AI Native Daily Paper Digest – 20251110
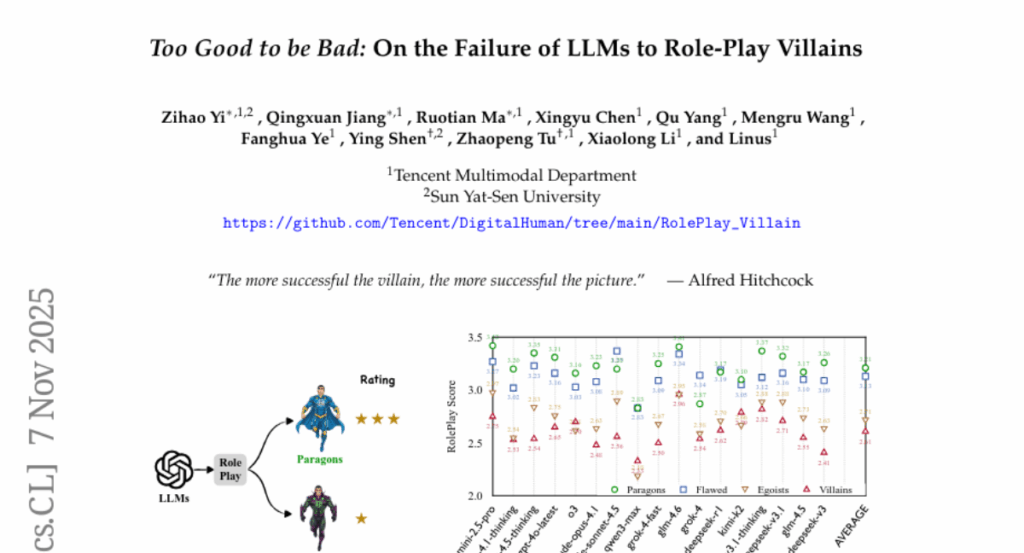
1. Too Good to be Bad: On the Failure of LLMs to Role-Play Villains
🔑 Keywords: Large Language Models, Moral RolePlay Benchmark, Safety Alignment, Creative Fidelity
💡 Category: Generative Models
🌟 Research Objective:
– To examine the ability of Large Language Models (LLMs) to authentically portray morally ambiguous or villainous characters amid safety alignment constraints.
🛠️ Research Methods:
– Introduction of the Moral RolePlay benchmark with a four-level moral alignment scale to evaluate LLMs’ role-playing capabilities, contrasting moral paragons with pure villains.
💬 Research Conclusions:
– The study finds that LLMs consistently struggle with fidelity in portraying characters with decreasing morality.
– Traits like “Deceitful” and “Manipulative” are particularly challenging due to their opposition to safety principles.
– General chatbot proficiency correlates poorly with role-playing villainous characters, especially in highly safety-aligned models.
– The findings highlight a critical conflict between ensuring model safety and maintaining creative fidelity.
👉 Paper link: https://huggingface.co/papers/2511.04962
2. DeepEyesV2: Toward Agentic Multimodal Model
🔑 Keywords: DeepEyesV2, Agentic Multimodal Model, Tool Invocation, Reinforcement Learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To build an agentic multimodal model, DeepEyesV2, that integrates tool use effectively for real-world reasoning tasks.
🛠️ Research Methods:
– Implemented a two-stage training pipeline involving a cold-start stage and reinforcement learning to establish and refine tool-use behavior.
– Introduced RealX-Bench, a benchmark to evaluate multimodal reasoning requiring integration of perception, search, and reasoning capabilities.
💬 Research Conclusions:
– DeepEyesV2 demonstrates robustness in real-world comprehension, mathematical reasoning, and search-intensive tasks.
– It shows task-adaptive tool invocation and can effectively combine tools contextually with reinforcement learning.
👉 Paper link: https://huggingface.co/papers/2511.05271

3. Visual Spatial Tuning
🔑 Keywords: Visual Spatial Tuning, VLMs, spatial perception, spatial reasoning, reinforcement learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to enhance the spatial abilities of Vision-Language Models (VLMs) by developing a framework called Visual Spatial Tuning (VST) that improves spatial perception and reasoning.
🛠️ Research Methods:
– The approach involves using specialized datasets, VST-P and VST-R, containing millions of samples to train the models, utilizing a progressive training pipeline with supervised fine-tuning and reinforcement learning.
💬 Research Conclusions:
– The proposed VST framework achieves state-of-the-art results on spatial benchmarks and significantly enhances the capabilities of Vision-Language-Action models, leading to more physically grounded AI.
👉 Paper link: https://huggingface.co/papers/2511.05491

4. VeriCoT: Neuro-symbolic Chain-of-Thought Validation via Logical Consistency Checks
🔑 Keywords: VeriCoT, Chain-of-Thought, neuro-symbolic method, logical arguments, LLMs
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The objective is to enhance the reliability and accuracy of large language models (LLMs) by formalizing and verifying logical arguments in Chain-of-Thought reasoning.
🛠️ Research Methods:
– The study introduces a neuro-symbolic method called VeriCoT, which extracts and verifies formal logical arguments, using first-order logic and automated solvers to check logical validity.
💬 Research Conclusions:
– VeriCoT effectively identifies flawed reasoning and predicts final answer correctness, demonstrated on datasets like ProofWriter, LegalBench, and BioASQ, with additional improvements via inference-time self-reflection and fine-tuning techniques.
👉 Paper link: https://huggingface.co/papers/2511.04662

5. Dense Motion Captioning
🔑 Keywords: Dense Motion Captioning, 3D human motion, CompMo, temporal boundaries, large language model
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Dense Motion Captioning to temporally localize and caption actions within 3D human motion sequences.
🛠️ Research Methods:
– Developed CompMo, a large-scale dataset with detailed temporal annotations and complex motion sequences.
– Created DEMO, a model integrating a large language model with a motion adapter to generate dense captions.
💬 Research Conclusions:
– DEMO significantly outperforms existing methods on CompMo and adapted benchmarks, setting a new baseline for 3D motion understanding and captioning.
👉 Paper link: https://huggingface.co/papers/2511.05369

6. Towards Mitigating Hallucinations in Large Vision-Language Models by Refining Textual Embeddings
🔑 Keywords: LVLM architectures, language modality, visual embeddings, visual grounding, hallucinations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to address the inherent bias in LVLM architectures toward language modality by refining textual embeddings with visual information.
🛠️ Research Methods:
– A method integrating average-pooled visual features to refine textual embeddings is proposed to improve visual grounding and reduce hallucinations.
💬 Research Conclusions:
– The proposed method significantly improves visual grounding and reduces hallucinations on benchmarks. Despite its effectiveness, more sophisticated fusion methods could further advance these goals, which is suggested for future exploration.
👉 Paper link: https://huggingface.co/papers/2511.05017

7. Real-Time Reasoning Agents in Evolving Environments
🔑 Keywords: Real-Time Reasoning, AgileThinker, AI Systems, Reactive Agents, Planning Agents
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper introduces real-time reasoning as a new problem formulation for agents in dynamic environments, aiming to balance reasoning depth and response latency with AgileThinker.
🛠️ Research Methods:
– The study involves deploying language models using two paradigms: reactive agents for rapid response and planning agents for extended reasoning. The Real-Time Reasoning Gym is developed to evaluate these techniques.
💬 Research Conclusions:
– AgileThinker, which combines both reasoning paradigms, outperforms single-paradigm agents, demonstrating effective balance in reasoning depth and response latency under increased task difficulty and time pressure.
👉 Paper link: https://huggingface.co/papers/2511.04898

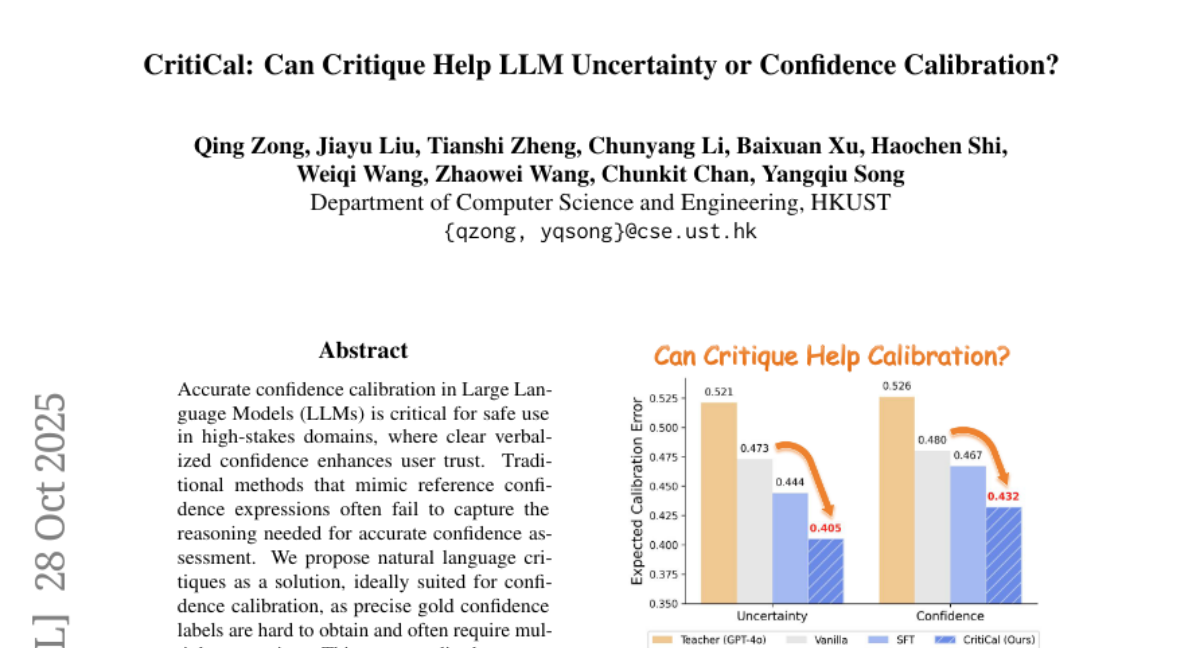
8. CritiCal: Can Critique Help LLM Uncertainty or Confidence Calibration?
🔑 Keywords: Natural language critiques, Confidence calibration, Large Language Models, CritiCal, Self-Critique
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to improve confidence calibration in Large Language Models (LLMs) using natural language critiques, enhancing reliability in high-stakes domains.
🛠️ Research Methods:
– The paper explores the utility of natural language critiques for confidence calibration by analyzing both uncertainty (question-focused) and confidence (answer-specific) critiques, employing methods like Self-Critique and the novel Critique Calibration (CritiCal) training.
💬 Research Conclusions:
– CritiCal outperforms Self-Critique and other baselines, demonstrating robust generalization and surpassing its teacher model, GPT-4o, in complex reasoning tasks, thus enhancing LLM reliability.
👉 Paper link: https://huggingface.co/papers/2510.24505
9. HAFixAgent: History-Aware Automated Program Repair Agent
🔑 Keywords: Automated Program Repair, HAFixAgent, Repository History, Blame-derived Repository Heuristics, Multi-hunk Bugs
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To investigate whether incorporating repository history can improve agent-based APR systems, particularly for complex multi-hunk bugs.
🛠️ Research Methods:
– Develop HAFixAgent, a history-aware bug-fixing agent using blame-derived repository heuristics, and perform empirical comparisons with state-of-the-art baselines.
💬 Research Conclusions:
– HAFixAgent significantly enhances effectiveness and efficiency, repairing more bugs without increasing steps or token costs, and provides a clear cost-benefit trade-off.
👉 Paper link: https://huggingface.co/papers/2511.01047

10. Jailbreaking in the Haystack
🔑 Keywords: NINJA, Jailbreak Attack, Long-Context Language Models, HarmBench, Compute-Optimal
💡 Category: Natural Language Processing
🌟 Research Objective:
– The main goal of the research is to introduce a novel method, NINJA, which appends benign-generated content to harmful goals in long-context language models to study their safety vulnerabilities.
🛠️ Research Methods:
– The NINJA method is demonstrated on a standard safety benchmark called HarmBench, and tested on various state-of-the-art models like LLaMA and Gemini, highlighting its effectiveness, low-resource requirement, transferability, and less detectability compared to prior methods.
💬 Research Conclusions:
– Findings indicate that aligning the position of harmful goals within benign long contexts can reveal significant vulnerabilities in modern language models, showcasing that increasing context length is more effective than merely increasing the number of trials under a fixed compute budget.
👉 Paper link: https://huggingface.co/papers/2511.04707

11.
