AI Native Daily Paper Digest – 20251126

1. GigaEvo: An Open Source Optimization Framework Powered By LLMs And Evolution Algorithms
🔑 Keywords: GigaEvo, LLM-guided evolutionary computation, AlphaEvolve, open-source framework, MAP-Elites
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To present GigaEvo, an open-source framework for studying and experimenting with hybrid Large Language Model (LLM)-evolution approaches inspired by AlphaEvolve.
🛠️ Research Methods:
– Implementation of modular components such as MAP-Elites quality-diversity algorithms, asynchronous DAG-based evaluation pipelines, and LLM-driven mutation operators.
– Evaluation of GigaEvo on challenging problems like Heilbronn triangle placement, circle packing in squares, and high-dimensional kissing numbers.
💬 Research Conclusions:
– GigaEvo effectively supports reproducibility and further research in LLM-driven evolutionary methods through its modularity, concurrency, and ease of experimentation.
👉 Paper link: https://huggingface.co/papers/2511.17592

2. MedSAM3: Delving into Segment Anything with Medical Concepts
🔑 Keywords: MedSAM-3, AI-Generated Summary, Multimodal Large Language Models, Medical Segmentation, SAM 3 Architecture
💡 Category: AI in Healthcare
🌟 Research Objective:
– The objective is to propose a text-promptable medical segmentation model, MedSAM-3, designed to enhance performance across different medical imaging modalities by utilizing semantic conceptual labels and large language models.
🛠️ Research Methods:
– MedSAM-3 builds on the Segment Anything Model (SAM) 3 architecture, fine-tuning it with medical images and supplemented by an innovative framework that incorporates Multimodal Large Language Models for complex reasoning and refinement.
💬 Research Conclusions:
– MedSAM-3 significantly outperforms existing models in medical image segmentation across several modalities, including X-ray, MRI, Ultrasound, CT, and video. The approach allows precise anatomical targeting through open-vocabulary text descriptions, and the code is made available for public use on GitHub.
👉 Paper link: https://huggingface.co/papers/2511.19046

3. SteadyDancer: Harmonized and Coherent Human Image Animation with First-Frame Preservation
🔑 Keywords: Image-to-Video, Motion Control, Identity Preservation, SteadyDancer
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to develop an Image-to-Video framework, SteadyDancer, that ensures first-frame identity preservation and precise motion control.
🛠️ Research Methods:
– Introduced a Condition-Reconciliation Mechanism for harmonizing conditions, Synergistic Pose Modulation Modules for adaptive pose representation, and a Staged Decoupled-Objective Training Pipeline for model optimization.
💬 Research Conclusions:
– SteadyDancer achieves state-of-the-art performance in appearance fidelity and motion control, requiring fewer training resources compared to existing methods.
👉 Paper link: https://huggingface.co/papers/2511.19320

4. Agent0-VL: Exploring Self-Evolving Agent for Tool-Integrated Vision-Language Reasoning
🔑 Keywords: self-evolution, tool-integrated reasoning, reinforcement learning, vision-language agent
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop Agent0-VL, a self-evolving vision-language agent that incorporates tool usage in both reasoning and self-evaluation for continuous improvement without human-annotated supervision.
🛠️ Research Methods:
– Implemented tool-integrated reasoning and self-repair within Agent0-VL, enabling it to introspect, verify, and refine its reasoning through evidence-grounded analysis and a Self-Evolving Reasoning Cycle.
💬 Research Conclusions:
– Agent0-VL successfully aligns reasoning and verification behaviors without external rewards, achieving a 12.5% improvement over the base model in geometric problem-solving and visual scientific analysis tasks.
👉 Paper link: https://huggingface.co/papers/2511.19900

5. iMontage: Unified, Versatile, Highly Dynamic Many-to-many Image Generation
🔑 Keywords: iMontage, Pre-trained Video Models, Image Generation, Temporal Coherence, Unified Framework
💡 Category: Generative Models
🌟 Research Objective:
– The main objective is to repurpose pre-trained video models to generate high-quality, diverse image sets with natural transitions and enhanced dynamics through iMontage, a unified framework.
🛠️ Research Methods:
– Utilization of a minimally invasive adaptation strategy, tailored data curation, and a tailored training paradigm to generate variable-length image sets without compromising original motion priors.
💬 Research Conclusions:
– iMontage successfully excels in many-in-many-out tasks, maintaining strong cross-image contextual consistency while generating scenes with superior dynamics that exceed conventional scopes.
👉 Paper link: https://huggingface.co/papers/2511.20635

6. Does Understanding Inform Generation in Unified Multimodal Models? From Analysis to Path Forward
🔑 Keywords: Unified Multimodal Models, understanding-generation gap, Chain-of-Thought, self-training, knowledge transfer
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to explore the gap between understanding and generation in Unified Multimodal Models and proposes methods to bridge this understanding-generation gap.
🛠️ Research Methods:
– Utilizes a decoupled evaluation framework named UniSandbox alongside controlled, synthetic datasets to avoid data leakage and enable a detailed analysis of the understanding-generation gap.
💬 Research Conclusions:
– Identifies a significant gap in reasoning generation and knowledge transfer, where explicit Chain-of-Thought (CoT) and self-training effectively bridge this gap. CoT also assists in knowledge transfer by enabling newly learned knowledge retrieval.
– Highlights that query-based architectures inherently have latent CoT-like properties beneficial for knowledge transfer.
👉 Paper link: https://huggingface.co/papers/2511.20561

7. Soft Adaptive Policy Optimization
🔑 Keywords: Soft Adaptive Policy Optimization, Reinforcement Learning, Large Language Models, Token-Adaptive, Training Stability
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to enhance the stability and performance of reinforcement learning in large language models through Soft Adaptive Policy Optimization (SAPO), which addresses the challenges of policy optimization by using a smooth, temperature-controlled gate.
🛠️ Research Methods:
– SAPO adapts existing policy optimization methods by replacing hard clipping with a token-adaptive and sequence-coherent approach, improving sample efficiency and consistency in performance across various model sizes and tasks.
💬 Research Conclusions:
– SAPO demonstrates improved training stability and higher Pass@1 performance compared to existing methods like GSPO and GRPO, and it offers a reliable, scalable strategy for RL training in LLMs, extending benefits to models such as the Qwen3-VL series.
👉 Paper link: https://huggingface.co/papers/2511.20347

8. SSA: Sparse Sparse Attention by Aligning Full and Sparse Attention Outputs in Feature Space
🔑 Keywords: Sparse Attention, Large Language Models (LLMs), Gradient Update Deficiency, Bidirectional Alignment, Long-Context Extrapolation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces SSA, a unified training framework designed to achieve state-of-the-art performance by aligning sparse attention with full attention to enhance long-context processing and extrapolation.
🛠️ Research Methods:
– SSA employs bidirectional alignment at every layer, ensuring gradient flow to all tokens and encouraging sparse-attention outputs to align with full-attention counterparts.
💬 Research Conclusions:
– SSA achieves superior performance in both sparse and full attention inference across multiple benchmarks, allowing models to adapt to varying sparsity budgets and improving long-context extrapolation by addressing gradient update deficiencies.
👉 Paper link: https://huggingface.co/papers/2511.20102

9. GigaWorld-0: World Models as Data Engine to Empower Embodied AI
🔑 Keywords: GigaWorld-0, Vision-Language-Action, 3D generative modeling, embodied AI, physically plausible
💡 Category: Generative Models
🌟 Research Objective:
– Development of GigaWorld-0, a framework integrating video generation and 3D modeling for Vision-Language-Action learning in embodied AI, aimed at enhancing real-world performance without using real-world training data.
🛠️ Research Methods:
– Utilization of GigaWorld-0 framework comprising GigaWorld-0-Video for scalable, controllable video generation, and GigaWorld-0-3D for ensuring geometric and physical realism of generated data through 3D generative modeling and reconstructions.
💬 Research Conclusions:
– GigaWorld-0 generates high-quality and diverse data, providing substantial improvements in generalization and task success in physical robots, highlighting its effectiveness as a data engine for training Vision-Language-Action models.
👉 Paper link: https://huggingface.co/papers/2511.19861

10. UltraViCo: Breaking Extrapolation Limits in Video Diffusion Transformers
🔑 Keywords: Video Diffusion Transformers, Video Length Extrapolation, Attention Dispersion, UltraViCo, Positional Encodings
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to tackle the challenge of video length extrapolation associated with AI-generated content by suppressing attention dispersion.
🛠️ Research Methods:
– Introduction of UltraViCo, a training-free, plug-and-play method using a constant decay factor to suppress attention dispersion for tokens beyond the training window, without requiring changes to the existing models.
💬 Research Conclusions:
– UltraViCo significantly extends the extrapolation limit from 2x to 4x, improving Dynamic Degree by 233% and Imaging Quality by 40.5% compared to previous methods, generalizing effectively to applications like controllable video synthesis and editing.
👉 Paper link: https://huggingface.co/papers/2511.20123

11. OmniAlpha: A Sequence-to-Sequence Framework for Unified Multi-Task RGBA Generation
🔑 Keywords: OmniAlpha, RGBA manipulation, Diffusion Transformer, Multi-task, MSRoPE-BiL
💡 Category: Generative Models
🌟 Research Objective:
– Introduce OmniAlpha, a unified multi-task generative framework for sequence-to-sequence RGBA image generation and editing, aiming to bridge the gap in current models.
🛠️ Research Methods:
– Implements a novel MSRoPE-BiL method in a Diffusion Transformer backbone and utilizes a new dataset named AlphaLayers for training on 21 diverse tasks.
💬 Research Conclusions:
– OmniAlpha outperforms specialized models with an 84.8% relative reduction in SAD for mask-free matting and receives over 90% human preference in layer-conditioned completion.
👉 Paper link: https://huggingface.co/papers/2511.20211

12. ReDirector: Creating Any-Length Video Retakes with Rotary Camera Encoding
🔑 Keywords: ReDirector, Rotary Camera Encoding, dynamic object localization, static background preservation, camera controllability
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce ReDirector, a novel method for generating camera-controlled video retakes to improve video quality by enhancing dynamic object localization and static background preservation.
🛠️ Research Methods:
– Utilize Rotary Camera Encoding (RoCE), integrating camera conditions into RoPE for handling multi-view relationships and improving consistency across variable-length videos.
💬 Research Conclusions:
– The approach significantly enhances camera controllability, geometric consistency, and video quality in dynamically captured variable-length videos.
👉 Paper link: https://huggingface.co/papers/2511.19827

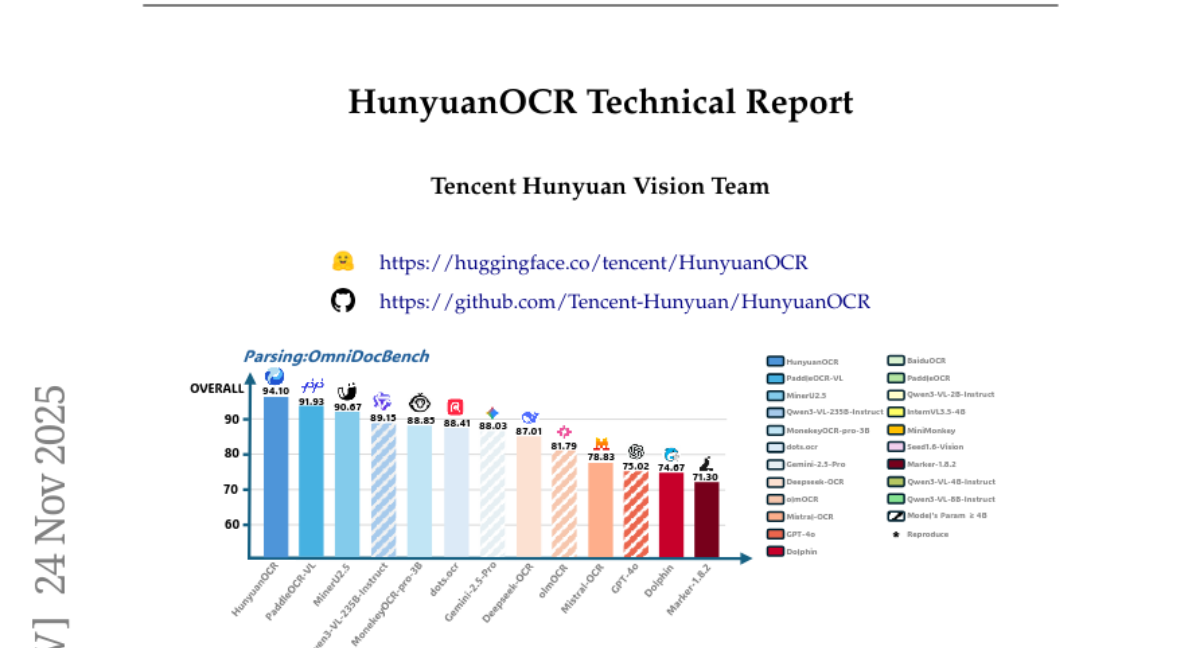
13. HunyuanOCR Technical Report
🔑 Keywords: HunyuanOCR, Vision-Language Model, Vision Transformer, OCR, Reinforcement Learning
💡 Category: Computer Vision
🌟 Research Objective:
– This study introduces HunyuanOCR, a lightweight Vision-Language Model for state-of-the-art OCR tasks, aiming to optimize both versatility and efficiency.
🛠️ Research Methods:
– Implementing a unified end-to-end architecture combining Vision Transformer and lightweight LLM, enhanced by data-driven and reinforcement learning strategies.
💬 Research Conclusions:
– HunyuanOCR surpasses commercial APIs and larger models in OCR tasks, establishing new benchmarks in perception and semantic tasks, and is open-sourced for broader industrial applications.
👉 Paper link: https://huggingface.co/papers/2511.19575
14. Fara-7B: An Efficient Agentic Model for Computer Use
🔑 Keywords: Computer Use Agents, Synthetic Data Generation, Fara-7B, Multi-step Web Tasks, AI Native
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to address the lack of large and high-quality datasets for computer use agents (CUAs) by introducing FaraGen, a system that generates synthetic data for multi-step web tasks.
🛠️ Research Methods:
– FaraGen proposes diverse tasks from popular websites, generates solution attempts, and verifies successful task trajectories using multiple verifiers to ensure efficiency and high throughput.
💬 Research Conclusions:
– The Fara-7B model, trained using data from FaraGen, outperforms other models of comparable size on various benchmarks and competes with larger models, showing the importance of scalable data generation systems for efficient agentic models.
👉 Paper link: https://huggingface.co/papers/2511.19663

15. STARFlow-V: End-to-End Video Generative Modeling with Normalizing Flow
🔑 Keywords: Normalizing Flows, Video Generation, Causal Prediction, Global-Local Architecture, Video-to-Video Generation
💡 Category: Generative Models
🌟 Research Objective:
– Revisiting the design space for video generation by introducing STARFlow-V, a normalizing flow-based video generator highlighting end-to-end learning and robust causal prediction.
🛠️ Research Methods:
– Utilization of a global-local architecture to manage spatiotemporal latent space interactions and minimize error accumulation.
– Introduction of flow-score matching with a causal denoiser for consistency in autoregressive video generation.
– Implementation of a video-aware Jacobi iteration scheme for efficient sampling while preserving causality.
💬 Research Conclusions:
– STARFlow-V demonstrates high-quality video generation with strong visual fidelity and temporal consistency.
– Provides the first evidence of normalizing flows being capable of autoregressive video generation, establishing them as a promising direction for future research in world models.
👉 Paper link: https://huggingface.co/papers/2511.20462
16. VQ-VA World: Towards High-Quality Visual Question-Visual Answering
🔑 Keywords: VQ-VA, agentic pipeline, web-scale deployment, IntelligentBench, open-source models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to advance Visual Question-Visual Answering (VQ-VA) by developing a data-centric framework to improve open-source model performance and narrow the gap with proprietary systems.
🛠️ Research Methods:
– Introduction of the VQ-VA World framework, utilizing an agentic pipeline for large-scale data construction, gathering approximately 1.8 million high-quality image-text samples.
– Implementation of IntelligentBench, a benchmark to evaluate VQ-VA across world knowledge, design knowledge, and reasoning.
💬 Research Conclusions:
– Training with VQ-VA World data significantly improved open-source model performance, with LightFusion achieving a substantial score on IntelligentBench, reducing the gap with proprietary systems like NanoBanana and GPT-Image.
– Release of model weights, datasets, and pipelines is expected to stimulate future research on VQ-VA.
👉 Paper link: https://huggingface.co/papers/2511.20573

17. MagicWorld: Interactive Geometry-driven Video World Exploration
🔑 Keywords: AI-generated summary, 3D geometric priors, Action-Guided 3D Geometry Module, History Cache Retrieval, dynamic scene evolution
💡 Category: Computer Vision
🌟 Research Objective:
– To overcome the limitations of current interactive video world models by improving scene stability and continuity using 3D geometric priors and historical retrieval.
🛠️ Research Methods:
– MagicWorld was developed by integrating a novel Action-Guided 3D Geometry Module and a History Cache Retrieval mechanism to enhance scene coherence.
💬 Research Conclusions:
– MagicWorld significantly boosts scene stability and continuity through multiple interaction iterations, successfully addressing previous issues of error accumulation and progressive drift.
👉 Paper link: https://huggingface.co/papers/2511.18886
18. Cook and Clean Together: Teaching Embodied Agents for Parallel Task Execution
🔑 Keywords: ORS3D, GRANT, 3D grounding, scheduling token mechanism, parallelizable subtasks
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This study introduces ORS3D, a task that synthesizes language understanding, 3D grounding, and efficiency optimization in task scheduling.
🛠️ Research Methods:
– The research utilizes ORS3D-60K, a dataset with 60K composite tasks set in real-world scenes, and proposes GRANT, a multi-modal language model using a scheduling token mechanism for task management.
💬 Research Conclusions:
– GRANT is validated as effective in language understanding, 3D grounding, and scheduling efficiency through extensive experiments on the ORS3D-60K dataset.
👉 Paper link: https://huggingface.co/papers/2511.19430

19. Scaling Agentic Reinforcement Learning for Tool-Integrated Reasoning in VLMs
🔑 Keywords: VISTA-Gym, vision-language models, multimodal reasoning, reinforcement learning, tool-integrated reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to enhance tool-integrated visual reasoning in vision-language models (VLMs) by introducing VISTA-Gym.
🛠️ Research Methods:
– VISTA-Gym is used as a scalable training environment leveraging diverse multimodal tasks and reinforcement learning, utilizing executable interaction loops and trajectory sampling.
💬 Research Conclusions:
– VISTA-R1, trained within VISTA-Gym, substantially surpasses state-of-the-art baselines on reasoning-intensive VQA benchmarks by 9.51%-18.72%, demonstrating its effectiveness in improving the reasoning capabilities of VLMs.
👉 Paper link: https://huggingface.co/papers/2511.19773

20. MajutsuCity: Language-driven Aesthetic-adaptive City Generation with Controllable 3D Assets and Layouts
🔑 Keywords: natural language-driven, 3D urban scenes, semantic controllability, stylistic diversity, geometric fidelity
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to develop MajutsuCity, a framework that synthesizes 3D urban scenes with high structural consistency and stylistically diverse features, emphasizing natural language-driven generation and semantic controllability.
🛠️ Research Methods:
– MajutsuCity employs a four-stage pipeline and integrates MajutsuAgent, an interactive editing agent, along with constructing a MajutsuDataset consisting of 2D semantic layouts, 3D building assets, and detailed annotations.
💬 Research Conclusions:
– MajutsuCity sets a new state-of-the-art standard in 3D city generation by significantly reducing layout FID compared to existing methods, showcasing superior performance in geometric fidelity, stylistic adaptability, and semantic controllability.
👉 Paper link: https://huggingface.co/papers/2511.20415

21. Cognitive Foundations for Reasoning and Their Manifestation in LLMs
🔑 Keywords: Cognitive Elements, LLMs, Meta-Cognitive Controls, Reasoning Guidance, Robust Cognitive Mechanisms
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To understand the reasoning gaps between large language models (LLMs) and human cognition, identifying cognitive elements and controls that influence successful problem-solving.
🛠️ Research Methods:
– Synthesizing cognitive science research into a taxonomy of 28 cognitive elements and conducting a large-scale empirical analysis involving 192K traces from 18 models, complemented by human think-aloud traces.
💬 Research Conclusions:
– Models underutilize cognitive elements, relying on rigid sequential processing. Introducing test-time reasoning guidance improves their complex problem-solving performance by up to 66.7%. The study establishes a shared vocabulary for diagnosing reasoning failures and enhancing robust cognitive mechanisms.
👉 Paper link: https://huggingface.co/papers/2511.16660

22. DiffSeg30k: A Multi-Turn Diffusion Editing Benchmark for Localized AIGC Detection
🔑 Keywords: DiffSeg30k, diffusion-based editing, semantic segmentation, pixel-level annotations, AI-generated content
💡 Category: Computer Vision
🌟 Research Objective:
– The study introduces DiffSeg30k, a dataset of 30k diffusion-edited images, to enhance the fine-grained detection of AI-generated content through semantic segmentation.
🛠️ Research Methods:
– Collection of in-the-wild images from COCO, use of eight diverse state-of-the-art diffusion models for local edits, implementation of multi-turn editing, and realistic editing scenarios through a vision-language model pipeline.
💬 Research Conclusions:
– The DiffSeg30k dataset shifts AIGC detection from binary classification to semantic segmentation, demonstrating significant challenges in robustness to image distortions. Segmentation models show superior performance as whole-image classifiers of diffusion edits and potential for cross-generator generalization, outperforming established forgery classifiers.
👉 Paper link: https://huggingface.co/papers/2511.19111

23. PhysChoreo: Physics-Controllable Video Generation with Part-Aware Semantic Grounding
🔑 Keywords: PhysChoreo, physical realism, video generation, physical controllability, physics-based rendering
💡 Category: Generative Models
🌟 Research Objective:
– Introduce PhysChoreo, a framework generating videos with diverse controllability and physical realism from a single image.
🛠️ Research Methods:
– Uses part-aware physical property reconstruction to estimate static initial physical properties.
– Involves temporally instructed simulations for synthesizing videos with rich dynamic behaviors.
💬 Research Conclusions:
– Demonstrates that PhysChoreo outperforms state-of-the-art methods on multiple evaluation metrics, generating videos with enhanced behaviors and physical realism.
👉 Paper link: https://huggingface.co/papers/2511.20562
24. Unified all-atom molecule generation with neural fields
🔑 Keywords: FuncBind, neural fields, score-based generative models, AI-generated, structure-conditioned
💡 Category: Generative Models
🌟 Research Objective:
– The introduction of FuncBind, a framework for generating diverse atomic structures in structure-conditioned molecular design using AI-generated approaches.
🛠️ Research Methods:
– Utilizes neural fields to represent molecules as continuous atomic densities.
– Employs score-based generative models with architectures adapted from computer vision.
💬 Research Conclusions:
– FuncBind achieves competitive performance across multiple modalities, generating varied atomic systems and molecules.
– Successfully demonstrates novel antibody generation through de novo redesign of the complementarity-determining region H3 loop.
– Introduces a new dataset and benchmark for macrocyclic peptide generation.
👉 Paper link: https://huggingface.co/papers/2511.15906

25. Yo’City: Personalized and Boundless 3D Realistic City Scene Generation via Self-Critic Expansion
🔑 Keywords: 3D city generation, spatial coherence, user-customized, AI-generated, isometric image synthesis
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Yo’City, a novel framework for user-customized, infinitely expandable 3D city generation using large models.
🛠️ Research Methods:
– Utilizes a top-down planning strategy with a hierarchical City-District-Grid structure for layout planning and detailed grid-level descriptions.
– Incorporates a produce-refine-evaluate loop for isometric image synthesis and subsequent image-to-3D generation.
– Employs a user-interactive, relationship-guided expansion mechanism for spatially coherent city growth.
💬 Research Conclusions:
– Yo’City outperforms existing methods in generating high-quality, personalized, and boundless city-scale scenes across multiple evaluation metrics.
👉 Paper link: https://huggingface.co/papers/2511.18734

26. Diverse Video Generation with Determinantal Point Process-Guided Policy Optimization
🔑 Keywords: AI-generated summary, Determinantal Point Processes, Group Relative Policy Optimization, diverse video generation, text-to-video
💡 Category: Generative Models
🌟 Research Objective:
– To address low diversity in text-to-video generation while maintaining quality through a novel framework, DPP-GRPO.
🛠️ Research Methods:
– Combines Determinantal Point Processes and Group Relative Policy Optimization to enforce diversity in video generation.
– The framework is implemented on WAN and CogVideoX, designed to work with existing models without compromising their output quality.
💬 Research Conclusions:
– DPP-GRPO improves video diversity on benchmarks like VBench and VideoScore.
– The method maintains prompt fidelity and visual quality.
– Code and a benchmark dataset of 30,000 diverse prompts are released to support future research.
👉 Paper link: https://huggingface.co/papers/2511.20647

27. SciEducator: Scientific Video Understanding and Educating via Deming-Cycle Multi-Agent System
🔑 Keywords: SciEducator, Multi-Agent System, Scientific Video Comprehension, Deming Cycle, Multi-Modal Learning
💡 Category: AI in Education
🌟 Research Objective:
– The study aims to develop SciEducator, an iterative self-evolving multi-agent system for enhancing scientific video understanding and education, integrating professional knowledge and step-wise reasoning.
🛠️ Research Methods:
– The design reformulates the Deming Cycle’s Plan-Do-Study-Act philosophy into a self-evolving reasoning and feedback mechanism, enabling the creation of tailored multi-modal educational content.
💬 Research Conclusions:
– SciEducator outperforms leading MLLMs and state-of-the-art video agents on SciVBench, establishing a new paradigm for scientific video comprehension and education.
👉 Paper link: https://huggingface.co/papers/2511.17943

28. Uplifting Table Tennis: A Robust, Real-World Application for 3D Trajectory and Spin Estimation
🔑 Keywords: 3D motion, monocular videos, front-end perception, 2D-to-3D uplifting, TTHQ dataset
💡 Category: Computer Vision
🌟 Research Objective:
– Propose a two-stage pipeline for accurate 3D motion analysis of a table tennis ball from monocular videos.
🛠️ Research Methods:
– Divide the challenge into front-end perception and back-end 2D-to-3D uplifting tasks.
– Utilize the TTHQ dataset for 2D supervision and train the uplifting model on physically-correct synthetic data.
– Integrate ball and table keypoint detectors for robust real-world application.
💬 Research Conclusions:
– The proposed method transforms a proof-of-concept into a practical and high-performing application for analyzing 3D table tennis trajectories and spins.
👉 Paper link: https://huggingface.co/papers/2511.20250

29. Concept-Aware Batch Sampling Improves Language-Image Pretraining
🔑 Keywords: Concept-Aware Batch Sampling, Data Concept, Diversity Maximization, Frequency Maximization, CLIP
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve vision-language model performance by curating training data based on specific concept distributions through a more flexible, task-adaptive online approach.
🛠️ Research Methods:
– Introduced Concept-Aware Batch Sampling (CABS) by leveraging a data collection called DataConcept, consisting of 128M web-crawled image-text pairs, and proposed two variants: Diversity Maximization and Frequency Maximization.
💬 Research Conclusions:
– Demonstrated that CABS significantly benefits CLIP/SigLIP model classes and provides an open-source alternative to proprietary online data curation algorithms, allowing practitioners to optimize concept distributions for specific tasks.
👉 Paper link: https://huggingface.co/papers/2511.20643

30. Future Is Unevenly Distributed: Forecasting Ability of LLMs Depends on What We’re Asking
🔑 Keywords: Large Language Models, forecasting competence, domain structure, prompt framing, context
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the variance in forecasting performance of Large Language Models on events beyond the model cutoff date.
🛠️ Research Methods:
– Analyze the effect of context, question type, and external knowledge on accuracy and calibration.
💬 Research Conclusions:
– Demonstrated that forecasting ability is highly variable and depends significantly on domain structure and prompt framing.
👉 Paper link: https://huggingface.co/papers/2511.18394

31. CLaRa: Bridging Retrieval and Generation with Continuous Latent Reasoning
🔑 Keywords: CLaRa, Retrieval-Augmented Generation, Embedding-Based Compression, Joint Optimization, QA Benchmarks
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to enhance retrieval-augmented generation by introducing a unified framework for embedding-based compression and joint optimization to achieve state-of-the-art performance in QA benchmarks.
🛠️ Research Methods:
– Introduces CLaRa, a framework performing embedding-based compression and joint optimization in a shared continuous space. Utilizes SCP for semantically rich compressed vectors and trains the reranker and generator end-to-end with a differentiable top-k estimator.
💬 Research Conclusions:
– CLaRa achieves state-of-the-art compression and reranking performance in multiple QA benchmarks, often surpassing text-based fine-tuned baselines.
👉 Paper link: https://huggingface.co/papers/2511.18659

32.
