Contrastive Learning strategy to encode unified representations from 2D visual inputs, facilitating their transformation into coherent 3D scenes.
– Development of InsScene-15K, a large-scale dataset with high-quality annotations to support this task.
💬 Research Conclusions:
– The proposed InstanceGrounded Geometry Transformer bridges the gap between low-level 3D reconstruction and high-level spatial understanding, enhancing the adaptability and performance of 3D scene analysis tasks.
👉 Paper link: https://huggingface.co/papers/2510.22706
10. E^2Rank: Your Text Embedding can Also be an Effective and Efficient Listwise Reranker
🔑 Keywords: Text embedding models, AI-generated summary, Efficient Embedding-based Ranking, Cosine similarity, State-of-the-art results
💡 Category: Natural Language Processing
🌟 Research Objective:
– This study aims to develop a unified framework, termed E^2Rank, that extends a single text embedding model to efficiently perform both retrieval and listwise reranking, achieving state-of-the-art results with low latency.
🛠️ Research Methods:
– The proposed model, E^2Rank, employs a text embedding model that is trained under a listwise ranking objective. It uses cosine similarity as a unified ranking function and enhances query signals using pseudo-relevance feedback from top-K documents.
💬 Research Conclusions:
– E^2Rank demonstrates state-of-the-art performance on the BEIR reranking benchmark and competitive results on the BRIGHT benchmark, with very low reranking latency. Additionally, the ranking training process enhances embedding performance on the MTEB benchmark, indicating the model’s efficiency and accuracy in unifying retrieval and reranking tasks.
👉 Paper link: https://huggingface.co/papers/2510.22733

11. Omni-Reward: Towards Generalist Omni-Modal Reward Modeling with Free-Form Preferences
🔑 Keywords: Omni-Reward, Reward Models, Modality Imbalance, Preference Rigidity, AI-generated summary
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address challenges in reward models, specifically Modality Imbalance and Preference Rigidity, and to introduce an omni-modal reward model that aligns AI behavior with human preferences.
🛠️ Research Methods:
– Development of Omni-RewardBench, an omni-modal RM benchmark covering multiple modalities and free-form preferences.
– Creation of Omni-RewardData, a comprehensive multimodal preference dataset.
– Proposal of Omni-RewardModel, combining discriminative and generative reward models.
💬 Research Conclusions:
– Omni-Reward approach significantly improves the performance of reward models on both Omni-RewardBench and other well-known reward modeling benchmarks.
👉 Paper link: https://huggingface.co/papers/2510.23451

12. Knocking-Heads Attention
🔑 Keywords: Knocking-heads attention, Multi-head attention, Training dynamics, Cross-head interactions
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to enhance multi-head attention in large language models by proposing Knocking-heads attention (KHA) to facilitate cross-head interactions, thereby addressing the limitation of conventional attention mechanisms.
🛠️ Research Methods:
– The method introduces a shared, diagonally-initialized projection matrix to enable attention heads to interact, integrating KHA seamlessly into existing mechanisms like MHA, GQA, and GTA with minimal additional parameters and computational costs.
💬 Research Conclusions:
– KHA improves training dynamics and performance in large language models, validated by the superior results achieved by a 6.1B parameter MoE model on downstream tasks when compared to baseline attention mechanisms.
👉 Paper link: https://huggingface.co/papers/2510.23052

13. PixelRefer: A Unified Framework for Spatio-Temporal Object Referring with Arbitrary Granularity
🔑 Keywords: PixelRefer, Scale-Adaptive Object Tokenizer (SAOT), Object-Centric Infusion, Multimodal large language models (MLLMs), Object-Only Framework
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This paper introduces PixelRefer, a unified region-level MLLM framework designed to enhance fine-grained, object-centric understanding in visual comprehension tasks.
🛠️ Research Methods:
– The research employs a Scale-Adaptive Object Tokenizer (SAOT) to generate compact object representations and an Object-Centric Infusion module to integrate global context into object tokens, creating an efficient Object-Only Framework.
💬 Research Conclusions:
– PixelRefer achieves leading performance with fewer training samples in benchmarks, and PixelRefer-Lite, its efficient variant, offers competitive accuracy with reduced computational costs, maintaining high semantic fidelity.
👉 Paper link: https://huggingface.co/papers/2510.23603

14. The Best of N Worlds: Aligning Reinforcement Learning with Best-of-N Sampling via max@k Optimisation
🔑 Keywords: Large Language Models, Best-of-N sampling, Reinforcement Learning, RLVR, max@k metric
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To optimize the max@k metric through unbiased gradient estimates in the context of RLVR, improving diversity and performance of Large Language Models in Best-of-N sampling scenarios.
🛠️ Research Methods:
– Introduction of an unbiased on-policy gradient estimate for direct optimization of the max@k metric.
– Extension of methods to off-policy updates for enhanced sample efficiency within modern RLVR algorithms.
💬 Research Conclusions:
– The approach effectively optimizes the max@k metric in off-policy scenarios and aligns the models with Best-of-N inference strategies, enhancing exploration and maintaining performance.
👉 Paper link: https://huggingface.co/papers/2510.23393

15. LightBagel: A Light-weighted, Double Fusion Framework for Unified Multimodal Understanding and Generation
🔑 Keywords: Unified Multimodal Models, Self-Attention Blocks, AI-Generated, Image Editing, Generation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To demonstrate that competitive performance in multimodal models can be achieved with efficient fusion of generation and understanding models using minimal training resources.
🛠️ Research Methods:
– The study employs a strategic fusion of publicly available models specialized for generation or understanding with interleaved multimodal self-attention blocks, using only ~35B tokens.
💬 Research Conclusions:
– The approach yields strong results across multiple benchmarks, achieving impressive scores in tasks such as compositional text-to-image generation and image editing, while supporting future research through the release of code, model weights, and datasets.
👉 Paper link: https://huggingface.co/papers/2510.22946

16. LongCat-Video Technical Report
🔑 Keywords: LongCat-Video, Diffusion Transformer, Video-Continuation, Coarse-to-Fine Generation, Block Sparse Attention
💡 Category: Generative Models
🌟 Research Objective:
– Introduce LongCat-Video, a foundational video generation model with 13.6B parameters, excelling in efficient and high-quality long video generation across multiple tasks.
🛠️ Research Methods:
– Utilizes a unified architecture based on the Diffusion Transformer framework, supporting Text-to-Video, Image-to-Video, and Video-Continuation tasks; employs a coarse-to-fine generation strategy and Block Sparse Attention to enhance efficiency.
💬 Research Conclusions:
– LongCat-Video achieves strong performance with multi-reward RLHF training, maintaining high quality and temporal coherence in long video generation, showing its potential as a step toward world models. The model’s code and weights are available to the public to encourage progress in video generation research.
👉 Paper link: https://huggingface.co/papers/2510.22200

17. LimRank: Less is More for Reasoning-Intensive Information Reranking
🔑 Keywords: LIMRANK-SYNTHESIZER, LIMRANK, Information Reranking, Minimal Supervision, Synthetic Data
💡 Category: Natural Language Processing
🌟 Research Objective:
– To demonstrate that modern LLMs can be effectively adapted for information reranking tasks with minimal, high-quality supervision using LIMRANK-SYNTHESIZER.
🛠️ Research Methods:
– Development of LIMRANK-SYNTHESIZER, an open-source pipeline for creating synthetic data to fine-tune LIMRANK, tested on benchmarks like BRIGHT and FollowIR.
💬 Research Conclusions:
– LIMRANK achieves competitive performance using less than 5% of data typically required, showcasing strong generalization across tasks such as scientific literature search and retrieval-augmented generation.
👉 Paper link: https://huggingface.co/papers/2510.23544

18. Distilled Decoding 2: One-step Sampling of Image Auto-regressive Models with Conditional Score Distillation
🔑 Keywords: Distilled Decoding 2, Image Auto-regressive Models, One-step Sampling, Conditional Score Distillation
💡 Category: Generative Models
🌟 Research Objective:
– The main objective of this research is to propose Distilled Decoding 2 (DD2), which enables efficient one-step sampling for image auto-regressive (AR) models with minimal performance degradation.
🛠️ Research Methods:
– The study introduces a novel method of conditional score distillation loss. A separate network is trained to predict the conditional score of the generated distribution, applying score distillation at every token position conditioned on previous tokens.
💬 Research Conclusions:
– DD2 demonstrates a significant improvement, reducing the performance gap by 67% compared to baseline methods like DD1. Additionally, it achieves up to 12.3 times training speed-up, marking progress towards fast and high-quality image AR generation.
👉 Paper link: https://huggingface.co/papers/2510.21003

19. Code Aesthetics with Agentic Reward Feedback
🔑 Keywords: Large Language Models, agentic reward feedback, instruction-tuning, code aesthetics, reinforcement learning
💡 Category: Generative Models
🌟 Research Objective:
– The primary aim is to enhance the aesthetic quality of LLM-generated code through a new pipeline involving instruction-tuning, agentic reward feedback, and joint optimization.
🛠️ Research Methods:
– Construction of AesCode-358K, a large-scale dataset focused on code aesthetics.
– Development of a multi-agent system providing agentic reward feedback to evaluate various aesthetic aspects.
– Integration of these feedback signals into the GRPO algorithm for joint optimization of code functionality and aesthetics.
💬 Research Conclusions:
– The approach significantly improves performance on the OpenDesign benchmark, surpassing existing models like GPT-4o and GPT-4.1. Additionally, it shows enhanced results on PandasPlotBench, demonstrating improvements due to supervised fine-tuning and reinforcement learning.
👉 Paper link: https://huggingface.co/papers/2510.23272

20. MergeMix: A Unified Augmentation Paradigm for Visual and Multi-Modal Understanding
🔑 Keywords: MergeMix, vision-language alignment, multi-modal large language models, attention-aware image mixing, preference-driven training
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to enhance vision-language alignment in multi-modal large language models (MLLMs) by introducing a new training-time augmentation method called MergeMix to improve efficiency and accuracy.
🛠️ Research Methods:
– MergeMix combines attention-aware image mixing and preference-driven training by creating preference pairs with mixed and raw images, optimized through SimPO loss. It bridges supervised fine-tuning (SFT) and reinforcement learning (RL) approaches.
💬 Research Conclusions:
– MergeMix surpasses heuristic-based methods in classification accuracy and offers a scalable approach to preference alignment in DMLMs, achieving competitive accuracy with improved efficiency.
👉 Paper link: https://huggingface.co/papers/2510.23479

21. RobotArena infty: Scalable Robot Benchmarking via Real-to-Sim Translation
🔑 Keywords: robot generalists, simulation benchmarks, human feedback, vision-language models, digital twins
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To introduce a new benchmarking framework using large-scale simulated environments with human feedback to evaluate robot policies.
🛠️ Research Methods:
– Utilizes advances in vision-language models, 2D-to-3D generative modeling, and differentiable rendering to convert video demonstrations into simulated counterparts.
– Implements automated VLM-guided scoring and scalable human preference judgments to evaluate policies.
💬 Research Conclusions:
– Provides a scalable and reproducible benchmark for robot manipulation policies trained in real-world scenarios, enhancing testing efficiency and safety.
👉 Paper link: https://huggingface.co/papers/2510.23571
22. Language Server CLI Empowers Language Agents with Process Rewards
🔑 Keywords: Language Server Protocol, coding agents, CI, deterministic workflows, process reward
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop Lanser-CLI, a CLI-first orchestration layer for Language Server Protocol servers, enhancing coding agent capabilities and continuous integration (CI) through deterministic workflows and verified code facts.
🛠️ Research Methods:
– Utilized a Selector DSL for robust addressing, implemented deterministic Analysis Bundles for Language Server responses, introduced a safety envelope for mutating operations, and derived a process-reward functional computable and replayable for analysis.
💬 Research Conclusions:
– Lanser-CLI provides actionable process rewards aligning agent planning with code realities and delivers a mechanism formalizing determinism and monotonicity for process supervision and counterfactual analysis.
👉 Paper link: https://huggingface.co/papers/2510.22907

23. VoMP: Predicting Volumetric Mechanical Property Fields
🔑 Keywords: Geometry Transformer, 3D objects, Young’s modulus, material latent codes, AI-generated summary
💡 Category: Machine Learning
🌟 Research Objective:
– The main objective is to develop VoMP, a feed-forward method using a Geometry Transformer, to predict volumetric material properties such as Young’s modulus, Poisson’s ratio, and density in 3D objects.
🛠️ Research Methods:
– VoMP processes and aggregates per-voxel multi-view features to predict material latent codes through a Geometry Transformer, utilizing a real-world dataset for learning physically plausible materials.
💬 Research Conclusions:
– VoMP provides significantly more accurate and faster estimations of volumetric properties than previous methods, supported by a new benchmark and comprehensive experiments.
👉 Paper link: https://huggingface.co/papers/2510.22975

24. PRISM-Bench: A Benchmark of Puzzle-Based Visual Tasks with CoT Error Detection
🔑 Keywords: PRISM-Bench, logical consistency, error detection, visual reasoning, multimodal reasoning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The research introduces PRISM-Bench, a new benchmark for evaluating models based on their reasoning processes by identifying errors in step-by-step solutions to visual puzzles.
🛠️ Research Methods:
– PRISM-Bench utilizes puzzle-based visual challenges that require models to identify the first incorrect step in a chain-of-thought, enhancing fine-grained assessment of logical consistency and error detection.
💬 Research Conclusions:
– Evaluations across state-of-the-art multimodal language models reveal a significant gap between fluent generation and faithful reasoning, indicating the necessity for diagnostic evaluation protocols to develop trustworthy models.
👉 Paper link: https://huggingface.co/papers/2510.23594

25. Scaling Laws for Deepfake Detection
🔑 Keywords: scaling laws, deepfake detection, power-law scaling, large language models, ScaleDF
💡 Category: Computer Vision
🌟 Research Objective:
– Analyze scaling laws in deepfake detection using a new large dataset, ScaleDF, which includes over 5.8 million real images and 8.8 million fake images.
🛠️ Research Methods:
– Construct and utilize ScaleDF to observe model performance against varying real image domains and deepfake methods, analyzing power-law scaling effects.
💬 Research Conclusions:
– Observed power-law scaling aiding in forecasting performance and inspiring data-centric countermeasures against deepfake technologies. Also assessed pre-training and data augmentation roles in deepfake detection.
👉 Paper link: https://huggingface.co/papers/2510.16320

26. EchoDistill: Bidirectional Concept Distillation for One-Step Diffusion Personalization
🔑 Keywords: Bidirectional concept distillation, text-to-image (T2I) diffusion models, one-step diffusion personalization (1-SDP), text encoder, adversarial losses
💡 Category: Generative Models
🌟 Research Objective:
– The objective of this research is to enhance one-step text-to-image diffusion models by leveraging a bidirectional concept distillation framework to improve personalization and generative quality.
🛠️ Research Methods:
– A multi-step diffusion model is used as a teacher, and a one-step model as a student. The bidirectional distillation process involves end-to-end training where the concept is distilled from teacher to student and echoed back, optimizing the student with adversarial and alignment losses.
💬 Research Conclusions:
– The EchoDistill framework significantly outperforms existing personalization methods, establishing a new paradigm for rapid and effective personalization in text-to-image diffusion models.
👉 Paper link: https://huggingface.co/papers/2510.20512

27. DiffusionLane: Diffusion Model for Lane Detection
🔑 Keywords: DiffusionLane, diffusion-based model, noisy lane anchors, hybrid diffusion decoder, auxiliary head
💡 Category: Computer Vision
🌟 Research Objective:
– Enhance lane detection by refining noisy lane anchors through a diffusion-based approach and achieving high performance across various benchmarks.
🛠️ Research Methods:
– A novel model called DiffusionLane utilizes Gaussian noise to create noisy lane anchors and refines them progressively.
– Implements a hybrid decoding strategy combining global and local decoders for better feature representation.
– Uses an auxiliary head during training to improve the encoder’s feature representation.
💬 Research Conclusions:
– DiffusionLane shows strong generalization ability and superior detection performance compared to previous state-of-the-art methods across multiple benchmarks.
– Achieves higher accuracy and F1 scores on datasets like Carlane, Tusimple, CULane, and LLAMAS, surpassing existing models by at least 1% in certain cases.
👉 Paper link: https://huggingface.co/papers/2510.22236

28. Once Upon an Input: Reasoning via Per-Instance Program Synthesis
🔑 Keywords: Per-Instance Program Synthesis, Large Language Models, Chain of Thought, structural feedback, zero-shot inference
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces Per-Instance Program Synthesis (PIPS) to enhance the performance of Large Language Models by refining programs at the instance level, aiming to improve accuracy and reduce undesirable solutions.
🛠️ Research Methods:
– PIPS generates and refines instance-level programs using structural feedback, and employs a confidence metric for dynamically choosing between direct inference and program synthesis.
💬 Research Conclusions:
– Experiments demonstrate that PIPS improves the absolute harmonic mean accuracy by up to 8.6% and 9.4% compared to Program of Thought (PoT) and Chain of Thought (CoT) respectively, while reducing undesirable program generations by 65.1% in algorithmic tasks.
👉 Paper link: https://huggingface.co/papers/2510.22849
