AI Native Daily Paper Digest – 20251211

1. StereoWorld: Geometry-Aware Monocular-to-Stereo Video Generation
🔑 Keywords: Stereo video, Monocular-to-stereo, Pretrained video generator, Geometry-aware regularization, Spatio-temporal tiling
💡 Category: Computer Vision
🌟 Research Objective:
– The primary goal is to develop StereoWorld, an end-to-end framework for transforming monocular video input into high-quality stereo video, addressing the demand from XR applications.
🛠️ Research Methods:
– Utilizes a pretrained video generator with geometry-aware regularization to preserve 3D structure and spatio-temporal tiling for efficient high-resolution synthesis.
– Curated a high-definition stereo video dataset with over 11 million frames aligned to human interpupillary distance for extensive training and evaluation.
💬 Research Conclusions:
– StereoWorld significantly outperforms previous methods, producing stereo videos with superior visual fidelity and geometric consistency.
👉 Paper link: https://huggingface.co/papers/2512.09363
2. BrainExplore: Large-Scale Discovery of Interpretable Visual Representations in the Human Brain
🔑 Keywords: automated framework, unsupervised decomposition, fMRI, visual representations, natural language descriptions
💡 Category: Computer Vision
🌟 Research Objective:
– To identify and explain visual representations in the human brain using an automated framework.
🛠️ Research Methods:
– Utilized unsupervised decomposition methods to discover interpretable patterns in fMRI data.
– Developed an automated pipeline to explain patterns by matching them with natural images and generating descriptions.
💬 Research Conclusions:
– Revealed thousands of interpretable patterns representing various visual concepts, including previously unreported fine-grained representations.
👉 Paper link: https://huggingface.co/papers/2512.08560

3. Composing Concepts from Images and Videos via Concept-prompt Binding
🔑 Keywords: Diffusion Transformers, Visual concept composition, Hierarchical binder structure, Prompt tokens, Temporal Disentanglement Strategy
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to improve the accurate composition of complex visual concepts from images and videos by using a method called Bind & Compose.
🛠️ Research Methods:
– Bind & Compose employs Diffusion Transformers with a hierarchical binder structure and a Diversify-and-Absorb Mechanism to bind visual concepts with corresponding prompt tokens.
– It utilizes a Temporal Disentanglement Strategy with a dual-branch binder structure to model temporal aspects in video concepts effectively.
💬 Research Conclusions:
– The method demonstrates superior concept consistency, prompt fidelity, and motion quality compared to existing approaches, enhancing possibilities for visual creativity.
👉 Paper link: https://huggingface.co/papers/2512.09824

4. OmniPSD: Layered PSD Generation with Diffusion Transformer
🔑 Keywords: OmniPSD, Flux ecosystem, in-context learning, spatial attention, RGBA-VAE
💡 Category: Generative Models
🌟 Research Objective:
– The research introduces OmniPSD, a diffusion framework aimed at generating and decomposing layered PSD files with transparency awareness.
🛠️ Research Methods:
– OmniPSD incorporates in-context learning to enable both text-to-PSD generation and image-to-PSD decomposition, leveraging spatial attention for compositional structure and RGBA-VAE to maintain transparency.
💬 Research Conclusions:
– Extensive experiments show OmniPSD’s capacity for high-fidelity generation, maintaining structural consistency and transparency, thereby establishing a new paradigm for designing and decomposing PSD layers using diffusion transformers.
👉 Paper link: https://huggingface.co/papers/2512.09247
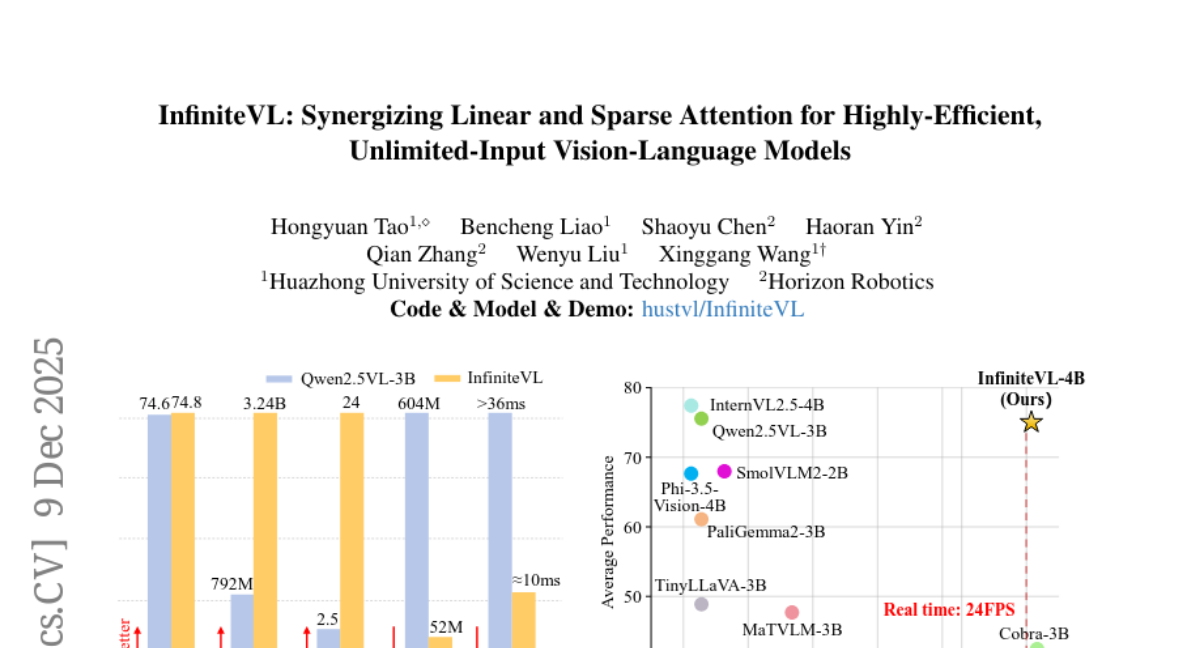
5. InfiniteVL: Synergizing Linear and Sparse Attention for Highly-Efficient, Unlimited-Input Vision-Language Models
🔑 Keywords: InfiniteVL, Vision-Language Models, Sliding Window Attention, Gated DeltaNet, Linear Complexity
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop InfiniteVL, a linear-complexity Vision-Language Model (VLM) architecture that combines sliding window attention with Gated DeltaNet to improve performance and efficiency.
🛠️ Research Methods:
– Implemented a three-stage training strategy including distillation pretraining, instruction tuning, and long-sequence SFT with less than 2% of the data compared to leading VLMs.
💬 Research Conclusions:
– InfiniteVL significantly surpasses previous linear-complexity VLM performances and matches leading Transformer-based VLM results, achieving over 3.6× inference speedup while preserving memory and maintaining constant latency, particularly effective in streaming video understanding scenarios.
👉 Paper link: https://huggingface.co/papers/2512.08829
6. HiF-VLA: Hindsight, Insight and Foresight through Motion Representation for Vision-Language-Action Models
🔑 Keywords: HiF-VLA, Motion, Bidirectional Temporal Reasoning, Long-Horizon Manipulation, Robotics
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Integrate motion into Vision-Language-Action models to improve long-horizon manipulation performance with minimal latency.
🛠️ Research Methods:
– Utilize a unified framework termed HiF-VLA, which employs hindsight, insight, and foresight for aiding VLAs using bidirectional temporal reasoning.
💬 Research Conclusions:
– HiF-VLA outperforms existing models on LIBERO-Long and CALVIN ABC-D benchmarks with negligible additional latency and demonstrates enhanced effectiveness in real-world tasks.
👉 Paper link: https://huggingface.co/papers/2512.09928

7. Fast-Decoding Diffusion Language Models via Progress-Aware Confidence Schedules
🔑 Keywords: Diffusion large language models, SchED, early-exit algorithm, instruction-tuned models, predictive entropy
💡 Category: Natural Language Processing
🌟 Research Objective:
– The primary objective is to accelerate diffusion large language model (dLLM) decoding with minimal performance loss using SchED, a training-free early-exit algorithm.
🛠️ Research Methods:
– Evaluation of SchED on two dLLM families (Dream and LLaDA) across ten benchmarks including various downstream tasks such as multiple-choice question answering, math, long-form QA/summarization, and translation.
💬 Research Conclusions:
– SchED provides substantial acceleration with up to 4.0 times speedup on instruction-tuned models while retaining near-perfect baseline score performance. It shows robustness and outperforms previous early-exit methods, particularly in long-form generation tasks.
👉 Paper link: https://huggingface.co/papers/2512.02892

8. EtCon: Edit-then-Consolidate for Reliable Knowledge Editing
🔑 Keywords: knowledge editing, large language models, overfitting, knowledge consolidation, policy optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– Propose the Edit-then-Consolidate framework to enhance knowledge editing in large language models and improve real-world applicability.
🛠️ Research Methods:
– Use Targeted Proximal Supervised Fine-Tuning (TPSFT) to mitigate overfitting by localizing edits through a trust-region objective.
– Implement a consolidation stage with Group Relative Policy Optimization (GRPO) to align edited knowledge with inference policy, optimizing trajectory-level behavior under reward signals.
💬 Research Conclusions:
– The framework improves editing reliability and generalization in real-world evaluations, while preserving locality and pre-trained capabilities.
👉 Paper link: https://huggingface.co/papers/2512.04753

9. Rethinking Chain-of-Thought Reasoning for Videos
🔑 Keywords: Chain-of-thought, multimodal large language models, video reasoning, visual tokens, inference efficiency
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to evaluate whether concise reasoning with reduced visual tokens can be sufficient for effective video reasoning without the need for manual annotations or supervised fine-tuning.
🛠️ Research Methods:
– The researchers designed and validated an efficient post-training and inference framework to enhance a video MLLM’s reasoning capability, enabling operation on compressed visual tokens and generating brief reasoning traces.
💬 Research Conclusions:
– The study concludes that long, human-like Chain-of-Thought reasoning may not be necessary for general video reasoning; concise reasoning is both effective and efficient, achieving improved inference efficiency and competitive benchmark performance.
👉 Paper link: https://huggingface.co/papers/2512.09616

10. WonderZoom: Multi-Scale 3D World Generation
🔑 Keywords: WonderZoom, scale-adaptive Gaussian surfels, progressive detail synthesizer, real-time rendering, multi-scale 3D scenes
💡 Category: Generative Models
🌟 Research Objective:
– Introduce WonderZoom, a novel method for generating multi-scale 3D scenes from a single image.
🛠️ Research Methods:
– Utilizes scale-adaptive Gaussian surfels for generating and real-time rendering.
– Employs a progressive detail synthesizer to iteratively create finer-scale 3D content.
💬 Research Conclusions:
– WonderZoom significantly outperforms existing models in quality and alignment, offering new possibilities for multi-scale 3D world creation from a single image.
👉 Paper link: https://huggingface.co/papers/2512.09164
11. UniUGP: Unifying Understanding, Generation, and Planing For End-to-end Autonomous Driving
🔑 Keywords: Autonomous Driving, Vision-Language Models, Video Generation, AI Native, Reasoning
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To enhance autonomous driving in complex scenarios by integrating vision-language models with video generation.
🛠️ Research Methods:
– Proposed a unified Understanding-Generation-Planning (UniUGP) framework to combine scene reasoning, future video generation, and trajectory planning using specialized datasets and a hybrid expert architecture.
💬 Research Conclusions:
– Achieved state-of-the-art performance in perception, reasoning, and decision-making, particularly in challenging long-tail scenarios.
👉 Paper link: https://huggingface.co/papers/2512.09864
12. Towards a Science of Scaling Agent Systems
🔑 Keywords: AI applications, multi-agent systems, quantitative scaling principles, coordination metrics, predictive model
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to address the lack of principled design choices in agent system performance by deriving quantitative scaling principles for multi-agent systems.
🛠️ Research Methods:
– Evaluated across four benchmarks using five canonical architectures and instantiated across three LLM families, a controlled evaluation was conducted over 180 configurations.
💬 Research Conclusions:
– Derived a predictive model based on empirical coordination metrics achieving cross-validated R^2=0.513.
– Identified key effects: tool-coordination trade-off, capability saturation, and topology-dependent error amplification.
– Centralized coordination significantly improves performance on parallelizable tasks, while decentralized coordination excels in dynamic tasks. The framework predicts optimal coordination strategies for 87% of configurations.
👉 Paper link: https://huggingface.co/papers/2512.08296

13. Learning Unmasking Policies for Diffusion Language Models
🔑 Keywords: Reinforcement Learning, Masked Discrete Diffusion, Sampling Procedure, Markov Decision Process, Single-Layer Transformer
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve token throughput and quality of masked discrete diffusion language models by training sampling procedures using reinforcement learning.
🛠️ Research Methods:
– Formalized masked diffusion sampling as a Markov decision process.
– Developed a lightweight policy architecture using a single-layer transformer to map token confidences to unmasking decisions.
💬 Research Conclusions:
– Trained policies match state-of-the-art heuristic performance in combination with semi-autoregressive generation and outperform them in full diffusion settings.
– Policies show generalization to new language models and longer sequences but face challenges with out-of-domain data and tuning the accuracy-efficiency trade-off.
👉 Paper link: https://huggingface.co/papers/2512.09106

14. TED-4DGS: Temporally Activated and Embedding-based Deformation for 4DGS Compression
🔑 Keywords: 3D Gaussian Splatting, dynamic 3D scenes, temporal activation, rate-distortion optimization, implicit neural representation
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to develop a more compact and efficient compression technique for dynamic 3D scenes using TED-4DGS, building upon the foundation of 3D Gaussian Splatting (3DGS) and focusing on rate-distortion optimization.
🛠️ Research Methods:
– TED-4DGS uses a sparse anchor-based 3DGS representation with learnable temporal-activation parameters for transitions over time.
– Utilizes temporal embedding to interact with a shared deformation bank for anchor deformation.
– Incorporates an implicit neural representation (INR)-based hyperprior and a channel-wise autoregressive model for effective compression.
💬 Research Conclusions:
– The proposed TED-4DGS scheme achieves state-of-the-art rate-distortion performance on various real-world datasets, pioneering a rate-distortion-optimized compression framework for dynamic 3DGS representations.
👉 Paper link: https://huggingface.co/papers/2512.05446

15. IF-Bench: Benchmarking and Enhancing MLLMs for Infrared Images with Generative Visual Prompting
🔑 Keywords: IF-Bench, infrared images, multimodal large language models, generative visual prompting, domain distribution shifts
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce IF-Bench, a benchmark for evaluating the understanding of infrared images by multimodal large language models.
🛠️ Research Methods:
– Systematically evaluate models using cyclic evaluation, bilingual assessment, and hybrid judgment strategies, alongside proposing a training-free method called Generative Visual Prompting (GenViP).
💬 Research Conclusions:
– Demonstrated that IF-Bench effectively evaluates model performance on infrared images and revealed how various factors affect image comprehension. GenViP improved model performance by translating infrared images to RGB, addressing domain distribution shifts.
👉 Paper link: https://huggingface.co/papers/2512.09663

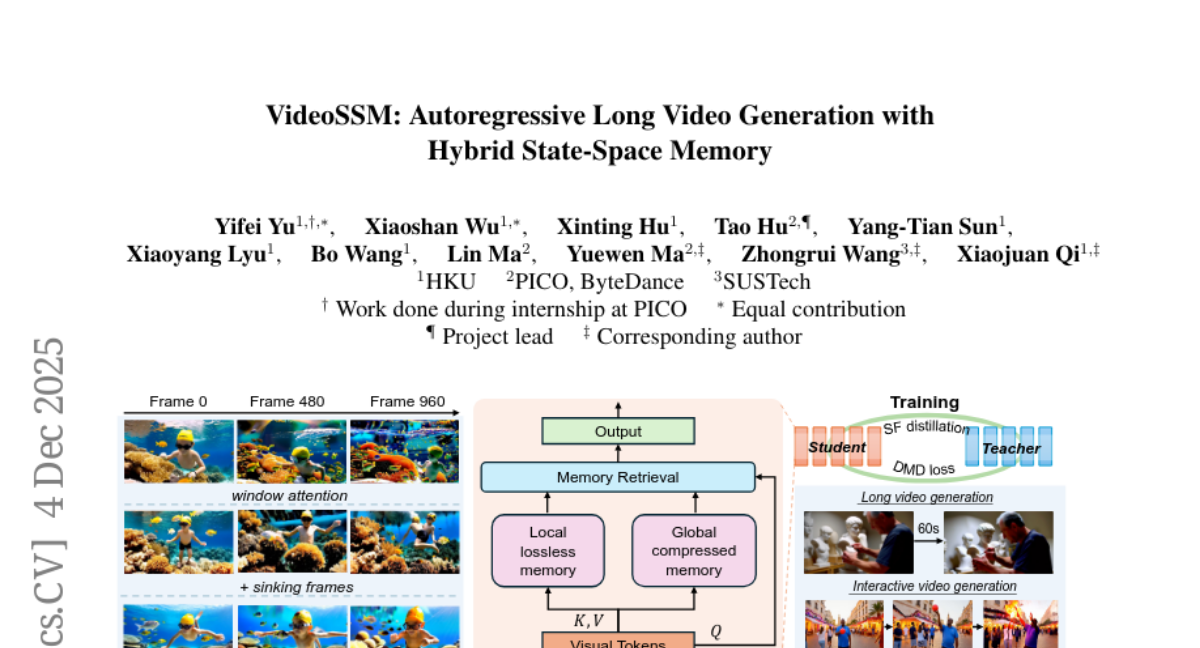
16. VideoSSM: Autoregressive Long Video Generation with Hybrid State-Space Memory
🔑 Keywords: VideoSSM, AR diffusion, state-space model, temporal consistency, motion stability
💡 Category: Generative Models
🌟 Research Objective:
– To achieve state-of-the-art temporal consistency and motion stability in long-video generation by coordinating short- and long-term context through a hybrid state-space memory model.
🛠️ Research Methods:
– Integration of AR diffusion with a state-space memory model to manage both short- and long-term video synthesis dynamics.
💬 Research Conclusions:
– VideoSSM improves upon existing autoregressive video generators by maintaining temporal coherence and motion stability over minute-scale horizons, supporting content diversity and allowing for interactive, prompt-based control.
👉 Paper link: https://huggingface.co/papers/2512.04519
17. Beyond Unified Models: A Service-Oriented Approach to Low Latency, Context Aware Phonemization for Real Time TTS
🔑 Keywords: real-time performance, phonemization quality, lightweight phonemizers, context-aware phonemization, service-oriented architecture
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose a framework that improves phonemization quality in TTS systems without compromising real-time performance.
🛠️ Research Methods:
– Introduction of lightweight strategies for context-aware phonemization and the development of a service-oriented TTS architecture that operates these modules as independent services.
💬 Research Conclusions:
– The proposed system enhances pronunciation soundness and linguistic accuracy while maintaining real-time responsiveness, making it suitable for offline and end-device TTS applications.
👉 Paper link: https://huggingface.co/papers/2512.08006

18. Reinventing Clinical Dialogue: Agentic Paradigms for LLM Enabled Healthcare Communication
🔑 Keywords: cognitive architecture, agentic autonomy, Large Language Models, stateless processing, medical AI
💡 Category: AI in Healthcare
🌟 Research Objective:
– The survey focuses on analyzing the cognitive architecture of medical AI systems and the shift from generative text prediction to agentic autonomy.
🛠️ Research Methods:
– Introduces a novel taxonomy structured by knowledge source and agency objective, categorizing methods into four archetypes for systematic analysis.
💬 Research Conclusions:
– Provides a comprehensive analysis of how architectural choices balance autonomy and safety, highlighting the trade-offs between creativity and reliability in medical AI.
👉 Paper link: https://huggingface.co/papers/2512.01453

19. Smart Timing for Mining: A Deep Learning Framework for Bitcoin Hardware ROI Prediction
🔑 Keywords: MineROI-Net, Transformer-based architecture, ASIC mining, multi-scale temporal patterns, ROI
💡 Category: AI in Finance
🌟 Research Objective:
– To predict profitability for ASIC mining hardware acquisitions, enhancing decision-making in the volatile mining industry.
🛠️ Research Methods:
– Utilized a Transformer-based architecture (MineROI-Net) to address the timing of hardware acquisition as a time series classification task, capturing multi-scale temporal patterns in mining profitability.
💬 Research Conclusions:
– MineROI-Net outperformed LSTM-based and TSLANet baselines with 83.7% accuracy and a macro F1-score of 83.1%, demonstrating strong economic relevance by accurately detecting profitable and unprofitable periods, offering a practical tool for reducing financial risk in mining operations.
👉 Paper link: https://huggingface.co/papers/2512.05402

20. Pay Less Attention to Function Words for Free Robustness of Vision-Language Models
🔑 Keywords: Function-word De-Attention, VLMs, cross-modal adversarial attacks, robustness, attention heads
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve robustness in VLMs against cross-modal adversarial attacks through minimizing the influence of function words using Function-word De-Attention (FDA).
🛠️ Research Methods:
– Implementing FDA by calculating and differentially subtracting function-word cross-attention within attention heads, validated against two SOTA baselines under various adversarial attacks across multiple tasks and datasets.
💬 Research Conclusions:
– FDA significantly reduces ASR with minimal performance trade-offs in models while demonstrating scalability, generalization, and zero-shot capabilities, supported by detailed experimental results and ablation studies.
👉 Paper link: https://huggingface.co/papers/2512.07222

21. GimbalDiffusion: Gravity-Aware Camera Control for Video Generation
🔑 Keywords: GimbalDiffusion, text-to-video generation, camera control, absolute coordinate system, gravity
💡 Category: Generative Models
🌟 Research Objective:
– Introduce the GimbalDiffusion framework to enhance camera control in text-to-video generation using absolute coordinates and gravity as a reference.
🛠️ Research Methods:
– Utilize absolute coordinate systems for camera trajectory definitions, and introduce null-pitch conditioning to improve model robustness.
💬 Research Conclusions:
– GimbalDiffusion significantly advances control and robustness in text-to-video models, providing precise, gravity-aligned camera manipulation.
👉 Paper link: https://huggingface.co/papers/2512.09112

22.
