AI Native Daily Paper Digest – 20251114

1. One Small Step in Latent, One Giant Leap for Pixels: Fast Latent Upscale Adapter for Your Diffusion Models
🔑 Keywords: Latent Upscaler Adapter, diffusion models, VAE decoding, Swin-style backbone, scalable
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to improve the efficiency of super-resolution in diffusion models by introducing the Latent Upscaler Adapter (LUA) that operates in the latent space to maintain image quality without additional latency.
🛠️ Research Methods:
– LUA integrates as a lightweight module in the latent space of diffusion models. It uses a Swin-style backbone with pixel-shuffle heads, enabling high-resolution synthesis through a single feed-forward pass without modifying base models or additional diffusion stages.
💬 Research Conclusions:
– LUA effectively reduces decoding and upscaling time while maintaining comparable perceptual quality to traditional image-space super-resolution. It generalizes well across different VAEs, simplifying deployment without retraining for new decoders and offers a practical path to scalable high-fidelity image synthesis.
👉 Paper link: https://huggingface.co/papers/2511.10629

2. PAN: A World Model for General, Interactable, and Long-Horizon World Simulation
🔑 Keywords: PAN, Generative Latent Prediction, AI-generated summary, long-horizon consistency, video diffusion decoder
💡 Category: Generative Models
🌟 Research Objective:
– Introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through detailed video simulation.
🛠️ Research Methods:
– Utilize Generative Latent Prediction architecture combining autoregressive latent dynamics with a video diffusion decoder for coherent and detailed simulations.
💬 Research Conclusions:
– PAN achieves strong performance in action-conditioned world simulation and simulative reasoning, advancing toward general world models for predictive simulation.
👉 Paper link: https://huggingface.co/papers/2511.09057

3. UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
🔑 Keywords: UniVA, multi-agent framework, video understanding, Plan-and-Act, hierarchical memory
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to develop UniVA, an open-source multi-agent framework for integrating video tasks like understanding, segmentation, editing, and generation into seamless workflows.
🛠️ Research Methods:
– UniVA employs a Plan-and-Act dual-agent architecture with a planner agent for interpreting user intentions and executor agents for executing structured video-processing steps using MCP-based tool servers.
💬 Research Conclusions:
– UniVA enables complex, iterative video workflows that were difficult to achieve with single-purpose models, and introduces UniVA-Bench to evaluate multi-step video tasks, promoting research on agentic video systems.
👉 Paper link: https://huggingface.co/papers/2511.08521
4. Black-Box On-Policy Distillation of Large Language Models
🔑 Keywords: Generative Adversarial Distillation, black-box distillation, large language models, generator, discriminator
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce and evaluate Generative Adversarial Distillation (GAD) as a new paradigm for black-box distillation of large language models.
🛠️ Research Methods:
– Utilizing a framework where the student model is a generator and a discriminator is used to provide adaptive feedback, forming a minimax game.
💬 Research Conclusions:
– GAD consistently surpasses traditional sequence-level knowledge distillation, enabling student models like Qwen2.5-14B-Instruct to reach performance levels comparable to their teacher models, such as GPT-5-Chat.
👉 Paper link: https://huggingface.co/papers/2511.10643

5. Hail to the Thief: Exploring Attacks and Defenses in Decentralised GRPO
🔑 Keywords: adversarial attacks, Group Relative Policy Optimization, Large Language Models, decentralized training, malicious tokens
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to identify and defend against adversarial attacks in decentralized Group Relative Policy Optimization (GRPO) for Large Language Models (LLMs).
🛠️ Research Methods:
– The authors introduce the first adversarial attack in decentralized GRPO by allowing malicious parties to poison systems through the injection of arbitrary malicious tokens during both out-of-context and in-context attacks.
💬 Research Conclusions:
– The research demonstrates that adversarial attacks can achieve up to 100% success rates in only 50 iterations, but proposes effective defense mechanisms that can stop such attacks entirely.
👉 Paper link: https://huggingface.co/papers/2511.09780

6. Depth Anything 3: Recovering the Visual Space from Any Views
🔑 Keywords: Depth Anything 3, plain transformer, teacher-student training, camera pose estimation, monocular depth estimation
💡 Category: Computer Vision
🌟 Research Objective:
– Depth Anything 3 (DA3) aims to provide state-of-the-art geometry prediction from visual inputs, including tasks such as camera pose estimation and monocular depth estimation.
🛠️ Research Methods:
– Utilizes a plain transformer as the core model architecture to avoid complex multi-task learning, employing a teacher-student training paradigm for enhanced detail and generalization.
💬 Research Conclusions:
– DA3 surpasses previous state-of-the-art models by significant margins in both camera pose and geometric accuracy, and performs better than its predecessor, DA2, in monocular depth estimation, setting new standards in visual geometry benchmarks. All models are trained on public academic datasets.
👉 Paper link: https://huggingface.co/papers/2511.10647

7. Superpositional Gradient Descent: Harnessing Quantum Principles for Model Training
🔑 Keywords: Superpositional Gradient Descent, Quantum Superposition, Large Language Models, Quantum Circuit Perturbations, Hybrid Quantum-Classical Circuits
💡 Category: Quantum Machine Learning
🌟 Research Objective:
– This research introduces a quantum-inspired optimizer, Superpositional Gradient Descent, to improve convergence and reduce final loss in large language model training compared to classical methods like AdamW.
🛠️ Research Methods:
– The study implements a mathematical framework and hybrid quantum-classical circuits using PyTorch and Qiskit, applying these to tasks such as synthetic sequence classification and large-scale LLM fine-tuning.
💬 Research Conclusions:
– Results demonstrate faster convergence and lower final loss with the quantum-inspired approach, though scalability and hardware constraints remain limiting factors. The work opens new insights into leveraging quantum principles in deep learning.
👉 Paper link: https://huggingface.co/papers/2511.01918

8. Solving a Million-Step LLM Task with Zero Errors
🔑 Keywords: MAKER, LLMs, microagents, extreme decomposition, error correction
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To demonstrate a system, MAKER, that scales LLM capabilities by solving tasks with over a million steps using microagents and error correction.
🛠️ Research Methods:
– Utilizing extreme decomposition of tasks into subtasks handled by microagents and applying error correction through a multi-agent voting scheme.
💬 Research Conclusions:
– MAKER successfully solves large tasks with zero errors by employing a massively decomposed agentic process, suggesting a new scalable approach for complex problem-solving at the level of organizations and societies.
👉 Paper link: https://huggingface.co/papers/2511.09030

9. AlphaResearch: Accelerating New Algorithm Discovery with Language Models
🔑 Keywords: AI Native, AlphaResearch, algorithm discovery, LLMs, open-ended problems
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce AlphaResearch, an autonomous research agent, to discover new algorithms in open-ended problems.
🛠️ Research Methods:
– Developed a dual research environment combining execution-based verification and simulated peer review to propose, verify, and optimize new ideas.
💬 Research Conclusions:
– AlphaResearch demonstrated competitive performance against human researchers, achieving a 2/8 win rate in benchmark competitions and excelling in a specific algorithmic problem by surpassing human efforts and established baselines.
👉 Paper link: https://huggingface.co/papers/2511.08522

10. Music Flamingo: Scaling Music Understanding in Audio Language Models
🔑 Keywords: Music Flamingo, audio-language model, music understanding, MF-Skills, GRPO-based reinforcement learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To advance music understanding in audio-language models, overcoming challenges of dynamic, layered, and information-dense music data.
🛠️ Research Methods:
– Fine-tuning the Audio Flamingo 3 model using the MF-Skills dataset.
– Improving reasoning abilities through a post-training process involving MF-Think and GRPO-based reinforcement learning.
💬 Research Conclusions:
– Music Flamingo achieves state-of-the-art results in multiple benchmarks, demonstrating advanced music understanding and setting new standards for perceiving songs in a human-like manner.
👉 Paper link: https://huggingface.co/papers/2511.10289

11. Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
🔑 Keywords: AdvancedIF, RIFL, instruction following, reinforcement learning, rubrics
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to improve instruction-following capabilities in large language models through the introduction of AdvancedIF benchmark and RIFL pipeline, focusing on complex, multi-turn, and system-level instructions.
🛠️ Research Methods:
– Introduction of AdvancedIF, a benchmark with over 1,600 prompts and expert-curated rubrics to evaluate LLMs.
– Proposal of RIFL, a post-training pipeline leveraging rubric generation, a finetuned rubric verifier, and reward shaping to enhance reinforcement learning for instruction following.
💬 Research Conclusions:
– Extensive experiments show that RIFL significantly enhances instruction-following abilities in LLMs, with a 6.7% absolute gain on AdvancedIF and strong performance on public benchmarks.
– The study confirms the effectiveness of rubrics as a tool for training and evaluating advanced instruction-following in LLMs.
👉 Paper link: https://huggingface.co/papers/2511.10507

12. ResearchRubrics: A Benchmark of Prompts and Rubrics For Evaluating Deep Research Agents
🔑 Keywords: Deep Research, Large Language Models, Multi-step Reasoning, ResearchRubrics, Evaluation
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce ResearchRubrics, a benchmark for assessing deep research agents using expert rubrics to evaluate factual grounding, reasoning, and clarity.
🛠️ Research Methods:
– Utilize over 2,800 hours of human labor to create domain-diverse prompts and over 2,500 expert-written rubrics. Develop a complexity framework for categorizing tasks and propose evaluation protocols for measuring rubric adherence.
💬 Research Conclusions:
– Leading DR agents like Gemini’s DR and OpenAI’s DR show under 68% compliance with ResearchRubrics due to missed implicit context and inadequate reasoning, highlighting a need for improved assessment tools in advancing justified research assistants.
👉 Paper link: https://huggingface.co/papers/2511.07685

13. Benchmarking Diversity in Image Generation via Attribute-Conditional Human Evaluation
🔑 Keywords: diversity evaluation, text-to-image models, human evaluation template, factors of variation, image embeddings
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a framework to systematically evaluate diversity in text-to-image (T2I) models, addressing their tendency to produce homogeneous outputs.
🛠️ Research Methods:
– Develop a novel human evaluation template for diversity assessment.
– Create a curated prompt set that covers diverse concepts with identified factors of variation.
– Use binomial tests for comparing models based on human annotations.
– Conduct a rigorous comparison of various image embeddings for measuring diversity.
💬 Research Conclusions:
– Provide a principled approach for ranking T2I models by diversity, highlighting categories where they particularly struggle, and paving the way for improvements in model diversity and metric development.
👉 Paper link: https://huggingface.co/papers/2511.10547

14. AffordBot: 3D Fine-grained Embodied Reasoning via Multimodal Large Language Models
🔑 Keywords: AffordBot, Multimodal Large Language Models, chain-of-thought reasoning, 3D Embodied Reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This research introduces Fine-grained 3D Embodied Reasoning, which aims for agents to predict spatial locations, motion types, and axes of affordance elements in 3D scenes based on task instructions.
🛠️ Research Methods:
– The study proposes a novel framework named AffordBot, which combines Multimodal Large Language Models (MLLMs) with a tailored chain-of-thought reasoning paradigm. It integrates active perception and surround-view images to bridge the gap between 3D input and 2D-compatible MLLMs.
💬 Research Conclusions:
– AffordBot achieves state-of-the-art performance on the SceneFun3D dataset, demonstrating strong generalization and physically grounded reasoning with 3D point cloud input.
👉 Paper link: https://huggingface.co/papers/2511.10017

15. MuSc-V2: Zero-Shot Multimodal Industrial Anomaly Classification and Segmentation with Mutual Scoring of Unlabeled Samples
🔑 Keywords: Zero-shot anomaly detection, Mutual Scoring framework, 3D representation, Similarity Neighborhood Aggregation, Cross-modal Anomaly Enhancement
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to improve zero-shot anomaly classification (AC) and segmentation (AS) by unveiling overlooked properties in 2D and 3D data, addressing the diversity and isolation of anomalies compared to normal patches.
🛠️ Research Methods:
– The study introduces the MuSc-V2 framework, leveraging Mutual Scoring and techniques like Iterative Point Grouping (IPG) and Similarity Neighborhood Aggregation (SNAMD) to enhance discriminative capabilities across modalities.
💬 Research Conclusions:
– The MuSc-V2 framework demonstrates significant performance improvements, notably achieving a +23.7% AP gain on the MVTec 3D-AD dataset and a +19.3% boost on the Eyecandies dataset, outperforming existing zero-shot and most few-shot methods.
👉 Paper link: https://huggingface.co/papers/2511.10047

16. CC30k: A Citation Contexts Dataset for Reproducibility-Oriented Sentiment Analysis
🔑 Keywords: CC30k dataset, reproducibility-oriented sentiments, citation contexts, large language models, data cleansing
💡 Category: Machine Learning
🌟 Research Objective:
– The creation of the CC30k dataset aimed at improving the accuracy of large language models in predicting the reproducibility of machine learning papers based on reproducibility-oriented sentiments.
🛠️ Research Methods:
– The dataset comprises 30,734 citation contexts labeled with sentiments towards reproducibility, achieved through crowdsourcing and a controlled pipeline for generating negative labels. It includes data cleansing, crowd selection, and thorough validation processes.
💬 Research Conclusions:
– The CC30k dataset significantly enhances the performance of large language models in classifying reproducibility-oriented sentiments, with a demonstrated labeling accuracy of 94%. This dataset lays the foundation for large-scale assessments of machine learning paper reproducibility.
👉 Paper link: https://huggingface.co/papers/2511.07790

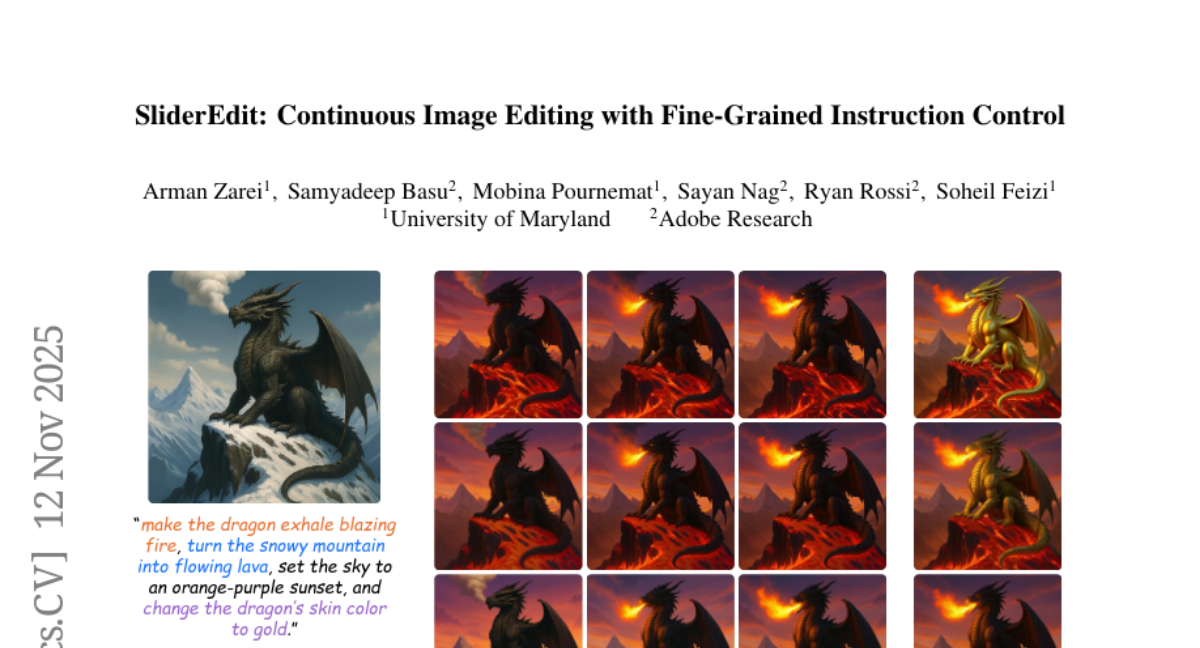
17. SliderEdit: Continuous Image Editing with Fine-Grained Instruction Control
🔑 Keywords: SliderEdit, fine-grained instruction control, image editing, AI-generated summary
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to introduce SliderEdit, a framework for continuous, fine-grained control over image editing instructions using low-rank adaptation matrices, enhancing edit controllability, visual consistency, and user steerability.
🛠️ Research Methods:
– Development of a globally trained slider system within SliderEdit, allowing smooth adjustment of edit strength across diverse attributes without requiring separate training or fine-tuning for each attribute.
💬 Research Conclusions:
– The implementation of SliderEdit in state-of-the-art image editing models, such as FLUX-Kontext and Qwen-Image-Edit, shows substantial improvements in edit controllability, visual consistency, and user steerability, paving the way for interactive, instruction-driven image manipulation.
👉 Paper link: https://huggingface.co/papers/2511.09715
18.
