AI Native Daily Paper Digest – 20260225

1. On Data Engineering for Scaling LLM Terminal Capabilities
🔑 Keywords: Terminal Agent, Synthetic Task Generation, Data Engineering, Curriculum Learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve terminal agent performance through synthetic task generation and data strategy analysis.
🛠️ Research Methods:
– Developed Terminal-Task-Gen, a pipeline for synthetic task generation.
– Conducted analysis on data strategies including filtering, curriculum learning, and scaling.
💬 Research Conclusions:
– Trained models (Nemotron-Terminal) significantly outperform larger counterparts on benchmarks.
– Open-sourced model checkpoints and datasets to promote further research in this domain.
👉 Paper link: https://huggingface.co/papers/2602.21193

2. PyVision-RL: Forging Open Agentic Vision Models via RL
🔑 Keywords: PyVision-RL, interaction collapse, reinforcement learning, multimodal models, video processing
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research introduces PyVision-RL, a framework designed to address interaction collapse in agentic multimodal models by enhancing reinforcement learning techniques.
🛠️ Research Methods:
– The framework employs an oversampling-filtering-ranking rollout strategy and an accumulative tool reward system to prevent interaction collapse and encourage multi-turn tool use.
💬 Research Conclusions:
– Experiments demonstrate that the PyVision-RL framework significantly improves performance and efficiency in multimodal agents by supporting sustained interaction and reducing visual token usage through on-demand visual processing.
👉 Paper link: https://huggingface.co/papers/2602.20739

3. Test-Time Training with KV Binding Is Secretly Linear Attention
🔑 Keywords: Test-time Training (TTT), learned linear attention, online meta-learning, architectural simplifications, representational capacity
💡 Category: Machine Learning
🌟 Research Objective:
– The primary goal is to reinterpret Test-time training (TTT) as a form of learned linear attention rather than memorization, providing improved efficiency and architectural simplifications.
🛠️ Research Methods:
– The study redefines TTT architectures to express them as learned linear attention operators, which admit fully parallel formulations and allow for systematic reduction to a standard linear attention form.
💬 Research Conclusions:
– Results suggest a shift in viewing TTT not as test-time memorization but as learned linear attention, leading to practical benefits like enhanced representational capacity, performance preservation, and efficiency improvements.
👉 Paper link: https://huggingface.co/papers/2602.21204

4. See and Fix the Flaws: Enabling VLMs and Diffusion Models to Comprehend Visual Artifacts via Agentic Data Synthesis
🔑 Keywords: AI-generated images, Artifact mitigation, ArtiAgent, Diffusion transformer, Perception agent
💡 Category: Generative Models
🌟 Research Objective:
– The primary objective is to automate the creation of real-artifact image pairs to study and mitigate visual artifacts in AI-generated images.
🛠️ Research Methods:
– The study introduces ArtiAgent, which includes three agents: a perception agent for recognizing entities, a synthesis agent for injecting artifacts using diffusion transformers, and a curation agent for filtering and providing explanations on synthesized artifacts.
💬 Research Conclusions:
– ArtiAgent efficiently synthesizes 100K images with rich artifact annotations, demonstrating its efficacy and versatility across various applications.
👉 Paper link: https://huggingface.co/papers/2602.20951

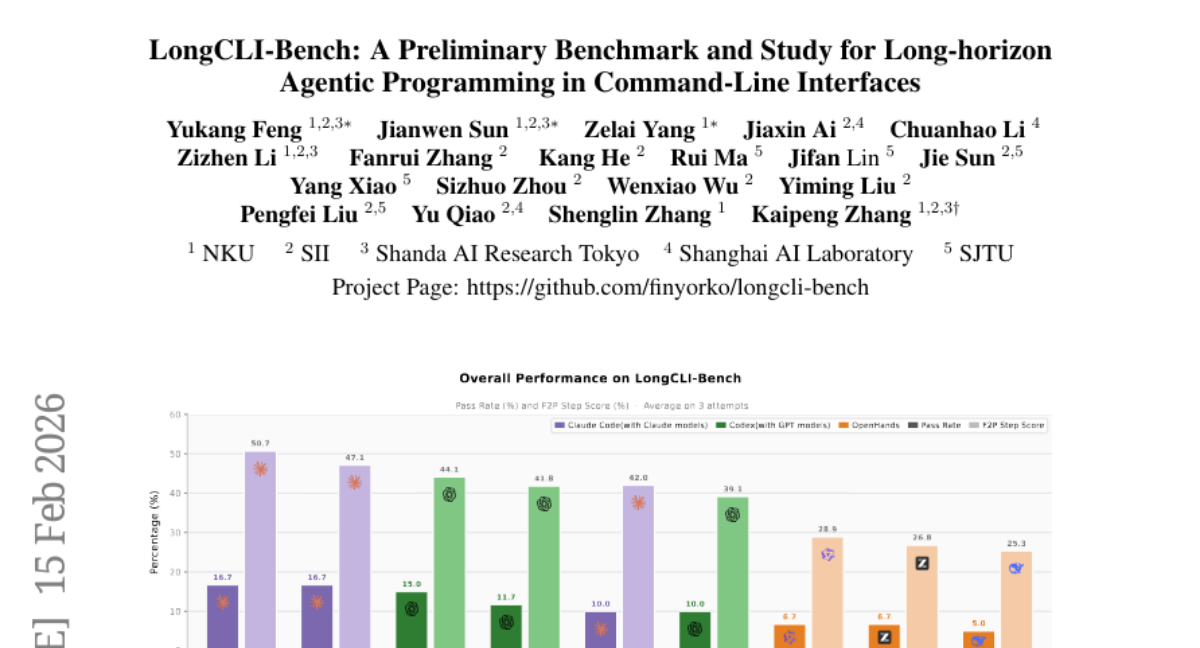
5. LongCLI-Bench: A Preliminary Benchmark and Study for Long-horizon Agentic Programming in Command-Line Interfaces
🔑 Keywords: AI-assisted programming, command-line interfaces, long-horizon planning, human-agent collaboration
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to evaluate AI agents’ ability to execute complex, long-horizon programming tasks using command-line interfaces through the newly introduced LongCLI-Bench benchmark.
🛠️ Research Methods:
– A comprehensive benchmark, LongCLI-Bench, was developed, featuring 20 curated tasks from computer science and real-world workflows. It incorporates a dual-set testing protocol to assess requirement fulfillment and regression avoidance, with step-level scoring to identify execution failures.
💬 Research Conclusions:
– State-of-the-art agents show low completion rates below 20% in LongCLI-Bench tasks. While self-correction offers slight improvements, human-agent collaboration significantly boosts performance, emphasizing the need for future research on developing synergistic workflows between humans and AI agents.
👉 Paper link: https://huggingface.co/papers/2602.14337
6. Conv-FinRe: A Conversational and Longitudinal Benchmark for Utility-Grounded Financial Recommendation
🔑 Keywords: conversational financial recommendation, large language models, decision quality, investor-specific risk preferences, rational analysis
💡 Category: AI in Finance
🌟 Research Objective:
– To evaluate large language models’ ability to balance rational decision-making with user behavior alignment in financial recommendations using multi-view references.
🛠️ Research Methods:
– Introduction of Conv-FinRe, a conversational and longitudinal benchmark for stock recommendation, assessing models through onboarding interviews, market context, and advisory dialogues.
– Utilization of real market data and controlled advisory conversations to evaluate state-of-the-art LLMs.
💬 Research Conclusions:
– Persistent tension exists between rational decision quality and behavioral alignment; models excelling in utility-based ranking may struggle with user behavior alignment, while those imitating behavior may overfit to short-term noise.
– The dataset is publicly available on Hugging Face, and the codebase is on GitHub.
👉 Paper link: https://huggingface.co/papers/2602.16990

7. Learning from Trials and Errors: Reflective Test-Time Planning for Embodied LLMs
🔑 Keywords: Reflective Test-Time Planning, reflection-in-action, reflection-on-action, AI-generated summary, behavioral correction
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study aims to enhance robot decision-making for long-horizon tasks by integrating multiple reflection mechanisms to learn from experience.
🛠️ Research Methods:
– Introduces Reflective Test-Time Planning with two reflection modes, reflection-in-action and reflection-on-action, to improve robot task performance.
– Utilizes retrospective reflection to re-evaluate decisions for better credit assignment over long periods.
💬 Research Conclusions:
– Experiments on new benchmarks show significant performance improvements over baseline models.
– Ablative studies validate the complementary roles of reflection-in-action and reflection-on-action, with qualitative analyses demonstrating behavioral correction.
👉 Paper link: https://huggingface.co/papers/2602.21198

8. Untied Ulysses: Memory-Efficient Context Parallelism via Headwise Chunking
🔑 Keywords: UPipe, Transformer models, context parallelism, memory efficiency, self-attention
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to efficiently process long sequences in Transformer models by significantly reducing activation memory usage while maintaining training speed.
🛠️ Research Methods:
– The method involves a fine-grained chunking technique at the attention head level, which reduces the intermediate tensor memory usage in the self-attention layer.
💬 Research Conclusions:
– UPipe reduces the activation memory usage by up to 87.5% for 32B Transformers and supports a context length of 5M tokens on a single node, improving upon prior methods by over 25%.
👉 Paper link: https://huggingface.co/papers/2602.21196

9. Communication-Inspired Tokenization for Structured Image Representations
🔑 Keywords: COMiT, object-centric representation, transformer model, flow-matching, compositional generalization
💡 Category: Computer Vision
🌟 Research Objective:
– The main objective is to introduce the COMiT framework to learn structured discrete visual token sequences, enhancing object-centric representation and compositional generalization.
🛠️ Research Methods:
– The approach involves iterative encoding and flow-matching decoding within a transformer model, combining flow-matching reconstruction and semantic representation alignment losses.
💬 Research Conclusions:
– The findings reveal that semantic alignment and attentive sequential tokenization are critical for achieving interpretable token structures, enhancing compositional generalization and relational reasoning compared to previous methods.
👉 Paper link: https://huggingface.co/papers/2602.20731

10. Implicit Intelligence — Evaluating Agents on What Users Don’t Say
🔑 Keywords: AI agents, implicit requirements, evaluation framework, contextual reasoning, Agent-as-a-World
💡 Category: Foundations of AI
🌟 Research Objective:
– To evaluate AI agents’ ability to interpret real-world requests that require implicit understanding and contextual reasoning.
🛠️ Research Methods:
– Implementation of “Implicit Intelligence”, an evaluation framework using interactive YAML files, and “Agent-as-a-World”, a model harness for simulating interactive worlds.
💬 Research Conclusions:
– Even the best-performing AI model achieved only a 48.3% scenario pass rate, highlighting the need for improvement in AI agents’ ability to perform human-like contextual reasoning.
👉 Paper link: https://huggingface.co/papers/2602.20424

11. The Diffusion Duality, Chapter II: Ψ-Samplers and Efficient Curriculum
🔑 Keywords: Discrete diffusion models, Predictor-Corrector samplers, Generative models, Masked diffusion, Gaussian relaxation
💡 Category: Generative Models
🌟 Research Objective:
– To evaluate the superiority of discrete diffusion models with predictor-corrector samplers over traditional methods in generation quality and efficiency, particularly challenging the necessity of masked diffusion in language modeling.
🛠️ Research Methods:
– Introduction of a family of Predictor-Corrector samplers for discrete diffusion models, applicable to arbitrary noise processes, and development of a memory-efficient curriculum for Gaussian relaxation training.
💬 Research Conclusions:
– The proposed discrete diffusion models, paired with Predictor-Corrector samplers, outperform ancestral sampling in language and image modeling, achieve better generative perplexity and FID/IS scores, reduce training time and memory while maintaining performance, thus questioning the dominance of masked diffusion methods.
👉 Paper link: https://huggingface.co/papers/2602.21185

12. TAPE: Tool-Guided Adaptive Planning and Constrained Execution in Language Model Agents
🔑 Keywords: Language Model, Adaptive Planning, constrained Execution, external solver, Environmental Feedback
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research aims to enhance the performance of Language Model (LM) agents in complex environments, particularly under strict feasibility constraints, by improving planning and execution strategies.
🛠️ Research Methods:
– The study introduces the TAPE framework, which combines Tool-guided Adaptive Planning with constrained Execution. It uses an external solver to aggregate multiple plans into a feasible path and employs constrained decoding to minimize sampling noise, with adaptive re-planning based on environmental feedback.
💬 Research Conclusions:
– TAPE significantly outperforms existing frameworks in challenging environments, achieving a 21.0 percentage point increase in success rates on hard settings, and improving performance by 20.0 percentage points for weaker base models on average.
👉 Paper link: https://huggingface.co/papers/2602.19633

13. The Art of Efficient Reasoning: Data, Reward, and Optimization
🔑 Keywords: Large Language Models, Chain-of-Thought, Reinforcement Learning, reward shaping, reasoning refinement
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study investigates the mechanics of efficient reasoning in Large Language Models (LLMs) through scaled Chain-of-Thought reasoning and reinforcement learning.
🛠️ Research Methods:
– Utilizes reward shaping to balance trajectory length and accuracy, and proposes fine-grained metrics for evaluation.
– Employs extensive experiments involving 0.2 million GPU hours with a two-stage training process.
💬 Research Conclusions:
– Key findings include training on easier prompts to ensure positive reward signals, thereby maintaining length adaptation without collapse.
– The research validates its insights across the Qwen3 series, demonstrating robustness and generalization of learned biases.
👉 Paper link: https://huggingface.co/papers/2602.20945

14. PETS: A Principled Framework Towards Optimal Trajectory Allocation for Efficient Test-Time Self-Consistency
🔑 Keywords: test-time self-consistency, trajectory allocation, self-consistency rate, offline regime, online streaming regime
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The research aims to enhance model performance using a principled and efficient test-time self-consistency method named PETS, which improves trajectory allocation through an optimization framework.
🛠️ Research Methods:
– The study introduces a self-consistency rate to provide a theoretical basis for sample-efficient test-time allocation, explores both offline and online settings, and employs a majority-voting-based allocation algorithm.
💬 Research Conclusions:
– PETS effectively reduces the sampling budget by up to 75% in offline settings and 55% in online settings while maintaining perfect self-consistency, outperforming uniform allocation.
👉 Paper link: https://huggingface.co/papers/2602.16745

15. QuantVLA: Scale-Calibrated Post-Training Quantization for Vision-Language-Action Models
🔑 Keywords: QuantVLA, post-training quantization, selective quantization, attention temperature matching, output head balancing
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce QuantVLA, a post-training quantization framework for vision-language-action models to improve deployment efficiency.
🛠️ Research Methods:
– Utilize three key techniques: selective quantization layout, attention temperature matching, and output head balancing.
💬 Research Conclusions:
– QuantVLA enhances VLA model deployment by achieving substantial memory savings and reduced latency without extra training, surpassing full-precision baselines on task success rates.
👉 Paper link: https://huggingface.co/papers/2602.20309

16. DREAM: Deep Research Evaluation with Agentic Metrics
🔑 Keywords: Deep Research Agents, Mirage of Synthesis, tool-use capabilities, temporal validity, DREAM
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Address the challenge of evaluating analyst-grade reports generated by Deep Research Agents by introducing new evaluation methods to overcome the limitations of existing benchmarks.
🛠️ Research Methods:
– Develop DREAM (Deep Research Evaluation with Agentic Metrics), a framework for evaluation using an evaluation protocol combining query-agnostic and adaptive metrics generated by a tool-calling agent to ensure temporally aware coverage and systematic reasoning.
💬 Research Conclusions:
– DREAM is significantly more sensitive to the factual and temporal decay compared to existing benchmarks, providing a scalable and reference-free evaluation paradigm.
👉 Paper link: https://huggingface.co/papers/2602.18940

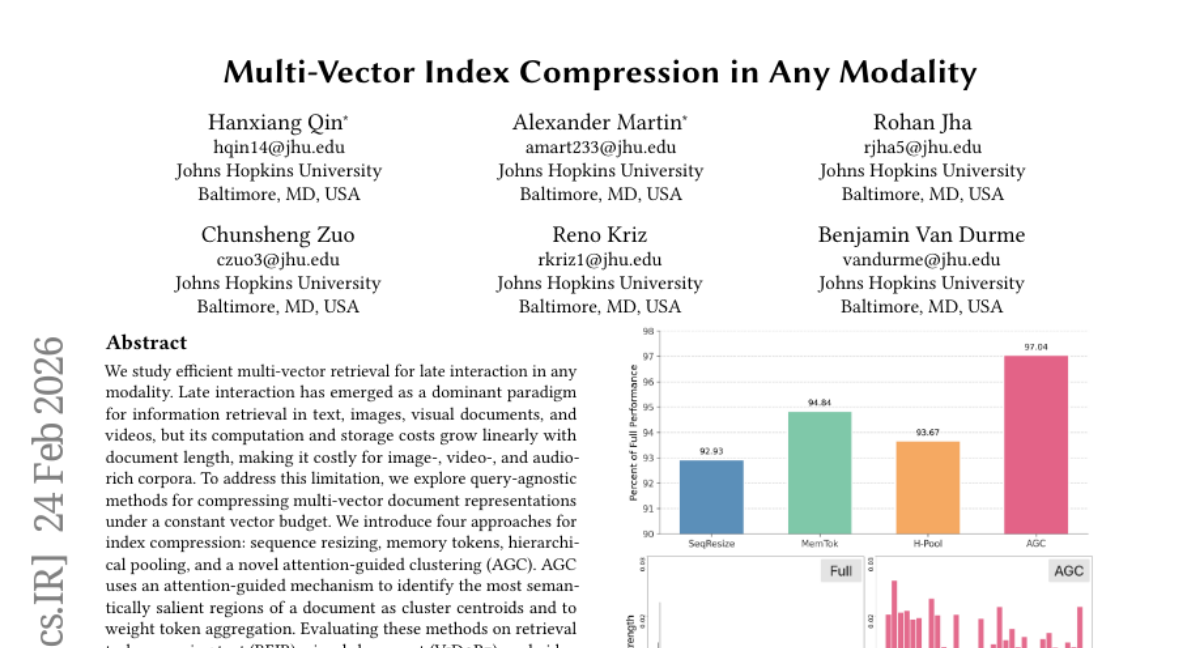
17. Multi-Vector Index Compression in Any Modality
🔑 Keywords: attention-guided clustering, multi-vector retrieval, late interaction, index compression
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To efficiently compress multi-vector document representations in late interaction retrieval tasks across multiple modalities without compromising performance.
🛠️ Research Methods:
– Introduction of four index compression methods: sequence resizing, memory tokens, hierarchical pooling, and a novel attention-guided clustering (AGC) approach.
💬 Research Conclusions:
– AGC consistently outperforms other parameterized compression methods and offers competitive or improved retrieval performance compared to full, uncompressed indexes across text, visual-document, and video modalities.
👉 Paper link: https://huggingface.co/papers/2602.21202
18. From Perception to Action: An Interactive Benchmark for Vision Reasoning
🔑 Keywords: Vision-Language Model, CHAIN benchmark, structured action sequences, physical constraints, causality
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce the CHAIN benchmark, a physics-driven testbed designed to evaluate vision-language models’ capability to understand, plan, and execute structured action sequences grounded in physical constraints.
🛠️ Research Methods:
– Conducting comprehensive studies of state-of-the-art vision-language models and diffusion-based models under unified interactive 3D settings, assessing their ability to reason about geometry, contact, and support relations in dynamic environments.
💬 Research Conclusions:
– Current top-performing models still struggle with internalizing physical structures and causal constraints, often failing to produce reliable long-horizon plans and to effectively translate perceived structure into actions.
👉 Paper link: https://huggingface.co/papers/2602.21015

19. Query-focused and Memory-aware Reranker for Long Context Processing
🔑 Keywords: attention scores, passage-query relevance, listwise solution, continuous relevance scores, dialogue understanding
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a lightweight reranking framework utilizing attention scores from selected heads to estimate passage-query relevance effectively across multiple domains.
🛠️ Research Methods:
– Utilizes a listwise solution leveraging holistic information from candidate shortlists and produces continuous relevance scores without Likert-scale supervision.
– Designs the framework around small-scale models, with extensive experiments showing superiority over state-of-the-art rerankers.
💬 Research Conclusions:
– The proposed method outperforms existing pointwise and listwise rerankers, establishing a new benchmark for dialogue understanding and memory usage.
– Demonstrated flexibility for extensions like contextual information augmentation and training attention heads from middle layers to enhance efficiency.
👉 Paper link: https://huggingface.co/papers/2602.12192
