AI Native Daily Paper Digest – 20251229

1. InsertAnywhere: Bridging 4D Scene Geometry and Diffusion Models for Realistic Video Object Insertion
🔑 Keywords: 4D scene understanding, realistic video object insertion, diffusion-based video generation, geometrically consistent object placement, visually coherent object insertions
💡 Category: Generative Models
🌟 Research Objective:
– Introduce InsertAnywhere, a framework to improve video object insertion with geometrically consistent and visually coherent outputs.
🛠️ Research Methods:
– Utilize a 4D aware mask generation module for scene geometry reconstruction and temporal coherence.
– Extend a diffusion-based video generation model to enhance object insertion with local variations.
💬 Research Conclusions:
– The InsertAnywhere framework demonstrates superior performance in realistic scenarios by producing geometrically plausible and visually coherent object insertions, outperforming current models.
👉 Paper link: https://huggingface.co/papers/2512.17504
2. MAI-UI Technical Report: Real-World Centric Foundation GUI Agents
🔑 Keywords: GUI agents, Human-Computer Interaction, MAI-UI, Reinforcement Learning, Device-Cloud Collaboration
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The paper aims to develop MAI-UI, a family of GUI agents designed to revolutionize the next generation of human-computer interaction by addressing key deployment challenges.
🛠️ Research Methods:
– The study employs a self-evolving data pipeline, native device-cloud collaboration, and an online reinforcement learning framework to enhance agent-user interaction and improve environment adaptability.
💬 Research Conclusions:
– MAI-UI establishes new state-of-the-art performance across various GUI grounding and mobile navigation benchmarks, demonstrating significant improvements in agent usability and performance.
👉 Paper link: https://huggingface.co/papers/2512.22047

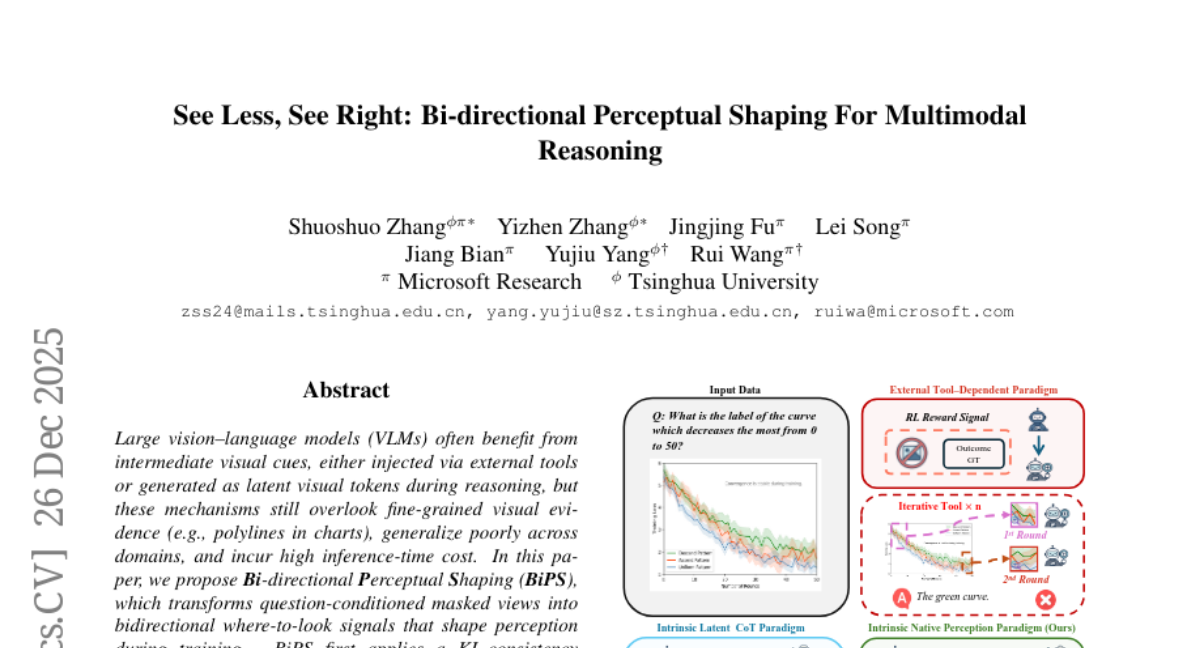
3. See Less, See Right: Bi-directional Perceptual Shaping For Multimodal Reasoning
🔑 Keywords: vision-language models, visual cues, Bi-directional Perceptual Shaping, generalization, inference-time cost
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to improve the fine-grained visual evidence and cross-domain generalization in large vision-language models, while also reducing inference-time cost.
🛠️ Research Methods:
– The study introduces Bi-directional Perceptual Shaping (BiPS) which employs KL-consistency and KL-separation constraints on the visual data to enhance perception during training.
💬 Research Conclusions:
– BiPS enhances the Qwen2.5-VL-7B model by 8.2% across eight benchmarks and demonstrates strong generalization to unseen datasets and image types, indicating improved performance and adaptability.
👉 Paper link: https://huggingface.co/papers/2512.22120
4. ProEdit: Inversion-based Editing From Prompts Done Right
🔑 Keywords: Visual Editing, ProEdit, State-of-the-Art (SOTA), Plug-and-Play, Inversion-based
💡 Category: Computer Vision
🌟 Research Objective:
– The primary goal of the paper is to improve inversion-based visual editing by reducing the dependency on source information, thus enhancing the consistency and effectiveness of edits in image and video editing.
🛠️ Research Methods:
– The authors propose two techniques: KV-mix which blends source and target features to maintain background consistency while reducing source influence, and Latents-Shift which perturbs the edited region of the source latent to minimize inverted latent impact on sampling.
💬 Research Conclusions:
– The proposed method, ProEdit, achieves state-of-the-art (SOTA) performance on various editing benchmarks. It is designed to be plug-and-play, allowing seamless integration into existing inversion and editing methods like RF-Solver, FireFlow, and UniEdit.
👉 Paper link: https://huggingface.co/papers/2512.22118

5. SVBench: Evaluation of Video Generation Models on Social Reasoning
🔑 Keywords: Text-to-Video Generation, Social Coherence, Social Reasoning, Video Generation Systems
💡 Category: Generative Models
🌟 Research Objective:
– To address the limitation of current text-to-video models in generating socially coherent behavior by introducing the first benchmark for social reasoning in video generation.
🛠️ Research Methods:
– Developed a fully training-free agent-based pipeline to distill reasoning mechanisms, synthesize diverse scenarios, enforce neutrality and difficulty control, and evaluate videos using a high-capacity VLM judge.
💬 Research Conclusions:
– Despite advancements in realism and motion fidelity, state-of-the-art models show significant gaps in understanding intentions, belief reasoning, and prosocial inference.
👉 Paper link: https://huggingface.co/papers/2512.21507

6. InSight-o3: Empowering Multimodal Foundation Models with Generalized Visual Search
🔑 Keywords: AI-generated summary, multimodal reasoning, visual reasoning, O3-Bench, InSight-o3
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce O3-Bench, a benchmark to evaluate multimodal reasoning with interleaved attention to visual details, addressing current shortcomings in multimodal agents’ reasoning capabilities.
🛠️ Research Methods:
– Development of InSight-o3, a multi-agent framework incorporating a visual reasoning agent and a visual search agent, employing generalized visual search and multimodal LLM trained via reinforcement learning.
💬 Research Conclusions:
– InSight-o3 significantly improves multimodal models’ performance, demonstrating progress towards powerful open systems and highlighting its effectiveness with the benchmark O3-Bench. Code and datasets are available for further research and development.
👉 Paper link: https://huggingface.co/papers/2512.18745

7. A 58-Addition, Rank-23 Scheme for General 3×3 Matrix Multiplication
🔑 Keywords: Algorithm, Matrix Multiplication, Non-Commutative Rings, Additive Complexity
💡 Category: Foundations of AI
🌟 Research Objective:
– The paper aims to present a new state-of-the-art algorithm for exact 3×3 matrix multiplication over general non-commutative rings.
🛠️ Research Methods:
– The algorithm was discovered through an automated search that combined ternary-restricted flip-graph exploration with greedy intersection reduction to eliminate common subexpressions.
💬 Research Conclusions:
– The new algorithm achieves a rank-23 scheme with only 58 scalar additions, improving the previous best additive complexity of 60 additions and reducing the total scalar operation count from 83 to 81.
👉 Paper link: https://huggingface.co/papers/2512.21980

8.

9. Rethinking Sample Polarity in Reinforcement Learning with Verifiable Rewards
🔑 Keywords: Large reasoning models, Reinforcement learning with verifiable reward, A3PO
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To investigate how the sample polarities affect the training dynamics and behaviors of reinforcement learning with verifiable reward (RLVR) and to develop a more precise advantage allocation method.
🛠️ Research Methods:
– Systematic investigation of sample polarities on RLVR.
– Development and evaluation of the Adaptive and Asymmetric token-level Advantage shaping method for Policy Optimization (A3PO).
💬 Research Conclusions:
– Positive samples enhance existing reasoning patterns while negative samples explore new paths.
– A3PO effectively allocates advantage signals, demonstrated through experiments across five reasoning benchmarks.
👉 Paper link: https://huggingface.co/papers/2512.21625

10. SlideTailor: Personalized Presentation Slide Generation for Scientific Papers
🔑 Keywords: SlideTailor, agentic framework, chain-of-speech mechanism, AI-generated summary
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research introduces SlideTailor, an innovative framework aimed at generating presentation slides that align with user preferences by utilizing implicit preferences from example pairs and visual templates.
🛠️ Research Methods:
– The method incorporates a human behavior-inspired agentic framework, employing a chain-of-speech mechanism for aligning slide content with oral narration. A benchmark dataset is constructed to capture diverse user preferences and provide robust evaluation metrics.
💬 Research Conclusions:
– The framework successfully customizes slide generation, improving the quality of slides and supporting applications like video presentations. Extensive experiments validate the framework’s effectiveness in aligning content with user needs.
👉 Paper link: https://huggingface.co/papers/2512.20292

11. SWE-RM: Execution-free Feedback For Software Engineering Agents
🔑 Keywords: Execution-based feedback, Unit testing, Reinforcement Learning, Reward models, AI Native
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to develop versatile reward models that are effective across test-time scaling (TTS) and reinforcement learning (RL) in software engineering agents.
🛠️ Research Methods:
– The authors conducted comprehensive experiments analyzing factors like training data scale, policy mixtures, and data source composition to train a robust reward model.
– Introduction of SWE-RM, a reward model using a mixture-of-experts architecture to enhance performance on TTS and RL.
💬 Research Conclusions:
– The SWE-RM model significantly improves the performance of SWE agents on TTS and RL tasks, achieving state-of-the-art results in open-source models.
– Notably, it increases the accuracy of coding agents like Qwen3-Coder-Flash and Qwen3-Coder-Max on SWE-Bench Verified.
👉 Paper link: https://huggingface.co/papers/2512.21919

12. Omni-Weather: Unified Multimodal Foundation Model for Weather Generation and Understanding
🔑 Keywords: Omni-Weather, Multimodal Foundation Model, Chain-of-Thought, Weather Generation, Shared Self-Attention Mechanism
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To unify weather generation and understanding in a single architecture using a multimodal approach, enhancing both prediction accuracy and mechanistic interpretation.
🛠️ Research Methods:
– Integration of a radar encoder with a shared self-attention mechanism, and the construction of a Chain-of-Thought dataset for causal reasoning in weather modeling tasks.
💬 Research Conclusions:
– Demonstrates state-of-the-art performance in weather generation and understanding, showing that these tasks can mutually enhance each other when unified, highlighting the feasibility and value of this approach.
👉 Paper link: https://huggingface.co/papers/2512.21643

13. TimeBill: Time-Budgeted Inference for Large Language Models
🔑 Keywords: Large Language Models, TimeBill, Inference Efficiency, Execution Time Estimation
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Propose a time-budgeted inference framework, TimeBill, for Large Language Models to improve efficiency and maintain response performance in time-critical systems.
🛠️ Research Methods:
– Develop a fine-grained response length predictor (RLP) and an execution time estimator (ETE) to predict the end-to-end execution time. Adapt KV cache eviction ratio based on time budget and execution time prediction.
💬 Research Conclusions:
– TimeBill significantly enhances task completion rate and maintains response performance across various overrun strategies.
👉 Paper link: https://huggingface.co/papers/2512.21859

14. UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and Texture
🔑 Keywords: Multimodal large language models, Perceptual-Level Image Understanding, Domain-Adaptive Pre-Training, Visual Rating, Visual Question Answering
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to advance perceptual-level image understanding for multimodal large language models (MLLMs) by introducing UniPercept-Bench, a unified framework focusing on Aesthetics, Quality, Structure, and Texture.
🛠️ Research Methods:
– The researchers establish a hierarchical definition system and construct large-scale datasets. They develop a strong baseline model called UniPercept, using Domain-Adaptive Pre-Training and Task-Aligned Reinforcement Learning for enhanced generalization in Visual Rating and Visual Question Answering tasks.
💬 Research Conclusions:
– UniPercept demonstrates superior performance in perceptual-level image understanding compared to existing MLLMs and serves as a versatile reward model for text-to-image generation. The framework provides a comprehensive benchmark and baseline for future advancements in this field.
👉 Paper link: https://huggingface.co/papers/2512.21675

15. Mindscape-Aware Retrieval Augmented Generation for Improved Long Context Understanding
🔑 Keywords: MiA-RAG, Retrieval-Augmented Generation (RAG), hierarchical summarization, global semantic representation, evidence-based understanding
💡 Category: Natural Language Processing
🌟 Research Objective:
– Present MiA-RAG, a system aiming to enhance LLM-based Retrieval-Augmented Generation systems with global context awareness.
🛠️ Research Methods:
– Utilize hierarchical summarization to build a mindscape and condition both retrieval and generation on a global semantic representation, improving long-context tasks.
💬 Research Conclusions:
– MiA-RAG consistently outperforms baselines in long-context and bilingual benchmarks, aligning local details with a global representation for enhanced retrieval and reasoning.
👉 Paper link: https://huggingface.co/papers/2512.17220
